一种基于数据虚拟化引擎的数据模型及其构建方法与流程
1.本发明涉及数据处理技术领域,尤其涉及一种基于数据虚拟化引擎的数据模型及其构建方法。
背景技术:
2.随着科学技术的迅速发展,大数据的应用越来越广,数据处理和数据模型的创建需求量越来越多,在通过各种大数据平台和工具来对数据进行建模分析时,往往需要先进行数据汇总,把不同来源的数据清理后统一保存到某个数据中台或大数据处理系统种,然后通过写sql语句、代码脚本或是其他方式来构建业务的数据模型。
3.然而,上述数据处理过程中存在以下几个弊端:(1)上述数据处理过程中必须借助于一个具备大数据的中间平台,这就需要高性能的硬件支撑,同时,还要求用户具备大数据维护的专业能力;(2)大多数据模型的构建都需要编写sql语句,模型越复杂,就需要更多的sql语句来满足业务需求,要求使用者具备sql的读写能力;(3)大多数据模型在通过sql语句编写和创建后,无法一目了然的获知模型输出的数据结果的数据来源,无法追溯数据流向。
4.综上,虽然目前大多数据产品都具有建立数据模型和编写sql语句的能力,但是不能很好的解决,在跨数据源情况下,不通过编写sql语句就能创建数据模型,以及分析模型数据结果的血缘关系的问题。
技术实现要素:
5.为了解决上述背景技术中所提到的技术问题,而提出的一种基于数据虚拟化引擎的数据模型及其构建方法。
6.为了实现上述目的,本发明采用了如下技术方案:一种基于数据虚拟化引擎的数据模型,包括数据预处理模块、数据模型装配模块、数据模型执行模块和数据模型输出模块;所述数据预处理模块,用于对数据虚拟化引擎下的不同数据源表的字段进行中英文注释和表达式配置,配置后生成一个数据表对象;所述数据模型装配模块包括运算组件,所述运算组件包括连接组件、字段设置组件、交集组件、并集组件、差集组件、聚合组件和筛选组件,通过运算组件连接一个或者多个数据表,使其装配成数据模型;所述数据模型执行模块包括sql语句构造器,所述sql语句构造器用于分析数据模型中数据表和运算组件的所有连接关系,把图形化的连接关系转换为sql查询语句,并通过数据虚拟化引擎执行该sql查询语句,实现不同数据来源的数据库表查询并得到数据结果;所述数据模型输出模块包括数据结果列表输出和血缘关系输出,数据结果列表输出把数据模型运行完毕后查询的数据结果集以列表的形式进行前端输出展示,血缘关系以
关系图谱的方式展示数据的流向和来源,所述血缘关系图包括依次连接的数据源节点、运算组件节点和结果节点,且每个节点的信息框显示有对应节点的信息内容,以便查看数据的生成关系。
7.作为上述技术方案的进一步描述:还包括数据虚拟引擎查询器,所述数据虚拟引擎查询器是基于数据虚拟化引擎的查询功能执行需要查询的sql语句,并分析sql语句的血缘关系生成血缘关系图。
8.作为上述技术方案的进一步描述:还包括数据存储器和业务数据库,所述数据存储器是用来保存数据模型的数据表、运算组件和连接关系,以及保存数据模型执行的数据结果和血缘关系图,并将它们存储在业务数据库中。
9.作为上述技术方案的进一步描述:所述连接组件和字段设置组件均用于连接两个数据表或运算组件,且字段设置组件用于配置数据表对象过滤或者注释字段,所述交集组件、并集组件和差集组件是以连接的数据表的所有字段做整体的数据比对输出,所述聚合组件用来进行分组排列输出,所述筛选组件用来配置连接的数据表对象需要过滤的字段条件。
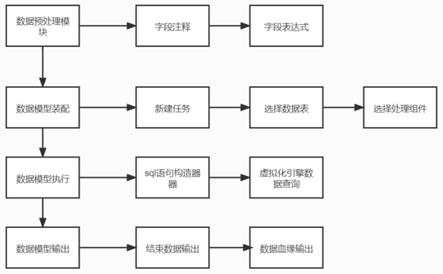
