行业专业文本自动标注方法、装置、终端及存储介质与流程
1.本发明属于一种文本标注方案,具体为一种基于数据增强的行业专业文本自动标注方法、装置、终端及存储介质,涉及文本实体识别技术领域。
背景技术:
2.在文本实体识别领域中,文本标注是一项重要技术,其能够对文本进行语义标注,构建起词到语义概念的映射。在后续的文本处理过程中,操作者即便只对文本进行浅层分析,也能够根据映射判断文本在语义概念空间上的分布,进而为文本的管理、搜索和推荐提供切实的基础。
3.目前,深度学习和机器学习等人工智能算法已经逐步成为了文本实体识别领域内的主流技术,在领域内得到了广泛应用。但这类技术在应对专业领域和行业专业文本实体的文本标注时,算法的最终效果往往无法达到预期。这是因为对于这些专业度较高的文本而言,标注语料的数量、质量及泛化能力等因素直接决定着文本标注的效果,而现阶段的各类自动化技术手段在专业性方面的表现并不如人工标注。也正因如此,现阶段业内对于各类行业专业文本的标注仍然以人工标注方式为主。
4.可以预见地,人工标注方法在实际操作过程中存在着几个明显的不足:首先,人工标注方法对于标注人员的专业性要求过高。人工标注不仅需要标注人员在专业领域内具备一定程度的专业知识,还要求标注人员能够进行大量的手工专业信息提取、判断和标注,从而极大地提高了专业领域内的文本标注成本。
5.其次,人工标注方法的效率和质量难以保证。人工标注需要标注人员在文本中进行全文信息检索,寻找并定位具体的实体位置,再进行实体类型标注。整个操作过程效率偏低,且极容易出现实体遗漏和类型错误等问题。
6.最后,人工标注方法的泛化能力较差。在专业领域和行业专业文本的分类过程中,领域和行业的边界往往存在动态性、模糊性和不确定性,人工标注工作一旦开展,过程中就很难再对标注实体的数量、类型和定义等进行调整,最终导致标注样本整体的泛化能力差。
7.综上所述,如果能够在目前已有的各类自动化文本标注方案的基础上,利用互联网上开放的知识和知识库信息,结合数据增强、半监督实体识别等技术手段,实现专业领域内行业专业文本的自动标注,那么必将极大地提升行业专业文本的标注效率和质量。
技术实现要素:
8.鉴于现有技术存在上述缺陷,本发明的目的是提出一种基于数据增强的行业专业文本自动标注方法、装置、终端及存储介质,具体如下。
9.一种行业专业文本自动标注方法,包括:依据初始关键词词袋在专业文本库中进行关键词检索,得到拓展文本信息,对所述拓展文本信息进行实体识别,得到外部智库初始拓展词袋;逐一比较所述外部智库初始拓展词袋中拓展词与所述初始关键词词袋中实体词
的词向量是否相似,依据比较结果分别得到外部智库拓展词袋和外部智库拓展噪音词袋;利用所述外部智库拓展噪音词袋对所述外部智库拓展词袋进行噪音实体特征内插,得到内插实体泛化样本,基于所述初始关键词词袋对所述外部智库拓展词袋进行噪音语句特征外插,得到外插语句泛化样本;针对所述内插实体泛化样本和所述外插语句泛化样本进行逆向文本标注定位,得到专业实体标注样本。
10.优选地,所述依据初始关键词词袋在专业文本库中进行关键词检索,得到拓展文本信息,对所述拓展文本信息进行实体识别,得到外部智库初始拓展词袋,包括:获取词汇实体,整理得到初始关键词词袋,所述初始关键词词袋依据词性分类要求被划分为多种类型的小词袋;利用所述初始关键词词袋,在专业文本库中进行关键词检索,得到拓展文本信息,所述拓展文本信息中拓展样本对应每种类型所述小词袋的样本数量相近似;利用实体识别技术对所述拓展文本信息进行实体信息识别,得到外部智库初始拓展词袋。
11.优选地,所述逐一比较所述外部智库初始拓展词袋中拓展词与所述初始关键词词袋中实体词的词向量是否相似,依据比较结果分别得到外部智库拓展词袋和外部智库拓展噪音词袋,包括:利用卷积神经网络对所述外部智库初始拓展词袋中的拓展词与所述初始关键词词袋中的实体词进行高维向量空间中的向量计算,依据计算结果识别出真实实体标注样本及噪音实体标注样本;将全部所述真实实体标注样本汇总整理得到外部智库拓展词袋,将全部所述噪音实体标注样本汇总整理得到外部智库拓展噪音词袋。
