一种异常参数调整方法、装置、设备及存储介质与流程
1.本发明涉及型钢轧制领域,特别涉及一种异常参数调整方法、装置、设备及存储介质。
背景技术:
2.当前,由于型钢轧制工艺参数较多,组合复杂,从而导致型钢轧制合格率低,并且现有技术为提高型钢轧制合格率而人工调整工艺参数的调整成本高。
3.由此可知,如何提高型钢轧制的合格率是本领域有待解决的问题。
技术实现要素:
4.有鉴于此,本发明的目的在于提供一种异常参数调整方法、装置、设备及存储介质,能够降低人工调整参数的次数,提高型钢轧制合格率,从而减少资源浪费。其具体方案如下:
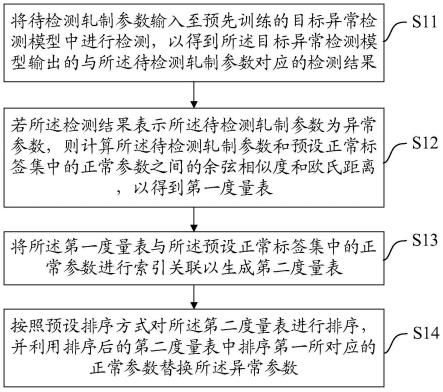
5.第一方面,本技术公开了一种异常参数调整方法,包括:
6.将待检测轧制参数输入至预先训练的目标异常检测模型中进行检测,以得到所述目标异常检测模型输出的与所述待检测轧制参数对应的检测结果;
7.若所述检测结果表示所述待检测轧制参数为异常参数,则计算所述待检测轧制参数和预设正常标签集中的正常参数之间的余弦相似度和欧氏距离,以得到第一度量表;
8.将所述第一度量表与所述预设正常标签集中的正常参数进行索引关联以生成第二度量表;
9.按照预设排序方式对所述第二度量表进行排序,并利用排序后的第二度量表中排序第一所对应的正常参数替换所述异常参数。
10.可选的,所述将待检测轧制参数输入至预先训练的目标异常检测模型中进行检测之前,还包括:
11.收集轧制参数和相应的规格值以得到原始数据集,并判断所述原始数据集中的所述规格值是否满足第一预设条件,若不满足,则将与所述规格值对应的样本从所述原始数据集进行剔除,以得到第一数据集;
12.判断所述第一数据集中的数据是否满足第二预设条件,若是,则对所述数据打上正常标签,若否,则为所述数据打上异常标签,以得到打标后的所述第一数据集;
13.利用预设无监督学习算法对打标后的所述第一数据集进行处理,以得到第二数据集,并基于所述第二数据集确定出相应的训练集和测试集;
14.利用所述训练集对基于预设监督学习算法构建的初始模型进行多次训练,并利用所述测试集对每一次训练后得到的异常检测模型进行测试评价以建立相应的评价指标集;
15.将所述评价指标集中数值最小的评价指标所对应的所述异常检测模型确定为目标异常检测模型。
16.可选的,所述将所述评价指标集中数值最小的评价指标所对应的所述异常检测模
型确定为目标异常检测模型之后,还包括:
17.基于预设超参数优化算法对所述目标异常检测模型进行优化以确定出优化后的目标异常检测模型。
18.可选的,所述判断所述原始数据集中的所述规格值是否满足第一预设条件,若不满足,则将与所述规格值对应的样本从所述原始数据集进行剔除,以得到第一数据集,包括:
19.判断所述规格值是否大于第一预设阈值;若是,则将所述规格值确定为异常值,并将与所述规格值对应的样本从所述原始数据集进行剔除,以得到第一数据集;其中,所述第一预设阈值为基于所述规格值对应的标准差确定的阈值。
20.可选的,所述利用预设无监督学习算法对打标后的所述第一数据集进行处理,以得到第二数据集之后,还包括:
21.从所述第二数据集中筛选出与所述正常标签对应的数据,以得到所述预设正常标签集。
22.可选的,所述利用预设无监督学习算法对打标后的所述第一数据集进行处理,以得到第二数据集,包括:
23.从打标后的所述第一数据集中选择目标数据,并计算所述目标数据的目标轧制向量与打标后的所述第一数据集中其余数据对应的轧制向量之间的欧氏距离和余弦相似度以生成第三度量表;
24.将所述第三度量表与所述打标后的所述第一数据集中的数据进行索引关联以生成第四度量表,并按照所述预设排序方式对所述第四度量表进行排序,以得到排序后的第四度量表;
25.按照预设筛选原则对所述排序后的第四度量表进行筛选,以得到筛选后的第四度量表,并计算所述筛选后的第四度量表中的正常标签数据对应的正常占比值与异常标签数据对应的异常占比值;
26.将所述正常比例值和所述异常比例值进行比较以得到相应的比较结果,基于所述比较结果确定出相应的目标标签,并判断所述目标数据对应的标签是否与所述目标标签一致;
