一种基于自适应多粒度时空建模的细粒度视频识别方法
1.本发明属于机器学习和深度学习领域,具体涉及基于多粒度时空线索自适应建模的视频动作识别方法。
背景技术:
2.视频动作识别是视频理解领域中最具有代表性和重要性的任务之一,它应用于现实世界中许多领域,包括行为分析、人机交互、游戏娱乐和视频检索等。随着近十年来深度学习体系的爆炸式进展,以及在图像检测领域取得的巨大成功,使得视频理解领域得到长足发展[1,2,3,4,5,6,7]。近年来,深度视频识别架构层出不穷,其中主流的三种趋势分别是开辟新路径捕获时间信息的双流网络[4]、提取时空特征信息的3d深度卷积网络[7,2,5]以及关注计算效率的基于时间建模的轻量化2d深度卷积网络[8,9,3,10,11]。除此之外,近期人们对transformers应用于视频识别进行热门研究[12,13],虽然取得了较优的性能,但同时也耗费了大量的计算和数据资源。
[0003]
然而,高效的视频识别算法仍然面临几个主要挑战。首先,现有深度视频识别模型捕捉时间信息带来不可忽视的训练和推理的计算代价。其次,在时间建模方面,日常生活中的动作是复杂且多变的,捕捉动作的视频本身存在很强的类内和类间变化。在日常视频实例中,不同动作类别往往区分在视觉节奏的不同上,如走路、竞走、跑步等动作,他们具有很强的表观相似性,但是处于不同的视觉节奏中。换而言之,复杂动作存在复杂的时空尺度变化,特别地,主要体现在动作具备不同的视觉节奏,而运动对象的空间尺度也存在不同程度的变化。这类现象也迫使动作实例需更聚焦在类内、类间差异进行精准建模。综上所述,这些视频动作实例的特殊属性的存在,给视频表示学习中如何有效地时空建模带来了十足的挑战。
[0004]
为了解决视频复杂的时空尺度变化问题,现有的研究大多基于输入级[1,14,15]或者特征级的金字塔机制来提取动作实例的视频线索[16]。
[0005]
具体来说,输入级金字塔机制是将视频通过使用不同采样策略获取更为丰富的输入数据,其中基于多速率视频随机跳跃的方法(rts)[15]通过对样本视频的多帧进行多次随机间隔采样得到多个片段,而不是传统tsn[6]中的仅一个片段。动态时间金字塔采样(dtpn)[14]针对样本视频采用不同的5个时间采样率提取特征,并作为输入数据。rts和dtpn均可视为时间维度的数据增强,但两者都是将多速率输入送入共享的主干网络(如双流网络[4]、c3d[2]),仅达到提取更为丰富时间金字塔特征这一目的。因而,这类方法的弊端较为直观,即使不同分辨率输入均经过共享模型,计算代价也将随采样率增加而迅猛增加。相应地,以基于多速率的慢与快通道网络[1]为例的多流网络,则是为了在准确性和效率之间实现更好的平衡,慢与快通道网络[1]提出两分支架构,分别使用重量和轻量模型处理慢速地和快速地时间采样输入,但仍然承受着昂贵的计算成本[16];除此之外,当面临高采样率时,模型也难以扩展。
[0006]
近来,现有方法提出时间金字塔(tpn)[16]在特征级别融合不同时空分辨率特征,
将输入级金字塔扩展到特征层面。但值得注意地是,tpn是融合来自深度卷积网络不同阶段的时空特征,因而这些特征是粗粒度的,其捕捉细微变化的视觉节奏能力是有限的。现有的多粒度方法[17]为了获得多粒度时空视频学习表示能力,构建的多流模型(msd),是通过采样单帧、多个连续帧、一个短片段以及整个视频作为多种粒度的输入。显然,多流模型也承受着昂贵的计算负担,并且他还存在用固定的方式提取且融合不同粒度的问题,难以完整地诠释视频中时空线索的复杂尺度变化。
技术实现要素:
[0007]
为克服现有方法与技术的不足,本发明旨在解决面临复杂视频动作时,如何高效且轻量的时空建模,并在视频动作识别任务上取得优秀的性能。为此,本发明的技术方案提出了一种基于单输入的自适应多粒度时空线索建模网络(ams-net),通过设计一个单尺度输入的单流网络,自适应地建模多粒度时空线索,旨在于高效率且有效地捕捉复杂时空动态过程。本方法针对视频识别场景,基于现有深度卷积网络模型,提出一种基于自适应多粒度时空建模的细粒度视频识别方法,解决捕获视频动作复杂尺度变化的难题。
[0008]
本发明采用如下技术方案:
[0009]
