信息处理装置、信息处理方法、移动体的控制装置、移动体的控制方法以及存储介质与流程
1.本发明涉及信息处理装置、信息处理方法、移动体的控制装置、移动体的控制方法以及存储介质。
背景技术:
2.近年来,使用了自然语言的人机界面的开发得到推进。在非专利文献1中,提出了使用被称为bert的语言表达模型来实现发言文中的意图的分类(intent classification)与槽填充(slot filling)的技术。发言文中的意图的分类例如为对用户的指示、提问(也称为问询)中的用户的意图进行推定的技术,另外槽填充是对用户已提供的或者不足的信息进行识别,并进行明确化的发问或者补充的技术。
3.现有技术文献
4.非专利文献
5.非专利文献1:qian chen另两人,bert for joint intent classification and slot filling,2019年2月28日,https://arxiv.org/pdf/1902.10909.pdf
技术实现要素:
6.发明所要解决的问题
7.在非专利文献1中,提出了使用通过bert安装好的单一模型来同时进行意图的分类与槽填充的技术,为了将发言分类为大量意图类别中的任一类别,需要使用了庞大量的数据的学习。
8.然而,单一分类器的模型为了对用户的意图进行分类,需要解决对于假定了所有情景(场景)的大量意图类别的分类问题。在假定了用户通过发言来控制移动体的情况下,能够存在大量用户的意图,例如,用于召唤在附近行驶的移动体的能否利用的询问、对于移动体的路线的指示、与车辆的行驶有关的指示(例如加速的指示)、结束乘车后对于移动体的开回指示等。即,在通过发言对移动体的控制中,为了对能否利用的询问到开回指示这样的各种各样的发言意图进行分类,需要很大的模型,其结果是,有时需要庞大量的学习数据、或者有时无法得到所希望的精度的意图分类结果。
9.本发明是鉴于上述问题而完成的,其目的在于实现如下技术:在通过发言对移动体的控制中,能够通过由更小规模的学习构建的模型来提供发言意图的分类。
10.用于解决问题的手段
11.根据本发明,
12.提供一种信息处理装置,其能够基于用户的发言的指示来控制移动体,其特征在于,
13.所述信息处理装置具有:
14.识别单元,其识别对象用户的利用场景是利用移动体时的多个利用场景中的哪一
种场景;
15.获取单元,其获取所述对象用户的发言信息;
16.选择单元,其根据识别出的所述对象用户的利用场景来选择不同的机器学习模型;以及
17.推定单元,其使用选择出的机器学习模型来推定所述对象用户的发言的意图。
18.另外,根据本发明,
19.提供一种信息处理方法,其是能够基于用户的发言的指示来控制移动体的信息处理装置中的信息处理方法,其特征在于,
20.所述信息处理方法具有:
21.识别步骤,在该识别步骤中,识别对象用户的利用场景是利用移动体时的多个利用场景中的哪一种场景;
22.获取步骤,在该获取步骤中,获取所述对象用户的发言信息;
23.选择步骤,在该选择步骤中,根据识别出的所述对象用户的利用场景来选择不同的机器学习模型;以及
24.推定步骤,在该推定步骤中,使用选择出的机器学习模型来推定所述对象用户的发言的意图。
25.进一步,根据本发明,
26.提供一种移动体的控制装置,该移动体能够基于用户的发言的指示来进行控制,其特征在于,
27.所述控制装置具有:
28.识别单元,其识别对象用户的利用场景是利用移动体时的多个利用场景中的哪一种场景;
29.获取单元,其获取所述对象用户的发言信息;
30.选择单元,其根据识别出的所述对象用户的利用场景来选择不同的机器学习模型;以及
31.推定单元,其使用选择出的机器学习模型来推定所述对象用户的发言的意图。
32.另外,根据本发明,
33.提供一种移动体的控制方法,该移动体能够基于用户的发言的指示来进行控制,其特征在于,
34.所述控制方法具有:
35.识别步骤,在该识别步骤中,识别对象用户的利用场景是利用移动体时的多个利用场景中的哪一种场景;
36.获取步骤,在该获取步骤中,获取所述对象用户的发言信息;
37.选择步骤,在该选择步骤中,根据识别出的所述对象用户的利用场景来选择不同的机器学习模型;以及
38.推定步骤,在该推定步骤中,使用选择出的机器学习模型来推定所述对象用户的发言的意图。
39.进一步,根据本发明,
40.提供一种存储介质,其保存用于将计算机作为信息处理装置的各单元而发挥功能
的程序,其特征在于,
41.能够基于用户的发言的指示来控制移动体的所述信息处理装置具有:
42.识别单元,其识别对象用户的利用场景是利用移动体时的多个利用场景中的哪一种场景;
