一种基于自编码器的自动调制识别扩增数据维度的方法
1.本发明涉及一种数据维度扩增方法,尤其涉及一种基于自编码器的自动调制识别扩增数据维度的方法。
背景技术:
2.随着无线通信的高速发展,无线通信服务业务出现了飞速增长,导致频谱资源愈发紧缺;无线设备由于软件无线电的快速发展而变得更加廉价,导致非法用户恶意占用授权频段的事件时有发生,因此,为了保障无线通信系统的高效利用与运行安全,无线电监测显得至关重要。而无线通信标准和无线信号的多样性使得无线通信环境越来越复杂,给无线电频谱监测带来了极大的挑战,鉴于此,无线信号调制方式识别技术被引入,用于通过识别指定频带内的信号的调制方式,提高频谱检测能力。
3.应用深度学习方法自动识别接收到的无线电信号的调制方式是近年来的一个研究热点,其性能超越了传统的基于似然理论和基于特征的方法,其中一些代表性的深度学习方法被提出,性能也被证明优于传统的方法。o’shea,timothy j.,johnathan corgan,and t.charles clancy."convolutional radio modulation recognition networks."international conference on engineering applications of neural networks.springer,cham,2016中提出使用卷积神经网络(cnn)实现自动调制识别,以原始接收数据(in-phase/quadrature形式)作为输入,它的识别准确率能超越传统方法,但模型的参数量较大。rajendran,sreeraj,et al."deep learning models for wireless signal classification with distributed low-cost spectrum sensors."ieee transactions on cognitive communications and networking 4.3(2018):433-445采用长短期记忆神经网络(lstm)来搭建自动调制识别模型,进一步提升了识别准确率,但识别准确率还有进一步提升的空间。hong,dehua,zilong zhang,and xiaodong xu."automatic modulation classification using recurrent neural networks."2017 3rd ieee international conference on computer and communications(iccc).ieee,2017提出了一种与lstm类似的模型,它将lstm网络用门控循环单位(gru)来代替,识别准确率与lstm模型相近,但其模型复杂度有所降低。x.liu,d.yang and a.e.gamal,"deep neural network architectures for modulation classification,"2017 51st asilomar conference on signals,systems,and computers,2017,pp.915-919,doi:10.1109/acssc.2017.8335483中提出了一种采用cnn和lstm层结合的混合模型,提取信号中具有的时间和空间特征,由此进行调制方式的识别,其准确率超过了cnn模型,但是未达到目前的最高识别准确率。xu,jialang,et al."a spatiotemporal multi-channel learning framework for automatic modulation recognition."ieee wireless communications letters 9.10(2020):1629-1632中提出了一种时空多通道学习模型,利用来自i(in-phase)通道和q(quadrature)通道的互补信息,并提取信号中的空间和时间特征,来实现自动调制识别,是目前为止自动调制识别领域识别准确率最高的模型,但是准确率仍有进一步提升的空间。
