一种基于视觉Transformer的小样本昆虫图像识别方法
一种基于视觉transformer的小样本昆虫图像识别方法
技术领域
1.本发明涉及一种基于视觉transformer的小样本昆虫图像识别方法,属于计算机视觉领域。
背景技术:
2.昆虫是地球上数量最多的动物群体,它们的种类繁多、形态各异。从人类自身利益的角度出发,这些昆虫总体上可以被分为害虫和益虫两大类别。害虫会危害农作物和观赏花卉的生长,给人类将会带来严重的经济损失,而益虫则可能为人类带来营养的食品或者丰富的工业材料。因此,对昆虫进行有效地识别对于保护生态环境以及促进社会生产发展具有重要意义。相比与传统的人工识别方法,基于计算机视觉技术的昆虫自动识别方法所耗费的人工成本将会大大降低,并且具有识别效率高,识别结果主观性小的优点。
3.近年来,随着深度学习技术的飞速发展,诸如图像分类、目标检测、语义分割等计算机视觉任务都取得突破性进展。具有强大特征表征能力的卷积神经网络也同样被应用到了昆虫识别领域,例如,皮家甜等(皮家甜,于昕,彭明杰,吴志友.基于区域建议网络的蜻蜓目昆虫识别方法.申请号:202110480792.7)公开了一种基于区域建议网络的蜻蜓目昆虫识别方法,该方法使用大容量卷积神经网络resnet50提取特征对蜻蜓目昆虫进行分类识别;陈彦彤(陈彦彤,王俊生,张献中.一种基于深度卷积神经网络的双翅目昆虫.申请号:202010471036.3)该方法采用retinanet目标检测模型,以resnext网络作为特征提取网络,在特征提取网络中加入改进注意力模块对双翅目昆虫进行分类识别。然而上述方法中仍然存在的技术问题如下:(1)对昆虫进行识别的类别仅限于蜻蜓目或者双翅目的昆虫,目前仍然缺乏包含昆虫四个目的图像数据集;(2)所使用的resnet 50或者resnext等卷积神经网络中所包含的参数容量大,需要大量的图像样本进行优化训练才能保证良好的识别性能。因此,为了克服在昆虫识别领域中存在的上述问题,需要公开一种基于视觉transformer的小样本图像识别方法来对昆虫图像进行分割从而完成对昆虫的分类识别。
技术实现要素:
4.针对上述现有技术存在的问题,本发明提供一种基于视觉transformer的小样本昆虫图像识别方法,从而解决上述技术问题。
5.为了实现上述目的,本发明采用的技术方案是:一种基于视觉transformer的小样本昆虫图像识别方法,包括以下步骤;
6.s1:昆虫数据集的构建,利用百度等图像搜索引擎搜索关于昆虫中七大元类别中各种昆虫的图像,然后对搜索后的图像人工标注标签,从而完成昆虫数据集的构建;
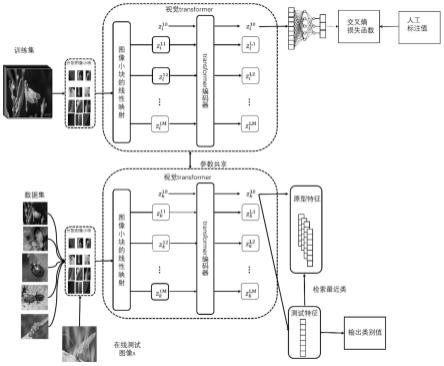
7.s2:预训练模型的构建,预训练模型主要是由图像小块的线性映射层、视觉transformer、全连接层和softmax层构成;
8.s3:预训练模型的优化,将昆虫数据集随机分为训练集、验证集和测试集,利用训练集对预训练模型中的参数进行优化训练;
9.s4:小样本昆虫识别模型的构建,移除预训练模型中的分类器,在训练集和测试集中随机抽取每类昆虫的少量图像样本,输入到视觉transformer中提取图像特征,计算每类样本的平均值作为每类昆虫图像原型特征进行存储;
10.s5:昆虫图像的在线测试,在线采集昆虫图像,输入到transformer中提取图像特征,计算其与每类昆虫图像表征之间的距离,其距离最近的昆虫类别就为此幅图像的类别输出。
11.进一步的,所述s1的具体步骤如下;
12.s11:将鞘翅目、鳞翅目、双翅目、膜翅目、半翅目、直翅目、蜻蜓目作为昆虫数据集中的元类别,对每个元类别中的20个小类别利用百度等图像搜索引擎搜索100幅图像;
13.s12:将所有图像统一归一化到224
×
224的尺寸,并对其类别进行人工标注。
14.进一步的,所述s2的具体步骤如下;
15.s21:图像小块的线性映射层的参数为投影系数矩阵其中p为图像小块的大小,c=3表示原始图像的通道数,d表示图像小块被线性映射后的维数;
16.s22:视觉transformer被表示为t
θ
,其中θ为参数,它是由l层的transformer编码器组成的,每层编码器是由规范化层、多头注意力以及多层感知器组成的。