43.获取单元,其获取所述对象用户的发言信息;
44.选择单元,其根据识别出的所述对象用户的利用场景来选择不同的机器学习模型;以及
45.推定单元,其使用选择出的机器学习模型来推定所述对象用户的发言的意图。
46.另外,根据本发明,
47.提供一种存储介质,其保存用于将计算机作为控制装置的各单元而发挥功能的程序,其特征在于,
48.能够基于用户的发言的指示来进行控制的移动体的所述控制装置具有:
49.识别单元,其识别对象用户的利用场景是利用移动体时的多个利用场景中的哪一种场景;
50.获取单元,其获取所述对象用户的发言信息;
51.选择单元,其根据识别出的所述对象用户的利用场景来选择不同的机器学习模型;以及
52.推定单元,其使用选择出的机器学习模型来推定所述对象用户的发言的意图。
53.发明效果
54.根据本发明,在通过发言对移动体的控制中,能够通过由更小规模的学习构建的模型来提供发言意图的分类。
附图说明
55.图1是对本发明的实施方式所涉及的信息处理系统的一个例子进行表示的图。
56.图2a、图2b是对本实施方式所涉及的车辆的硬件的构成例进行表示的框图。
57.图3是对本实施方式所涉及的车辆的功能构成例进行表示的框图。
58.图4是对本实施方式所涉及的服务器的功能构成例进行表示的框图。
59.图5a是对本实施方式所涉及的利用车辆时的利用场景、与利用场景相关联的发言的意图类别、以及与意图类别对应的发言的一个例子进行表示的图。
60.图5b是对在本实施方式的乘车前的利用场景下,应用了隐马尔科夫模型的情况的一个例子进行说明的图。
61.图5c是对在本实施方式连续的利用场景中,分别推定发言意图的情形进行说明的图。
62.图6是对本实施方式所涉及的发言意图推定处理的一系列动作进行表示的流程图。
63.图7是对其他实施方式所涉及的信息处理系统的一个例子进行表示的图。
64.附图标记说明
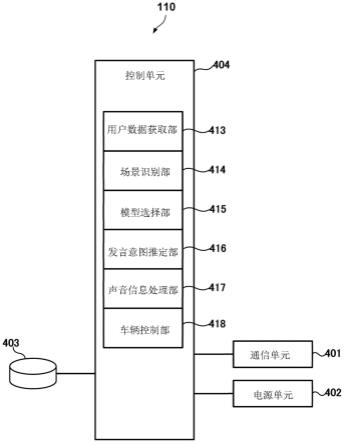
65.100:车辆;110:服务器;120:通信装置;404:控制单元;413:用户数据获取部;414:场景识别部;415:模型选择部;416:发言意图推定部;417:声音信息处理部;418:车辆控制
部。
具体实施方式
66.以下,参照附图对实施方式进行详细说明。此外,以下实施方式不对技术方案所涉及的发明作限定,另外,在实施方式中说明的特征组合的全部并非是发明所必须的。可以对在实施方式中说明的多个特征中的两个以上的特征进行任意组合。另外,对相同或者同样的构成标注相同的附图标记,并省略重复的说明。
67.(信息处理系统的构成)
68.参照图1,对本实施方式所涉及的信息处理系统1的构成进行说明。信息处理系统1包括作为移动体的一个例子的车辆100、作为信息处理装置的一个例子的服务器110、以及通信装置120。
69.在该信息处理系统1中,用户130通过自然语言的发言,能够与车辆100对话或者控制车辆100的动作。当通信装置120接受用户130对于车辆100的发言时,将发言信息发送至服务器110。服务器110根据用户的发言信息来推定用户的发言意图。服务器110基于推定出的发言意图,如果需要,则进行槽填充(对用户已提供的信息或者不足的信息进行识别,并根据需要,将用于明确化的发问提供给用户130)。当服务器110识别用户的发言意图时,为了确定具体的指示内容而根据发言信息来确定需要的信息,从而接受用户的指示。在用户130的发言是对于车辆100的指示(例如,“立刻到当前地来接”)的情况下,服务器110将与该指示相应的控制指示发送至车辆100。
70.车辆100是移动体的一个例子,例如为搭载电池并且主要以马达的动力来移动的超小型移动装置。超小型移动装置是指,比通常的机动车更紧凑并且额定乘员为一人或者二人左右的超小型车辆。在本实施方式中,车辆100例如为四轮车。此外,在以下实施方式中,移动体不限于交通工具,可以包括与步行用户并行而运送货物、或者对人进行引导这样的小型移动装置,另外,也可以包括其他能够自主移动的移动体(例如步行型机器人等)。
71.车辆100例如经由wi-fi、第五代移动通信等无线通信而连接至网络140。车辆100通过各种各样的传感器来测量(车辆的位置、行驶状态、周围的物体的目标物等)车辆内外的状态,并能够将测量出的数据发送给服务器110。如这样收集并发送的数据通常被称为浮动数据、探测数据、交通信息等。与车辆有关的信息以一定的间隔或者根据特定的事件已发生这一情况而被发送至服务器110。即使在用户130未乘车的情况下,车辆100也能够通过自动驾驶来行驶。车辆100接收由服务器110提供的控制指令等信息、或者使用通过本车测量出的数据来控制车辆的动作。
