可视化媒体文件的检索方法、装置、电子设备和存储介质与流程
1.本技术涉及数据处理技术,更具体地说,涉及一种可视化媒体文件的检索方法、装置、电子设备和存储介质。
背景技术:
2.可视化媒体文件检索,指的是通过图像对比寻找已知图像和视频多媒体文件库中与待检索图像拥有相似元素的文件。该技术的本质是图像分类。许多传统的图像分类算法以全局相似度作为分类准则,但这并不能满足某些实际情况。有时候用户搜索图像时,目的是为了寻找包含原图中某元素的其他图像,而并非寻找与该图全局相似的图像。这种情况下,同类别的图像是指其具有相似的元素。该元素通常是在图像的前景部分,然而其所在区域是不确定的。除了相似元素,图像的其他部分往往差距较大。
3.用户所关心的原图中的目标元素,往往仅占据图像的局部区域,图像中非目标区域的其他元素就会对分类算法产生一定程度的干扰。以图1中两图为例,两个图像均为“拥有笑脸元素”的类别。但从全图的角度看,两张图片并不相似,左图的背景中有太阳、云朵、山峦,右图的背景中有月亮、云朵、树木,这些因素的干扰,导致传统算法可能无法对其进行正确地分类。
4.为了解决这一问题,许多算法在计算相似性时对图像中不同像素赋予不同的权重,但它们仍以全图作为输入进行匹配,因此仍不能免除非目标区域的干扰。
技术实现要素:
5.本技术要解决的技术问题在于,针对现有技术的上述缺陷,提供一种能减少图像中前景元素与背景元素的互相干扰的可视化媒体文件的检索方法和装置以及实现该方法的电子设备和存储介质。
6.本技术为解决其技术问题在第一方面提出一种可视化媒体文件的检索方法,所述方法包括:
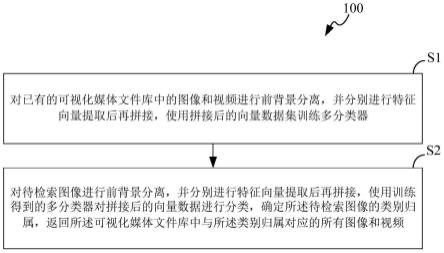
7.s1、对已有的可视化媒体文件库中的图像和视频进行前背景分离,并分别进行特征向量提取后再拼接,使用拼接后的向量数据集训练多分类器,其中,所述可视化媒体文件库已预先设置了各元素的类别标签;
8.s2、对待检索图像进行前背景分离,并分别进行特征向量提取后再拼接,使用所述步骤s1中训练得到的多分类器对拼接后的向量数据进行分类,确定所述待检索图像的类别归属,返回所述可视化媒体文件库中与所述类别归属对应的所有图像和视频。
9.根据本技术第一方面的一个实施例中,所述步骤s1进一步包括:
10.s11、对可视化媒体文件库中的图像和视频进行前背景分离,得到媒体文件前景库和媒体文件背景库;
11.s12、针对媒体文件前景库中的每个前景视频提取出多个关键帧图像,将媒体文件前景库中的所有前景图像和所有前景视频的关键帧图像组成的集合进行降维处理,得到第
一降维因子矩阵集合,并将降维处理后的张量进行向量化,得到前景向量数据集;
12.s13、针对媒体文件背景库中的每个背景视频提取出多个关键帧图像,将媒体文件背景库中的所有背景图像和所有背景视频的关键帧图像组成的集合进行与所述步骤s12相同的降维处理,得到第二降维因子矩阵集合,并将降维处理后的张量进行向量化,得到背景向量数据集;
13.s14、将前景向量数据集和背景向量数据集中的向量依次拼接得到拼接后的向量数据集;
14.s15、使用拼接后的向量数据集对多分类器进行训练。
15.根据本技术第一方面的一个实施例中,所述步骤s2进一步包括:
16.s21、对待检索图像进行前背景分离,得到前景图像和背景图像;
17.s22、采用所述步骤s12中得到的第一降维因子矩阵集合对待检索图像的前景图像进行降维处理,并将降维处理后的张量进行向量化,得到前景向量;
18.s23、采用所述步骤s13中得到的第二降维因子矩阵集合对待检索图像的背景图像进行降维处理,并将降维处理后的张量进行向量化,得到背景向量;
19.s24、将所述前景向量和背景向量进行拼接得到拼接后的向量;
20.s25、使用所述步骤s15训练得到的多分类器对所述拼接后的向量进行分类,返回与所述拼接后的向量的类别归属对应的所有图像和视频。
21.根据本技术第一方面的一个实施例中,所述步骤s12和步骤s13中采用mpca算法进行降维处理。
22.根据本技术第一方面的一个实施例中,所述方法采用rpca算法进行前背景分离。
