语句相似度确定方法、装置、计算机设备和存储介质与流程
1.本发明涉及计算机应用技术领域,特别是涉及语句相似度确定方 法、装置、计算机设备和存储介质。
背景技术:
2.知识图谱(knowledge graph),在图书情报界称为知识域可视化或 知识领域映射地图,是显示知识发展进程与结构关系的一系列各种不 同的图形,用可视化技术描述知识资源及其载体,挖掘、分析、构建、 绘制和显示知识及它们之间的相互联系。
3.传统关系相似度计算主要通过词频统计实现,缺少泛化能力,且 无法计算语义级别的相似度,比如“住持”和“方丈”。因此需要一种高 效的关系相似度计算模型。
技术实现要素:
4.本技术提供了一种语句相似度确定方法、装置、计算机设备和存 储介质。
5.第一方面提供了一种语句相似度确定方法,包括:
6.接收用户问题;
7.将所述用户问题输入至实体识别模型得到所述用户问题中的实 体信息;
8.将所述用户问题输入至属性识别模型得到所述用户问题中的属 性信息;
9.在预设的知识图谱中检索与所述属性信息相关的标准属性信息;
10.根据所述实体信息和所述标准属性信息,在所述知识图谱中确定 候选语句;
11.针对每个候选语句,采用多个不同的相似度算法分别计算所述候 选语句与所述用户问题的相似度,得到所述候选语句对应的多个的相 似度结果;
12.将每个候选语句的多个所述相似度结果进行融合,得到所述候选 语句与所述用户问题的最终相似度结果。
13.在一些实施例中,在得到所述候选语句与所述用户问题的最终相 似度结果之后,还包括:
14.确定所述用户问题的所有候选语句中满足预设条件的命中语句, 所述预设条件为所述命中语句的最终相似度结果大于其他候选语句 的最终相似度结果;
15.在所述知识图谱内检索出所述命中问题对应的命中答案,将所述 命中答案作为所述用户问题的答案。
16.在一些实施例中,所述接收用户问题,识别所述用户问题的实体 信息和属性信息,包括:
17.所述用户问题输入预配置的bert-bilstm-crf模型中,得到所 述用户问题中的实体信息;其中,所述bert-bilstm-crf模型包括: bert预训练模型层、bilstm网络层以及crf推理层,所述bert 预训练模型层用于将每个字符进行编码得到对应字符的字向量;所述 bilstm网络层用于将所述字向量组成的序列双向编码获取新的特 征向量;所述crf推理层用于基于所述新的特征向量输出概率最大 的实体信息。
18.在一些实施例中,对所述用户问题进行分词处理得到词序列,通 过word embedding获取每个词的词向量w1,w2
…
,wn;
19.将词向量w1,w2
…
,wn映射成对应的概念词向量e1,e2
…
, en;
20.将概念词向量e1,e2
…
,en输入到属性识别模型的bi-lstm层, 并使用实体层的表征向量entity进行attention操作得到第二隐藏向 量h1,h2
…
,hn;
21.将第二隐藏向量h1,h2
…
,hn再次输入到属性识别模型的 bi-lstm层,并使用短语层的表征向量phrase进行attention操作, 并对输出的第三隐藏向量进行加权求和,得到表征向量vector;
22.将表征向量vector输入到属性识别模型的全连接层并进行 softmax操作,得到所述用户问题中的属性信息。
23.在一些实施例中,所述根据所述实体信息和所述标准属性信息, 在所述知识图谱中确定候选语句,包括:
24.提取所述用户问题中的实体和第一属性词;
25.根据所述用户问题中的实体,在知识图谱中查找与所述实体匹配 的多个第二属性词;
26.计算所述第一属性词和多个所述第二属性词之间的相关度,并根 据相关度对多个所述第二属性词进行筛选,确定第三属性词;
27.如果所述第三属性词为多个,统计每个所述第三属性词在所述知 识图谱中出现的次数,并将出现次数最多的第三属性词作为标准属性;
28.将所述实体信息视为主语或宾语,与所述标准属性相结合,从所 述知识图谱中检索并找到对应的三元组,根据所述三元组确定候选语 句。
29.在一些实施例中,所述采用多个不同的相似度算法分别计算所述 候选语句与所述用户问题的相似度,得到所述候选语句对应的多个的 相似度结果,包括:
30.采用bert算法计算所述用户问题与候选语句的第一相似度;
31.采用bm25算法计算所述用户问题与候选语句的第二相似度;