10.作为上述技术方案的进一步描述:一种基于数据虚拟化引擎的数据模型构建方法,包括以下步骤:s1、数据源表选择:选择数据虚拟化引擎包含的某个数据库中的一个数据表作为一个数据对象,数据对象用来与其他的数据表进行运算处理;s2、数据预处理:s21、设置字段注释:对数据表中的字段添加中文或者英文注释;s22、设置字段表达式:通过表达式配置进行字段的函数转换,包括数字转换字符串、时间格式转换,以及对敏感字段进行局部或者全局脱敏设置;s3、数据模型装配:s31、建立数据模型:设置模型的名称、标签和执行模式,执行模式分为离线任务和实时任务:s32、推拽数据表对象:模型建立完成后,进入到流程模型的编辑页面,将已经配置好的数据表对象拖拽到编辑页面进行模型的业务配置;s32、配置数据处理组件:通过运算组件进行数据表对象的处理,实现数据表对象的交并差关联、聚合排序、字段和行数筛选功能,构建零语句的数据模型;s4、执行模型:先通过sql语句构造器,把图形化的模型连接关系转换为数据库的sql查询语句,再通过数据虚拟化引擎查询器执行该sql查询语句,实现跨不同来源的数据库表查询,并得到数据结果以及生成数据的血缘关系图,最后将数据结果和血缘关系图通过数据存储器存储在业务数据库中;s5、数据输出:s51、在预览数据结果时取其前n条数据进行展示;s52、数据以血缘关系图的方式进行展示,以便追溯数据流向。
11.综上所述,由于采用了上述技术方案,本发明的有益效果是:本发明基于数据虚拟化引擎使用数据表对象和运算组件构建数据模型,实现跨不同数据源的直接查询,不需要搭建数据中台或中间汇聚平台,也不需要编写sql语句实现数据模型的构建,具体为:首先,把不同数据来源的数据表进行数据预处理,添加注释、字段表达式和数据脱敏等,其次,通
过数据模型装配模块,把要处理的数据表拖拽到编辑页面中并利用连接、字段设置、交集、并集、差集、聚合、筛选行等运算组件对数据表进行各种处理,最后,结合sql语句构造器、数据虚拟引擎查询器和数据存储器模块,将模型执行的结果和数据血缘进行前端输出并显示,以便追溯数据流向。
附图说明
12.图1示出了根据本发明实施例提供的一种基于数据虚拟化引擎的数据模型的结构示意图;图2示出了根据本发明实施例提供的一种基于数据虚拟化引擎的数据模型构建方法的流程示意图;图3示出了根据本发明实施例提供的血缘关系示意图。
具体实施方式
13.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
14.实施例一请参阅图1-3,本发明提供一种技术方案:一种基于数据虚拟化引擎的数据模型,包括数据预处理模块、数据模型装配模块、数据模型执行模块和数据模型输出模块、数据虚拟引擎查询器、数据存储器和业务数据库;数据预处理模块,用于对数据虚拟化引擎下的不同数据源表的字段进行中英文注释和表达式配置,配置后生成一个数据表对象,其中,添加字段注释是方便在使用该表的时候其他使用者能知道字段含义;数据模型装配模块包括运算组件,运算组件包括连接组件、字段设置组件、交集组件、并集组件、差集组件、聚合组件和筛选组件等运算组件,每个组件都分别具有不同的功能、参数设置,通过运算组件连接一个或者多个数据表,使其装配成数据模型,完全不用写后台查询语句就能实现数据的业务分析和模型构建;具体的,连接组件可以连接两个数据表或运算组件,在组件设置界面可以设置左连接、右连接、内连接和全连接,并选择两个数据表的关联字段,可添加一个或者多个关联字段;字段设置组件可以连接数据表或运算组件,字段设置组件用来配置数据表对象需要过滤哪些字段和注释哪些字段,不需要进行下一级输出的字段则取消勾选;交集组件、并集组件和差集组件是以连接的数据表的所有字段做整体的数据比对,比对数据的字段要一致,如学生表a和学生表b进行交集组件连接,设置交集组件的字段是学号、姓名和班级,那么交集组件就会比对表a和表b中这三个字段都完全一致的数据进行数据输出,并集组件则是进行合并输出,差集组件则是表a中这三个字段剔除表b存在的记录进行输出;聚合组件用来进行分组排列输出,聚合组件只能一对一连接,聚合组件获取上级