4.通常来说,训练一个性能良好的深度学习模型通常需要大量的数据,训练数据不足会导致严重的过拟合问题,降低分类精度,为提升数据集的数据量较小情况下的分类精度,数据增强方法被应用于自动调制识别领域中,以提高深度学习模型的鲁棒性和识别准确率。l.huang,w.pan,y.zhang,l.qian,n.gao and y.wu,"data augmentation for deep learning-based radio modulation classification,"in ieee access,vol.8,pp.1498-1506,2020,doi:10.1109/access.2019.2960775中提出了一种对原始数据进行旋转、翻转和加入高斯噪声的数据增强方法,能够提升模型的识别准确率。数据增强方法是通过对原始数据进行处理,获得新的数据,并和原始数据一起输入网络进行训练,因此增大了数据量,会使得网络的训练时间明显变长。
5.目前基于深度学习的自动调制模型尚未充分利用同相/正交(in-phase/quadrature,以下简称i/q)通道中的交互信息,识别准确率可通过提升i/q通道间的信息交互进一步提高的问题。目前的基于深度学习的调试识别模型大都直接采用i/q数据作为模型输入,使得模型对i/q通道间的交互信息利用不足,由此准确率并未达到最高水平。现有的一些数据增强方法能够给深度学习模型带来识别准确率上的提升,但它们只是对数据量进行了扩充,会使得网络的训练开销明显增大,也并为考虑提升i/q通道间的信息交互。
技术实现要素:
6.本发明提供一种基于自编码器的自动调制识别扩增数据维度的方法,针对背景技术中提到的问题,目的在于提出了一种自编码器模型,来增强输入数据i/q通道间的信息交互,将自编码器模型中间层输出的交互信息与i/q通道数据进行拼接,再一起输入深度学习模型进行训练,能够在训练开销基本不变的情况下提升现有基于深度学习的调试识别模型的识别准确率。
7.本发明解决上述技术问题提供以下技术方案:
8.一种基于自编码器的自动调制识别扩增数据维度的方法,包括以下步骤:
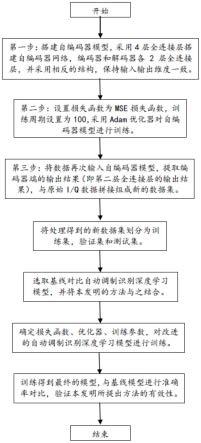
9.步骤1:搭建自编码器模型:通过rml2016.10a[7]数据集得到i/q数据;基于深度神经网络,搭建自编码器模型;将i/q数据整理为i/q数据样本,将i/q数据样本输入所述自编码器模型,每条i/q数据样本包含l个采样点,每个采样点由i通道和q通道的数据组成,即输入的数据维度为2
×
l;所述自编码器模型输入的数据维度和输出的数据维度一致,均为2
×
l;
[0010]
步骤2:训练自编码器模型:在自编码器模型中设置损失函数为最小均方误差损失函数,训练周期设置为100次,训练批大小为400个;采用adam优化器对自编码器模型进行训练;所述最小均方误差损失函数计算自编码器模型输出数据和输入数据间的误差;所述自编码器模型的训练目标是最小化最小均方误差损失函数,最终训练得到输出与输入最接近的模型,并保存模型参数;
[0011]
步骤3:提取数据:将步骤2中自编码器模型输入的数据全部重新输入自编码器模型,这些数据只通过自编码器模型前两层得到维度为l的数据,并提取自编码器模型的第二层全连接层输出的维度为l的数据,作为i/q通道间的交互信息;
[0012]
通过矩阵维度变换操作将所述第二层全连接层输出的数据维度为l的数据转换为维度为1
×
l的数据,再与i/q数据进行拼接,得到维度为3
×
l的增强输入数据。
[0013]
作为优选,所述自编码器模型包括依次连接的编码器、解码器和调整器;所述编码器和解码器均包含两层全连接层;
[0014]
所述编码器包括第一层全连接层和第二层全连接层,所述第一层全连接层包含2l个节点,所述第二层全连接层包含l个节点;
[0015]
所述解码器包含第三层全连接层和第四层全连接层,所述第三层全连接层包含l个节点,所述第四层全连接层包含2l个节点;