12.优选地,所述利用所述外部智库拓展噪音词袋对所述外部智库拓展词袋进行噪音实体特征内插,得到内插实体泛化样本,基于所述初始关键词词袋对所述外部智库拓展词袋进行噪音语句特征外插,得到外插语句泛化样本,包括:从所述外部智库拓展噪音词袋随机挑选噪音实体样本插入所述外部智库拓展词袋内所述真实实体标注样本中,得到内插实体泛化样本;选择包含有所述初始关键词词袋内词汇实体的噪音语句插入所述外部智库拓展词袋内所述真实实体标注样本中,得到外插语句泛化样本。
13.一种行业专业文本自动标注装置,包括:初始拓展词袋生成模块,被配置为依据初始关键词词袋在专业文本库中进行关键词检索,得到拓展文本信息,对所述拓展文本信息进行实体识别,得到外部智库初始拓展词袋;拓展词袋及拓展噪音词袋生成模块,被配置为逐一比较所述外部智库初始拓展词袋中拓展词与所述初始关键词词袋中实体词的词向量是否相似,依据比较结果分别得到外部智库拓展词袋和外部智库拓展噪音词袋;泛化样本生成模块,被配置为利用所述外部智库拓展噪音词袋对所述外部智库拓展词袋进行噪音实体特征内插,得到内插实体泛化样本,基于所述初始关键词词袋对所述外部智库拓展词袋进行噪音语句特征外插,得到外插语句泛化样本;
专业实体标注模块,被配置为针对所述内插实体泛化样本和所述外插语句泛化样本进行逆向文本标注定位,得到专业实体标注样本。
14.优选地,所述初始拓展词袋生成模块,包括:初始关键词词袋获取单元,被配置为获取词汇实体,整理得到初始关键词词袋,所述初始关键词词袋依据词性分类要求被划分为多种类型的小词袋;拓展文本信息获取单元,被配置为利用所述初始关键词词袋,在专业文本库中进行关键词检索,得到拓展文本信息,所述拓展文本信息中拓展样本对应每种类型所述小词袋的样本数量相近似;外部智库初始拓展词袋生成单元,被配置为利用实体识别技术对所述拓展文本信息进行实体信息识别,得到外部智库初始拓展词袋。
15.优选地,所述拓展词袋及拓展噪音词袋生成模块,包括:拓展词袋生成单元,被配置为利用卷积神经网络对所述外部智库初始拓展词袋中的拓展词与所述初始关键词词袋中的实体词进行高维向量空间中的向量计算,依据计算结果识别出真实实体标注样本及噪音实体标注样本;拓展噪音词袋生成单元,被配置为将全部所述真实实体标注样本汇总整理得到外部智库拓展词袋,将全部所述噪音实体标注样本汇总整理得到外部智库拓展噪音词袋。
16.优选地,所述泛化样本生成模块,包括:内插实体泛化样本生成单元,被配置为从所述外部智库拓展噪音词袋随机挑选噪音实体样本插入所述外部智库拓展词袋内所述真实实体标注样本中,得到内插实体泛化样本;外插语句泛化样本生成单元,被配置为选择包含有所述初始关键词词袋内词汇实体的噪音语句插入所述外部智库拓展词袋内所述真实实体标注样本中,得到外插语句泛化样本。
17.一种终端,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如上所述行业专业文本自动标注方法中的步骤。
18.一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行所述计算机程序时实现如上所述行业专业文本自动标注方法中的步骤。
19.本发明的优点主要体现在以下几个方面:本发明所提出的一种基于数据增强的行业专业文本自动标注方法,利用半监督实体识别算法,结合外部专业的知识文本库,最大限度上降低了文本实体标注的人工成本,提升了文本实体识别过程中建模的质量和效率。同时,本发明的方法还使用了具有通用性的实体识别算法,结合特定的词袋高维向量化相似度计算技术,使得前期的文本实体识别过程能够以自动化的方式开展,可以在多个不同的专业领域内实现高质量的实体信息提取。此外,本发明的方法基于数据增强技术,通过噪音实体特征内插和噪音语句特征外插技术,大幅优化了传统无监督自动标注算法所存在的泛化能力不足的问题,使得标注模型可以在多种不同的行业专业文本上实现半监督自动标注。