72.服务器110是信息处理装置的一个例子。服务器110通过一个以上的服务器装置构成,能够经由网络140获取从车辆100发送的与车辆有关的信息、从通信装置120发送的发言信息、以及各个位置信息,并能够控制车辆100的行驶。服务器110根据用户的发言信息,执行后述的用户的意图推定处理,从而推定发言中的用户的意图。
73.通信装置120例如为智能手机,但不限于此,也可以是耳机型的通信终端,还可以是个人计算机、平板电脑终端、游戏机等。通信装置120例如经由wi-fi、第五代移动通信等无线通信而连接至网络140。通信装置120接受用户130的发言,并将已接受的发言信息(声音信息)发送至服务器110。
74.网络140例如包括因特网、移动电话网等通信网,并传输服务器110与车辆100之间的信息、服务器110与通信装置120之间的信息。
75.(车辆的构成)
76.接下来,参照图2a~图2b,对作为本实施方式所涉及的车辆的一个例子的车辆100的构成进行说明。
77.图2a对本实施方式所涉及的车辆100的侧面进行了表示,图2b对车辆100的内部构成进行了表示。图中箭头x表示车辆100的前后方向,f表示前,r表示后。箭头y、z表示车辆100的宽度方向(左右方向)、上下方向。
78.车辆100是具备行驶单元12并将电池13作为主电源的电动自主式车辆。电池13例如为锂离子电池等充电电池,车辆100通过由电池13提供的电力并通过行驶单元12来自主行驶。行驶单元12是具备左右一对前轮20与左右一对后轮21的四轮车。行驶单元12也可以是三轮车的方式等其他方式。车辆100具备一人用或者两人用的座席14。座席14例如通过压力传感器等,将乘员是否在乘车发送至控制单元30。
79.行驶单元12具备转向机构22。转向机构22是将马达22a作为驱动源而使一对前轮20的转角变化的机构。能够通过使一对前轮20的转角变化来变更车辆100的行进方向。行驶单元12还具备驱动机构23。驱动机构23是将马达23a作为驱动源而使一对后轮21旋转的机构。能够通过使一对后轮21旋转来使车辆100前进或者后退。
80.车辆100具备检测车辆100的周围目标物的检测单元15~17。检测单元15~17是监视车辆100的周边的外界传感器组,在本实施方式的情况下,均为拍摄车辆100的周围图像的拍摄装置,例如具备透镜等光学系统与图像传感器。但是,代替拍摄装置或者在拍摄装置的基础上,也能够采用雷达、光学雷达(light detection and ranging:光检测与测距)。
81.两个检测单元15以沿y方向隔开的方式配置在车辆100的前部,主要检测车辆100的前方的目标物。检测单元16分别配置在车辆100的左侧部以及右侧部,主要检测车辆100的侧方的目标物。检测单元17配置在车辆100的后部,主要检测车辆100的后方目标物。
82.图3是车辆100的控制系统的框图。车辆100具备控制单元(ecu)30。控制单元30包括以cpu为代表的处理器、半导体存储器等存储装置、与外部装置的接口等。在存储装置中保存有处理器所执行的程序、处理器用于处理的数据等。处理器、存储装置以及接口也可以构成为,按车辆100的功能类别设置为多个组而能够相互通信。也可以进行对于已输入的声音的声音识别、对于通过检测单元拍摄到的图像的图像处理。
83.控制单元30根据检测单元15~17的检测结果、操作面板31的输入信息、由声音输入装置33输入的声音信息、来自服务器110的控制指令等,执行对应的处理。控制单元30进行马达22a、23a的控制(行驶单元12的行驶控制)、操作面板31的显示控制、通过声音对车辆100的乘员的报告、信息的输出。
84.声音输入装置33能够拾取车辆100的乘员的声音。控制单元30能够识别已输入的声音来执行对应的处理。gnss(global navigation satellite system:全球导航卫星系统)传感器34接收gnss信号来检测车辆100的当前位置。
85.存储装置35是大容量存储装置,其存储包括车辆100能够行驶的行驶道路、建造物等地标、门店等信息在内的地图数据等。存储装置35也可以保存有处理器所执行的程序、处理器用于处理的数据等。存储装置35还可以保存通过控制单元30而执行的声音识别、图像
识别用的机器学习模型的各种参数(例如深层神经网络的学习完毕参数等)。
86.通信装置36例如为经由wi-fi、第五代移动通信等无线通信而能够连接至网络140的通信装置。