输出的字段,并在聚合组件中设置需要分组的字段和聚合的字段,比如,将“学院”字段拉到分组栏中,然后,把“学生成绩”拉到聚合栏,在聚合栏中会识别字段类型,数值型的会有常用的sum、avg、max、min和cnt等运算方法选择,如果是字符型的字段,则只有cnt和cnt(去重)两个运算方法选择;筛选组件是一对一连接的组件,用来配置连接的数据表对象需要过滤的字段条件,条件关系有=、≠、in、not in、like、not like、为空和不为开空等,比如,筛选组件连接了学生表对象,设置“学院”字段=“文学院”字段,还可以增加字段筛选,设置字段是“且”与“或”的关系;数据模型执行模块包括sql语句构造器,sql语句构造器用于分析数据模型中数据表和运算组件的所有连接关系,把图形化的连接关系转换为sql查询语句,并通过数据虚拟化引擎执行该sql查询语句,实现不同数据来源的数据库表查询并得到数据结果;具体的,sql语句构造器用于分析图形化的模型连接关系,并按顺序依次把数据表对象和运算组件的关联转换为sql查询语句,把每个运算关系的结果暂存为临时表,然后继续分析下一个运算组件的sql查询语句,直到把所有的运算关系分析完毕后,生成最终的sql语句;具体的,数据模型都是由数据表对象和运算组件连接构成,数据表对象与运算组件的参数设置都在数据库中,sql语句构造器就是一个一个按顺序从数据库中获取连接关系,再把参数配置分析出来,每一个连接用到的字段、过滤条件和参数设置应等都被转换为对应的sql语句生成出来,完成一个连接关系就封装一个sql语句取一个别名,再依次循环执行;数据模型输出模块包括数据结果列表输出和血缘关系输出,数据结果列表输出把数据模型运行完毕后查询的数据结果集以列表的形式进行前端输出展示,血缘关系以关系图谱的方式展示数据的流向和来源,血缘关系图包括依次连接的数据源节点、运算组件节点和结果节点,且每个节点的信息框显示有对应节点的信息内容,以便查看数据的生成关系;具体的,数据血缘输出,是根据数据模型的连接方式,把模型的数据流向转换为以“实体—关系”的关系图谱的方式展示数据的流向,如图3所示,图形左边的节点是数据源节点,中间是运算组件节点,最右边是结果节点,在每个节点的信息框里面显示节点的信息内容,比如数据源,数据表、字段信息等,方便查看数据的生成关系;数据虚拟引擎查询器是基于数据虚拟化引擎的查询功能执行需要查询的sql语句,并分析sql语句的血缘关系生成血缘关系图;具体的,数据虚拟化引擎查询器由一个协调节点、多个工作节点和连接器组成,协调节点是负责解析语句、规划查询和管理工作节点的服务器,它是查询器的“大脑”,也是客户端连接以提交语句执行的节点,协调节点跟踪每个工作节点上的活动,并协调查询的执行,协调节点创建了一个查询的逻辑模型,其中包含一系列阶段,然后将其转换为在工作节点集群上运行的一系列相互连接的任务;工作节点负责执行任务和处理数据,工作节点从连接器获取数据,并相互交换中间数据,协调节点负责从工作节点获取结果,并将最终结果返回给客户端;连接器类似数据库的驱动,将虚拟引擎适配到关系型数据库的数据源,它允许使
用标准api与资源交互,数据虚拟引擎有多个不同的连接器,针对每个类型的数据源就有一个连接器,每个连接器都有对应的目录,每个目录都与一个特定的连接器相关联,目录之外还有模式,模式是组织表的一种形式,目录和模式一起定义了一组可以查询的表,当数据虚拟引擎查询器查询执行sql语句时,并将这些语句转换为跨协调节点和工作节点分布式集群执行的查询,查询任务将数据生成到输出缓冲区中,并使用交换客户端使用来自其他任务的数据,查询包含阶段、任务、分片、连接器和其他组件以及协同工作以生成结果的数据源;数据存储器是用来保存数据模型的数据表、运算组件和连接关系,以及保存数据模型执行的数据结果和血缘关系图,并将它们存储在业务数据库中。
