一种基于师生协同的知识蒸馏方法
1.本发明涉及知识蒸馏技术领域,具体涉及一种基于师生协同的知识蒸馏方法。
背景技术:
2.随着深度学习的快速发展,深度卷积网络在计算机视觉的各项任务中表现出了出色的性能。然而卷积神经网络越来越深,导致模型参数巨大、计算复杂、延时高,使得在有限硬件资源条件下难以部署到终端。其中,知识蒸馏(knowledge distillation)作为神经网络模型压缩的一种重要方法,其目的是使用一种轻量化的模型从过度参数化的模型中学习有效的知识,获得近似于复杂模型的性能,从而达到模型压缩的目的。
3.现有技术通常将知识蒸馏模型结构称为师生网络,在具有一位经验丰富的教师网络的条件下,学生网络通过知识蒸馏学习教师网络丰富信息,提升自身网络的性能。例如,公开号为cn112418343a的中国专利就公开了《多教师自适应联合知识蒸馏》,其包括:将训练好的多个教师网络的特征输入到一个深度神经网络进行二次分类,将深度神经网络的中间层作为教师网络的特征融合模型;将同一批训练数据输入教师网络和学生网络,得到各个教师网络的特征和概率分布;用训练好的深度神经网络融合特征,用加权预测融合各个教师网络的预测结果;构造损失函数,并基于损失函数更新学生网络的参数,固定其他模型的参数;重复上述步骤,直到学生网络收敛。
4.上述现有方案中的多教师自适应联合知识蒸馏方法,通过将不同教师网络传递的知识有差异的结合,形成软标签引导学生网络的学习,使得学生网络的学习更加有效。但申请人发现,上述现有方案在训练学生网络时,需要构建并融合多个教师网络的特征和概率分布,这大大增加了整个知识蒸馏模型的复杂度和训练成本。同时,现有方案仅专注于提升教师网络的性能以及如何传递有效的信息,而忽略了挖掘学生网络的潜在价值,导致学生网络的性能有待进一步提高。因此,如何设计一种能够降低知识蒸馏模型复杂度并提高学生网络性能的知识蒸馏方法是亟需解决的技术问题。
技术实现要素:
5.针对上述现有技术的不足,本发明所要解决的技术问题是:如何提供一种基于师生协同的知识蒸馏方法,以能够通过教师网络和学生网络自身来协同优化和训练学生网络,使得不增加教师网络的复杂度并能够基于学生网络的输出进行自监督和自学习,从而能够降低知识蒸馏模型的复杂度并提高学生网络的性能。
6.为了解决上述技术问题,本发明采用了如下的技术方案:
7.基于师生协同的知识蒸馏方法,包括以下步骤:
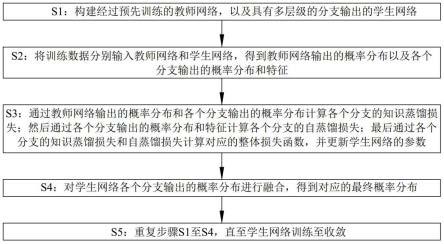
8.s1:构建经过预先训练的教师网络,以及具有多层级的分支输出的学生网络;
9.s2:将训练数据分别输入教师网络和学生网络,得到教师网络输出的概率分布以及各个分支输出的概率分布和特征;
10.s3:通过教师网络输出的概率分布和各个分支输出的概率分布计算各个分支的知
识蒸馏损失;然后通过各个分支输出的概率分布和特征计算各个分支的自蒸馏损失;最后通过各个分支的知识蒸馏损失和自蒸馏损失计算对应的整体损失函数,并更新学生网络的参数;
11.s4:对学生网络各个分支输出的概率分布进行融合,得到对应的最终概率分布;
12.s5:重复步骤s1至s4,直至学生网络训练至收敛。
13.优选的,步骤s1中,使用过参数化的resnet模型或vgg模型作为教师网络,并对教师网络进行训练。
14.优选的,步骤s1中,在学生网络的不同阶段添加自适应瓶颈层和全连接层,使得学生网络能够形成由浅到深的多个层级的分支输出。
15.优选的,步骤s2中,步骤s2中,自适应瓶颈层的结构由1x1、3x3、1x1的三层卷积模块组成,其自适应体现在根据不同特征图的大小使用不同数量的瓶颈模块。
16.优选的,步骤s3中,分支的知识蒸馏损失包括教师网络输出的概率分布和对应分支输出的概率分布之间的kl散度,以及对应分支输出的概率分布与训练数据的真实标签之间的交叉熵损失。
17.优选的,步骤s3中,知识蒸馏损失通过如下公式计算:
[0018][0019]
其中,y
t
=f
t
(x,w
t
);
[0020]
yi=fs(x,ws);
[0021]
式中:表示第i个分支的知识蒸馏损失;i∈[1,n];t2l
kl
(yi,y
t
)表示教师网络输出的概率分布y
t