一种基于自适应多粒度时空建模的细粒度视频识别方法,所述方法基于深度神经网络、细粒度cptm模块和粗粒度cstp模块;包括如下步骤:
[0010]
所述细粒度cptm模块并入深度神经网络提取细粒度的时间线索;
[0011]
所述细粒度cptm模块是以渐进时间卷积和竞争式融合机制进行构建;包括:
[0012]
以计算尺度k的时间特征的一组多尺度特征.表示为:
[0013]
yk=g(wk)
⊙yk-1
,k=1,
…
,k,
[0014]
其中,y0=χ且g(wk)表示权重为wk的时间卷积;
[0015]
所述细粒度cptm模块以竞争式融合机制的多尺度特征表示为:
[0016][0017]
其中,维度为c的向量h通过对时空特征全局平均池化(gap),以捕获多时间尺度{y1,
…
,yk}的全局上下文关系,即}的全局上下文关系,即是通过两个权重分别为是通过两个权重分别为的全连接层计算得到;
⊙
表示沿通道维度的点积运算;τ则是决定多尺度特征之间竞争或协作模式的一个平衡参数;
[0018]
所述粗粒度cstp模块并入深度神经网络提取融合粗粒度的时空特征;包括:
[0019]
所述粗粒度cstp模块采用两阶段自适应融合机制表示为:
[0020][0021]
其中,φ
up
、φ
dw
和φz是三个核大小为1
×
1的2d卷积层,而标识[
·
;
·
]表示特征间
的连接操作;权重和由输入通过函数g1计算得到;输出z
up
和z
dw
作为函数g2输入,计算出权重ω
up
和ω
dw
。
[0022]
进一步,所述细粒度cptm模块和所述粗粒度cstp模块并入2d深度神经网络过程:
[0023]
在2d深度神经网络的卷积阶段间有选择性地插入cptm模块,提取当前连续卷积阶段间的特征的细粒度时间线索:
[0024]
设为第l阶段第i残差块(res
l,i
)的输出,其中w表示宽度,h表示高度,t表示时间维度以及c表示通道数;
[0025]
cptm模块(f
cptm
)在该层输入特征χ
l,nl
所提取细粒度时间线索可以表示为:
[0026]
y(l)=f
cptm
(χ
l,nl
)
[0027]
其中,n
l
为res
l
的最后一个残差块,该输出y(l)为下一阶段res
l+1,1
的输入;
[0028]
所述cstp模块是采用如下公式将不同卷积阶段的时空分辨率特征进行自适应融合输出:
[0029]
z=f
cstp
(y(l-1),y(l))
[0030]
其中:l表示深度卷积网络中阶段总数,z则用于融合特征后的最后预测。
[0031]
进一步,所述细粒度cptm模块和所述粗粒度cstp模块并入3d深度神经网络过程:
[0032]
在3d深度神经网络将cptm模块和2d空间卷积以残差方式结合,构建出3d
cptm
层结构,并通过3d
cptm
层代替残差网络中原有的3d卷积层,以达到提取细粒度时间线索目的;
[0033]
所述cstp模块是采用如下公式将不同卷积阶段的时空分辨率特征进行自适应融合输出:
[0034][0035]
其中:z同样表示自适应融合跨不同时空分辨率的粗粒度特征信息。
[0036]
有益效果
[0037]
本发明提出了一种基于单尺度输入自适应提取多粒度时空特征的单流网络结构(即ams网络),旨在提高视频动作识别的性能,具备捕获视频中复杂尺度变化的时空线索的能力。为此,提出了两个核心结构:细粒度时间建模模块和粗粒度时空金字塔模块(即cptm模块和cstp模块),在单分辨率特征图上并行提取细粒度的时间线索,并自适应融合跨时空分辨率的粗粒度时空特征。鉴于cptm模块和cstp模块是与特定模型无关的,本发明的ams网络可以根据现有的深度2d/3d卷积网络架构灵活实例化。在时间主导、表征主导以及细粒度视频数据集上,大量实验清晰地证明了本发明所提出的方法的有效性,并展示出与需求更多帧的深度卷积网络相比,本发明更利于细粒度时间线索建模的同时,可以更高效的捕获复杂时空线索,更有效地、鲁棒地时间建模。
附图说明
[0038]
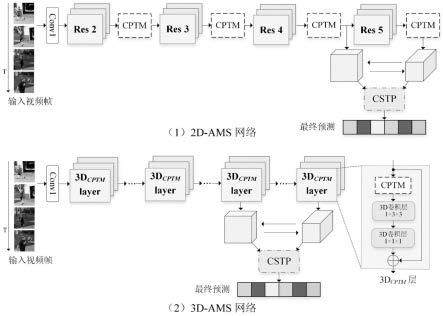
图1是本发明涉及的2d/3d ams网络框架图;
[0039]
图2cptm细粒度时间建模模块框架图;
[0040]
图3cstp粗粒度时空金字塔框架图。
具体实施方式
[0041]
