翻译引擎智能推荐系统的制作方法
1.本发明涉及智能翻译推荐系统技术领域,更具体为翻译引擎智能推荐系统。
背景技术:
2.翻译系统的主要实现原理:将模型部署在公有云或私有服务器上,用户将数据通过互联网或局域网传输给数据接口,由数据接口访问预训练并部署的翻译模型及相关组件,由翻译模型计算得出相应的结果并返回给用户,完成翻译。
3.目前,现有技术下的预训练翻译模型由于前期训练数据获取的难度较高,导致可以用于对外服务的机器翻译引擎主要使用的是统一的大模型,无法针对用户的场景动态切换选择,该大模型在预训练时使用的数据如不能适应不同用户场景的需求(如领域,场景,语言风格),导致翻译效果不佳。
4.现有的预训练模型主要依靠transformer等技术架构,对源端和目标端进行encode和decode操作,却很少对于目标端的译文和源端的原文进行对照质量评估和事后追溯,当译文质量突然较差时,大大影响用户的使用体验。为此,需要设计一个新的方案给予改进。
技术实现要素:
5.本发明的目的在于提供翻译引擎智能推荐系统,解决了现有技术下的预训练翻译模型由于前期训练数据获取的难度较高,导致可以用于对外服务的机器翻译引擎主要使用的是统一的大模型,无法针对用户的场景动态切换选择,该大模型在预训练时使用的数据如不能适应不同用户场景的需求(如领域,场景,语言风格),导致翻译效果不佳的问题,满足实际使用需求。
6.为实现上述目的,本发明提供如下技术方案:翻译引擎智能推荐系统,场景学习和实际使用,所述场景学习包括对不同特征的文本的翻译质量评估,且所述不同特征的文本的翻译质量评估包括如下步骤:
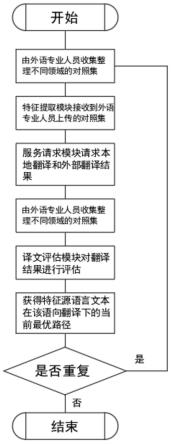
7.步骤1:由外语专业人员收集整理不同领域的对照集,包含语向,源语言文本和目标语言文本,源语言文本和目标语言文本意思相同,即目标语言文本是源语言文本的译文;注意,源语言文本长短不一,目标语言文本可以不唯一,但均为源语言文本对应的译文;
8.步骤2:特征提取模块接收到外语专业人员上传的对照集,将具有相似特征的句子归为数类,与其对应的目标语言文本一起归类到多个新的文件中;
9.步骤3:服务请求模块会通过局域网请求和公网http请求的方式,请求每个类的源语言文本通过已有的本地不同预训练模型和外部翻译引擎的翻译结果;
10.步骤4:译文评估模块会将不同预训练模型和外部云翻译引擎返回的翻译结果,与步骤1中的每句目标语言文本进行比较,以目标语言文本作为参考标准,评估不同的预训练模型和外部云翻译引擎的结果的翻译相似度,若目标语言文本有多句,则选择最优得分,将最终相似度得分作为“翻译质量”指标;
11.步骤5:将不同模型和外部翻译引擎的“翻译质量指标”结果,与该句的语向和所在的具有相同特征的句子组信息一起记入数据库;获得该类特征源语言文本在该语向翻译下的当前最优路径;
12.步骤6:由于预训练模型、外部翻译引擎会不定期增多或优化,定期重复以上操作,动态获得不同类特征源语言文本在不同语向翻译下的最新最优路径。
13.作为本发明的一种优选实施方式,智能推荐系统实际使用包括如下步骤:
14.步骤1:用户通过微信公众号后台、本地app、pc/mac客户端、集成了应用程序接口的软件通过云服务传输待翻译的原文文本、用户位置等信息和需要翻译的目标语种信息;
15.步骤2:特征提取模块提取用户待翻译的原文文本、语向、用户信息、位置、使用习惯特征,将该请求归入一个类,若可归入前述的“不同特征的文本的翻译质量评估”已有的类,则使用该类在数据库中记录的对应语向的最优路径进行翻译(若该模型、引擎无法服务,则使用第二顺位,以此类推);若无法归入已有的类,则使用该语向已有类别中获得第一最多次数的引擎进行服务(若该模型、引擎无法服务,则使用第二顺位,以此类推);
16.步骤3:译文评估模块将获得翻译结果与用户需求的原文文本进行比较评估,通过句向量、词对齐等评估手段,确认原文和译文在文本语义上的一致性;如果发现译文质量较差,则采用第二顺位引擎进行翻译,以此类推;
17.步骤4:将确认质量合格的译文返回给用户;
18.步骤5:在用户授权的情况下,定期随机抽检译文,并进行人工标注,评估机器译文和人工标注译文结果的相似度,对翻译的服务质量进行追溯。
19.作为本发明的一种优选实施方式,步骤(2)中,对对照集进行领域、句意、场景等文本特征的提取对句子进行聚类。