和第i个分支输出的概率分布yi之间的kl散度;l
ce
(yi,y)表示第i个分支输出的概率分布yi与训练数据的真实标签y之间的交叉熵损失;w
t
、ws表示教师网络和学生网络的权重参数;x表示教师网络和学生网络的输入;f
t
和fs表示教师网络和学生网络的特征。
[0022]
优选的,步骤s3中,分支的自蒸馏损失包括对应分支输出的概率分布与主干网络输出的概率分布之间的kl散度,以及对应分支输出的特征与主干网络输出的特征之间的l2损失;其中,将最深层级分支的输出作为主干网络的输出。
[0023]
优选的,步骤s3中,自蒸馏损失通过如下公式计算:
[0024][0025]
其中,yi,fi=fs(x,ws);
[0026]
式中:表示第i个分支的自蒸馏损失;i∈[1,n];t2l
kl
(yi,yn)表示第i个分支输出的概率分布yi与主干网络输出的概率分布yn之间的kl散度;||ui(fi)-fn||2表示第i个分支输出的特征fi与主干网络输出的特征fn之间的l2损失。
[0027]
优选的,步骤s3中,整体损失函数表示为:
[0028][0029]
式中:loss表示整体损失;表示第i个分支的知识蒸馏损失;表示第i个分支的自蒸馏损失;i∈[1,n];a、β表示设置的超参数。
[0030]
优选的,步骤s4中,最终概率分布通过如下公式计算:
[0031][0032]
式中:ys表示学生网络输出的最终概率分布;yi表示第i个分支输出的概率分布;i∈[1,n]。
[0033]
本发明中的基于师生协同的知识蒸馏方法与现有技术相比,具有如下有益效果:
[0034]
本发明通过构建教师网络以及具有多层级分支输出的学生网络,进而通过教师网络输出的概率分布以及各个分支输出的概率分布和特征分别构建基于知识蒸馏和自蒸馏结合的整体损失函数,使得能够在教师网络指导的基础上,通过学生网络多层级的分支输出的概率分布和特征进行自我监督,即在教师网络蒸馏结构的基础上将学生网络作为第二个老师,能够通过教师网络和学生网络自身来协同优化和训练学生网络,本发明仅需在学生网络的主干网络中添加少许层,而无需提高教师网络的复杂度,使得不增加教师网络的复杂度并能够基于学生网络的输出进行自监督和自学习,从而能够降低知识蒸馏模型的复杂度并提高学生网络的性能,并兼顾知识蒸馏模型的训练成本和训练效果。
附图说明
[0035]
为了使发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步的详细描述,其中:
[0036]
图1为基于师生协同的知识蒸馏方法的逻辑框图;
[0037]
图2为教师网络和学生网络的网络结构示意图;
[0038]
图3为四个分支输出特征的示意图。
具体实施方式
[0039]
下面通过具体实施方式进一步详细的说明:
[0040]
实施例:
[0041]
本实施例中公开了一种基于师生协同的知识蒸馏方法。
[0042]
如图1和图2所示,基于师生协同的知识蒸馏方法,包括以下步骤:
[0043]
s1:构建经过预先训练的教师网络,以及具有多层级的分支输出的学生网络;
[0044]
s2:将训练数据分别输入教师网络和学生网络,得到教师网络输出的概率分布以及各个分支输出的概率分布和特征;本实施例中,需固定教师网络的参数。
[0045]
s3:通过教师网络输出的概率分布和各个分支输出的概率分布计算各个分支的知识蒸馏损失;然后通过各个分支输出的概率分布和特征计算各个分支的自蒸馏损失;最后通过各个分支的知识蒸馏损失和自蒸馏损失计算对应的整体损失函数,并更新学生网络的参数;
[0046]
s4:对学生网络各个分支输出的概率分布进行融合,得到对应的最终概率分布;
[0047]
s5:重复步骤s1至s4,直至学生网络训练至收敛。
[0048]
本发明通过构建教师网络以及具有多层级分支输出的学生网络,进而通过教师网络输出的概率分布以及各个分支输出的概率分布和特征分别构建基于知识蒸馏和自蒸馏结合的整体损失函数,使得能够在教师网络指导的基础上,通过学生网络多层级的分支输出的概率分布和特征进行自我监督,即在教师网络蒸馏结构的基础上将学生网络作为第二个老师,能够通过教师网络和学生网络自身来协同优化和训练学生网络,本发明仅需在学