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图与实例对本发明做详细的论述,以下实施例只是描述性的,不是限定性的,不能以此限定本发明的保护范围。
[0042]
如图1所示,本发明在基于单分辨率输入的2d深度卷积架构,本发明提出的细粒度时间建模模块cptm是即插即用地插入深度卷积网络的各个阶段之间(如残差网络的各阶段间),提取当前时空分辨率的细粒度时间线索;而在3d深度卷积网络中,本发明以3d残差网络为例,cptm模块替换了部分3d残差层中第一个核大小为1
×1×
1的3d卷积层,旨在计算量和性能之间取得平衡。而对于时空金字塔模块cstp,在2d和3d深度卷积网络实例化中,均于不同阶段获取该阶段的输出特征,进行不同时空分辨率特征的粗粒度自适应融合。
[0043]
本发明提出的cptm模块和cstp模块分别自适应地提取细粒度的时间线索和融合粗粒度的时空特征。特别地,提出的cptm模块由几个具有相同核大小但非共享的时间卷积连续组成,针对同一时间分辨率提取多尺度特征,以达到多尺度特征捕捉微妙时间变化的目的,而所捕捉的时间细微变化,即上文提及的细粒度时间线索,最终以多尺度特征形式竞争式地进行融合。正因如此,本发明的cptm模块具有自适应捕捉视频视觉节奏细微变化的能力。而协作式时空金字塔(即cstp模块)启发于tpn[16],以协作的方式自适应融合跨不同时空分辨率的时空特征,更好的捕捉粗粒度的时空线索。
[0044]
本发明将详细介绍如何构建本发明的2d ams网络和3d ams网络。
[0045]
2.具体方案
[0046]
2.1整体网络架构
[0047]
为了合理构建并广泛应用ams网络,本发明将所提出的cptm模块和cstp模块集成到现有的2d/3d深度卷积网络模型中,从而实例化两种体系结构,分别称为2d-ams网络和3d-ams网络。
[0048]
为了构建2d-ams网络,基于之前学者提出[8,9,3]的架构,在不同的卷积阶段间有选择性地插入cptm模块,提取当前连续卷积阶段间的特征的细粒度时间线索。具体而言,设为第l阶段第i残差块(res
l,i
)的输出,其中w表示宽度,h表示高度,t表示时间维度以及c表示通道数。那么cptm模块(f
cptm
)在该层输入特征χ
l,nl
所提取细粒度时间线索可以表示为:
[0049]
y(l)=f
cptm
(χ
l,nl
)
ꢀꢀꢀ
(1)
[0050]
其中,n
l
为res
l
的最后一个残差块,该输出y(l)为下一阶段res
l+1,1
的输入。而对于cstp模块,则将不同卷积阶段的时空特征,即不同时空分辨率特征进行自适应融合,在本发明中,为了效率和精度的权衡,本发明只融合了最后两个卷积阶段的输出。在下式(2)中,l表示深度卷积网络中阶段总数,z则用于融合特征后的最后预测:
[0051]
z=f
cstp
(y(l-1),y(l))
ꢀꢀꢀ
(2)
[0052]
而对于3d ams网络的构建,本发明将cptm模块和2d空间卷积以残差方式结合,构建出3d
cptm
层结构,如图1(b)中所示,通过3d
cptm
层代替残差网络中原有的3d卷积层,以达到提取细粒度时间线索目的。同2d ams网络一致的是,本发明仍然使用cstp模块融合最后两个卷积阶段的输出特征,即其中z同样表示自适应融合跨不同
时空分辨率的粗粒度特征信息。本发明所提出的ams网络就以上述两种方式建模自适应的多粒度时空线索。
[0053]
2.2细粒度cptm模块
[0054]
本发明提出的cptm模块用于自适应提取多尺度、细粒度的时间线索。现有的方法通常采用空洞卷积或平均聚合等方式多尺度时间建模。虽然,多尺度时间特征可以通过不同膨胀率的空洞卷积来表征,但权重共享的空洞卷积却很难充分捕捉时间特征尺度变化;同样地,若采用具有不同内核大小的非共享卷积,其计算负担随着卷积数量的增加而显著增加。因此,本发明的cptm模块利用几个具有相同内核大小,但非共享权重的渐进时间卷积提取时间特征,细节如图2所示,具体而言,如若给定输入特征χ,本发明cptm模块计算尺度k的时间特征表示为:
[0055]
yk=g(wk)
⊙yk-1
,k=1,
…
,k,
ꢀꢀꢀ
(3)
[0056]
其中,y0=χ且g(wk)表示权重为wk的时间卷积。因此,cptm可以获得一组多尺度特征{y1,