20.与上述方法相对应的,本发明所提出的一种基于数据增强的行业专业文本自动标
注装置、终端及存储介质,能够以系统化、标准化的处理流程,高效、准确地完成对行业专业文本的标注,硬件的适配性和兼容性较高,能够切实地应用于文本标注领域内的技术实现中。
21.本发明还为其他与文本标注技术相关的方案提供了参考,可以以此为依据进行拓展延伸和深入研究,具有十分广阔的应用前景。
22.以下便结合实施例附图,对本发明的具体实施方式作进一步的详述,以使本发明技术方案更易于理解、掌握。
附图说明
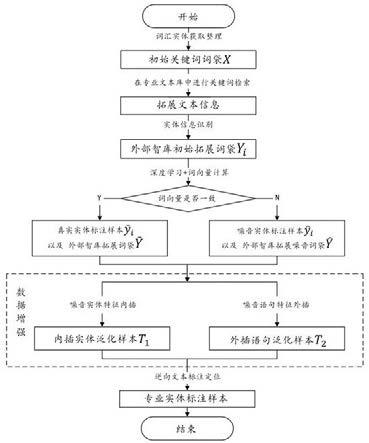
23.构成本技术的一部分的附图用来提供对本技术的进一步理解,使得本技术的其它特征、目的和优点变得更明显。本技术的示意性实施例附图及其说明用于解释本技术,并不构成对本技术的不当限定。在附图中:图1为本发明实施例提供的一种行业专业文本自动标注方法的流程示意图;图2为本发明实施例中按方法进行初始关键词词袋整理的结果示意图;图3为本发明实施例中所选取的命名实体识别算法模型的结构示意图;图4为本发明实施例中所建立的噪音识别模型的网络结构示意图;图5为本发明实施例提供的一种行业专业文本自动标注装置的结构示意图。
具体实施方式
24.本发明揭示了一种基于数据增强的行业专业文本自动标注方法、装置、终端及存储介质,具体方案如下。
25.一方面,本发明涉及一种行业专业文本自动标注方法,具体流程如图1所示,包括如下步骤:s1、依据初始关键词词袋在专业文本库中进行关键词检索,得到拓展文本信息,对所述拓展文本信息进行实体识别,得到外部智库初始拓展词袋。进一步而言,这一步骤具体包括如下操作。
26.s11、获取词汇实体,依据预先设置的、基于专业人员人工经验而形成的标准,整理得到一个小规模的初始关键词词袋。
27.所述初始关键词词袋 依据具体的词性分类要求可以被划分为多种类型的小词袋 ,例如产品实体词袋、技术实体词袋、领域实体词袋等。为了保证后续词袋向量表示的多样性和鲁棒性,每个类型的小词袋中的词汇实体不可重复,且实体数应不低于50个。
28.例如,需要对“智能穿戴”领域的文本进行实体识别算法开发,传统做法是召集了解的“智能穿戴”领域的标注人员人工进行文本标注,本方案只需要依据“智能穿戴”领域内专业人员的人工经验,整理一个由不同实体类型组成的小规模关键词袋即可,整理结果如图2所示。
29.s12、利用所述初始关键词词袋 ,在专业文本库中进行关键词检索,得到拓展文本信息,所述拓展文本信息中拓展样本对应每种类型所述小词袋 的样本数量相近似。
30.考虑到专业文本中往往包含多个不同的专业实体信息,例如在包含“穿戴设备”的
专利文件中,往往还包含“穿戴设备”相关的技术、领域、产品、原材料等其它扩展实体。因此,需要利用所述初始关键词词袋 ,前往搜索引擎、专利检索库等专业智库进行关键词检索,由此可以得到大量的包含词汇实体的扩展文本信息。
31.为了保证后续强化学习模型能够有足够多的训练样本,此步骤中所选取的、用于关键词检索扩展的专业智库的文本数量应不低于10000条。同时,为了尽量保证扩展样本能涵盖不同的实体类型,此处检索出的拓展文本信息应保证扩展样本中匹配每种类型小词袋 的样本数量尽量均匀、且每种类型样本数量尽量应大于1000条。
32.s13、利用实体识别技术对所述拓展文本信息进行实体信息识别,得到外部智库初始拓展词袋 。
33.考虑到专业文本中包含大量与目标实体相近似的实体信息,在此步骤中利用通用的实体识别技术(named entity recognition,ner)对所述拓展文本信息中的实体信息进行识别。本实施例中选取在命名实体识别算法中效果较为稳定的是bert+bilstm+crf的3层模型结构,模型整体框架如图3所示。