23.根据本技术第一方面的一个实施例中,所述方法在步骤s15中使用拼接后的向量数据集对one-versus-one多分类器进行训练得到多个二分类器,在步骤s25中使用所述步骤s15中训练得到的多个二分类器对所述拼接后的向量进行分类。
24.根据本技术第一方面的一个实施例中,所述步骤s25进一步包括:将所述多个二分类器的分类计算任务分发到多个计算节点以分布式并行计算的方式计算分类结果。
25.本技术为解决其技术问题在第二方面提出一种可视化媒体文件的检索装置,包括:
26.训练模块,用于对已有的可视化媒体文件库中的图像和视频进行前背景分离,并分别进行特征向量提取后再拼接,使用拼接后的向量数据集对多分类器进行训练,其中,所述可视化媒体文件库已预先设置了各元素的类别标签;
27.搜索模块,用于对待检索图像进行前背景分离,并分别进行特征向量提取后再拼接,使用所述训练模块训练得到的多分类器对拼接后的向量数据进行分类,确定所述待检索图像的类别归属,返回所述可视化媒体文件库中与所述类别归属对应的所有图像和视频。
28.本技术为解决其技术问题在第三方面提出一种电子设备,包括处理器和存储器,所述存储器存储有计算机程序,所述计算机程序被所述处理器执行时,执行前述的可视化媒体文件的检索方法。
29.本技术为解决其技术问题在第四方面提出一种计算机可读存储介质,存储有计算机程序,所述计算机程序被处理器执行时实现前述的可视化媒体文件的检索方法。
30.实施本技术的可视化媒体文件的检索方法和装置以及实现该方法的电子设备和存储介质,具有以下有益效果:根据本技术实施例的可视化媒体文件的检索方法和装置通过前背景分离,再分别处理为两段向量数据后拼接起来,再对拼接后的向量数据进行分类,降低前背景元素间的干扰,因此有效提高分类的准确度,从而提高检索的精确性。同时,根据本技术进一步实施例的可视化媒体文件的检索方法和装置在计算分类时通过多节点分布式并行计算的方式,减少了多分类器识别待检索图像的类别的时间,进一步提高了检索效率。
附图说明
31.下面将结合附图及实施例对本技术作进一步说明,附图中:
32.图1是传统算法进行图像分类的示意图;
33.图2是本技术图像分类的原理示意图;
34.图3是本技术一个实施例的可视化媒体文件的检索方法的流程图;
35.图4是图3中步骤s1的进一步具体实施例的流程图;
36.图5是图3中步骤s2的进一步具体实施例的流程图;
37.图6是本技术一个实施例的可视化媒体文件的检索装置的逻辑框图;
38.图7是本技术一个实施例的电子设备的逻辑框图。
具体实施方式
39.为了使本技术的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本技术进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本技术,并不用于限定本技术。并且,在不冲突的情况下,本技术中的实施例及实施例中的特征可以相互组合。
40.本技术提出一种可视化媒体文件的检索方法,采用前背景分离的预处理步骤。对于图1所示的两图,本技术分别将其前景的笑脸元素和背景图像分离,如图2所示,再分别处理为两段向量数据后拼接起来,再对拼接后的向量数据进行分类,从而减少图像中前景元素与背景元素的相互干扰,能有效提高分类的准确度,从而提高检索结果的精确性。
41.为方便理解后文描述,本技术首先给出如下说明:
42.1)假设本技术所处理的所有图像视频均拥有统一的分辨率。
43.2)采用记号image表示图像。对于灰度图像,其本质为一个二维矩阵;对于彩色rgb图像,其本质是一个三阶张量。
44.3)采用记号video表示视频。对于灰度视频,其本质为一个三阶张量;对于彩色视频,其本质是一个四阶张量。
45.4)采用记号d表示张量的阶数,对于灰度图像,其阶数d=2;对于彩色图像,其阶数d=3;灰度视频的每一帧均为灰度图像(d=2);彩色视频的每一帧均为彩色图像(d=3)。
46.5)图像image的前背景分离,指的是由图像image生成前景图像image_f和背景图像image_b,其中image_f与image_b的分辨率和原image保持一致,image_f中主要为图像image中的前景部分,image_b中主要为图像image中的背景部分。
47.6)视频video的前背景分离,指的是由视频video生成前景视频video_f和背景视
