一种全链路数据整合方法及系统与流程
1.本发明涉及计算机物联网领域,尤其涉及一种全链路资源数据整合方法及系统。
背景技术:
2.行业内存在大量的业务系统和物联设备,目前已有大量的存量数据,系统和物联设备运行随时产生增量数据。但是当前情况是数据分散,标准缺失,缺乏技术手段对数据汇聚处理,无法形成统一有效、有价值的数据。在当前数据作为生产资料的时代,如何有效汇聚、处理数据,形成行业的数据资产目录,并通过数据服务能力,提高各部门之间、以及本部门与其他部门之间的业务协同能力,对行业具有重大意义。
技术实现要素:
3.本发明主要解决的技术问题是提供一种数据整合和价值变现系统,本发明的系统通过数据引接、数据处理、数据编目、数据服务功能,实现资源类数据的整合和价值变现。通过引接业务系统、物联设备数据形成数据资源池,通过数据质量检测方法判断数据质量,通过数据分层分域、标准转换、去重等规则处理数据形成资源数据编目,最终通过零编码的数据服务功能提供数据价值变现的通道。本发明通过引接、处理数据,形成资源数据编目,并以灵活的方法提供数据服务,提高数据在业务联动中的利用价值。
4.本发明的技术方案为:一种全链路数据整合方法,包括如下步骤:
5.步骤1、通过引接业务系统、物联设备数据形成数据资源池;
6.步骤2、通过数据质量检测方法判断数据质量;
7.步骤3、通过数据分层分域、标准转换、去重处理数据形成资源数据编目;
8.步骤4、最终通过零编码的数据服务功能提供整合后的数据。
9.根据本发明的另一方面,提出一种全链路数据整合系统,包括:数据源模块、任务调度模块、数据引接模块、数据处理模块、数据编目模块和数据服务模块,通过各个模块协作配合,整合数据全链路数据;其中,
10.数据源模块利用classloader技术,采用插件化机制,在内存中对不同的数据库驱动隔离管理,避免冲突;提供数据源sdk给有数据查询需求的功能模块,即数据引接模块和数据处理模块,实现数据源动态加载;
11.任务调度模块采用分布式调度技术,调度作为master,执行方作为worker,可配置任务调度周期,按照年月日时分周期调度数据处理和数据服务任务,master利用分布式锁控制worker调度和执行,多个worker采用伪分布式机制,采用单点部署,或
‑‑‑
根据并发量扩展多个worker节点。
12.数据引接模块包括数据库引接、物联设备数据实时采集和消息中间件数据引接,其中数据库引接模块引用数据源sdk,通过数据库提供的jdbc接口引接数据、物联设备数据引接通过适配物联设备协议,实时引接物联数据写入消息中间件,消息中间件数据引接通过订阅消费模式,监听消息中间件topic,实时消费数据;
13.数据处理模块通过组件化配置方式,可视化设计数据处理流程,包括去重、字符串替换、json解析、时间格式转换等,提交到任务调度模块;
14.数据编目根据业务梳理数据资源分类,按照树型结构编排目录体系,形成资源数据资产,数据开发者选择数据资产对外发布;
15.数据服务模块以零编码的方式,提供可视化sql编辑窗口,数据开发者编写sql并发布为数据服务,数据服务经审核通过后向其他数据需求方提供查询和订阅功能,数据需求方根据数据服务开发规范调用数据服务接口获取数据。
16.有益效果:
17.本发明提供的系统为行业构建完善、共享、统一管理数据环境提供基本保障,实现把行业的业务数据、感知数据等数据作为资产管理的有效手段。
附图说明
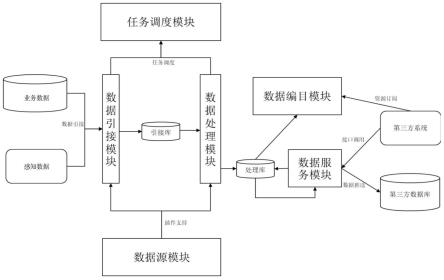
18.图1系统整体架构图;
19.图2数据源模块架构图;
20.图3任务调度模块架构图;
21.图4数据引接模块架构图;
22.图5数据处理模块架构图。
具体实施方式
23.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的描述,显然,所描述的实施例仅为本发明的一部分实施例,而不是全部的实施例,基于本发明中的实施例,本领域的普通技术人员在不付出创造性劳动的前提下所获得的所有其他实施例,都属于本发明的保护范围。
24.为解决上述技术问题,参见图1,本发明全链路数据整合系统包括:数据源模块、任务调度模块、数据引接模块、数据处理模块、数据编目模块和数据服务模块。通过各个模块协作配合,形成数据全链路整合过程。