[0016]
所述第一层全连接层、第二层全连接层、第三层全连接层和第四层全连接层均采用线性函数作为激活函数;
[0017]
所述调整器将解码器输出的数据维度由2l转换为2
×
l。
[0018]
作为优选,还包括以下步骤:
[0019]
步骤4:将经过所述步骤3处理得到的增强输入数据划分为训练集、验证集和测试集;
[0020]
步骤5:选取基线自动调制识别模型进行准确率对比,并将本发明的方法与基线自动调制识别模型结合作为改进模型,改进模型的输入采用所述步骤3得到的增强输入数据,基线自动调制识别模型采用所述步骤1的i/q数据;
[0021]
步骤6:设置基线自动调制识别模型和改进模型训练的损失函数、优化器、训练的周期和批大小、初始学习率,对基线自动调制识别模型和改进模型进行训练;
[0022]
步骤7:将改进模型和基线自动调制识别模型的输出结果进行准确率对比,验证本发明所提出方法的有效性。
[0023]
作为优选,所述步骤4具体包括:将所述增强输入数据按6:2:2的比例划分为训练集、验证集和测试集。
[0024]
作为优选,所述步骤6具体包括:以分类交叉熵作为损失函数和采用adam方法作为优化器,初始学习率从0.001开始,在实验中批大小设置为400个,如果模型的验证损失训练过程中的5个周期内不减少,学习率将减半,如果验证损失在50个周期内保持稳定,模型的训练则结束,得到最终的训练好的模型。
[0025]
作为优选,所述步骤5所使用的基线自动调制识别模型包含卷积神经网络模型(cnn),门控循环单元模型(gru),多通道卷积长短期深度神经网络模型(mcldnn),卷积长短期深度神经网络模型(cldnn),长短期深度神经网络模型(lstm-iq);
[0026]
对每个改进模型的第一层神经网络进行参数调节,以适应增强的输入数据维度,得到改进模型,将卷积神经网络改进模型和卷积长短期深度神经网络改进模型的第一层神经网络的卷积核大小设置为2*3,使得所述步骤1的i/q数据通过基线自动调制识别模型第一层后的数据维度与增强数据通过改进模型第一层神经网络后的数据维度一样,保证基线自动调制识别模型和改进模型的后续层参数设置一致;
[0027]
将门控循环单元改进模型和长短期深度神经网络改进模型的输入层的维度参数设置为(128,3);
[0028]
将多通道卷积长短期深度神经网络改进模型的通道数增加1,由原来的i通道、q通道和i/q通道修改为i通道、q通道、增强数据通道和i/q/增强数据通道。
[0029]
综上所述,由于采用了上述技术方案,本发明的有益效果是:
[0030]
1、本发明考虑到现有自动调制识别模型对i/q通道间的交互信息利用不足,提出
了一种基于自编码器的方法来增强i/q通道数据间的信息交互。
[0031]
2、本发明能够在不增加原始数据的数据量的情况下,提升现有模型的调制识别准确率。
[0032]
3、本发明仅采用较少层数和较少参数量的全连接层搭建自编码器模型,模型收敛速度快,并不会带来过度的额外开销。
[0033]
4、本发明能够很好的应用到现有的大多数自动调制识别深度学习模型上。
[0034]
5、本发明获取了i/q通道间的信息交互,既解决了训练数据不足的问题,又提升了自动调制识别准确率。
附图说明
[0035]
图1为本发明的流程图。
[0036]
图2为本发明所提出的自编码器模型。
[0037]
图3为本发明所提出的模型在rml2016.10a数据集上的准确率对比(采用i/q数据进行实验的模型命名为:cnn,gru,mcldnn,cldnn,lstm-iq,采用增强输入数据(enhanced input)进行实验的模型命名为:cnn-enhanced,gru-enhanced,mcldnn-enhanced,cldnn-enhanced,lstm-iq-enhanced)。
具体实施方式
[0038]
为了使本发明实现的技术手段、特征与功效更容易被理解下面结合具体实施例和本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的描述。
[0039]