17.进一步的,所述s3的具体步骤如下;
18.s31:将昆虫数据集随机分为训练集、验证集和测试集,训练集用于模型参数的优化,验证集用于超参数的整定,测试集由于小样本昆虫识别模型的构建;
19.s32:在训练集中随机抽取一批图像,此批图像中图像的总数为t,第i幅图像表示为xi,其对应的人工标注值为yi,以采样步长为s个像素将分辨率为h
×w×
c的图像分割为若干p
×
p大小的图像小块,假设图像小块的数目为m,将其转化为p2c维的向量并拼接起来得到大小为m
×
p2c的二维矩阵,则第i幅图像被表示为相应的坐标向量被表示为
20.s33:利用投影矩阵将其转换为d维的固定长度向量,此时第i幅图像被表示为插入与一个p2c的向量作为该幅图像的全局特征表示,此时第i幅图像的表示被转化为此时得到transformer编码器的第一层输入;
21.s34:对于编码器的第l层,记其输入为输出为则计算过程为:
[0022][0023][0024]
式中msa为多头自注意力(multi-head self-attention,msa),mlp为多层感知器(multi-layer perceptron,mlp),ln为规范化层(layer norm,ln);
[0025]
s35:将第l层的输出中的第1个向量输入到全连接层和softmax层中得到第i幅图像的类别概率输出值
[0026]
s36:将该批中其它图像同样依次按照步骤s32,s33、s34和s35进行处理,计算此批图像的总的交叉熵损失函数并利用交叉熵损失函数对模型中的参数进行优化。
[0027]
进一步的,所述s4的具体步骤如下;
[0028]
s41:移除预训练模型中的全连接层和softmax层;
[0029]
s42:在训练集、验证集和测试集中随机抽取每类昆虫的少量图像样本,每类昆虫图像样本的数目小于等于5,将其输入到预训练模型中,图像数据集中昆虫的总的类别数为n,每类被抽取的样本总数为k≤5,第n个昆虫类别中第k个图像表示为xk,同样以采样步长为s个像素将其分割为若干p
×
p大小的图像小块,然后经过线性映射层得到输入到l层的transformer编码器中得到将其中第1个向量作为此幅图像的特征表示;
[0030]
s43:计算k个图像样本特征的平均值作为每类昆虫的原型特征进行存储,即第n类昆虫的原型特征rn的计算公式为:
[0031][0032]
进一步的,所述s5的具体步骤如下;
[0033]
s51:在线采集昆虫图像x,以采样步长为s个像素将其分割为若干p
×
p大小的图像小块,然后经过线性映射层得到输入到l层的transformer编码器中得到将其中第1个向量作为此幅图像的特征表示;
[0034]
s52:计算图像x的特征与所存储的每类昆虫的原型特征之间的欧式距离,与第n个原型特征的计算公式为:
[0035][0036]
将距离最近的昆虫类别就为此幅图像的类别输出。
[0037]
本发明的有益效果是:本发明使用少量训练样本对昆虫完成分类识别,能够克服目前昆虫识别中所使用的卷积神经网络训练时需要大量的图像样本的技术问题;本发明使用视觉transform作为图像的特征提取器,能够克服昆虫在自然图像中被遮挡的问题。
附图说明
[0038]
图1为本发明的基于视觉transformer的小样本昆虫图像识别方法的流程图;
[0039]
图2为本发明的昆虫数据集示例图像;
[0040]
图3为本发明的视觉transformer的结构示意图。
具体实施方式
[0041]
为使本发明的目的、技术方案和优点更加清楚明了,下面通过附图及实施例,对本发明进行进一步详细说明。但是应该理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限制本发明的范围。
[0042]
除非另有定义,本文所使用的所有的技术术语和科学术语与属于本发明的技术领
域的技术人员通常理解的含义相同,本文中在本发明的说明书中所使用的术语只是为了描述具体的实施例的目的,不是旨在于限制本发明。
[0043]
如图1所示,一种基于视觉transformer的小样本昆虫图像识别方法,包括以下步骤;
[0044]
s1:昆虫数据集的构建,
[0045]