27.若是,则计算所述正常比例值和所述异常比例值之间的绝对值差,并判断所述绝对值差是否不小于第二预设阈值,若是,则将所述目标数据添加至数据集,以得到第二数据集。
28.可选的,所述基于所述比较结果确定出相应的目标标签,包括:
29.当所述比较结果表示所述正常比例值大于所述异常比例值时,则将所述正常比例值对应的正常标签确定为目标标签;
30.当所述比较结果表示所述正常比例值不大于所述异常比例值时,则将所述异常比例值对应的异常标签确定为目标标签。
31.第二方面,本技术公开了一种异常参数调整装置,包括:
32.数检测模块,用于将待检测轧制参数输入至预先训练的异常检测模型中进行检测,以得到所述目标异常检测模型输出的与所述待检测轧制参数对应的检测结果;
33.第一度量表生成模块,用于若所述检测结果表示所述待检测轧制参数为异常参
数,则计算所述待检测轧制参数和预设正常标签集中的正常参数之间的余弦相似度和欧氏距离,以得到第一度量表;
34.第二度量表生成模块,用于将所述第一度量表与所述预设正常标签集中的正常参数进行索引关联以生成第二度量表;
35.参数替换模块,用于按照预设排序方式对所述第二度量表进行排序,并利用排序后的第二度量表中排序第一所对应的正常参数替换所述异常参数。
36.第三方面,本技术公开了一种电子设备,包括:
37.存储器,用于保存计算机程序;
38.处理器,用于执行所述计算机程序,以实现前述公开的异常参数调整方法的步骤。
39.第四方面,本技术公开了一种计算机可读存储介质,用于存储计算机程序;其中,所述计算机程序被处理器执行时实现前述公开的异常参数调整方法的步骤。
40.可见,本技术提供了一种异常参数调整方法,包括:将待检测轧制参数输入至预先训练的目标异常检测模型中进行检测,以得到所述目标异常检测模型输出的与所述待检测轧制参数对应的检测结果;若所述检测结果表示所述待检测轧制参数为异常参数,则计算所述待检测轧制参数和预设正常标签集中的正常参数之间的余弦相似度和欧氏距离,以得到第一度量表;将所述第一度量表与所述预设正常标签集中的正常参数进行索引关联以生成第二度量表;按照预设排序方式对所述第二度量表进行排序,并利用排序后的第二度量表中排序第一所对应的正常参数替换所述异常参数。由此可知,本技术通过预先训练的目标异常检测模型检测异常的待检测轧制参数,并利用构建出的排序后的第二度量表确定出正常参数,然后利用所述正常参数替代所述异常参数,以降低人工调整参数的次数,提高型钢轧制合格率,从而减少资源浪费。
附图说明
41.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
42.图1为本技术公开的一种异常参数调整方法流程图;
43.图2为本技术公开的一种具体的目标异常检测模型创建方法流程图;
44.图3为本技术公开的一种模型训练次数与评价指标之间的关系示意图;
45.图4为本技术公开的一种模型训练流程示意图;
46.图5为本技术公开的一种异常检测模型自学习各项指标趋势示意图;
47.图6为本技术公开的一种异常参数调整装置结构示意图;
48.图7为本技术公开的一种电子设备结构图。
具体实施方式
49.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他
实施例,都属于本发明保护的范围。
50.当前,由于型钢轧制工艺参数较多,组合复杂,从而导致型钢轧制合格率低,并且现有技术为提高型钢轧制合格率而调整工艺参数的调整成本高。为此,本技术提供了一种新的异常参数调整方法,能够降低人工调整参数的次数,提高型钢轧制合格率,从而减少资源浪费,同时也提高关键岗位的智能化应用水平,为企业降本增效持续发展提供了方向。
51.本发明实施例公开了一种异常参数调整方法,参见图1所示,该方法包括:
52.步骤s11:将待检测轧制参数输入至预先训练的目标异常检测模型中进行检测,以得到所述目标异常检测模型输出的与所述待检测轧制参数对应的检测结果。