34.第一层bert使用transformer机制对输入数据进行编码,使用预训练模型获取字的语义表示。transformer与传统的序列对齐递归神经网络或卷积神经网络的转换模型不同,是一个完全依赖自注意力机制(attention)计算输入和输出的表示。自注意力层的计算公式如下,式中 为query向量组合的矩阵, 为key向量组合的矩阵, 为value向量组合的矩阵, 为query向量的维度。
35.,第二层bilstm层在bert输出结果的基础上进一步提取数据的高层特征。此处之所以使用bilstm算法是为了更好地捕捉特征实体在专业文本中的上下文信息。
36.第三层crf是全局范围内统计归一化的条件状态转移概率矩阵,对bilstm层的输出结果进行状态转移约束,让底层深度神经网络在crf的特征限定下,依照新的损失函数,学习出一套更合理的非线性变换空间。
37.s2、逐一比较所述外部智库初始拓展词袋中拓展词与所述初始关键词词袋中实体词的词向量是否相似,依据比较结果分别得到外部智库拓展词袋和外部智库拓展噪音词袋。进一步而言,这一步骤具体包括如下操作。
38.s21、利用卷积神经网络对所述外部智库初始拓展词袋 中的拓展词 与所述初始关键词词袋中的实体词进行高维向量空间中的向量计算,依据计算结果进行识别,若相似则认定所述拓展词 为真实实体标注样本 、若不相似则认定所述拓展词 为噪音实体标注样本 。
39.具体而言,为了保证噪音识别效果,同时兼顾实际运行中的计算的速度,本实施例设计了一套单层的cnn神经网络模型作为噪音识别模型,具体的网络结构设计如图4所示。
40.其中,本实施例中所使用的词向量转化工具为腾讯词向量库,它可以将每个词对
应一个200维的向量,与其他现有的中文词向量数据相比,腾讯词向量库提升了整体词向量的覆盖率、新鲜度、准确性。在完成词向量转化后,就可以将单个词向量组装成输入词袋向量,词袋向量长度固定为n,即一个词袋由n个词组成(如超出n则截断,小于n则用空白字符填充)的输入向量。每个词的特征由其本身的词向量(d_word维向量)及其分别距离两个实体的位置向量(d_pos维向量)串联而成。卷积核在词粒度对3个连续的词的词向量和位置向量进行卷积操作,卷积核大小为3*(d_word+2*d_pos)。
41.上述基于卷积神经网络的分类模型的参数包括卷积层和全连接层的权重和偏移项,故模型参数集合 ,则输出的某句子属于某关系类型的概率如下式所示,其中,代表由模型划分出来的词袋, 代表词袋中的某一个实体,下标 和 分别代表真实实体和噪音实体。
42.ꢀꢀ
,在给定训练集 ,模型参数 ,模型的损失函数设计为如下公式所示。
43.。
44.s22、将全部所述真实实体标注样本 汇总整理得到外部智库拓展词袋 ,将全部所述噪音实体标注样本 汇总整理得到外部智库拓展噪音词袋 。
45.s3、利用所述外部智库拓展噪音词袋对所述外部智库拓展词袋进行噪音实体特征内插,得到内插实体泛化样本,基于所述初始关键词词袋 对所述外部智库拓展词袋 进行噪音语句特征外插,得到外插语句泛化样本。
46.由于无监督环境下算法极容易捕捉到专业文本(如专利文本)的特定特征,使得最终算法只能在特定文本(如专利文本)下具有较好的标注效果,模型整体泛化能力较差。因此,为解决标注模型泛化能力不足的问题,此处需要在外部智库扩展词袋 的特征空间中采用特定的数据增强技术。
47.与简单的向量噪音添加方法(如添加高斯噪音)不同,本方案中采用了针对专业文本的特定数据增强方法,进一步而言,这一步骤具体包括如下操作。
48.s31、在同类别实体间,随机从噪音实体词袋 中挑选1-2个特征空间相似程度较高的噪音实体插入到所述外部智库拓展词袋 的真实实体之间,从而达到降低关联实体间空间相关性的效果、得到内插实体泛化样本 。
49.上述操作主要考虑的是在专业文本中,实体间密度要远高于普通的新闻类文本,这也导致了模型在识别标注实体时非常容易学习到实体间的空间特征。