生网络的主干网络中添加少许层,而无需提高教师网络的复杂度,使得不增加教师网络的复杂度并能够基于学生网络的输出进行自监督和自学习,从而能够降低知识蒸馏模型的复杂度并提高学生网络的性能,并兼顾知识蒸馏模型的训练成本和训练效果。
[0049]
具体实施过程中,使用过参数化的resnet模型或vgg模型作为教师网络,并对教师网络进行训练。使用相比教师网络较小的模型作为学生网络,在学生网络的不同阶段添加自适应瓶颈层和全连接层,使得学生网络能够形成由浅到深的多个层级的(分类器)分支输出。
[0050]
本实施例中,自适应瓶颈层的具体结构由1x1、3x3、1x1的三层卷积模块组成,自适应体现在根据不同特征图的大小使用不同数量的瓶颈模块。引入自适应瓶颈层一方面是为了保证学生网络不同阶段的输出特征是相同尺度的,另一方面是减小卷积的计算量。全连接层用于输出类别的概率分布。由于不同阶段的分支(分类器)网络结构不同,对样本有不同的拟合性能,这提供了丰富的类别信息。
[0051]
具体实施过程中,分支的知识蒸馏损失包括教师网络输出的概率分布和对应分支输出的概率分布之间的kl散度,以及对应分支输出的概率分布与训练数据的真实标签之间的交叉熵损失。知识蒸馏损失通过如下公式计算:
[0052][0053]
其中,y
t
=f
t
(x,w
t
);
[0054]
yi=fs(x,ws);
[0055]
式中:表示第i个分支的知识蒸馏损失;i∈[1,n];t2l
kl
(yi,y
t
)表示教师网络输出的概率分布y
t
和第i个分支输出的概率分布yi之间的kl散度;l
ce
(yi,y)表示第i个分支输出的概率分布yi与训练数据的真实标签y之间的交叉熵损失;w
t
、ws表示教师网络和学生网络的权重参数;x表示教师网络和学生网络的输入;f
t
和fs表示教师网络和学生网络的特征。
[0056]
具体实施过程中,分支的自蒸馏损失包括对应分支输出的概率分布与主干网络输出的概率分布之间的kl散度,以及对应分支输出的特征与主干网络输出的特征之间的l2损失;其中,将最深层级分支的输出作为主干网络的输出。自蒸馏损失通过如下公式计算:
[0057][0058]
其中,yi,fi=fs(x,ws);
[0059]
式中:表示第i个分支的自蒸馏损失;i∈[1,n-1];t2l
kl
(yi,yn)表示第i个分支输出的概率分布yi与主干网络输出的概率分布yn之间的kl散度;||ui(fi)-fn||2表示第i个分支输出的特征fi与主干网络输出的特征fn之间的l2损失。
[0060]
整体损失函数表示为:
[0061][0062]
式中:loss表示整体损失;表示第i个分支的知识蒸馏损失;表示第i个分支的自蒸馏损失;i∈[1,n];a、β表示设置的超参数。
[0063]
本实施例中,kl散度、交叉熵损失和l2损失的计算均采用现有手段,这里不再赘述。
[0064]
其中,kl散度(kullback-leibler divergence,kullback-leibler散度)又称为相
对熵(relative entropy)或信息散度(information divergence),是两个概率分布(probability distribution)间差异的非对称性度量。
[0065]
在信息理论中,相对熵等价于两个概率分布的信息熵(shannon entropy)的差值。相对熵是一些优化算法,例如最大期望算法(expectation-maximization algorithm,em)的损失函数。此时参与计算的一个概率分布为真实分布,另一个为理论(拟合)分布,相对熵表示使用理论分布拟合真实分布时产生的信息损耗。
[0066]
交叉熵(cross entropy)是shannon信息论中一个重要概念,主要用于度量两个概率分布间的差异性信息。
[0067]
语言模型的性能通常用交叉熵和复杂度(perplexity)来衡量。交叉熵的意义是用该模型对文本识别的难度,或者从压缩的角度来看,每个词平均要用几个位来编码。复杂度的意义是用该模型表示这一文本平均的分支数,其倒数可视为每个词的平均概率。平滑是指对没观察到的n元组合赋予一个概率值,以保证词序列总能通过语言模型得到一个概率值。通常使用的平滑技术有图灵估计、删除插值平滑、katz平滑和kneser-ney平滑。