87.(服务器的构成)
88.接下来,参照图4,对作为本实施方式所涉及的信息处理装置的一个例子的服务器110的构成进行说明。
89.控制单元404包括以cpu为代表的处理器、半导体存储器等存储装置、与外部装置的接口等。存储装置保存有处理器所执行的程序、处理器用于处理的数据等。处理器、存储装置、接口也可以构成为,按服务器110的功能类别设置为多个组而能够相互通信。控制单元404通过执行程序,执行服务器110的各种动作、后述的用户的意图推定处理、车辆100的控制等。控制单元404在包括cpu的基础上,还包括gpu、或者适合神经网络等机器学习模型的处理执行的专用硬件。
90.用户数据获取部413获取从车辆120发送的用户130的发言信息。另外,用户数据获取部413获取从通信装置100发送的浮动数据(例如,车辆位置、乘员的有无等)信息。用户数据获取部413也可以将获取到的图像、位置信息保存于存储部403。用户数据获取部413获取到的发言信息被输入至(学习完毕的)推论阶段的学习完毕模型,但也可以作为用于使通过服务器110执行的机器学习模型进行学习的学习数据来被使用。
91.场景识别部414识别用户所处的当前的情景(场景)。场景识别部414例如识别用户的场景是乘车前、乘车中、下车后的哪一种。针对场景的识别方法的例子在后面叙述。
92.模型选择部415在通过场景识别部414识别出的场景中,选择机器学习模型。如后述那样,机器学习模型存在有多个,各个机器学习例如与乘车前、乘车中、下车后的任一者相关联。即,各机器学习模型以如下方式构成:针对每一个相关联的利用场景,推定的意图类别不同,并输出任一场景的意图类别的似然度。
93.发言意图推定部416使用通过模型选择部415选择出的机器学习模型,推定用户的发言的意图。针对发言的意图推定方法在后面叙述。
94.声音信息处理部417基于识别出的发言意图,为了确定具体的指示内容而根据发言信息来确定必要的信息。例如,在用户的发言信息的意图为要求过来迎接的情况下,确定去哪里、什么时候去迎接等信息。当声音信息处理部417确定必要的信息时,接受用户的指示。声音信息处理部417也可以包括槽填充的处理。声音信息处理部417可以包括与用于发言的意图推定的机器学习模型不同的多个机器学习模型,各机器学习模型例如可以通过深层神经网络(dnn)构成。dnn能够通过进行学习阶段的处理而成为学习完毕的状态,并能够通过将新的发言信息输入至学习完毕的dnn来进行对于新的发言信息的处理(推论阶段的处理)。
95.车辆控制部418基于通过声音信息处理部417识别出的发言内容,控制车辆100的动作。例如,在根据用户的发言信息来确定去哪里、什么时候去迎接等信息的情况下,基于用户以及车辆的当前位置、地图信息等来确定路线,使车辆在该路线上行驶。
96.此外,与车辆100等相比,服务器110通常能够使用丰富的计算资源。相比每一个车辆100搭载用于执行机器学习模型的计算资源的情况,服务器110能够更高速地提供运算结果,此外,还能够有助于车辆的成本抑制。另外,服务器110通过接收、积累各种各样的用户
的发言信息,能够采集包括多种多样的发言信息在内的学习数据,并使得更强有力的推论处理成为可能。
97.通信单元401例如为包括通信用电路等在内的通信装置,并与车辆100、通信装置120等外部装置进行通信。通信单元401接收来自车辆100的位置信息和乘员的有无、来自通信装置120的发言信息和位置信息,此外,还发送对车辆100的控制指令、对通信装置120的发言信息。
98.电源部402向服务器110内的各部提供电力。存储部403是硬盘、半导体存储器等非易失性存储器。
99.(用户的意图推定处理的概要)
100.如上述那样,在假设了用户通过发言来控制移动体的情况下,能够存在大量的用户的意图,例如,用于召唤在附近行驶的移动体的能否利用的询问、对于移动体的路线的指示、与车辆的行驶有关的指示(例如加速的指示)、结束乘车后对于移动体的开回指示等。
101.但是,在移动体的利用前,有可能对移动体的能否利用进行询问、或者发出呼叫移动体那样的意图发言,而另一方面发出指示利用后的开回那样的意图发言的可能性很低。换言之,在乘车前、乘车中以及下车后的各场景内发出的交谈的意图有些是在其他场景中不会出现的。
102.因此,在本实施方式中,在通过发言来控制移动体时,针对每一个假定的场景(利用场景)来总结意图类别,并针对每一个场景来关联机器学习模型。各机器学习模型仅推定相关联的利用场景的意图类别。通过这样,能够使用适合每一个场景的模型,相比通过单一的模型来对大量的意图类别进行分类的情况,各模型能够更小规模化,并且能够通过更小规模的学习来进行构建。另外,能够期待识别精度的提高。