53.本实施例中,上述待检测轧制参数就是型钢轧制工艺参数,将待检测轧制参数输入至预先训练的目标异常检测模型中进行检测。可以理解的是,将待检测轧制参数输入至上述目标异常检测模型也就是将上述型钢轧制工艺参数所对应的轧制参数向量输入至上述目标异常检测模型,上述目标异常检测模型就会输出相应的检测结果,从而可以确定出上述轧制参数向量是否为异常的参数向量。
54.需要指出的是,将待检测轧制参数输入至预先训练的目标异常检测模型中进行检测之前,需要基于型钢生产过程中所涉及的轧制参数以及型钢成品对应的规格参数建立异常检测模型,以得到本实施例中用于检测待检测轧制参数是否为异常参数的目标异常检测模型。
55.步骤s12:若所述检测结果表示所述待检测轧制参数为异常参数,则计算所述待检测轧制参数和预设正常标签集中的正常参数之间的余弦相似度和欧氏距离,以得到第一度量表。
56.需要指出的是,上述预设正常标签集也就是从目标异常检测模型过程中确定出来的第二数据集分离出的正常标签集,并且上述第一度量表表征被检测为异常的所述待检测轧制参数与所述预设正常标签集中的所有正常参数之间的相似程度。
57.步骤s13:将所述第一度量表与所述预设正常标签集中的正常参数进行索引关联以生成第二度量表。
58.可以理解的是,将上述第一度量表与上述预设正常标签集进行合并,并且上述预设正常标签中的每一正常参数都要对应关联上述步骤s12中的第一度量表中的余弦相似度以及欧氏距离,也就是说,上述第二度量表包含用于替代异常参数的上述正常参数以及对应的余弦相似度与欧氏距离。
59.步骤s14:按照预设排序方式对所述第二度量表进行排序,并利用排序后的第二度量表中排序第一所对应的正常参数替换所述异常参数。
60.需要指出的是,上述预设排序方式也就是按照上述余弦相似度从高到低以及上述欧氏距离从低到高的顺序进行排序,基于所述余弦相似度和所述欧氏距离可以准确地确定出更适合替换异常参数的正常参数。对上述第二度量表进行排序是为了高效地确定出所述正常参数,也即上述排序后的第二度量表中的排序第一对应的第一条数据中的正常参数就能够用于替换异常参数。这样就能够节省用于查找能够替换异常参数的正常参数的时间,从而提高异常参数的调整效率。
61.可见,本技术实施例通过预先训练的目标异常检测模型检测异常的待检测轧制参数,并利用构建出的排序后的第二度量表确定出正常参数,然后利用所述正常参数替代所
述异常参数,以降低人工调整参数的次数,提高型钢轧制合格率,从而减少资源浪费。
62.进一步的,本技术实施例公开了一种具体的目标异常检测模型创建方法,如图2所示,该方法包括:
63.步骤s21:收集轧制参数和相应的规格值以得到原始数据集,并判断所述原始数据集中的所述规格值是否满足第一预设条件,若不满足,则将与所述规格值对应的样本从所述原始数据集进行剔除,以得到第一数据集。
64.本实施例中,首先需要进行数据收集,也即收集轧制参数和相应的规格值以得到原始数据集,也就是说,提取每支钢轧制参数以及所述轧制参数对应型钢成品的规格数据,并基于所述轧制参数和所述规格数据构成原始数据集,然后对上述原始数据集进行数据清洗,将所述原始数据集中的不满足第一预设条件的规格数据进行剔除,例如,去除所述原始数据集a中含有缺失值和异常值的样本,从而得到所述原始数据集a清洗后的第一数据集b,具体的数据清洗方式,可以包括:判断所述规格值是否大于第一预设阈值;若是,则将所述规格值确定为异常值,并将与所述规格值对应的样本从所述原始数据集进行剔除,以得到第一数据集;其中,所述第一预设阈值为基于所述规格值对应的标准差确定的阈值。例如,对每一种规格数据的型钢成品估计其高斯密度函数,从而确定出该规格值对应的标准差,将所述原始数据集中大于3倍的标准差的规格值确定为异常值,从而将所述异常值所对应的样本从所述原始数据集进行剔除,以得到第一数据集。
65.步骤s22:判断所述第一数据集中的数据是否满足第二预设条件,若是,则对所述数据打上正常标签,若否,则为所述数据打上异常标签,以得到打标后的所述第一数据集。