s11:将鞘翅目、鳞翅目、双翅目、膜翅目、半翅目、直翅目、蜻蜓目作为昆虫数据集中的元类别,对每个元类别中的20个小类别利用百度等图像搜索引擎搜索100幅图像;数据集中每个元类别中的示例图像如图2所示;
[0046]
s12:将所有图像统一归一化到224
×
224的尺寸,并对其类别进行人工标注;
[0047]
s2:预训练模型的构建,
[0048]
s21:图像小块的线性映射层的参数为投影系数矩阵其中p为图像小块的大小,c=3表示原始图像的通道数,d表示图像小块被线性映射后的维数;
[0049]
s22:视觉transformer被表示为t
θ
,其中θ为参数,它是由l层的transformer编码器组成的,每层编码器是由规范化层、多头注意力以及多层感知器组成的,结构图如图3所示;
[0050]
s3:预训练模型的优化,将昆虫数据集随机分为训练集、验证集和测试集,利用训练集对预训练模型中的参数进行优化训练;
[0051]
s31:将昆虫数据集随机分为训练集、验证集和测试集,训练集用于模型参数的优化,验证集用于超参数的整定,测试集由于小样本昆虫识别模型的构建;
[0052]
s32:在训练集中随机抽取一批图像,此批图像中图像的总数为t,第i幅图像表示为xi,其对应的人工标注值为yi,以采样步长为s个像素将分辨率为h
×w×
c的图像分割为若干p
×
p大小的图像小块,假设图像小块的数目为m,将其转化为p2c维的向量并拼接起来得到大小为m
×
p2c的二维矩阵,则第i幅图像被表示为相应的坐标向量被表示为
[0053]
s33:利用投影矩阵将其转换为为d维的固定长度向量,此时第i幅图像被表示为插入与一个p2c的向量作为该幅图像的全局特征表示,此时第i幅图像的表示被转化为此时得到transformer编码器的第一层输入;
[0054]
s34:对于编码器的第l层,记其输入为输出为则计算过程为:
[0055][0056][0057]
式中msa为多头自注意力(multi-head self-attention,msa),mlp为多层感知器(multi-layer perceptron,mlp),ln为规范化层(layer norm,ln);
[0058]
s35:将第l层的输出中的第1个向量输入到全连接层
和softmax层中得到第i幅图像的类别概率输出值
[0059]
s36:将该批中其它图像同样依次按照步骤s32,s33、s34和s35进行处理,计算此批图像的总的交叉熵损失函数并利用交叉熵损失函数对模型中的参数进行优化;
[0060]
s4:小样本昆虫识别模型的构建,
[0061]
s41:移除预训练模型中的全连接层和softmax层;
[0062]
s42:在训练集、验证集和测试集中随机抽取每类昆虫的少量图像样本,每类昆虫图像样本的数目小于等于5,将其输入到预训练模型中,图像数据集中昆虫的总的类别数为n,每类被抽取的样本总数为k≤5,第n个昆虫类别中第k个图像表示为xk,同样以采样步长为s个像素将其分割为若干p
×
p大小的图像小块,然后经过线性映射层得到输入到l层的transformer编码器中得到将其中第1个向量作为此幅图像的特征表示;
[0063]
s43:计算k个图像样本特征的平均值作为每类昆虫的原型特征进行存储,即第n类昆虫的原型特征rn的计算公式为:
[0064][0065]
s5:昆虫图像的在线测试,在线采集昆虫图像,输入到transformer中提取图像特征,计算其与每类昆虫图像表征之间的距离,其距离最近的昆虫类别就为此幅图像的类别输出。
[0066]
s51:在线采集昆虫图像x,以采样步长为s个像素将其分割为若干p
×
p大小的图像小块,然后经过线性映射层得到输入到l层的transformer编码器中得到将其中第1个向量作为此幅图像的特征表示;
[0067]
s52:计算图像x的特征与所存储的每类昆虫的原型特征之间的欧式距离,与第n个原型特征的计算公式为:
[0068][0069]
将距离最近的昆虫类别就为此幅图像的类别输出。
[0070]
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换或改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1