[0068]
相对熵(relative entropy),又被称为kullback-leibler散度(kullback-leibler divergence)或信息散度(information divergence),是两个概率分布(probability distribution)间差异的非对称性度量。在信息理论中,相对熵等价于两个概率分布的信息熵(shannon entropy)的差值。
[0069]
相对熵是一些优化算法,例如最大期望算法(expectation-maximization algorithm,em)的损失函数。此时参与计算的一个概率分布为真实分布,另一个为理论(拟合)分布,相对熵表示使用理论分布拟合真实分布时产生的信息损耗
[0070]
l2损失(l2范数损失函数),也被称为最小平方误差(lse)。它是把目标值与估计值的差值的平方和最小化。一般回归问题会使用此损失,离群点对次损失影响较大。
[0071]
本发明通过教师网络输出的概率分布和分支输出的概率分布之间的kl散度以及分支输出的概率分布与训练数据的真实标签之间的交叉熵损失计算分支的知识蒸馏损失,通过分支输出的概率分布与主干网络输出的概率分布之间的kl散度,以及分支输出的特征与主干网络输出的特征之间的l2损失计算分支的自蒸馏损失,进而能够基于各个分支的知识蒸馏损失和自蒸馏损失计算整体损失函数,使得能够在教师网络指导的基础上,通过学生网络多层级的分支输出的概率分布和特征进行自我监督,即在教师网络蒸馏结构的基础上将学生网络作为第二个老师,从而能够通过教师网络和学生网络自身来协同优化和训练学生网络。
[0072]
具体实施过程中,最终概率分布通过如下公式计算:
[0073][0074]
式中:ys表示学生网络输出的最终概率分布;yi表示第i个分支输出的概率分布;i∈[1,n]。
[0075]
本发明通过平均集成的方式计算学生网络输出的最终概率分布,使得能够综合各个分支输出的概率分布来分析最终概率分布,从而能够进一步提高学生网络的性能。
[0076]
为了更好的说明本发明的优势,本实施例中还公开了如下实验。
[0077]
1、数据集和实验设置
[0078]
1)cifar-100(来自a.krizhevsky,learning multiple layers of features from tinyimages):该数据集由alexkrizhevsky,vinodnair和geoffreyhinton收集,共有60k张大小为32x32的彩色图像,分成100个类别,其中训练样本50k,测试样本10k。数据预处理遵循crd(来自y.tian,d.krishnan,p.isola,contrastive representation distillation)的数据集处理方法,将训练集图像各边填充4个像素,再随机裁剪为32x32,同时以0.5的概率进行随机水平翻转。测试时,采用原始图像进行评估。实验使用sgd优化,将权重衰减和动量分别设置为0.0001和0.9。batchsize设置为128,初始学习率为0.1,在epoch为150、180、210分别降低为原来的0.1倍,在240轮结束训练。
[0079]
2)tiny-imagenet:作为大规模图像分类数据集imagenet(来自j.deng,w.dong,r.socher,l.-j.li,k.li,l.fei-fei,imagenet:a large-scale hierarchical image database)的一个子集,由斯坦福大学2016年发布。共有120k张大小为64x64的彩色图像,分成200个类别,其中训练样本100k张,验证集、测试集各10k。实验仅采用简单的随机水平翻转进行预处理,以原图大小进行训练和测试。优化方式及超参数设置遵循cifar数据集。
[0080]
2、对比基准方法
[0081]
