一种基于视觉语言双向编码变换器和排序损失函数的异常检测方法
1.本发明属于视频异常检测技术领域,具体涉及一种基于视觉语言双向编码变换器和排序损失函数的异常检测方法
背景技术:
2.异常检测不仅是计算机视觉领域一个重要且活跃的研究课题,也是一项具有非常具有挑战性的任务,因为在一个开放且复杂的环境中可能会出现各种各样的现实情况,因此几乎不可能收集到各种异常事件的数据。除此之外,由于异常事件种类繁多,而且发生频率较低,如果在海量视频数据集中对异常事件进行采集和标记,不仅需要耗费大量的人力而且十分耗时。近些年一些聚类方法被用于解决异常检测问题,例如高斯混合模型和k均值聚类算法。但是这些方法都属于无监督异常检测方法,由于异常事件种类繁多,难以通过一个简单的分类器进行区分,因此在实际应用过程中通常会遇到性能不佳的问题。
3.近些年来,为了进一步提高模型性能,采用弱监督思想的异常检测方法越来越受到研究者的广泛关注。在弱监督方法中,异常检测通常被表述为一个多实例学习mil任务,在实际应用中取得了一定效果,但其对异常事件的识别在很大程度上会受到占主要部分的正常事件的影响,从而导致准确度不高。为了解决这个问题,tian等人在mil方法中的利用鲁棒时间特征幅度进行学习,提出了一种弱监督异常检测方法(y.tian,g.pang,y.chen,r.singh,j.w.verjans,g.carneiro,weaklysupervised video anomaly detection with robust temporal feature magnitude learning.in iccv,2021)。degardin等人提出了一种迭代弱/自监督学习方法用于异常检测(b.degardin,h.proena,iterative weak/self-supervised classifification framework for abnormal events detection.in prl,2021)。zhong等人通过设计一个图卷积网络去除噪声标签,从而将有监督的动作分类器应用于弱监督异常检测(j.zhong,n.li,w.kong,s.liu,t.h.li,g.li,graph convolutional label noise cleaner:train a plug-and-play action classififier for anomaly detection.in cvpr,2019)。但是现有的方法都没有明确地使用注意力机制对异常事件进行检测。
技术实现要素:
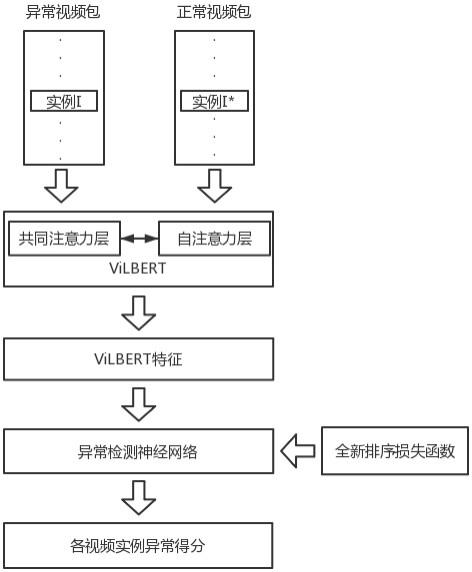
4.为解决上述问题,本发明提供了一种基于视觉语言双向编码变换器和排序损失函数的异常检测方法。该方法将含有异常实例的正类包和只含正常实例的负类包输入基于共同注意力和自注意力机制的vilbert模块,提取得到视频实例的vilbert特征,再将此特征输入到一个基于全新排序损失函数调整的神经网络中进行训练,最终构建一个完整的异常检测模型,每一个视频实例能获得各自的异常得分。
5.一种基于视觉语言双向编码变换器和排序损失函数的异常检测方法,具体包括以下步骤:
6.s1,根据视频数据设定训练集和待测集,将每个视频看作一个视频包,在训练集中,将包含至少一个异常实例的视频包定义为正包b
p
,将不包含任何异常实例的视频包定义为负包bn;
7.s2,将s1中得到的正包和负包分成相同数量l的时间段,每个时间段表示视频包中的一个实例;
8.s3,将s2中得到的正包和负包都输入到基于注意力机制的vilbert模块,从而提取到所有视频实例的vilbert特征;
9.s4,将s3中得到的实例vilbert特征输入到一个三层的全连接神经网络中,并基于排序损失函数进行迭代训练,训练后得到一个区分异常事件和正常事件的异常检测模型,输入待测集,其中的每个视频实例获得各自的异常得分,得到异常的检测结果。
10.进一步地,所述s1中的视频包b
p
和bn中所含的实例数量相等。
11.进一步地,所述s2中的正包视频实例依次用p1,p2,...,p
l
,...p
l
表示,负包视频实例依次用n1,n2,...,n
l
,...n
l
表示。
12.进一步地,所述s3中,vilbert模块的注意力机制结构主要由共同注意力层和自注意力层构建。将正包和负包中的图片实例经过转化后得到视觉向量,将该视觉向量分别与wq,wk,wv三个矩阵相乘,得到每个正包实例对应的三个向量q,k,v,每个正包实例对应的三个向量q*,k*,v*。然后将得到的三个向量输入到vilbert模块中,其中正包中的k,v与负包中的k*,v*交换输入从而构建共同注意力,接着将q,k*,v*依次通过vilbert模块的自注意力层、归一化层、前向传播层、归一化层,最终得到一个输出结果;对q*,k,v同样以上所述进行相同的操作并同样得到一个输出结果。最后对两个输出结果进行拼接整合得到vilbert特征。
13.进一步地,所述s4中,排序损失函数基于means方法对视频包中的实例异常得分取平均值而得到,进行松弛操作和铰链损失定义,同时考虑时间的平滑性和异常事件的稀疏性。
14.进一步地,所述s4中,排序损失函数定义如下:
15.l(w)=l(b
p
,bn)+β3||w||f16.其中,w是权重,β3是平衡参数,||w||f是w的frobenius范数;