103.以下,参照图5a~5c,对本实施方式所涉及的利用场景、发言的意图类别的关系、以及意图推定的算法进行说明。
104.图5a对利用车辆时的利用场景、与利用场景相关联的发言的意图类别、以及与意图类别对应的发言的一个例子进行了表示。如图5a所示那样,利用场景501作为一个例子被分为乘上车辆100前的状态(乘车前状态)、乘车中的状态(乘车中状态)、以及下车后的状态(下车后状态)。此外,图5a中的“平时”不是特定的利用场景,而是意味着属于“平时”的三个意图类别被包含在任意利用场景中。
105.发言的意图类别502对用户的发言中的意图进行表示。“乘车前”的利用场景例如与询问、迎接要求、打招呼、目的地指示、同意、否定、重问等七个意图类别相关联。另外,“乘车中”的利用场景例如与路线指示、停止指示、加速指示、减速指示、同意、否定、重问等七个意图类别相关联。同样地,“下车后”的利用场景也与图5a所示的七个意图类别相关联。
106.发言例503对与各个意图类别对应的发言例进行了表示。例如“现在能够乘车?”等发言与“询问”的意图对应。
107.如这样,将在利用车辆时假定的连续的场景定义为预定数量的场景,各利用场景仅与能够与多个利用场景相关的全部的意图类别中的一部分的意图类别相关联。通过这样,机器学习模型可以仅针对能够与多个利用场景相关的全部的意图类别中的一部分的意图类别来输出推论结果。因此,能够将推定意图类别的机器学习模型小规模化,并能够通过小规模的学习数据来使机器学习模型进行学习。
108.此外,在图5a所示的例子中,对于全部的利用场景,对数目相同的意图类别相关联的例子进行了表示,但各利用场景也可以与不同数量的意图类别相关联。另外,意图类别不限于上述例子,可以包括其他意图类别,也可以不包括图5a所示的一部分的意图类别。例如,乘车前的利用场景还可以包括“追赶要求”即要求车辆追赶上用户的移动目的地。针对追赶要求,例如考虑“追上去”等发言例。
109.另外,发言例将用户130对车辆100说话这样的发言例作为例子进行了表示。但是,不限于用户130将车辆100作为对象的发言例,也可以使用用户130对(协调车辆控制的)人类接待员说话那样的发言。
110.接下来,参照图5b,对在乘车前的利用场景中应用隐马尔可夫模型的情况的一个例子进行说明。马尔可夫模型是指,任意时刻的状态的概率分布按照仅依赖于之前的状态那样的概率过程的概率模型。在本实施方式中,应用隐马尔可夫模型(也称为hmm),在给出能够观测的状态(发言信息)时,解决对隐藏在其背后的状态(发言意图)进行推定的问题。
111.图5b所示的510~513对隐马尔可夫模型中的隐状态进行表示,相当于意图类别。此外,在图5b所示的例子中,仅以四个意图类别为例进行了表示以使图不会过于复杂。意图类别的圆内所记载的数值表示初始状态概率。即,对在成为了“乘车前”的利用场景之后能够产生的意图类别的概率(似然度)进行表示。另外,各箭头对意图类别(状态)之间的转换进行表示,添加在箭头上的数值(例如“0.aa”)表示状态转换概率。初始状态概率的分布以及状态转换概率的分布可以预先决定,例如,求出学习数据所包含的正确答案数据的各意图类别间的转换概率、初始状态概率,从而能够使用这些概率。
112.进一步,参照图5c,对本实施方式所涉及的意图推定处理的例子进行说明。在图5所示的例子中,对将“乘车前”作为第一利用场景、将“乘车中”作为第二利用场景并针对各利用场景来推定发言意图进行了表示。图中的510~513与图5b示出的意图类别对应,概率分布中的柱状图表示各意图类别的概率(似然度)。图中的520~523分别与“乘车中”的意图类别(路线指示、停止指示、加速指示、减速指示)对应,概率分布中的柱状图表示这些意图类别的概率(似然度)。
113.在第一利用场景的初始状态概率分布530中,如图5b示出的那样,询问与打招呼的概率变得比其他概率高。在第一利用场景开始后,用户进行发言(例如“能够乘车?”)。这样一来,服务器110使用与第一利用场景相关联的机器学习模型来计算意图类别的概率(似然度),并且加入初始状态概率分布530,从而计算出意图类别的概率(似然度)(概率分布540)。第一利用场景的概率分布540对与询问的意图有关的概率(似然度)高这一情况进行表示。进一步,当用户进行接下来的发言时,服务器110使用相同的机器学习模型来计算意图类别的概率(似然度),并且加入状态转换概率,从而计算出意图类别的概率(似然度)。如这样,通过机器学习模型来计算意图的似然度,在此基础上,通过加入从某意图的状态转换至下一个意图的状态的概率,并考虑意图的似然度与概率分布易于转换,从而能够进行最终的发言意图的推定。