实验分别选用经典的resnet(来自k.he,x.zhang,s.ren,j.sun,deep residual learning forimage recognition)和vgg(来自j.kim,s.park,n.kwak,paraphrasing complex network:network compression via factor transfer)作为主干网络。为了融合教师网络和学生网络自身不同层次知识,我们在常规的教师指导下构造了多级输出的学生网络。方便起见,在特征空间分辨率下降的块间插入三个独立分类器分支,每一分支包含了瓶颈层和全连接层,其中瓶颈层保证了输出特征图大小保持一致,同时减轻浅层分类器之间影响。
[0082]
与zhang el al.(来自l.zhang,j.song,a.gao,j.chen,c.bao,k.ma,be yourown teacher:improve the performance of convolutional neuralnetworks via self distillation)不同,我们多个分支网络的全连接层采用共享权重,降低模型参数量。
[0083]
表1显示了学生网络每个分支在cifar100上的表现,我们发现,由于网络深度不同,捕获的语义特征也不同,深层分类器较浅层拥有更高的分类精度。测试时,我们使用了一种平均集成方法,平衡多出口的分类差异,实验结果表明,我们最终的测试准确率对比基准值均有4%-7%的提升。另外,我们发现,基于师生协同的知识蒸馏方法让模型浅层出口的分类精度就已经能接近或超越整个模型的最终精度。
[0084]
表1师生协同知识蒸馏方法与基准方法的分类准确率对比(%)
[0085][0086]
3、对比知识蒸馏方法
[0087]
为了表明本发明提出的师生联合蒸馏方法的有效性和鲁棒性,我们选用了五种不同的师生架构,其中包含了同构和异构模型,并分别对比了一些主流的知识蒸馏方法。大多实验方法遵循原作者开源代码实现,少数方法按照tian et al.(来自y.tian,d.krishnan,p.isola,contrastive representation distillation)的复现,在cifar-100和tiny-imagenet两个数据集进行了实验。以分类准确率和参数量为评价指标,分类结果如表2,3所示。模型参数量如表4所示。由于我们在学生网络上构建了多出口网络,导致参数量略高于传统kd算法,但与教师网络仍有较大差距,也能达到较好的模型压缩效果。而且,从分类精度上看,我们方法对比一些优秀的蒸馏方法,学生网络均有1%-3%的提升。
[0088]
表2 cifar100上师生协同知识蒸馏方法与知识蒸馏方法的分类准确率对比(%)
[0089][0090]
其中,kd来自g.hinton,o.vinyals,j.dean,distilling the knowledge in aneural network;
[0091]
fit来自a.romero,n.ballas,s.e.kahou,a.chassang,c.gatta,y.bengio,fitnets:hints for thin deep nets;
[0092]
at来自s.zagoruyko,n.komodakis,paying more attention to attention:improving the performance of convolutional neural networks via attention transfer;
[0093]
sp来自f.tung,g.mori,similarity-preserving knowledge distillation;
[0094]
cc来自b.peng,x.jin,j.liu,d.li,y.wu,y.liu,s.zhou,z.zhang,correlation congruence for knowledge distillation;
[0095]
vid来自s.ahn,s.x.hu,a.damianou,n.d.lawrence,z.dai,variational information distillation for knowledge transfer;
[0096]
