基于多流形相似度与强判别性的医学图像跨模态哈希检索方法
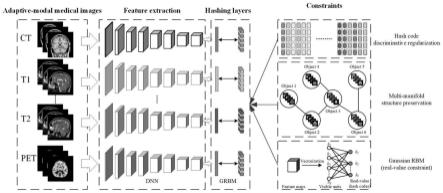
1.本发明属于信息检索领域,结合深度神经网络、高斯受限玻尔兹曼机、多流形相似度保持以及哈希码判别正则化损失函数实现医学图像跨模态哈希检索。
背景技术:
2.医院每天都会产生大量不同模态的医学影像,例如ct、mri(t1-w、t2-w)、pet等多种形式的影像。如何有效地减少存储消耗并实现快速、准确检索,一直是科研领域和临床上的研究热点。医学图像跨模态检索能够为医生提供以前相似的图像和相应的治疗记录,从而提高决策的效率和准确性。现阶段,已经提出了一系列基于深度学习的跨模态哈希检索方法,该方法通过使用深度神经网络同时学习特征表示和哈希码。
3.跨模态哈希检索的关键是减少异构数据的模态内和模态间的流形距离。基于此,有学者已经提出了许多优秀的基于深度学习和流形学习的跨模态哈希检索方法,并且可以应用于检索医学图像。尽管现有的跨模态哈希方法取得了较大的进展,但仍然存在三个挑战:1)对多个异构数据之间的潜在多模态流形结构考虑不足;2)哈希码的判别性较弱;3)三种模态以上的数据检索精度较低以及连续松弛造成的亚优化问题。
技术实现要素:
4.本发明旨在解决以上现有技术的问题,提出了一种能够实现医学图像跨模态哈希检索方法,建模异构数据之间的多模态流形结构,同时避免解决哈希码判别性较弱、三种模态以上的数据检索精度较低以及连续松弛造成的亚优化问题。具体地,本发明利用深度神经网络与高斯玻尔兹曼机,实现医学图像跨模态哈希检索。提出多流形相似度来减少相似图像之间的流形距离,同时增加不同图像之间的流形距离,在获得高精度检索结果基础上,进一步提高用户可接受度。哈希编码过程中,引入高斯受限玻尔兹曼机将连续特征直接输出为二进制哈希码,避免连续松弛造成的亚优化问题。同时,嵌入哈希码判别损失,确保任意两组哈希码不相同。训练过程中,首先采用交替训练方式,分别训练深度神经网络与高斯受限玻尔兹曼机模块,然后采用端到端方式微调整个模型。
5.鉴于此,本发明采用的技术方案是,基于多流形相似度与强判别性的医学图像跨模态哈希检索方法,首先,通过深度神经网络将原始图像编码为连续性特征,然后通过高斯受限玻尔兹曼机将连续性特征直接输出为二进制哈希码。在这过程中,通过多流形相似度保持损失与哈希码判别损失保持图像之间的流形和相似性关系。具体包括以下步骤:
6.1)构建深度神经网络与高斯受限玻尔兹曼机,深度神经网络将原始图像数据编码为连续性特征,然后通过高斯受限玻尔兹曼机将连续性特征直接输出为二进制哈希码,避免松弛操作造成的“亚优化”问题。哈希检索阶段,直接采用异或操作计算哈希码之间的距离,以此提高检索效率和存储开销。
7.2)构建多流形相似度,以减少相似样本之间流形距离的同时,增加非相似样本之
间的流形距离,并保持较好的用户可接受度。
8.3)添加哈希码判别项,以确保任意两组哈希码均不相同,进一步保证数据集中图像的唯一性,从而提高检索精度。
9.4)构造目标函数,在原始图像和哈希码之间构建多流形结构保持损失与哈希码判别损失,通过计算损失并反向传播梯度使得网络的输出与输入的流形空间保持相似;
10.5)训练过程中,首先采用交替训练方法(即,训练其中一个模块时,固定另一个模块的参数),利用医学图像数据集从头开始训练深度神经网络模块与高斯受限玻尔兹曼机模块;然后,将这两个模块构造为端到端网络进行微调。
11.上述技术方案具有如下优点或有益效果:
12.1)提出了一种基于多流形相似度与强判别性的医学图像跨模态哈希检索方法。本发明具有多路径结构和较强的扩展性,支持自适应模态数据检索。本发明包含深度神经网络模块与高斯受限玻尔兹曼机模块,前者用于提取图像信息,后者用于直接输出哈希码,不使用任何连续松弛或平滑拟合。
13.2)提出多流形相似性,用于建模跨模态异构数据之间的流形关系,进一步提高提高检索精度和用户可接受度。