50.操作具体表现为,在内插实体选择中,插入的噪音实体主要通过在噪音实体词袋 中选择与2个真实实体间空间向量表示最接近的噪音实体。假设有两个真实实体 和 ,其在n维向量空间中的表示分别是 和 。
51.获取随机的n维权重矩阵 ,选取 ,则内插噪音实体的n为向量表示 应当满足如下表达式,即选择的噪音实体应当在高维空间表示中尽量与真实实体 和 接近,从而达到最好的泛化效果。
52.,在插入实体位置选择中,插入的噪音实体位置应当尽量处于真实实体 和 的中间位置,从而使得噪音实体的泛化影响对于两个真实实体的影响尽可能相似,数学表达式如下所示。
53.。
54.s32、选择包含有所述初始关键词词袋 内词汇实体的噪音语句插入所述外部智库拓展词袋 内所述真实实体标注样本中,得到外插语句泛化样本 。
55.由于专业文本的行文方式与其他文本存在巨大差异,专业文本的整体特征也会被深度学习算法捕捉,从而不利于在其他类型的专业文本或非专业文本中进行标注识别。因此,为了提高标注算法在不同类型文本中的标注效果,还需要在实体外进行噪音语句的插入,以降低专业文本整体特征对算法泛化能力的影响。
56.在噪音语句的选择中,本方案中选择的是包含人工词袋 的其他类型的文本语句,不仅可以添加特征差异的噪音语句,也可以尽量使得噪音语句与原语句间存在一定的特征一致性。
57.例如,在原语句中包含“激光束扫描显示投影元件”和“全息投影镜片”这两个实体,为了增强算法通过上下文关系识别这两个实体的泛化能力,我们会在该句前插入一句其他类型文本的语句,要求是插入的句子中应包含人工词袋 的一个或多个词。
58.此处还有一个实现技巧,如果希望模型在特定类型的文本中获得更强的泛化能力,则外插语句可以从该类型文本中获得。例如,如果希望模型在新闻类型的文本中泛化能力更强,则外插语句可从新闻文本中提取。
59.s4、针对所述内插实体泛化样本和所述外插语句泛化样本进行逆向文本标注定位,得到专业实体标注样本。
60.综上所述,本发明所提出的一种行业专业文本自动标注方法,与现有技术中的人工标注及传统监督式文本标注方法相比,具有以下几个方面的优点:1、技术实现成本更低。传统的对于行业专业文本的标注方法需要标注人员进行人工标注,不仅会耗费大量的时间成本,其标注结果也可能存在一定的错漏,无法满足实际生产中大批量专业实体识别的要求。本发明的方法利用半监督实体识别算法,结合外部专业
的知识文本库,最大限度上降低了文本实体标注的人工成本,提升了实际文本实体识别过程中模型构建的质量和效率。
61.2、文本标注质量更高。传统的针对专业领域的文本实体标注往往都需要标注人员具备特定领域内的专业知识,从而对标注工作提出了很高的要求。本发明的方法中使用了具有通用性的实体识别算法(ner),结合特定的词袋高维向量化相似度计算技术,使得前期的文本实体识别过程不需要标注人员进行干预,理论上可以在多个不同的专业领域内实现高质量的实体信息提取。
62.3、泛化能力更强。传统的文本自动标注技术往往只能针对单一特定文本进行标注,当文本类型或文本质量发生变化时,标注算法往往无法在新的标注集上取得较好的标注结果。本发明的方法基于数据增强技术,通过噪音实体特征内插和噪音语句特征外插技术,大幅优化了传统无监督自动标注算法所存在的泛化能力不足的问题,使得标注模型可以在多种不同的行业专业文本上实现半监督自动标注。
63.另一方面,本发明还涉及一种行业专业文本自动标注装置,其架构如图5所示,包括:初始拓展词袋生成模块,被配置为依据初始关键词词袋在专业文本库中进行关键词检索,得到拓展文本信息,对所述拓展文本信息进行实体识别,得到外部智库初始拓展词袋;拓展词袋及拓展噪音词袋生成模块,被配置为比较所述外部智库初始拓展词袋中拓展词与所述初始关键词词袋中实体词的词向量是否相似,依据比较结果分别得到外部智库拓展词袋和外部智库拓展噪音词袋;泛化样本生成模块,被配置为利用所述外部智库拓展噪音词袋对所述外部智库拓展词袋进行噪音实体特征内插,得到内插实体泛化样本,基于所述初始关键词词袋对所述外部智库拓展词袋进行噪音语句特征外插,得到外插语句泛化样本;专业实体标注模块,被配置为针对所述内插实体泛化样本和所述外插语句泛化样本进行逆向文本标注定位,得到专业实体标注样本。