32.采用fasttext算法计算所述用户问题与候选语句的第三相似度。
33.在一些实施例中,所述将每个候选语句的多个所述相似度结果进 行融合,得到所述候选语句与所述用户问题的最终相似度结果,包括:
34.将多个所述相似度结果根据bagging策略进行投票,得到最终结 果信息。
35.第二方面提供了一种语句相似度确定装置,包括:
36.接收单元,用于接收用户问题;
37.实体识别,用于利用实体识别模型得到所述用户问题中的实体信 息;
38.属性获取,用于利用属性识别模型得到所述用户问题中的属性信 息;
39.标准化单元,用于在预设的知识图谱中检索与所述属性信息相关 的标准属性信息;
40.候选语句单元,用于根据所述实体信息和所述标准属性信息,在 所述知识图谱中确定候选语句;
41.相似计算单元,用于采用多个不同的相似度算法,分别计算所述 用户问题与候选语句的相似度,得到各相似度算法对应的相似度结果;
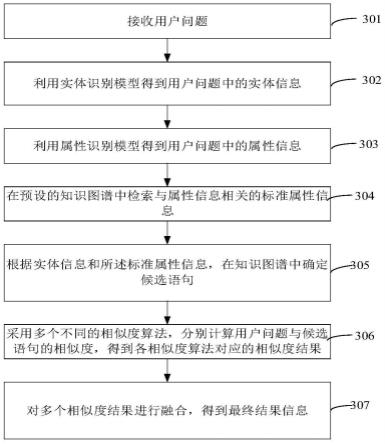
42.结果输出单元,用于对所述多个相似度结果进行融合,得到最终 结果信息。
43.第三方面提供了一种计算机设备,包括存储器和处理器,所述存 储器中存储有计算机可读指令,所述计算机可读指令被所述处理器执 行时,使得所述处理器执行上述所述语句相似度确定方法的步骤。
44.第四方面提供了一种存储有计算机可读指令的存储介质,所述计 算机可读指令被一个或多个处理器执行时,使得一个或多个处理器执 行上述所述语句相似度确定方法的步骤。
45.上述语句相似度确定方法、装置、计算机设备和存储介质,接收 用户问题;利用实体识别模型得到所述用户问题中的实体信息;利用 属性识别模型得到所述用户问题中的属性信息;在预设的知识图谱中 检索与所述属性信息相关的标准属性信息;根据所述实体信息和所述 标准属性信息,在所述知识图谱中确定候选语句;采用多个不同的相 似度算法,分别计算所述用户问题与候选语句的相似度,得到各相似 度算法对应的相似度结果;对所述多个相似度结果进行融合,得到最 终结果信息。因此,采用多模型并行的方法同时计算不同维度相似度, 整合所有相似度模型结果给出最终相似度计算结果,更全面的衡量关 系相似度。
附图说明
46.图1为一个实施例中提供的语句相似度确定方法的实施环境图;
47.图2为一个实施例中计算机设备的内部结构框图;
48.图3为一个实施例中语句相似度确定方法的流程图;
49.图4为一个实施例中语句相似度确定装置的结构框图。
具体实施方式
50.为了使本发明的目的、技术方案及优点更加清楚明白,以下结合 附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描 述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
51.可以理解,本技术所使用的术语“第一”、“第二”等可在本文中用 于描述各种元件,但这些元件不受这些术语限制。这些术语仅用于将 第一个元件与另一个元件区分。
52.图1为一个实施例中提供的语句相似度确定方法的实施环境图, 如图1所示,在该实施环境中,可以包括计算机设备110以及终端 120。
53.计算机设备110为数据提供方设备,计算机设备110具有接口, 例如可以为接口是api(application programming interface,即应用程 序接口)。终端120为理赔请求输入方,具有接口配置界面,当语句 相似度确定时,用户可以通过终端120输入请求,以使计算机设备 110进行接下来的语句相似度确定。
54.需要说明的是,终端120以及计算机设备110可为智能手机、平 板电脑、笔记本电脑、台式计算机等,但并不局限于此。计算机设备 110以及终端110可以通过蓝牙、usb(universal serial bus,通用串 行总线)或者其他通讯连接方式进行连接,本发明在此不做限制。
55.图2为一个实施例中计算机设备的内部结构示意图。如图2所示, 该计算机设备可