66.本实施例中,主要是对所述第一数据中的数据进行数据打标,也就是对对所述第一数据中的数据打上相应的标签,当所述第一数据中的数据满足第二预设条件时,则为所述数据打上正产标签,当所述数据不满足第二预设条件时,则为所述数据打上异常标签,所述第一数据集中的所有数据都打上标签之后,所述第一数据集也就是打标后的所述第一数据集。例如,判断所述第一数据集b的规格值是否在标准误差范围内,对所述规格值在标准误差范围内的数据打上正常标签,对所述规格值不在标准误差范围内的数据打上异常标签。
67.步骤s23:利用预设无监督学习算法对打标后的所述第一数据集进行处理,以得到第二数据集,并基于所述第二数据集确定出相应的训练集和测试集。
68.本实施例中,得到打标后的所述第一数据集之后,还需要利用预设无监督学习算法对打标后的所述第一数据集进行处理,以得到能够用于训练以及测试异常检测模型的第二数据集。
69.本实施例中,所述利用预设无监督学习算法对打标后的所述第一数据集进行处理,以得到第二数据集,具体可以包括:从打标后的所述第一数据集中选择目标数据,并计算所述目标数据的目标轧制向量与打标后的所述第一数据集中其余数据对应的轧制向量之间的欧氏距离和余弦相似度以生成第三度量表;将所述第三度量表与所述打标后的所述第一数据集中的数据进行索引关联以生成第四度量表,并按照所述预设排序方式对所述第四度量表进行排序,以得到排序后的第四度量表;按照预设筛选原则对所述排序后的第四度量表进行筛选,以得到筛选后的第四度量表,并计算所述筛选后的第四度量表中的正常标签数据对应的正常占比值与异常标签数据对应的异常占比值;将所述正常比例值和所述
异常比例值进行比较以得到相应的比较结果,基于所述比较结果确定出相应的目标标签,并判断所述目标数据对应的标签是否与所述目标标签一致;若是,则计算所述正常比例值和所述异常比例值之间的绝对值差,并判断所述绝对值差是否不小于第二预设阈值,若是,则将所述目标数据添加至数据集,以得到第二数据集,可以理解的是,对上述打标后的所述第一数据集都执行上述处理操作,直至上述打标后的所述第一数据集中的所有数据都遍历完毕,从而得到上述第二数据集。其中,所述基于所述比较结果确定出相应的目标标签,还包括:当所述比较结果表示所述正常比例值大于所述异常比例值时,则将所述正常比例值对应的正常标签确定为目标标签;
70.当所述比较结果表示所述正常比例值不大于所述异常比例值时,则将所述异常比例值对应的异常标签确定为目标标签。并且,在得到上述第二数据集之后,还需要从所述第二数据集中筛选出与所述正常标签对应的数据,以得到所述预设正常标签集。可以理解的是,随机打乱上述第二数据集之后,划分出相应的训练集和测试集用于建立目标异常检测模型。并且从上述第二数据集中分离出的上述预设正常标签集用于调整异常的轧制参数。例如,从上述打标后的所述第一数据集b中依次选择一条目标数据x,并依次计算每一条所述目标数据x的轧制向量与所述打标后的所述第一数据集b中其余轧制向量之间的余弦相似度cs和欧氏距离ed,生成cs和ed度量表t0(上述第三度量表),将表t0与b中标签数据按索引进行关联生成表t1(上述第四度量表);对所述表t1按照上述余弦相似度cs从高到低以及上述欧氏距离ed从低到高的顺序进行排序,得到排序后的表t1(排序后的第四度量表),通过上述余弦相似度cs的阈值α和上述欧氏距离ed的阈值β对排序后的t1进行筛选,也就是,在所述排序后的第四度量表中留下大于α小于β的数据生成表t2(上述筛选后的第四度量表),其中,通过抽样多条所述目标数据x得到多张所述排序后的t1表,然后确定出每张所述排序后的t1表对应的与所述目标数据x相近的最后一条数据的cs值和ed值,再计算所述cs值的均值与所述ed值的均值从而确定出阈值α和上述阈值β;计算上述表t2中正常标签占比p1(正常占比值),异常标签占比p2(异常占比值),进而比较p1与p2的大小确定出大的标签l(目标标签),查询从打标后的所述第一数据集b中选择的所述目标数据x的标签y,也就是说,确定所述目标数据x的标签是正常标签还是异常标签,然后判断上述标签y是否与上述标签l相同,若不同则不将上述目标数据x加入稳定数据集c(第二数据集);若相同,则计算上述正常标签占比p1与上述异常标签占比p2的绝对值差δp,即δp=|p1-p2|,并且当上述绝对值差δp大于阈值λ,则将所述目标数据x加入稳定数据集c,反之不加入,其中,上述阈值λ的取值可通过抽样几组上述绝对值差δp再计算其均值来确定;当对打标后的所述第一数据集b中的目标数据进行处理完毕之后得到稳定数据集c,同时从c中分离出正常标签数据集d(预设正常标签集)。