rkd来自w.park,d.kim,y.lu,m.cho,relational knowledge distillation;
[0097]
pkt来自n.passalis,a.tefas,learning deep representations with probabilistic knowledge transfer;
[0098]
ab来自b.heo,m.lee,s.yun,j.y.choi,knowledge transfer via distillation of activation boundaries formed by hidden neurons;
[0099]
ft来自j.kim,s.park,n.kwak,paraphrasing complex network:network compression via factor transfer;
[0100]
nst来自z.huang,n.wang,like what you like:knowledge distill vianeuron selectivity transfer;
[0101]
crd来自y.tian,d.krishnan,p.isola,contrastive representation distillation。
[0102]
表3 tiny-imanet上师生协同知识蒸馏方法与知识蒸馏方法的分类准确率对比(%)
[0103][0104]
表4师生模型参数量对比(m)
[0105]
modelparametersresnet15258.348resnet5037.812resnet3421.798resnet1812.334resnet105.859vgg139.923vgg85.383
[0106]
4、对比多出口网络(multi-exit net)
[0107]
无教师自蒸馏模型通常是多出口结构,本发明的学生网络也可以看作一种基于知识蒸馏的多出口结构,与过去zhang et al.提出的多分类器网络主要区别在于我们的每个分类器都接受来自教师网络的监督,而不是仅是深层分类器的监督,deeply supervised net(dsn)(来自c.-y.lee,s.xie,p.gallagher,z.zhang,z.tu,deeply supervised nets)则是用真实标签对中间层加以约束,通过减轻梯度爆炸或消失来提高分类精度。为了验证提出的方法的有效性,实验对比了这两种方法,选用resnet152作为教师网络,分别用resnet18和resnet50作为多出口学生主干网络。实验结果如表5所示,无论是浅层分类器还
是模型最终的输出,本发明基于师生协同蒸馏的多出口学生网络都表现出优越的性能。可以发现,知识蒸馏使多出口网络去匹配一个额外的教师网络知识是有效的,每个分类器捕获了更多的视图特征。
[0108]
表5提出的方法对比其他多出口网络优化方法(%)
[0109][0110]
其中,dsn(深度监督网络)来自c.-y.lee,s.xie,p.gallagher,z.zhang,z.tu,deeply supervised nets;
[0111]
sd(自蒸馏)来自l.zhang,j.song,a.gao,j.chen,c.bao,k.ma,be your own teacher:improve the performance of convolutional neural networks via self distillation。
[0112]
5、实验分析
[0113]
我们对实验观察展开进一步地分析:首先通过消融实验对每一部分策略进行讨论,然后分别分析了多出口蒸馏和集成模块的有效性,最后从信息论的和特征学习的角度对我们的整体方法提供解释。
[0114]
5.1消融实验(ablation study)
[0115]
由于我们的方法是基于师生之间知识蒸馏和学生网络自蒸馏实现的,实验效果来自于知识蒸馏还是自蒸馏是有争议的。为了进一步验证我们方法的有效性,选用不同的学生网络,分别实施随机梯度下降、知识蒸馏和学生自我蒸馏三种方法进行对比,以分类准确率为评价指标。
[0116]