14.3)提出哈希码判别正则化项,用以确保任意两组哈希码不同,进一步增强了哈希码的判别性,提高了检索的准确性。
15.4)本发明利用流形三步连接,构建多流形相似度矩阵,并利用严谨的推导,证明其能够准确建模异构数据之间的多流形结构。
16.5)本发明首先采用交替训练方法(即,训练其中一个模块时,固定另一个模块的参数),利用医学图像数据集从头开始训练深度神经网络模块与高斯受限玻尔兹曼机模块。然后,将这两个模块构造为端到端网络进行微调,进一步提升整体网络的检索精度。
附图说明
17.图1是本发明提供实施算法框架图;
18.图2为本发明的用户可接受度实验结果图;
19.图3-4为本发明的检索精度的对比图。
具体实施方式
20.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、详细地描述。所描述的实施例仅仅是本发明的一部分实施例。
21.本发明为了保持数据集中图像之间的流形结构,进一步获得较高检索精度和较好的用户可接受度,通过深度神经网络与高斯受限玻尔兹曼机直接输出哈希码,从而实现高效的哈希检索。将原始图像数据输入到深度神经网络中,得到对应的连续性特征。然后,将连续性特征输入到高斯受限玻尔兹曼机中,不采用任何的松弛策略,输出二进制哈希码。哈希编码过程中,通过多流形相似度保持多模态异构数据之间的流形结构,进一步保证图像之间的相似性和非相似性,提高用户的可接受度。利用哈希码判别损失确保任意两组哈希码不同,提高哈希码的判别性,进一步提高检索精度。通过定义矩阵非负性,图对称与非对称性,相似度的对称与非对称性,证明多流形相似度的对称性,进一步证明其对图像相似度
的保持和检索性能的保持。训练过程中,首先采用交替训练方法(即,训练其中一个模块时,固定另一个模块的参数),利用医学图像数据集从头开始训练深度神经网络模块与高斯受限玻尔兹曼机模块。然后,将这两个模块构造为端到端网络进行微调,进一步提升整体网络的检索精度。
22.为了实现医学图像跨模态哈希检索,通过深度神经网络提取图像特征,然后利用高斯受限玻尔兹曼机对高维连续特征进行哈希编码,不需要任何松弛操作,直接输出二进制哈希码。
23.在特征提取与哈希编码的过程中,通过多流形相似度矩阵,保持跨模态异构数据的流形结构,进一步保持图像之间的相似性和非相似性。
24.在哈希编码过程中,通过哈希码判别正则化损失,确保任意两组哈希码不同,提高哈希码的判别性,进一步提高检索精度。
25.在原始图像和哈希码之间构建多流形结构保持损失与哈希码判别损失,通过计算损失并反向传播梯度使得网络的输出与输入的流形空间保持相似。
26.构建哈希码判别损失,确保任意两组哈希码不同,保持数据集中图像的唯一性。
27.利用多流形相似度矩阵保持异构数据之间的流形关系,在减少相似图像之间流形距离的同时,增加非相似样本之间的流形距离,进一步提高检索精度与用户可接受度。
28.通过定义矩阵非负性,图对称与非对称性,相似度的对称与非对称性,证明多流形相似度的对称性,进一步证明其对图像相似度的保持和检索性能的保持。
29.多流形相似度的非负性。由于高斯热核函数与示性函数均输出非负矩阵,因此,多流形相似度是非负的。
30.图对称与非对称性。在子图中,如果两个顶点之间的最短路径是唯一的,则由子图组成的超图是对称的,超图推导的矩阵是对称的,否则,无论是超图还是矩阵都是不对称的。
31.相似度的对称与非对称性。单模态流形相似矩阵是对称的,而跨模态和多模态流形相似矩阵是非对称的。
32.多流形相似度的对称性。多流形相似矩阵满足关系s=s
t
,相似性矩阵满足s
uv
=(s
vu
)
t
。通过使用三步连接,可以得到第u个模态和第v个模态之间的多流形相似矩阵为然后,根据单模流形相似度矩阵的对称性和元素乘法的可交换性,s
uv
的转置可以计算为:
[0033][0034]