以包括通过系统总线连接的处理器、存储介质、存储 器和网络api接口。其中,该计算机设备的存储介质存储有操作系统、 数据库和计算机可读指令,数据库中可存储有控件信息序列,该计算 机可读指令被处理器执行时,可使得处理器实现一种语句相似度确定 方法。该计算机设备的处理器用于提供计算和控制能力,支撑整个计 算机设备的运行。该计算机设备的存储器中可存储有计算机可读指令, 该计算机可读指令被处理器执行时,可使得处理器执行一种语句相似 度确定方法。该计算机设备的网络api接口用于与终端连接通信。本 领域技术人员可以理解,图2中示出的结构,仅仅是与本技术方案相 关的部分结构的框图,并不构成对本技术方案所应用于其上的计算机 设备的限定,具体的计算机设备可以包括比图中所示更多或更少的部 件,或者组合某些部件,或者具有不同的部件布置。
56.如图3所示,在一个实施例中,提出了一种语句相似度确定方法, 该语句相似度确定方法可以应用于上述的计算机设备110中,具体可 以包括以下步骤:
57.步骤101、接收用户问题;
58.该实施中,用户问题可以是用户问的佛学领域的问题。
59.步骤102、将用户问题输入至实体识别模型得到用户问题中的实 体信息;
60.该步骤中,实体识别模型为bert-bilstm-crf模型,上述步骤 102可以包括:将用户问题输入预配置的bert-bilstm-crf模型中, 得到用户问题的命名实体;其中,bert-bilstm-crf模型包括: bert预训练模型层、bilstm网络层以及crf推理层,bert预训 练模型层用于将每个字符进行编码得到对应字符的字向量;bilstm 网络层用于将字向量组成的序列双向编码获取新的特征向量;crf 推理层用于基于新的特征向量输出概率最大的命名实体。
61.本实施例基于bert模型构建的命名实体识别模型,很好的解决 了标注数据不足以及实体边界模糊时实体识别困难,精度不高的问题, 提高实体识别模型的性能和识别准确率。
62.举例说明,实体识别模型输入:王小小的哥哥是谁?转成模型的 word序列也就是(王,小,小,的,哥,哥,是,谁,?),经过bert 层编码和bi-lstm层后,实体识别结果输出:(b,i,i,o,o,o, o,o,o),其中b表示实体的开始word,i表示实体的中间或结束 word,o表示不是实体的word。模型的输出也就是“王小小”被预测 为实体部分。
63.步骤103、将用户问题输入至属性识别模型得到用户问题中的属 性信息;
64.在一些实施例中,上述步骤103可以包括:
65.步骤1031、对用户问题进行分词处理得到词序列,通过word embedding获取每个词的词向量w1,w2
…
,wn;
66.步骤1032、将词向量w1,w2
…
,wn映射成对应的概念词向量 e1,e2
…
,en;
67.步骤1033、将概念词向量e1,e2
…
,en输入到属性识别模型的 bi-lstm层,并使用实体层的表征向量entity进行attention操作得 到第二隐藏向量h1,h2
…
,hn;
68.步骤1034、将第二隐藏向量h1,h2
…
,hn再次输入到属性识别 模型的bi-lstm层,并使用短语层的表征向量phrase进行attention 操作,并对输出的第三隐藏向量进行加权求和,得到表征向量vector;
69.步骤1035、将表征向量vector输入到属性识别模型的全连接层 并进行softmax操作,得到用户问题中的属性信息。
70.首先对用户的问题语句进行分词得到句子的 词序列,通过wordembedding获取每个词的词向量w1,w2..., wn。然后经过实体概念映射操作映射成对应的概念的词向量e1,e2..., en,词向量携带了单词语义信息,而且通过实体的概念映射可以获取 整个问题句子的更深层的语义。将概念化的词向量输入bi-lstm层, 并使用实体层的表征向量entity进行attention操作得到隐藏向量h1, h2...,hn。bi-lstm可以很好的学习到对应词前后的语义信息,使 用实体层信息进行attention操作可以很好地将实体层的语义信息融 入到模型中。然后将上一层得到的序列表征向量再次输入到bi-lstm 层,并使用短语层的表征向量phrase进行attention操作,做一个近 似于加权求和的操作,得到表征向量vector。这里学习到表征向量 vector很好的融合了实体层语义、短语层语义、问题层语义。最后, 将学习到的表征向量vector经过全连接层以及softmax操作,得到句 子(用户问题)中对应到知识图谱的关系(属性)类别。其中实体层entity、 短语层phrase的处理如下:
71.实体层语义entity:实体是自然语言的基本单位之一,基于知识 图谱的实体语义理解为上层语义计算,特别是问题中的实体语义。本 发明关于实体层的语义解析这里使用了语义社团搜索模型,获取实体 层的语义信息。
72.短语层语义phrase:短文本是自然语言的最常见形式之一,起到 对实体和更复杂文本单元(如问句)的承接作用,短文本已经有了基本 的语法结构和上下文的语义信息。这里主要是使用动词模板用来细粒 度的语义表示,并综合使用了上下文信息进行实体的概念化。
73.步骤104、在预设的知识图谱中检索与属性信息相关的标准属性 信息;
74.可以理解的是,知识图谱中的属性词也就是同一个属性或关系可 能有多个表达方式,其中,第一属性词和多个第二属性词之间的相 关度计算方法可以采用将属性词转换为语义向量并进行语义关联性 分析,生成多个第二属性词和第一属性词之间相关度的排序和/或相 关度,然后根据预设相关度阈值和/或相关度排序筛选策略,确定出 一个或多个第三属性词。如果存在多个第三属性词,统计每个第三属 性词在知识图谱中出现的次数,次数最多的作为标准属性,即语义相 同的属性词,采用最常用的属性词作为标准谓词,确定为标准属性。
75.步骤105、根据实体信息和标准属性信息,在知识图谱中确定候 选语句;
76.在一些实施例中,上述步骤104可以包括:
77.步骤1041、提取用户问题中的实体和第一属性词;
78.步骤1042、根据用户问题中的实体,在知识图谱中查找与该实 体匹配的多个第二属性词;
79.步骤1043、计算第一属性词和多个第二属性词之间的相关度, 并根据相关度对多个第二属性词进行筛选,确定出一个或多个第三属 性词;
80.步骤1044、如果第三属性词为多个,统计每个第三属性词在知 识图谱中出现的次数,并将出现次数最多的第三属性词作为标准属性;
81.步骤1045、将实体信息视为主语或宾语,与标准属性相结合, 从知识图谱中检索并找到对应的三元组,根据三元组确定候选语句。
82.在知识图谱中,知识数据是以(s、p、o)三元组形式保存的,对 应表示为实体、属性(关系)、属性值(关系类别),其中实体和其对应 的属性值可能都是以实体的形式表示的。
83.步骤106、针对每个候选语句,采用多个不同的相似度算法分别 计算候选语句与用户问题的相似度,得到候选语句对应的多个的相似 度结果;
84.可以理解的是,在知识图谱中确定的候选语句可能不止一个,当 候选语句是多个的时候,则需要分别计算每个候选语句与用户问题之 间的相似度,又每个候选语句与用户问题的相似度的计算是采用多个 不同的相似度算法计算的,故每个候选问题对应多个(相似度算法的 个数)相似度结果。
85.在一些实施例中,对于每一组数据对,都使用bert,bm25,fasttext 模型计算相似度,这些模型输入输出形式相同,均是输入一组数据对, 输入改数据对对应的相似度,相似度结果在0到1之间,但相似度计 算过程各有侧重,bert模型侧重语义角度相似度,bm25侧重字符串 角度相似度,fasttext可以用更细粒度的切分形式解决输入数据不在 模型词表中收录的情况,采用三种模型可以从三种不同的维度计算相 似度结果。
86.采用多种相似度算法计算用户问题与候选语句之间的相似度,根 据计算得到的相似度确定用户问题的目标答案,从多个维度计算用户 问题与每个候选问题之间的相似度,根据计算得到的相似度确定目标 问题的目标答案,提高了目标问题的目标答案的准确率。
87.步骤107、将每个候选语句的多个相似度结果进行融合,得到候 选语句与用户问题的最终相似度结果。
88.可以理解的是,将每个候选问题对应多个相似度结果进行融合后 得到的结果才是该候选语句与用户问题的最终相似度结果。
89.该步骤中,将获取的相似度结果根据bagging策略进行投票,得 到最终结果信息。
90.bagging(装袋)又叫自助聚集,是一种根据均匀概率分布从数据中 重复抽样(有放回)的技术。每个抽样生成的自助样本集上,训练一个 基分类器;对训练过的分类器进行投票,将测试样本指派到得票最高 的类中。每个自助样本集都和原数据一样大。有放回抽样,一些样本 可能在同一训练集中出现多次,一些可能被忽略。
91.在一些实施例中,在得到候选语句与用户问题的最终相似度结果 之后,还包括:
92.步骤108、确定用户问题的所有候选语句中满足预设条件的命中 语句,预设条件为命中语句的最终相似度结果大于其他候选语句的最 终相似度结果;