64.所述初始拓展词袋生成模块,包括:初始关键词词袋获取单元,被配置为获取词汇实体,整理得到初始关键词词袋,所述初始关键词词袋依据词性分类要求被划分为多种类型的小词袋;拓展文本信息获取单元,被配置为利用所述初始关键词词袋,在专业文本库中进行关键词检索,得到拓展文本信息,所述拓展文本信息中拓展样本对应每种类型所述小词袋的样本数量相近似;外部智库初始拓展词袋生成单元,被配置为利用实体识别技术对所述拓展文本信息进行实体信息识别,得到外部智库初始拓展词袋。
65.所述拓展词袋及拓展噪音词袋生成模块,包括:拓展词袋生成单元,被配置为利用卷积神经网络对所述外部智库初始拓展词袋中的拓展词与所述初始关键词词袋中的实体词进行高维向量空间中的向量计算,依据计算结果识别出真实实体标注样本及噪音实体标注样本;拓展噪音词袋生成单元,被配置为将全部所述真实实体标注样本汇总整理得到外部智库拓展词袋,将全部所述噪音实体标注样本汇总整理得到外部智库拓展噪音词袋。
66.所述泛化样本生成模块,包括:内插实体泛化样本生成单元,被配置为从所述外部智库拓展噪音词袋随机挑选噪音实体样本插入所述外部智库拓展词袋内所述真实实体标注样本中,得到内插实体泛化样本;外插语句泛化样本生成单元,被配置为选择包含有所述初始关键词词袋内词汇实体的噪音语句插入所述外部智库拓展词袋内所述真实实体标注样本中,得到外插语句泛化样本。
67.又一方面,本发明还涉及一种终端,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如前文所述行业专业文本自动标注方法中的步骤,例如图1所示的步骤。或者,处理器执行计算机程序时实现上述各装置实施例中各模块/单元的功能,例如图5所示的各模块/单元的功能。
68.再一方面,本发明还涉及一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行所述计算机程序时实现如前文所述行业专业文本自动标注方法中的步骤。
69.其中,可读存储介质可以是计算机存储介质,也可以是通信介质。通信介质包括便于从一个地方向另一个地方传送计算机程序的任何介质。计算机存储介质可以是通用或专用计算机能够存取的任何可用介质。例如,可读存储介质耦合至处理器,从而使处理器能够从该可读存储介质读取信息,且可向该可读存储介质写入信息。当然,可读存储介质也可以是处理器的组成部分。处理器和可读存储介质可以位于专用集成电路(application specific integrated circuits,asic)中。另外,该asic可以位于用户设备中。当然,处理器和可读存储介质也可以作为分立组件存在于通信设备中。可读存储介质可以是只读存储器(rom)、随机存取存储器(ram)、cd-rom、磁带、软盘和光数据存储设备等。
70.与前文中方法内容相对应的,本发明所提出的一种行业专业文本自动标注装置、终端及存储介质,能够以系统化、标准化的处理流程,高效、准确地完成对行业专业文本的标注,硬件的适配性和兼容性较高,能够切实地应用于文本标注领域内的技术实现中。
71.本发明还为其他与文本标注技术相关的方案提供了参考,可以以此为依据进行拓展延伸和深入研究,具有十分广阔的应用前景。
72.对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神和基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。
73.最后,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1