由此,可以证明得到:多流形相似度矩阵为对称矩阵。
[0035]
具体步骤表示为:
[0036]
步骤一:构建深度神经网络与高斯受限玻尔兹曼机
[0037]
在特征提取过程中,利用由深度神经网络组成的哈希网络对原始图像进行特征提取,输出连续特征。在哈希编码过程中,利用高斯玻尔兹曼机对连续特征进行编码,直接输出二进制哈希码。表示为:
[0038][0039]
q表示高斯玻尔兹曼机中隐含层的层数,k表示哈希码的长度,σ
im
表示高斯分布的标准差。m表示模态数量,f
im
表示第m个模态中高斯受限玻尔兹曼机隐层中的第i个结点的输入值,表示第m个模态中高斯受限玻尔兹曼机隐层中的第j个结点的输入值,和分别表示f
im
和的偏移量,表示f
im
和之间的连接权重。隐层和显层的条件概率分表表示为:
[0040][0041][0042]
其中,sigmoid()表示sigmoid激活函数,n(
·
|μ,σ2)表示在“均值为μ,方差为σ”的条件下的高斯概率密度函数,其中,q表示高斯玻尔兹曼机中隐含层的层数,fm表示第m模态隐层结点的输出。
[0043]
步骤二:构建多流形相似度
[0044]
本发明提出多流形相似度,在减少相似样本之间流形距离的同时,增加非相似样本之间的流形距离,进一步提高检索精度和提高用户可接受度。多流形相似度表示为:
[0045]
多流形相似度表示为:
[0046][0047]
并有,其中,表示u模态中第i个样本点与v模态中第j个样本点之间的相似度。s
uv
(
·
)表示图像之间的多流形相似度矩阵,表示矩阵元素乘法,和分别表示v模态和u模态的单模态流形相似度,表示跨模态流形相似度,分别表示为:
[0048]
[0049][0050]
其中,n为图像数据的大小。
[0051]
步骤三:添加哈希码判别项
[0052]
引入哈希码判别项,提高哈希码的判别性能。最大化任意两组哈希码之间的距离,确保任意两组哈希码不相同,构造哈希码判别损失为:
[0053][0054]dh
(
·
)表示哈希码之间的海明距离,与分别表示u模态中第i个样本点和v模态中第j个样本点的哈希码,m表示模态数。
[0055]
步骤四:构造目标函数
[0056]
引入超参数α和β,结合多流形相似度保持损失和哈希码判别损失,构建整体目标函数,表示为:
[0057][0058]
其中,s
uv
(
·
)表示图像之间的多流形相似度矩阵,dh(
·
)表示哈希码之间的海明距离,α与β表示超参数,用于平衡不同损失之间的权重。
[0059]
综上所述,本发明的创新和优势:
[0060]
本发明提出的医学图像跨模态哈希检索方法,利用深度神经网络与高斯受限玻尔兹曼机实现特征提取与哈希编码,在实现快速、准确检索的同时,提高用户的可接受度。
[0061]
针对现阶段无法较好地对异构数据进行建模的问题,本发明提出多流形相似度与强判别性跨模态哈希检索算法,采用多路径结构,具有较强的扩展性,支持自适应模态数据检索。
[0062]
本发明包含深度神经网络与高斯受限玻尔兹曼机模块,前者用于提取图像信息,后者用于直接输出哈希码,不使用任何连续松弛或平滑拟合;
[0063]
提出多流形相似性,用于建模跨模态异构数据之间的流形关系,进一步提高提高检索精度和用户可接受度;
[0064]
提出哈希码判别正则化项,用以确保任意一组哈希码不同,进一步增强了哈希码的判别性,提高了检索的准确性;
[0065]
本发明利用流形三步连接,构建多流形相似度矩阵,并利用严谨的推导,证明其能够准确建模异构数据之间的多流形相似度;
[0066]
以上这些实施例应理解为仅用于说明本发明而不用于限制本发明的保护范围。在阅读了本发明的记载的内容之后,技术人员可以对本发明作各种改动或修改,这些等效变化和修饰同样落入本发明权利要求所限定的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1