如图1-图1所示,本发明的最优实施例如下所述:
[0040]
参见图1所示,一种基于自编码器的自动调制识别扩增数据维度的方法,包括以下步骤:
[0041]
步骤1:搭建自编码器模型:通过rml2016.10a[7]数据集得到i/q数据;基于深度神经网络,搭建自编码器模型;将i/q数据整理为i/q数据样本,将i/q数据样本输入所述自编码器模型,每条i/q数据样本包含l个采样点,每个采样点由i通道和q通道的数据组成,即输入的数据维度为2
×
l;所述自编码器模型输入的数据维度和输出的数据维度一致,均为2
×
l;
[0042]
步骤2:训练自编码器模型:在自编码器模型中设置损失函数为最小均方误差损失函数,训练周期设置为100次,训练批大小为400个;采用adam优化器对自编码器模型进行训练;所述最小均方误差损失函数计算自编码器模型输出数据和输入数据间的误差;所述自编码器模型的训练目标是最小化最小均方误差损失函数,最终训练得到输出与输入最接近的模型,并保存模型参数;
[0043]
步骤3:提取数据:将步骤2中自编码器模型输入的数据全部重新输入自编码器模型,这些数据只通过自编码器模型前两层得到维度为l的数据,并提取自编码器模型的第二层全连接层输出的维度为l的数据,作为i/q通道间的交互信息;
[0044]
通过矩阵维度变换操作将所述第二层全连接层输出的数据维度为l的数据转换为维度为1
×
l的数据,再与i/q数据进行拼接,得到维度为3
×
l的增强输入数据。
[0045]
参见图1所示,所述自编码器模型包括依次连接的编码器、解码器和调整器;所述
编码器和解码器均包含两层全连接层;
[0046]
所述编码器包括第一层全连接层和第二层全连接层,所述第一层全连接层包含2l个节点,所述第二层全连接层包含l个节点;
[0047]
所述解码器包含第三层全连接层和第四层全连接层,所述第三层全连接层包含l个节点,所述第四层全连接层包含2l个节点;
[0048]
所述第一层全连接层、第二层全连接层、第三层全连接层和第四层全连接层均采用线性函数作为激活函数;
[0049]
所述调整器将解码器输出的数据维度由2l转换为2
×
l。
[0050]
参见图3和表1所示,还包括以下步骤:
[0051]
步骤4:将经过所述步骤3处理得到的增强输入数据划分为训练集、验证集和测试集;
[0052]
步骤5:选取基线自动调制识别模型进行准确率对比,并将本发明的方法与基线自动调制识别模型结合作为改进模型,改进模型的输入采用所述步骤3得到的增强输入数据,基线自动调制识别模型采用所述步骤1的i/q数据;
[0053]
步骤6:设置基线自动调制识别模型和改进模型训练的损失函数、优化器、训练的周期和批大小、初始学习率,对基线自动调制识别模型和改进模型进行训练;
[0054]
步骤7:将改进模型和基线自动调制识别模型的输出结果进行准确率对比,验证本发明所提出方法的有效性。
[0055]
参见图1所示,所述步骤4具体包括:将所述增强输入数据按6:2:2的比例划分为训练集、验证集和测试集。
[0056]
参见图1所示,所述步骤6具体包括:以分类交叉熵作为损失函数和采用adam方法作为优化器,初始学习率从0.001开始,在实验中批大小设置为400个,如果模型的验证损失训练过程中的5个周期内不减少,学习率将减半,如果验证损失在50个周期内保持稳定,模型的训练则结束,得到最终的训练好的模型。
[0057]
参见图3和表1所示,,所述步骤5所使用的基线自动调制识别模型包含卷积神经网络模型(cnn),门控循环单元模型(gru),多通道卷积长短期深度神经网络模型(mcldnn),卷积长短期深度神经网络模型(cldnn),长短期深度神经网络模型(lstm-iq);
[0058]
表1为本发明在rml2016.10a数据集上的最高识别准确率和平均准确率的对比
[0059][0060]
图3和表1中cnn为卷积神经网络模型,cnn-enhanced为使用增强数据的卷积神经网络改进模型;gru为门控循环单元模型,gru-enhanced为使用增强数据的门控循环单元改进模型;mcldnn为多通道卷积长短期深度神经网络模型,mcldnn-enhanced为使用增强数据