93.该步骤中,在候选语句为多个时,每个候选语句对应一个最终候 选相似度结果,需要从多个候选语句中选择出与用户问题最相似的语 句,可以是将用户问题的所有候选语句按照最终相似度结果按照由小 到大或由小到大排序,选择排在队列末尾或者首位的候选语句为命中 语句即可。
94.步骤109、在知识图谱内检索出命中问题对应的命中答案,将命 中答案作为用户问题的答案。
95.如图4所示,在一个实施例中,提供了一种语句相似度确定装置, 该语句相似度确定装置可以集成于上述的计算机设备110中,具体可 以包括:
96.接收单元411,用于接收用户问题;
97.实体识别412,用于将所述用户问题输入至实体识别模型得到用 户问题中的实体信息;
98.属性获取413,用于将所述用户问题输入至属性识别模型得到用 户问题中的属性
信息;
99.标准化单元414,用于在预设的知识图谱中检索与属性信息相关 的标准属性信息;
100.候选语句单元415,用于根据实体信息和标准属性信息,在知识 图谱中确定候选语句;
101.相似计算单元416,用于针对每个候选语句,采用多个不同的相 似度算法分别计算所述候选语句与所述用户问题的相似度,得到所述 候选语句对应的多个的相似度结果;
102.结果输出单元417,用于将每个候选语句的多个所述相似度结果 进行融合,得到所述候选语句与所述用户问题的最终相似度结果。
103.在一个实施例中,提出了一种计算机设备,计算机设备可以包括 存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序, 处理器执行计算机程序时实现以下步骤:接收用户问题;将所述用户 问题输入至实体识别模型得到所述用户问题中的实体信息;将所述用 户问题输入至属性识别模型得到所述用户问题中的属性信息;在预设 的知识图谱中检索与所述属性信息相关的标准属性信息;根据所述实 体信息和所述标准属性信息,在所述知识图谱中确定候选语句;针对 每个候选语句,采用多个不同的相似度算法分别计算所述候选语句与 所述用户问题的相似度,得到所述候选语句对应的多个的相似度结果; 将每个候选语句的多个所述相似度结果进行融合,得到所述候选语句 与所述用户问题的最终相似度结果。
104.在一个实施例中,提出了一种存储有计算机可读指令的存储介质, 该计算机可读指令被一个或多个处理器执行时,使得一个或多个处理 器执行以下步骤:接收用户问题;将所述用户问题输入至实体识别模 型得到所述用户问题中的实体信息;将所述用户问题输入至属性识别 模型得到所述用户问题中的属性信息;在预设的知识图谱中检索与所 述属性信息相关的标准属性信息;根据所述实体信息和所述标准属性 信息,在所述知识图谱中确定候选语句;针对每个候选语句,采用多 个不同的相似度算法分别计算所述候选语句与所述用户问题的相似 度,得到所述候选语句对应的多个的相似度结果;将每个候选语句的 多个所述相似度结果进行融合,得到所述候选语句与所述用户问题的 最终相似度结果。
105.本领域普通技术人员可以理解实现上述实施例方法中的全部或 部分流程,是可以通过计算机程序来指令相关的硬件来完成,该计算 机程序可存储于一计算机可读取存储介质中,该程序在执行时,可包 括如上述各方法的实施例的流程。其中,前述的存储介质可为磁碟、 光盘、只读存储记忆体(read-only memory,rom)等非易失性存 储介质,或随机存储记忆体(random access memory,ram)等。
106.以上实施例的各技术特征可以进行任意的组合,为使描述简洁, 未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而, 只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的 范围。
107.以上实施例仅表达了本发明的几种实施方式,其描述较为具体和 详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的 是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下, 还可以做出若干变形和改进,这些都属于本发明的保护范围。因此, 本发明专利的保护范围应以所附权利要求为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1