频video_b,其中video_f与video_b的分辨率和原video保持一致,video_f中主要为视频video中的前景部分,video_b中主要为视频video中的背景部分。
48.7)rpca(robust principal component analysis,鲁棒主成分分析)是一种图像和视频数据的前背景分离的现有方法。对于张量x,rpca算法将其分解为x=b+s+ns,其中b为低秩张量,s为稀疏张量,ns为噪声部分。若x描述的是图像/视频,则b即为背景部分,s即为前景部分。有关rpca的介绍可以参见以下文献:
49.goldfarb d,qin z.“robust low-rank tensor recovery:models and algorithms,”in siam journal on matrix analysis and applications,2014,35(1):225-253.
50.8)mpca(multilinear principal component analysis,多线性主成分分析)是一种针对张量数据进行降维处理的现有方法。对于m个尺寸为i1×
i2×…×
id的d阶张量{x1,x2,
…
xm},mpca算法将计算得到d个因子矩阵{u1,u2,
…
ud},其尺寸分别为r1×
i1,r2×
i2,
…
rd×
id,最后通过yi=xi×1u1×2u2…×dud得到降维后的张量{y1,y2,
…
ym}(其尺寸均为r1×
r2×…×
rd)。其中,
×k表示张量与矩阵的模态积。有关mpca的介绍可以参见以下文献:
51.h.lu,k.n.plataniotis and a.n.venetsanopoulos,"mpca:multilinear principal component analysis of tensor objects,"in ieee transactions on neural networks,2008,19(1):18-39.
52.9)多分类svm(support vector machines,支持向量机)算法的一对一法(one-vs-one svms)简介:假设有n个类别c1,c2,
…cn
,对任意2个类别ci和cj训练得到二分类svm分类器svmbinaryclassifier
i,j
,则可得到共n(n-1)/2个二分类svm分类器。在判定一个新样本的类别归属时,使用上述训练得到的所有二分类svm分类器判定其类别,以得到票数最多次的类别做为该样本的最终类别。
53.图3示出了根据本技术一个实施例的可视化媒体文件的检索方法100的流程图。该可视化媒体文件的检索方法100以已有一个可视化媒体文件库medialib={image1,image2,
…
,imagen,video1,video2,
…
,videom}并已预先设置其中各元素的类别标签(共n个类别)为前提,包括如下步骤:
54.步骤s1,对已有的可视化媒体文件库中的图像和视频进行前背景分离,并分别进行特征向量提取后再拼接,使用拼接后的向量数据集训练多分类器。
55.步骤s2,对待检索图像进行前背景分离,并分别进行特征向量提取后再拼接,使用所述步骤s1中训练得到的多分类器对拼接后的向量数据进行分类,确定所述待检索图像的类别归属,返回所述可视化媒体文件库中与所述类别归属对应的所有图像和视频。
56.根据本技术的进一步具体实施例中,参见图4所示,上述步骤s1进一步包括:
57.步骤s101中,采用合适的算法(例如rpca)对可视化媒体文件库medialib中的图像和视频进行前背景分离,从而得到媒体文件前景库medialib_f={image_f1,image_f2,
…
,image_fn,video_f1,video_f2,
…
,video_fm}和媒体文件背景库medialib_b={image_b1,image_b2,
…
,image_bn,video_b1,video_b2,
…
,video_bm},之后分别进行处理。
58.然后步骤s102中,针对步骤s101中得到媒体文件前景库medialib_f中的每个前景视频video_fk(k=1,2,