114.其后,当利用场景变化时,服务器110使用与第二利用场景相关联的机器学习模型、第二利用场景的初始状态概率分布、以及第二利用场景的状态转换概率分布来计算意图类别的概率(似然度)。
115.在本实施方式中,服务器110根据以下算式计算意图类别的似然度。以下意图类别
的计算如上述那样是针对各利用场景来计算的。
116.[算式1]
[0117][0118]
输出意图类别
[0119]
在上述算式中,b(c
t
)是意图类别的离散概率分布,x
t
是已将发言文矢量化的情况,c是可取的意图类别的集合(已矢量化的情况),c是表示意图类别的概率变量,下标t(t≧1)表示时刻。似然度函数p(x
t
|c
t
)的运算结果通过(针对每一个利用场景而不同的)机器学习模型的运算来求出。b(c
t=0
)是(针对每一个利用场景而不同的)初始状态概率分布。p(c
t
|c
t-1
)表示(针对每一个利用场景而不同的)状态转换概率。通过该计算,在推定时刻t的发言的意图时,能够递归地加入为了比时刻t的发言靠前一次的发言而推定出的推定结果。
[0120]
(用户的意图推定处理的一系列动作)
[0121]
接下来,参照图6,对服务器110中的用户的意图推定处理的一系列动作进行说明。此外,本处理是通过控制单元404执行程序来实现的。通过该一系列动作所执行的机器学习模型使用学习用数据而处于学习完毕(推论阶段)的状态。在以下说明中,为了简化说明,将控制单元404作为执行各处理而进行说明,但通过(在图4中上述的)控制单元404的各部来执行对应的处理。
[0122]
在s601中,控制单元404从通信装置120接收开始触发。开始触发例如,对基于用户的发言来控制车辆的服务的利用开始进行表示。例如根据用户130在通信装置120中启动了用于利用该服务的应用、或者对表示该服务的利用开始的预定的用语进行了发言等,从通信装置120发送该开始触发。
[0123]
在s602中,控制单元404确定与用户130相关联的车辆。控制单元404基于例如根据从车辆发送的浮动数据而在平时掌握的各种各样的车辆的当前位置、用户130的当前位置,确定离用户130最近的车辆100。不限于该方法,也可以将在通信装置120上通过用户而指定的车辆确定为相关联的车辆。
[0124]
在s603中,控制单元404从确定到的车辆100,获取用于判定利用场景的信息。用于判定利用场景的信息例如包括,在车辆上乘员是否在乘车的信息、以及用户130是否在预定时间内已乘车的信息。乘员是否在乘车的信息例如根据车辆的座席来得到。还可以包括通过设置于车辆内的拍摄装置而识别出的乘员的信息。
[0125]
此外,在这些信息包含在从车辆100发送至服务器110的浮动数据中的情况下,可以省略本步骤。在该情况下,控制单元404可以从浮动数据中获取确定到的车辆100的信息。虽然图6未明示,但在其他用户在车辆100上乘车的情况下,控制单元404使处理返回到s602并确定其他车辆。
[0126]
在s604中,控制单元404识别用户对于车辆100的利用场景。利用场景根据上述{乘车前、乘车中、下车后}来被识别。在乘员未在乘车且用户130在预定时间内未乘车的情况下,控制单元404将当前的利用场景识别为乘车前。在乘员在车辆上在乘车且该乘员为用户130的情况下,将当前的利用场景判定为乘车中。另外,在乘员未在乘车且用户130在预定时间内已乘车的情况下,控制单元404将当前的利用场景识别为下车后。
[0127]
在s605中,控制单元404根据识别出的利用场景来选择机器学习模型。机器学习模型分别使用针对每一个对应的利用场景而不同的学习用数据来进行学习。学习用数据例如对于用户的发言信息,赋予成为正确答案的发言的意图的标签,进一步,赋予表示对应的利用场景的标签。即,控制单元404在使针对每一个利用场景的机器学习模型进行学习时,能够仅将对应的利用场景的学习数据输入至机器学习模型来使机器学习模型进行学习。
[0128]
在s606中,控制单元404判定是否获取到用户的发言信息。在控制单元404从通信装置120获取到用户的发言信息的情况下,使处理进入到s607,在控制单元404从通信装置120未获取到用户的发言信息的情况下,使处理返回到s606并等待获取用户的发言信息。
[0129]
在s607中,控制单元404使用在s605中选择出的机器学习模型来判定发言的意图。具体地说,控制单元404针对上述的算式来进行运算,计算输出意图类别argmax b(c