…
,yk}.与并行结构相比,cptm基于前一尺度提取特征,考虑了不同尺度特征间的相关性,同时具有较低的模型复杂性。接着,对于一组多尺度特征{y1,
…
,yk},本发明cptm模块提出竞争式融合机制,可表示为:
[0057][0058]
其中,维度为c的向量h通过对时空特征全局平均池化(gap),以捕获多时间尺度{y1,
…
,yk}的全局上下文关系,即}的全局上下文关系,即是通过两个权重分别为的全连接层计算得到;
⊙
表示沿通道维度的点积运算;特别地,τ是决定多尺度特征之间竞争或协作的一个平衡参数,容易看出,当τ趋近无穷时,融合更趋近于选择某一时间尺度,当τ=0时,所有时间尺度均等融合。
[0059]
综上,根据公式(3)和(4),提出的cptm模块具有在单分辨率特征图χ上自适应捕获细粒度时间线索y的能力。
[0060]
2.3粗粒度cstp模块
[0061]
为了基于更宏观、粗粒度的时空线索进行建模,受tpn[16]工作启发,本发明提出协作式时空金字塔模块,旨在于针对通过计算得到的不同时空分辨率的信息流,自适应的方式融合不同分辨率的时空特征。具体来说,根据给定的两个时空分辨率特征χi和χj,首先,通过充分考虑特征大小从而计算信息流动特征,对应生成一组对齐特征具体计算过程如下[16],为了使得不同时空分辨率特征大小对齐,第i阶段特征第j阶段特征其中和θ均由2d卷积层和时间池化层构成,获得对齐后的阶段特征其次,根据网络前向结构的自顶向下或自底向上的流动方向,通过核大小为1
×
1的2d卷积φi和φj,计算得到经过信息流动的对应阶段特征
或最终,为了充分聚合该组对齐特征本发明cstp模块采用两阶段自适应融合机制,如图3所示,最终用于预测特征z由下式计算得到:
[0062][0063]
其中,φ
up
、φ
dw
和φz是三个核大小为1
×
1的2d卷积层,而标识[
·
;
·
]表示特征间的连接操作。在公式(5)中,权重和由输入通过函数g1计算得到;接着,计算得到z
up
和z
dw
的作为输入通过函数g2计算出权重ω
up
和ω
dw
。特别地,函数g1、g2同公式(4)形式类似,同时值得注意的是,在函数g1和g2中平衡参数τ为0.5,使得cstp模块得以协作方式进行特征自适应融合。
[0064]
针对细粒度视频识别任务,本发明选用了细粒度数据集:跳水比赛数据集(diving48)[18]和细粒度体操数据集(finegym)[19]进行实验,实验结果达到了最先进的性能。接下来,将详细阐述本发明ams网络的实验细节和实施方式。
[0065]
一、ams网络模型构建
[0066]
为了构建2d-ams网络,本发明采用以残差网络(r50)[20]作为骨干网络模型,将本发明提出的细粒度时间建模模块cptm有选择性地插入不同的卷积阶段之间(如res2和res4之后);粗粒度跨时空分辨率特征融合则选择残差网络最后两个阶段输出作为时空特征,以平衡计算代价和效率。而构建3d-ams网络,本发明基于网络深度为50的慢通道网络作为骨干网络模型[1],其中,为了平衡计算代价和效率,在后两个卷积阶段,将3d
cptm
层每隔一个残差块地整体替换原始的3d卷积层,故在骨干网络基础上本发明使用了4个3d
cptm
层。
[0067]
二、数据准备
[0068]
针对细粒度视频数据集,本发明在跳水比赛数据集(diving48)和细粒度体操数据集(finegym)上进行广泛实验,其中对diving48数据集的旧版本(v1)和更新版本(v2)均进行了实验。为了数据增强,将采样的每一帧随机剪裁至224
×
224并伴有尺度抖动。而对于视频帧的采样,延续[6]和[1]设置,在2d-ams网络中,每个视频样本先均匀采样16段片段,每个片段分别随机提取一帧,获得跨越整个视频时间线的16帧;鉴于3d-ams网络,则采用以步长为4帧从连续64帧中采样16帧。在推理阶段,采样采用了多视图策略,即视频帧的多次随机剪裁及视频片段的多次采样,用于与最先进的方法性能的比较。
[0069]
三、深度网络模型的训练
[0070]