15.请参阅图2,一种基于数据虚拟化引擎的数据模型构建方法,包括以下步骤:s1、数据源表选择:选择数据虚拟化引擎包含的某个数据库中的一个数据表作为一个数据对象,数据对象用来与其他的数据表进行运算处理,在选择数据表时,可以过滤表的字段,比如:学生表中有20个字段,但是只需要常用的5个字段,其他15个字段可以设置为不可见,如选择学生库中的“学生成绩表”和银行库中的“学生银行信用表”;s2、数据预处理:s21、设置字段注释:在平台的数据资源页面中,选择数据源表后,会显示出数据源表字段信息,手动对数据表中的字段添加中文或者英文注释,为了方便数据表对象在自己和其他人使用的方便理解,注释依据表字段的内容和使用者的习惯添加;s22、设置字段表达式:在平台的数据资源页面中,选择数据源表后,会显示处数据源表字段信息,在字段后面有“表达式”列,通过表达式配置进行字段的函数转换,包括数字转换字符串、时间格式转换,以及对敏感字段进行局部或者全局脱敏设置;比如,“学生银行信用表”的表中有学生的年度交易金额、交易笔数、身份证号、余额和信用等级字段,这时候需要把身份证号和余额字段进行脱敏,就可以在这两个字段后面“表达式”列中选择脱敏函数,可以选择“数据模糊化”、“数据裁切”、“固定值替换”、“随机填充”、“哈希处理”和“md5处理”等多种方式;s3、数据模型装配:s31、建立数据模型:设置模型的名称、标签和执行模式,执行模式分为离线任务和实时任务:s32、推拽数据表对象:模型建立完成后,进入到数据模型的编辑页面,将已经配置好的数据表对象拖拽到编辑页面进行模型的业务配置,在编辑页面单击数据表对象还能进行表数据和字段的过滤,可以添加过滤条件,比如:设置“性别=
‘
女
’”
就只取数据表中为女性的数据,也可以勾选需要使用的字段,不用的字段取消勾选;s32、配置数据处理组件:通过运算组件进行数据表对象的处理,实现数据表对象的交并差关联、聚合排序、字段和行数筛选功能,构建零语句的数据模型,每个组件都分别具有不同的功能和参数设置,比如,两个数据对象:一个学生成绩数据、一个学生银行信用数据,两个数据对象关联到“连接”组件设置学生id相同的过滤条件和勾选要输出的字段;s4、执行模型:先通过s61sql语句构造器,把图形化的模型连接关系转换为数据库的sql查询语句,再通过s62数据虚拟化引擎查询器执行该sql查询语句,虚拟化引擎已经实现跨不同来源的数据库表查询,所以可以直接执行生成的语句并得到数据结果,且生成数据的血缘关系,最后将数据结果和血缘关系图通过数据存储器存储在业务数据库中;s5、数据输出:
s51、在页面前端进行数据结果预览的时候把数据结果进行展示输出,取结果数据的前100条数据进行展示;s52、在页面前端进行数据的血缘输出展示,通过关系图谱的方式展示数据的来源。
16.本发明基于数据虚拟化引擎使用数据表对象和运算组件构建数据模型,实现跨不同数据源的直接查询,不需要搭建数据中台或中间汇聚平台,也不需要编写sql语句实现数据模型的构建,具体为:首先,把不同数据来源的数据表进行数据预处理,添加注释、字段表达式和数据脱敏等,其次,通过数据模型装配模块,把要处理的数据表拖拽到编辑页面中并利用连接、字段设置、交集、并集、差集、聚合、筛选行等运算组件对数据表进行各种处理,最后,结合sql语句构造器、数据虚拟引擎查询器和数据存储器模块,将模型执行的结果和数据血缘进行前端输出并显示,以便追溯数据流向。
17.以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1