71.步骤s24:利用所述训练集对基于预设监督学习算法构建的初始模型进行多次训练,并利用所述测试集对每一次训练后得到的异常检测模型进行测试评价以建立相应的评价指标集。
72.需要指出的是,所述预设监督学习算法可以包括但不限于随机森林算法以及决策树算法等。
73.本实施例中,利用上述训练集对所述异常检测模型进行多次训练,并利用上述测试集分别对每次训练后的异常检测模型进行测试评价,进而存储每次训练后的异常检测模
型以及对应的评价指标,然后基于上述评价指标建立相应的评价指标集。如图3所示,异常检测模型的评价指标会随着训练次数的增加呈现先减小后增加的趋势,也即随着训练次数增加,模型效果越来越好,评价指标也越来越小,并且在多次训练的过程中监测到评价指标出现增加的情况,则可以停止对模型的训练。其中,上述评价指标越接近0,上述异常检测模型效果越好,并且,上述评价指标的计算公式如下:
74.γ=2*(假阳率*假阴率)/(假阳率+假阴率);
75.其中,γ表示评价指标,所述假阴率=预测为正常样本中实际为异常的样本数/实际正常样本数;所述假阳率=预测为异常样本中实际为正常的样本数/实际为异常样本数。
76.步骤s25:将所述评价指标集中数值最小的评价指标所对应的所述异常检测模型确定为目标异常检测模型。
77.本实施例中,将上述评价指标集中数值最小的评价指标对应的异常检测模型确定为最优模型,也即,将最优模型作为检测异常轧制参数的目标异常检测模型。
78.本实施例中,将所述评价指标集中数值最小的评价指标所对应的所述异常检测模型确定为目标异常检测模型之后,还可以包括:基于预设超参数优化算法对所述目标异常检测模型进行优化以确定出优化后的目标异常检测模型。可以理解的是,如图4所示,首先预设一组超参数集,作为初始超参数集,并利用上述初始超参数集对所述目标异常检测模型进行多次训练以得到最小评价指标对应的训练后的目标异常检测模型,然后基于上一次的模型训练结果中的所述最小评价指标确定是否需要确定一组新的超参数集,再利用所述新的超参数集对所述目标异常检测模型进行训练以得到另一个最小评价指标对应的训练后的目标异常检测模型,重复利用每一次确定出来的新的超参数集对模型训练的步骤,从而得到多个不同超参数集对应的多个训练后的目标异常检测模型。将所述多个训练后异常检测模型对应的多个最小评价指标中数值最小的评价指标确定为目标评价指标,并将所述目标评价指标对应的所述训练后目标异常检测模型确定为优化后的目标检测模型。也就是说,利用多组超参数集训练上述目标异常检测模型,每组超参数集需要基于上一次模型训练的结果来确定,当上一次的训练结果已经满足预设条件时,就不再需要确定下一组超参数集,从而能够节约模型最终训练的时间,提高模型训练效率。利用每组所述超参数集对所述目标异常检测模型进行多次训练后得到的最优模型都是评价指标最小的模型,然后存储每组所述超参数集对应的所述最优模型以及所述最优模型对应的最小评价指标,最后从存储的多个最优模型中选择评价指标最小的模型作为模型训练的最终模型,即优化后的目标异常检测模型。需要指出的是,上述预设超参数优化算法可以包括但不限于贝叶斯超参数优化算法。
79.需要指出的是,在上述目标异常检测模型在检测的过程中,还能够通过异常检测模型的自学习,根据实际的应用情况更新上述目标异常检测模型,上述异常检测模型的自学习过程也即定时向上述异常检测模型输入新的轧制参数以及对应的型钢成品的规格数据,并将所述新的轧制参数以及对应的新的规格数据与上述原始数据集a合并,然后重复上述数据清洗和处理的步骤,生成新的第二数据集,并从所述新的第二数据集中分离出新的正常标签集,进而利用上述新的第二数据集分离出新的训练集和新的测试集完成目标异常检测模型的训练与优化,得到新的异常检测模型,其中,在上述新的测试集进行测试时,生成假阳率和假阴率,并结合时间生成时间序列走势得到假阳率曲线和假阴率曲线,然后利