本发明提出的ams网络采用动量为0.9的随机梯度下降(sgd)优化器进行训练,学习率则采用衰减率为0.1的降台阶策略进行更新。对于16帧输入,2d/3d网络模型初始学习率分别设置为8e-3和5e-3,训练权重衰减分别为5e-4及1e-4,训练样本批量大小为48。本发明代码项目基于工具箱mmaction实现,运行于配置8张英伟达geforce rtx 2080ti gpus服务器。
[0071]
四、深度网络模型的预测
[0072]
本发明实施例的实验结果如表1和表2分别所示,该结果展示了多种最新方法在diving48数据集、finegym数据集的性能,视频识别方法包括上文提及方法以及corrnet[21]、gst[22]、selfy[23]、tqn[24]等方法以及本发明中的方法ams网络。结果表明,本发明所提出的方法在细粒度数据集相比其他方法能够取得更好的表现,取得最先进的性能,因而,说明在更具有难度的捕获时间线索数据集上,本发明方法仍具备优秀捕获复杂时间尺度变化的能力。
[0073]
综上所述,本发明中提出的基于自适应多粒度时空建模的细粒度视频识别方法ams网络,通过细粒度自适应时间建模和粗粒度时空特征自适应融合,具备较强的捕获复杂时间变化线索的能力;同时,本方法可以灵活的插入现有的深度卷积网络实例化,高效且轻量的实现视频动作识别任务,提高其性能。
[0074][0075][0076]
表1基于diving48数据集预测精度比较
[0077][0078]
表2基于finegym数据集预测精度比较
[0079]
7.其他资料
[0080]
参考文献
[0081]
[1]christoph feichtenhofer,haoqi fan,jitendra malik,andkaiming he.slowfast networks for video recognition.iniccv,2019.1,2,5,7,8.
recognition without representation bias.ineccv,2018.2,5.
[0099]
[19]dian shao,yue zhao,bo dai,and dahua lin.finegym:ahierarchical video dataset for fine-grained action understanding.in cvpr,2020.2,5.
[0100]
[20]kaiming he,xiangyu zhang,shaoqing ren,and jian sun.deep residual learning for image recognition.in cvpr,2016.5.
[0101]
[21]heng wang,du tran,lorenzo torresani,and matt feiszli.video modeling with correlation networks.in cvpr,2020.8.
[0102]
[22]chenxu luo and alan yuille.grouped spatial-temporal aggregationfor efficient action recognition.in iccv,2019.8.
[0103]
[23]heeseung kwon,manjin kim,suhakwak,and minsu cho.learning self-similarity in space and time as generalized motionfor video action recognition.in iccv,2021.7,8.
[0104]
[24]chuhan zhang,ankush gupta,and andrew zisserman.temporal query networks for fine-grained video understanding.in cvpr,2021.8.
[0105]
本发明并不限于上文描述的实施方式。以上对具体实施方式的描述旨在描述和说明本发明的技术方案,上述的具体实施方式仅仅是示意性的,并不是限制性的。在不脱离本发明宗旨和权利要求所保护的范围情况下,本领域的普通技术人员在本发明的启示下还可做出很多形式的具体变换,这些均属于本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1