进一步,本发明提出的师生协同蒸馏方法融合了三个部分的监督:(i)教师网络输出logits对学生网络监督logits(t),(ii)学生网络深层的soft logits对浅层指导logits(s),(iii)学生网络浅层的特征匹配深层特征feature(s),以及最后使用了平均集成策略。为了评估每一部分的有效性,我们选用resnet152和resnet18分别作为教师和学生网络,在cifar-100上进行了消融实验。
[0117]
实验结果如表6所示。可以看出,每个策略对于分类精度都有不同程度的提升,且对比传统只用教师网络logits的知识蒸馏方法,有较大的提升,甚至优于教师网络。
[0118]
表6 cifar100上对不同策略的消融实验结果
[0119]
[0120]
5.2 multi-exits学生网络特征降维可视化
[0121]
本发明构建了基于自蒸馏的多出口学生网络,其中主干网络最深层输出可以被认为是第二老师,类似于多教师蒸馏,不同网络学到了不同的视图特征,通过知识蒸馏和自蒸馏,使学生网络匹配多个模型的特征表示知识。我们对三个分支网络和主干网络中全连接层前的高维特征进行降维可视化。如图3所示,学生网络每个出口的分类效果显著,浅层的分类精度甚至接近深层的分类性能。
[0122]
5.3平均集成及敏感度分析
[0123]
这一部分我们讨论了多出口集成的有效性以及集成的出口数量对实验的影响。在学生网络中,我们构造了多个输出通道,每个输出通道都是一个独立的分类网络。在“多视图”数据中,每个数据类包含了多种视图特征,不同的网络往往学到了不同的视图特征,通过集成能有效融合多个模型学到的不同特征信息。同时,由于网络之间的差异可能较浅的网络容易过拟合或陷入局部最优,通过集成能有效减小类别概率间的方差,形成一个强分类器。我们的实验分别在cifar100和tiny-imagenet数据集进行,以及使用不同师生架构下验证了集成策略的有效性,进一步我们还探索了集成出口的数量对分类的精度的影响,结果表明,在一定范围内,集成网络出口数量越多能提升网络最终的性能。
[0124]
5.4师生联合蒸馏
[0125]
最后,从信息论和特征学习的角度分析基于师生协同的知识蒸馏方法性。回顾知识蒸馏,它的有效性很大程度来自于教师网络的软标签信息。信息量大小仅与概率有关,软标签比起one-hot标签信息熵更大,隐式地包含了类别之间的信息,丰富的信息让学生网络获得收益。这也为我们的方法提供了一种解释,我们在常规的师生架构中,让学生网络不仅匹配教师网络的软标签信息,而且学习学生网络的自身输出的软标签信息,我们知道学生网络对于教师网络而言,通常结构简单、性能较差,这就导致学生网络输出的类别概率不确定性更大,信息量也更大。因此我们联合学生和教师的指导,让类别信息得到进一步丰富,学生网络也从中受益。
[0126]
从特征学习的角度看,由于学习的随机性,初始化不同的模型学到的视图特征不同。另一方面,输入数据经过同一网络的不同层次卷积核,也依次抽取了低维和高维特征视图。我们的协同蒸馏方法,将这二者结合起来,学生网络试图学习教师网络的学习的视图,同时学生网络自己从训练数据中学习新的视图。教师的指导起到了正则化的作用,限制了学生网络在教师网络学习的视图附近搜索新的视图,所以学生的效果更好。多出口网络也可以用多视图的角度来解释,每个出口的所构建的模型学到的就是训练数据的一个新的视图特征,所以多个出口就学到了多个视图,并且这些视图还是相关的,最后通过集成形成了一个学到了多种视图特征的强分类器。
[0127]
6、结论
[0128]
在本发明中,我们提出了一种的师生协同蒸馏方法。与传统知识蒸馏方法不同,我们引入知识蒸馏和自蒸馏相融合的思想,让模型从教师网络和自身学习新的视图特征知识。通过大量的实验和可视化分析,验证了我们提出的方法及每个组件的有效性,并表明该方法对知识蒸馏和多出口网络均有重要的指导意义。
[0129]
最后需要说明的是,以上实施例仅用以说明本发明的技术方案而非限制技术方案,本领域的普通技术人员应当理解,那些对本发明的技术方案进行修改或者等同替换,而
不脱离本技术方案的宗旨和范围,均应涵盖在本发明的权利要求范围当中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1