用上述假阳率曲线和上述假阴率曲线分别计算最新节点与后推第n个节点之间连线的斜率k,进而判断上述斜率k是否在阈值范围θ内,上述斜率k不在上述阈值范围θ内,则不更新模型人工进行干预,若上述斜率k在范围内则自动更新上述目标异常检测模型,也就是说,用上述新的目标检测模型进行异常检测,其中所述阈值范围θ∈[-1,0],上述节点位数n的取值可以根据曲线波动周期来确定。如图5示出的异常检测模型自学习假阴率和假阳率指标趋势,也就是说,在自学习的过程中,当假阳率呈下降趋势,说明异常检测模型的可靠性在逐步增加。
[0080]
相应的,本技术实施例还公开了一种异常参数调整装置,参见图6所示,该装置包括:
[0081]
数据检测模块11,用于将待检测轧制参数输入至预先训练的异常检测模型中进行检测,以得到所述目标异常检测模型输出的与所述待检测轧制参数对应的检测结果;
[0082]
第一度量表生成模块12,用于若所述检测结果表示所述待检测轧制参数为异常参数,则计算所述待检测轧制参数和预设正常标签集中的正常参数之间的余弦相似度和欧氏距离,以得到第一度量表;
[0083]
第二度量表生成模块13,用于将所述第一度量表与所述预设正常标签集中的正常参数进行索引关联以生成第二度量表;
[0084]
参数替换模块14,用于按照预设排序方式对所述第二度量表进行排序,并利用排序后的第二度量表中排序第一所对应的正常参数替换所述异常参数。
[0085]
由上可见,本实施例通过预先训练的目标异常检测模型检测异常的待检测轧制参数,并利用构建出的排序后的第二度量表确定出正常参数,然后利用所述正常参数替代所述异常参数,以降低人工调整参数的次数,提高型钢轧制合格率,从而减少资源浪费。
[0086]
在一些具体的实施例中,所述异常参数调整装置,还可以包括:
[0087]
参数收集模块,用于收集轧制参数和相应的规格值以得到原始数据集;
[0088]
第一条件判断模块,用于判断所述原始数据集中的所述规格值是否满足第一预设条件,若不满足,则将与所述规格值对应的样本从所述原始数据集进行剔除,以得到第一数据集;
[0089]
第二条件判断模块,用于判断所述第一数据集中的数据是否满足第二预设条件,若是,则对所述数据打上正常标签,若否,则为所述数据打上异常标签,以得到打标后的所述第一数据集;
[0090]
数据处理模块,用于利用预设无监督学习算法对打标后的所述第一数据集进行处理,以得到第二数据集,并基于所述第二数据集确定出相应的训练集和测试集;
[0091]
模型训练模块,用于利用所述训练集对基于预设监督学习算法构建的初始模型进行多次训练;
[0092]
模型评价模块,用于利用所述测试集对每一次训练后得到的异常检测模型进行测试评价以建立相应的评价指标集。
[0093]
在一些具体的实施例中,所述将所述评价指标集中数值最小的评价指标所对应的所述异常检测模型确定为目标异常检测模型之后,具体还可以包括:
[0094]
模型优化模块,用于基于预设超参数优化算法对所述目标异常检测模型进行优化以确定出优化后的目标异常检测模型。
[0095]
在一些具体的实施例中,所述第一条件判断模块,具体可以包括:
[0096]
第一判断单元,用于判断所述规格值是否大于第一预设阈值;
[0097]
数据剔除单元,用于当所述规格值大于所述第一预设阈值时,则将所述规格值确定为异常值,并将与所述规格值对应的样本从所述原始数据集进行剔除,以得到第一数据集;其中,所述第一预设阈值为基于所述规格值对应的标准差确定的阈值。
[0098]
在一些具体的实施例中,所述利用预设无监督学习算法对打标后的所述第一数据集进行处理,以得到第二数据集之后,具体还可以包括:
[0099]
数据筛选模块,用于从所述第二数据集中筛选出与所述正常标签对应的数据,以得到所述预设正常标签集。
[0100]
在一些具体的实施例中,所述数据处理模块,具体可以包括:
[0101]