的多通道卷积长短期深度神经网络改进模型;cldnn为卷积长短期深度神经网络模型,cldnn-enhanced为使用增强数据的卷积长短期深度神经网络改进模型;lstm-iq为长短期深度神经网络模型,lstm-iq-enhanced为使用增强数据的长短期深度神经网络改进模型;snr为信噪比。
[0061]
对每个改进模型的第一层神经网络进行参数调节,以适应增强的输入数据维度,得到改进模型,将卷积神经网络改进模型和卷积长短期深度神经网络改进模型的第一层神经网络的卷积核大小设置为2*3,使得所述步骤1的i/q数据通过基线自动调制识别模型第一层后的数据维度与增强数据通过改进模型第一层神经网络后的数据维度一样,保证基线自动调制识别模型和改进模型的后续层参数设置一致;
[0062]
将门控循环单元改进模型和长短期深度神经网络改进模型的输入层的维度参数设置为(128,3);
[0063]
将多通道卷积长短期深度神经网络改进模型的通道数增加1,由原来的i通道、q通道和i/q通道修改为i通道、q通道、增强数据通道和i/q/增强数据通道。
[0064]
下面结合附图对发明的步骤和工作原理做进一步的说明,以便本领域技术人员能够充分理解本发明,具体如下所述:
[0065]
本发明选择公开数据集rml2016.10a作为模型性能测试的数据集,这个数据集是通过模拟恶劣环境下的传播特性而生成的,rml2016.10a包含11种(8psk,bpsk,cpfsk,gfsk,pam4,am-dsb,am-ssb,16qam,64qam,qpsk,wbfm)调制方式的数据,包含信噪比(snr)在-20db到18db之间的模拟数据,得到图3所示的不同信噪比条件下的准确率对比结果,验证了本发明的有效性。
[0066]
参见图2所示,本发明包括以下步骤:
[0067]
步骤1:搭建自编码器模型:通过rml2016.10a[7]数据集得到i/q数据;基于深度神经网络,搭建自编码器模型;将i/q数据整理为i/q数据样本,将i/q数据样本输入所述自编码器模型,每条i/q数据样本包含l个采样点,每个采样点由i通道和q通道的数据组成,即输入的数据维度为2
×
l;所述自编码器模型输入的数据维度和输出的数据维度一致,均为2
×
l;
[0068]
步骤2:训练自编码器模型:在自编码器模型中设置损失函数为最小均方误差损失函数,训练周期设置为100次,训练批大小为400个;采用adam优化器对自编码器模型进行训练;所述最小均方误差损失函数计算自编码器模型输出数据和输入数据间的误差;所述自编码器模型的训练目标是最小化最小均方误差损失函数,最终训练得到输出与输入最接近的模型,并保存模型参数;
[0069]
步骤3:提取数据:将步骤2中自编码器模型输入的数据全部重新输入自编码器模型,这些数据只通过自编码器模型前两层得到维度为l的数据,并提取自编码器模型的第二层全连接层输出的维度为l的数据,作为i/q通道间的交互信息;
[0070]
通过矩阵维度变换操作将所述第二层全连接层输出的数据维度为l的数据转换为维度为1
×
l的数据,再与i/q数据进行拼接,得到维度为3
×
l的增强输入数据。
[0071]
步骤4:将经过所述步骤3处理得到的增强输入数据划分为训练集、验证集和测试集;
[0072]
步骤5:选取基线自动调制识别模型进行准确率对比,并将本发明的方法与基线自
动调制识别模型结合作为改进模型,改进模型的输入采用所述步骤3得到的增强输入数据,基线自动调制识别模型采用所述步骤1的i/q数据;
[0073]
步骤6:设置基线自动调制识别模型和改进模型训练的损失函数、优化器、训练的周期和批大小、初始学习率,对基线自动调制识别模型和改进模型进行训练;
[0074]
步骤7:将改进模型和基线自动调制识别模型的输出结果进行准确率对比,验证本发明所提出方法的有效性。
[0075]
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1