…
,m)提取出所有t(k)个关键帧,得到{video_f_frame
k,1
,video_f_frame
k,2
,
…
,video_f_frame
k,t(k)
},其中每一帧video_f_frame
k,i
均为图像。
59.步骤s103中,将媒体文件前景库medialib_f中的所有前景图像和所有前景视频的关键帧图像组成集合{image_f1,image_f2,
…
,image_fn,video_f_frame
1,1
,video_f_frame
1,2
,
…
,video_f_frame
1,t(1)
,
…
,video_f_frame
m,1
,video_f_frame
m,2
,
…
,video_f_frame
m,t(m)
}。
60.步骤s104中,对上述集合使用mpca算法进行降维处理,得到第一降维因子矩阵集合u_f1,u_f2,
…
,u_fd。
61.步骤s105中,将降维处理后的张量进行向量化,得到前景向量数据集vectors_f={image_f_vec1,image_f_vec2,
…
,image_f_vecn,video_f_frame_vec
1,1
,video_f_frame_vec
1,2
,
…
,video_f_frame_vec
1,t(1)
,
…
,video_f_frame_vec
m,1
,video_f_frame_vec
m,2
,
…
,video_f_frame_vec
m,t(m)
}。
62.同时,本方法对步骤s101中得到的媒体文件背景库medialib_b进行与上述步骤s102-s105相同的处理,具体如下:
63.步骤s106中,针对步骤s101中得到的媒体文件背景库medialib_b中的每个背景视频video_bk(k=1,2,
…
,m)提取出所有t(k)个关键帧,得到{video_b_frame
k,1
,video_b_frame
k,2
,
…
,video_b_frame
k,t(k)
},其中每一帧video_b_frame
k,i
均为图像。
64.步骤s107中,将媒体文件背景库medialib_b中的所有背景图像和所有背景视频的关键帧图像组成集合{image_b1,image_b2,
…
,image_bn,video_b_frame
1,1
,video_b_frame
1,2
,
…
,video_b_frame
1,t(1)
,
…
,video_b_frame
m,1
,video_b_frame
m,2
,
…
,video_b_frame
m,t(m)
}。
65.步骤s108中,对上述集合使用mpca算法进行降维处理,得到第二降维因子矩阵集合u_b1,u_b2,
…
,u_bd。
66.步骤s109中,将降维处理后的张量进行向量化,得到背景向量数据集vectors_b={image_b_vec1,image_b_vec2,
…
,image_b_vecn,video_b_frame_vec
1,1
,video_b_frame_vec
1,2
,
…
,video_b_frame_vec
1,t(1)
,
…
,video_b_frame_vec
m,1
,video_b_frame_vec
m,2
,
…
,video_b_frame_vec
m,t(m)
}。
67.然后在步骤s110中,将前景向量数据集vectors_f和背景向量数据集vectors_b中的向量依次拼接得到拼接后的向量数据集,即vectors={image_vec1,image_vec2,
…
,image_vecn,video_frame_vec
1,1
,video_frame_vec
1,2
,
…
,video_frame_vec
1,t(1)
,
…
,video_frame_vec
m,1
,video_frame_vec
m,2
,
…
,video_frame_vec
m,t(m)
},其中image_veci为image_f_veci和image_b_veci拼接而成(i=1,2,
…
n);video_frame_vec
k,j
为video_f_frame_vec