第一表生成单元,用于从打标后的所述第一数据集中选择目标数据,并计算所述目标数据的目标轧制向量与打标后的所述第一数据集中其余数据对应的轧制向量之间的欧氏距离和余弦相似度以生成第三度量表;
[0102]
第二表生成单元,用于将所述第三度量表与所述打标后的所述第一数据集中的数据进行索引关联以生成第四度量表,并按照所述预设排序方式对所述第四度量表进行排序,以得到排序后的第四度量表;
[0103]
筛选单元,用于按照预设筛选原则对所述排序后的第四度量表进行筛选,以得到筛选后的第四度量表,并计算所述筛选后的第四度量表中的正常标签数据对应的正常占比值与异常标签数据对应的异常占比值;
[0104]
标签确定单元,用于将所述正常比例值和所述异常比例值进行比较以得到相应的比较结果,基于所述比较结果确定出相应的目标标签,并判断所述目标数据对应的标签是否与所述目标标签一致;
[0105]
数据集确定单元,用于当所述目标数据对应的标签与所述目标标签一致,则计算所述正常比例值和所述异常比例值之间的绝对值差,并判断所述绝对值差是否不小于第二预设阈值,若是,则将所述目标数据添加至数据集,以得到第二数据集。
[0106]
在一些具体的实施例中,所述标签确定单元,具体可以包括:
[0107]
第一标签确定子单元,用于当所述比较结果表示所述正常比例值大于所述异常比例值时,则将所述正常比例值对应的正常标签确定为目标标签;
[0108]
第二标签确定子单元,用于当所述比较结果表示所述正常比例值不大于所述异常比例值时,则将所述异常比例值对应的异常标签确定为目标标签。
[0109]
进一步的,本技术实施例还提供了一种电子设备。图7是根据一示例性实施例示出的电子设备20结构图,图中的内容不能认为是对本技术的使用范围的任何限制。
[0110]
图7为本技术实施例提供的一种电子设备20的结构示意图。该电子设备20,具体可以包括:至少一个处理器21、至少一个存储器22、电源23、通信接口24、输入输出接口25和通信总线26。其中,所述存储器22用于存储计算机程序,所述计算机程序由所述处理器21加载并执行,以实现前述任一实施例公开的异常参数调整方法中的相关步骤。另外,本实施例中的电子设备20具体可以为电子计算机。
[0111]
本实施例中,电源23用于为电子设备20上的各硬件设备提供工作电压;通信接口24能够为电子设备20创建与外界设备之间的数据传输通道,其所遵循的通信协议是能够适
用于本技术技术方案的任意通信协议,在此不对其进行具体限定;输入输出接口25,用于获取外界输入数据或向外界输出数据,其具体的接口类型可以根据具体应用需要进行选取,在此不进行具体限定。
[0112]
另外,存储器22作为资源存储的载体,可以是只读存储器、随机存储器、磁盘或者光盘等,其上所存储的资源可以包括操作系统221、计算机程序222等,存储方式可以是短暂存储或者永久存储。
[0113]
其中,操作系统221用于管理与控制电子设备20上的各硬件设备以及计算机程序222,其可以是windows server、netware、unix、linux等。计算机程序222除了包括能够用于完成前述任一实施例公开的由电子设备20执行的异常参数调整方法的计算机程序之外,还可以进一步包括能够用于完成其他特定工作的计算机程序。
[0114]
进一步的,本技术实施例还公开了一种存储介质,所述存储介质中存储有计算机程序,所述计算机程序被处理器加载并执行时,实现前述任一实施例公开的异常参数调整方法步骤。
[0115]
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其它实施例的不同之处,各个实施例之间相同或相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
[0116]
最后,还需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
[0117]
以上对本发明所提供的一种异常参数调整方法、装置、设备及存储介质进行了详细介绍,本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1