20.作为本发明的一种优选实施方式,步骤(3)中,考虑到神经网络机器翻译的不可解释性和不稳定性,确保即使在综合评估质量较高的模型或引擎进行翻译时,句子不会出现偶发的质量较低的情况。
21.与现有技术相比,本发明的有益效果如下:
22.本发明,可以实现同时使用不同的预训练模型、翻译引擎进行翻译工作,可以大大提升机器译文的质量。由于预训练的翻译模型所使用的数据领域、优劣不同,导致不同的预训练模型和翻译引擎在不同类型的文本上的翻译质量有高有低,只使用一个预训练模型进行翻译时,容易出现翻译质量时高时低的问题。
附图说明
23.图1为本发明所述不同特征的文本的翻译质量评估流程图;
24.图2为本发明所述智能推荐系统实际使用流程图。
具体实施方式
25.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
26.请参阅图1-2,本发明提供一种技术方案:翻译引擎智能推荐系统,场景学习和实际使用,场景学习包括对不同特征的文本的翻译质量评估,且不同特征的文本的翻译质量评估包括如下步骤:
27.步骤1:由外语专业人员收集整理不同领域的对照集,包含语向,源语言文本和目标语言文本,源语言文本和目标语言文本意思相同,即目标语言文本是源语言文本的译文;注意,源语言文本长短不一,目标语言文本可以不唯一,但均为源语言文本对应的译文;
28.例如:line1 zh2en src-我最喜欢踢足球。ref1-my favourite sport is football.ref2-i love playing football the best.ref3-...。
29.步骤2:特征提取模块接收到外语专业人员上传的对照集,进行领域、句意、场景等文本特征的提取对句子进行聚类,将具有相似特征的句子归为数类,与其对应的目标语言文本一起归类到多个新的文件中;
30.步骤3:服务请求模块会通过局域网请求或公网http请求等方式,请求每个类的源语言文本通过已有的本地不同预训练模型和外部翻译引擎的翻译结果;
31.步骤4:译文评估模块会将不同预训练模型和外部云翻译引擎返回的翻译结果,与步骤1中的每句目标语言文本进行比较,以目标语言文本作为参考标准,评估不同的预训练模型和外部云翻译引擎的结果的翻译相似度,若目标语言文本有多句,则选择最优得分,将最终相似度得分作为“翻译质量”指标;
32.步骤5:将不同模型和外部翻译引擎的“翻译质量指标”结果,与该句的语向和所在的具有相同特征的句子组信息一起记入数据库;获得该类特征源语言文本在该语向翻译下的当前最优路径;
33.步骤6:由于预训练模型、外部翻译引擎会不定期增多或优化,定期重复步骤1-5的操作,动态获得不同类特征源语言文本在不同语向翻译下的最新最优路径。
34.进一步改进地,智能推荐系统实际使用包括如下步骤:
35.步骤1:用户通过微信公众号后台、本地app、pc/mac客户端、集成了应用程序接口的软件通过云服务传输待翻译的原文文本、用户位置等信息和需要翻译的目标语种信息;
36.步骤2:特征提取模块提取用户待翻译的原文文本、语向、用户信息、位置、使用习惯特征,将该请求归入一个类,若可归入前述的“不同特征的文本的翻译质量评估”已有的类,则使用该类在数据库中记录的对应语向的最优路径进行翻译(若该模型、引擎无法服务,则使用第二顺位,以此类推);若无法归入已有的类,则使用该语向已有类别中获得第一最多次数的引擎进行服务(若该模型、引擎无法服务,则使用第二顺位,以此类推);
37.步骤3:译文评估模块将获得翻译结果与用户需求的原文文本进行比较评估,通过句向量、词对齐等评估手段,确认原文和译文在文本语义上的一致性,考虑到神经网络机器翻译的不可解释性和不稳定性,确保即使在综合评估质量较高的模型或引擎进行翻译时,句子不会出现偶发的质量较低的情况;如果发现译文质量较差,则采用第二顺位引擎进行翻译,以此类推;
38.步骤4:将确认质量合格的译文返回给用户;
39.步骤5:在用户授权的情况下,定期随机抽检译文,并进行人工标注,评估机器译文和人工标注译文结果的相似度,对翻译的服务质量进行追溯。
40.使用本系统可以实现同时使用不同的预训练模型、翻译引擎进行翻译工作,可以
大大提升机器译文的质量。由于预训练的翻译模型所使用的数据领域、优劣不同,导致不同的预训练模型和翻译引擎在不同类型的文本上的翻译质量有高有低,只使用一个预训练模型进行翻译时,容易出现翻译质量时高时低的问题。
41.最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1