k,j
和video_b_frame_vec
k,j
拼接而成。
68.最后在步骤s111中,使用拼接后的向量数据集vectors对多分类svm算法的one-versus-one多分类器进行训练得到n(n-1)/2个二分类器{svmbinaryclassifier
i,j
|1≤i≤n,1≤j《i}。
69.根据本技术的进一步具体实施例中,参见图5所示,前述方法100的步骤s2进一步包括:
70.步骤s201中,对待检索图像imgx,采用合适的算法(例如rpca)进行前背景分离,得到前景图像imgx_f和背景图像imgx_b,然后分别进行处理。
71.步骤s202中,采用第一降维因子矩阵集合u_f1,u_f2,
…
,u_fd对前景图像imgx_f进
行降维处理,即y_f=imgx_f
×1u_f1×2u_f2…×du_fd。
72.步骤s203中,将降维处理后的张量进行向量化,得到前景向量imgx_f_vec。
73.步骤s204中,采用第二降维因子矩阵集合u_b1,u_b2,
…
,u_bd对背景图像imgx_b进行降维处理,即y_b=imgx_b
×1u_b1×2u_b2…×du_bd。
74.步骤s205中,将降维处理后的张量进行向量化,得到背景向量imgx_b_vec。
75.步骤s206中,将前景向量imgx_f_vec和背景向量imgx_b_vec进行拼接得到拼接后的向量imgx_vec。
76.步骤s207中,使用前述步骤s111中训练得到的多分类器{svmbinaryclassifier
i,j
|1≤i≤n,1≤j《i}对拼接后的向量imgx_vec进行分类。一个具体实施例中,由于需要计算n(n-1)/2个二分类器svmbinaryclassifier
i,j
对imgx_vec的分类结果,而不同分类器相互独立,因此在有多个计算节点的环境下,可以将多个二分类器的分类计算任务分发到多个计算节点上,以分布式并行计算的方式计算分类结果,从而缩短分类时间,提高检索效率。
77.最后步骤s208中,返回与拼接后的向量imgx_vec的类别归属对应的所有图像和视频。
78.根据本技术上述实施例的可视化媒体文件的检索方法100在对图像进行分类时采用了多分类svm算法的one-versus-one多分类器,但是本技术并不局限于此,根据本技术的不同实施例中,其它分类算法例如神经网络、决策树等均可实现。
79.基于本技术上述的可视化媒体文件的检索方法,本技术还提出一种可视化媒体文件的检索装置。图6示出了根据本技术一个实施例的可视化媒体文件的检索装置200的逻辑结构图。如图6所示,该可视化媒体文件的检索装置包括训练模块21和搜索模块22。训练模块21用于对前述已有的可视化媒体文件库中的图像和视频进行前背景分离,并分别进行特征向量提取后再拼接,使用拼接后的向量数据集训练多分类器。其中,所述可视化媒体文件库已预先设置了各元素的类别标签。搜索模块22用于对待检索图像进行前背景分离,并分别进行特征向量提取后再拼接,使用训练模块21训练得到的多分类器对拼接后的向量数据进行分类,确定所述待检索图像的类别归属,返回所述可视化媒体文件库中与所述类别归属对应的所有图像和视频。有关训练模块21和搜索模块22的具体实现,可参见前述对可视化媒体文件的检索方法100的步骤s1和步骤s2的具体描述,在此便不再赘述。
80.基于本技术上述的可视化媒体文件的检索方法,本技术还提出一种电子设备300。参见图7所示,电子设备300包括处理器31和存储器32,处理器31和存储器32通信连接。存储器32存储有计算机程序,所述计算机程序被处理器31执行时使处理器31实现本技术前述实施例的可视化媒体文件的检索方法。
81.本技术还提出一种计算机可读存储介质,存储有计算机程序,所述计算机程序被处理器执行时实现本技术前述实施例的可视化媒体文件的检索方法。
82.以上所述仅为本技术的较佳实施例而已,并不用以限制本技术,凡在本技术的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本技术的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1