25.其中,数据源模块、数据引接模块、数据处理模块、数据服务模块是全链路中的关键模块,本发明创新设计了数据源模块,数据源模块适配数据库、中间件、文件系统,并对数据引接、数据处理模块、数据服务模块提供标准的rest接口,减少数据源适配的二次开发适配工作量。参见图1,其中包括多个数据流向:
26.数据流向1,数据引接模块从数据源读取源的连接信息;
27.数据流程2,数据引接模块从数据源读取数据并写入到引接库;
28.数据流向3,数据处理模块从引接库读取数据,经过清洗转换处理后讲处理后数据写入到数据库;
29.数据流向4,数据服务模块读取处理库的表数据,并将表数据封装为数据服务接口对外提供发布;
30.数据流向5,第三方系统调用数据服务接口获取数据或者由数据服务模块推送数据到指定数据库。
31.其他说明:数据编目模块是非关键模块,此模块组织数据,可提供查看和订阅服
务,不在主数据链路上。
32.如图2所示,其中,数据源模块利用类加载器classloader技术,采用插件化机制,在内存中对不同的数据库驱动隔离管理,避免冲突。提供数据源sdk给有数据查询需求的功能模块,即数据引接模块和数据处理模块,实现数据源动态加载。
33.所述数据源包括mysql、oracle、postgresql、mssql、db2、达梦、kingbase、greenplum、gaussdb、gbase8a、gbase8t、神通cluster、tbase、clickhouse、hive、hbase、kafka、mongdbdb等。
34.如图3所示,任务调度模块采用分布式调度技术,调度作为master,执行方,执行服务即使数据接引模块、数据处理模块和数据服务模块。可配置任务调度周期,按照年月日时分周期调度数据处理和数据服务任务。master利用分布式锁控制执行服务的调度和执行,多个执行服务采用伪分布式机制,可单点部署,也可根据并发量扩展多个执行节点的个数。执行服务通过task queue和执行服务交互,将消息写入task queue,执行服务读取task queue中的消息,根据消息执行具体任务。
35.如图4所示,数据引接模块用于进行数据库、kafka中间件、csv/excel文件以及其他文件的数据引接。数据引接分为应用层、执行层和业务库层。应用层即是图3所描述的调度模块,执行层即是数据引接服务的具体实现,采用分布式计算引擎spark,通过批量和实时两种数据方式读取数据,业务库层存储数据引接模块的任务配置数据,其中流程配置存储在资源库中,数据引接任务的基本信息和调度信息存储在调度库中。
36.如图5所示,数据处理模块分为应用层、执行层和业务库层,应用层即是图3所描述的调度模块,执行层即是数据处理服务的具体实现,采用分布式计算引擎spark,在模块中实现清洗、转换、关联用的具体逻辑,业务库层存储数据处理模块的任务配置数据,其中流程配置存储在资源库中,数据处理任务基本信息和调度信息存储在调度库中。
37.数据编目根据行业梳理数据资源分类,按照树型结构编排目录体系,形成数据资产,数据开发者选择数据资产对外发布。
38.数据服务模块以零编码的方式,提供可视化sql编辑窗口,数据开发者编写sql并发布为数据服务。数据服务经审核通过后向其他数据需求方提供查询和订阅功能。数据需求方根据数据服务开发规范调用数据服务接口获取数据。
39.根据本发明的另一方面,提出一种全链路数据整合方法,包括如下步骤:
40.步骤1、配置数据源连接信息,测试数据源连通性,采集数据源的库表字段、中间件topic、文件系统目录文件路径和文件名等基本描述信息。
41.步骤2、配置数据引接任务的数据接收目标,如数据库、中间件topic。
42.步骤3、配置数据引接任务,并配置调度周期。
43.步骤4、调度数据引接任务,读取源端数据到引接库。
44.步骤5、配置数据处理任务的数据接收目标。
45.步骤6、配置数据处理任务,并配置调度周期。
46.步骤7、调度数据处理任务,读取并处理数据,处理后的数据写入处理库。
47.步骤8、配置数据服务,并发布数据服务。
48.步骤9、第三方系统订阅数据服务。
49.步骤10、第三方系统调用数据服务接口或者由全链路整合和价值变现系统推送数
据。
50.尽管上面对本发明说明性的具体实施方式进行了描述,以便于本技术领域的技术人员理解本发明,且应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1