t
)。此时,在识别出新的利用场景之后的发言信息的情况下,用户的发言信息执行t=1的情况下的运算,在未识别出新的利用场景之后的发言信息的情况下,用户的发言信息进行t≧2的情况下的运算。
[0130]
在s608中,控制单元404将与发言的意图相应的控制指令发送至车辆。控制单元40例如如上述那样,基于推定出的发言意图,为了确定具体的指示内容而根据发言信息来确定必要的信息。例如,在用户的发言信息的意图为要求过来迎接的情况下,确定去哪里、在什么时候去迎接等信息。声音信息处理部417还可以包括槽填充的处理。另外,控制单元404基于识别出的发言内容,将控制车辆100的动作的控制指令发送至车辆100。例如,在根据用户的发言信息确定去哪里、在什么时候去迎接等信息的情况下,基于用户以及车辆的当前位置、地图信息等来确定路线,将在该路线上行驶的控制指令发送至车辆100。
[0131]
在s609中,控制单元404判定用户操作是否已结束。控制单元404例如判定是否已从通信装置120接收表示结束的信息。例如,在通信装置120中,根据用户130对表示该服务的利用结束的预定的用语进行了发言等,从通信装置120发送表示结束的信息。在控制单元404判定为用户操作已结束的情况下,结束该一系列处理,在控制单元404判定为用户操作未结束的情况下,使处理返回到s603并重复s603之后的处理。
[0132]
此外,在上述实施方式中,以服务器110基于来自车辆100的信息来识别利用场景的情况为例进行了说明。但是,服务器110也可以基于其他信息来识别利用场景。例如,服务器110也可以基于来自通信装置120的信息来识别利用场景。例如,通信装置120也可以接收从通信装置120发送的开始触发、表示发生与车辆的接近的信息,来识别利用场景。如上述那样,例如,在通信装置120中,根据用户130启动了用于利用上述服务的应用、或者对表示该服务的利用开始的预定的用语进行了发言等,从通信装置120发送利用触发。另外,例如,用户在车辆100上乘车时以及下车时,使车辆100接近通信装置120,当通信装置120通过接近无线通信等来检测与车辆的接近时,将表示发生接近的信息发送至车辆。例如,服务器110在接收开始触发后未接收到表示发生接近的信息的情况下,将利用场景识别为乘车前,其后,当接收表示发生接近的信息时,可以将利用场景识别为乘车中。进一步,当接收表示发生接近的信息时,可以将利用场景识别为下车后。此外,可以在通信装置120中识别利用场景以代替服务器110识别利用场景,并根据利用场景的切换,将识别出的利用场景发送至服务器110。
[0133]
如以上说明的那样,在上述实施方式中,在能够基于用户的发言的指示来控制车
辆的信息处理装置中,首先,识别对象用户的利用场景是利用移动体时的多个利用场景中的哪一种场景。在识别出利用场景后,根据识别出的对象用户的利用场景来选择不同的机器学习模型,并使用选择出的机器学习模型,来推定对象用户的发言的意图。通过这样,在通过发言对移动体的控制中,通过由更小规模的学习构建的模型来提供发言意图的分类。
[0134]
(变形例)
[0135]
以下,对本发明所涉及的变形例进行说明。在上述实施方式中,对在服务器110中执行发言意图的推定处理的例子进行了说明。但是,上述发言意图的推定处理也能够在车辆侧执行。在该情况下,如图7所示那样,信息处理系统700通过车辆710与通信装置120构成。用户的发言信息从通信装置120发送至车辆710。除了控制单元30能够执行发言意图的推定处理以外,车辆710的构成可以与车辆100是相同的构成。车辆710的控制单元30作为车辆710中的控制装置而动作,并通过执行存储的程序,执行上述发言意图的推定处理。图6所示出的一系列动作中的服务器与车辆之间的互动可以在车辆的内部(例如控制单元30的内部)进行。针对其他处理,能够与服务器同样地执行。
[0136]
如这样,在能够基于用户的发言的指示来控制车辆的控制装置中,首先,识别对象用户的利用场景是利用移动体时的多个利用场景中的哪一种场景。在识别出利用场景后,根据识别出的对象用户的利用场景来选择不同的机器学习模型,并使用选择出的机器学习模型,推定对象用户的发言的意图。通过这样,在发言的移动体的控制中,能够通过由更小规模的学习构建的模型来提供发言意图的分类。
[0137]
<实施方式的总结>
[0138]
1.上述实施方式的信息处理装置(例如110)是一种能够基于用户的发言的指示来控制移动体(例如100)的信息处理装置,
[0139]
所述信息处理装置具有:
[0140]
识别单元(例如414),其识别对象用户的利用场景是利用移动体时的多个利用场景中的哪一种场景;
[0141]
获取单元(例如413),其获取对象用户的发言信息;
[0142]
选择单元(例如415),其根据识别出的对象用户的利用场景来选择不同的机器学习模型;以及
[0143]
推定单元(例如416),其使用选择出的机器学习模型来推定对象用户的发言的意图。
[0144]
根据该实施方式,在通过发言对移动体的控制中,能够通过由更小规模的学习构建的模型来提供发言意图的分类。
[0145]
2.在上述实施方式的信息处理装置中,
[0146]
针对机器学习模型所关联的每一个利用场景,机器学习模型推定的意图类别(例如501、502)不同。
[0147]
根据该实施方式,能够使用适合每一个场景的的机器学习模型。
[0148]
3.在上述实施方式的信息处理装置中,
[0149]
推定单元使用输出似然度的机器学习模型来推定对象用户的意图,该似然度是仅涉及能够与多个利用场景相关联的全部意图类别中的一部分意图类别。
[0150]
根据该实施方式,能够使用对适合每一个场景的少量意图类别进行输出的模型。
即,能够使模型的学习变容易。
[0151]
4.在上述实施方式的信息处理装置中,
[0152]
推定单元在选择出的机器学习模型的输出中,加入使用了被作为预先分布而设定在意图类别中的初始状态概率分布后的运算,来推定所述对象用户的发言的意图。
[0153]
根据该实施方式,能够对与依赖于场景语境的发言有关的常识(交流的第一声为否定意图、或者在交谈期间有打招呼意图的可能性很低)进行反映。
[0154]
5.在上述实施方式的信息处理装置中,
[0155]
被作为预先分布而设定的初始状态概率分布是针对每一个利用场景而单独决定的。
[0156]
根据该实施方式,能够针对每一个场景来对与发言有关的常识进行反映。
[0157]
6.在上述实施方式的信息处理装置中,
[0158]
推定单元在选择出的机器学习模型的输出中,加入使用了意图类别之间的状态转换概率分布后的运算,来推定对象用户的发言的意图。
[0159]
根据该实施方式,能够进行考虑到实际的对话中的意图的转换顺序的意图推定。
[0160]
7.在上述实施方式的信息处理装置中,
[0161]
状态转换概率分布是针对每一个场景而单独决定的。
[0162]
根据该实施方式,能够单独决定场景的意图类别之间的状态转换概率。
[0163]
8.在上述实施方式的信息处理装置中,
[0164]
推定单元在对时刻t的发言的意图进行推定时,在选择出的所述机器学习模型的输出中,加入为了比时刻t的发言靠前一次的发言而推定出的推定结果,来推定对象用户的发言的意图。
[0165]
根据该实施方式,能够递归地考虑对于到时刻t-1为止的发言的概率分布。
[0166]
9.在上述实施方式的信息处理装置中,
[0167]
机器学习模型分别针对每一个对应的利用场景而使用不同的学习用数据进行学习,学习用数据包括表示利用场景的标签。
[0168]
根据该实施方式,能够使机器学习模型针对每一个利用场景而通过小规模化的学习用数据来进行学习,学习数据能够根据标签很容易地对利用场景进行分类来用于学习。
[0169]
10.在上述实施方式的信息处理装置中,
[0170]
基于来自与对象用户相关联的移动体的信息,识别对象用户的利用场景是哪一种场景。
[0171]
根据该实施方式,基于由移动体即利用对象提供的信息来判定利用场景,由此能够高精度地进行利用场景的判定。
[0172]
11.上述实施方式中的移动体(例如710)的控制装置(例如30)是一种能够基于用户的发言的指示来进行控制的移动体的控制装置,
[0173]
所述控制装置具有:
[0174]
识别单元(例如30、s604),其识别对象用户的利用场景是利用移动体时的多个利用场景中的哪一种场景;
[0175]
获取单元(例如30、s606),其获取对象用户的发言信息;
[0176]
选择单元(例如30、s605),其根据识别出的对象用户的利用场景来选择不同的机
器学习模型;以及
[0177]
推定单元(例如30、s607),其使用选择出的机器学习模型来推定对象用户的发言的意图。
[0178]
根据该实施方式,在通过发言对移动体的控制中,能够通过由更小规模的学习构建的模型来提供发言意图的分类。
[0179]
本发明不限于上述的实施方式,可以在本发明的主旨的范围内进行各种变形、变更。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1