[0017][0018]
其中,和表示通过mean方法遍历每个视频包中所有视频实例计算出的预测异常得分平均值,表示时间平滑性约束,表示稀疏性约束,λ为松弛参数,β1,β2都是平衡参数。
[0019]
本发明的有益效果是:
[0020]
(1)本发明采用视频级标签代替帧级标签。有效解决了异常检测中缺乏大量帧级标签的问题,这样的做法在给海量视频加上标签方面有很大优势。
[0021]
(2)本发明引入了基于共同注意力和自注意力机制的vilbert模块,通过该模块提取到的vilbert特征能有效代表视频实例的特征。
[0022]
(3)本发明构造了一个全新的排序损失函数,该损失函数基于对视频包中的实例异常得分取平均值而得到,同时考虑到了时间的平滑性和异常事件的稀疏性,通过这样的方式构造的损失函数能使得模型获得的信息更加完整,有效提高了模型区分异常事件与正常事件的准确性。
附图说明
[0023]
图1为本发明实施例中的异常检测方法的流程图。
[0024]
图2为本发明实施例中的vilbert模块的结构图。
[0025]
图3为本发明实施例中的异常检测方法的网络模型结构图。
[0026]
图4为本发明实施例中的本方法与其他异常检测方法在ucf crime数据集上的roc曲线图对比图。
具体实施方式
[0027]
下面结合说明书附图对本发明的技术方案做进一步的详细说明。
[0028]
本发明是一种基于视觉语言双向编码变换器与全新排序损失函数结合的异常检测方法,该异常检测方法具体包括如下步骤:
[0029]
s1,将每个视频看作一个视频包,将包含至少一个异常实例的视频包视为正包b
p
,将不包含任何异常实例的视频包视为负包bn,视频包b
p
和bn中所含的视频实例数量相等。
[0030]
s2,将s1中得到的两类视频包分割成一个个固定数量的时间段,时间段的数量均为l,每个时间段代表视频包中的一个视频实例。正包视频实例依次用p1,p2,...,p
l
,...p
l
表示,负包视频实例依次用n1,n2,...,n
l
,...n
l
表示。
[0031]
s3,将s2中得到的两类包输入基于共同注意力和自注意力机制的vilbert模块,从该模块中提取得到视频包中所有实例的vilbert特征。将正包和负包中的图片实例经过转化后得到视觉向量,将该视觉向量分别与wq,wk,wv三个矩阵相乘,得到每个正包实例对应的三个向量q,k,v,每个正包实例对应的三个向量q*,k*,v*。然后将得到的三个向量输入到vilbert模块中,其中正包中的k,v与负包中的k*,v*交换输入从而构建共同注意力,接着将q,k*,v*依次通过vilbert模块的自注意力层、归一化层、前向传播层、归一化层,最终得到一个输出结果;对q*,k,v同样以上所述进行相同的操作并同样得到一个输出结果。最后对两个输出结果进行拼接整合得到vilbert特征。
[0032]
s4,将s3中得到的实例vilbert特征输入到一个三层的全连接神经网络中,该网络基于所提出的全新排序损失函数进行迭代训练,最终构建一个能有效区分异常事件和正常事件的异常检测模型,每个视频实例能够获得各自的异常得分。
[0033]
该步骤中全新排序损失函数的具体构造过程如下:
[0034]
s4-1,对于给定的异常视频实例xa和正常视频实例xr。最简单的损失函数如下:
[0035]
s(xa)>s(xr)
[0036]
其中,s(xa)和s(xr)分别表示视频实例xa和xr预测的异常分数。但是由于视频实例级别的标签未知,因此无法通过上式训练神经网络。
[0037]
s4-2,为解决s4-1中存在的问题,同时更完整地保存视频实例信息,本方法提出的针对多实例排序的目标函数如下:
[0038][0039]
其中,mean方法遍历每个视频包中所有的视频实例,通过计算每个视频包中所有视频实例预测异常得分的平均值来执行排序损失函数。从而使得异常实例和正常实例异常得分相差更大,进一步有利于二者的区分。
[0040]
s4-3,为了使得正常实例异常得分之间的差距比异常实例和正常实例异常得分之间的差距更小,进一步调整目标函数如下:
[0041][0042]
其中,的值大于零,从而确保s4-2中的式子仍然成立。
[0043]
s4-4,为了防止过拟合的出现,对s4-3中的式子进行松弛操作,调整后的目标函数如下:
[0044][0045]
其中,λ为松弛参数。
[0046]
s4-5,排序损失函数由铰链损失公式定义如下:
[0047][0048]
s4-6,考虑到时间平滑性和异常实例的稀疏性,损失函数进一步调整如下:
[0049][0050]
其中,表示时间平滑性约束,表示稀疏性约束,β1,β2都是平衡参数。
[0051]
s4-7,最终构造的完整全新排序损失函数定义如下:
[0052]
l(w)=l(b
p
,bn)+β3||w||f[0053]
其中,w是模型的权重,β3是平衡参数,||w||f是w的frobenius范数。
[0054]
本发明属于一种弱监督学习方法,提出了将视觉语言双向编码变换器与全新排序损失函数结合的异常检测方法。首次明确将注意力机制引入视频异常检测中,从而有效提取出视频实例的vilbert特征。同时,本发明提出了一种全新的排序损失函数对神经网络进行训练,该函数既考虑到了视频实例信息的完整性,又兼顾到了时间的平滑性和异常事件的稀疏性。本发明提出的基于视觉语言双向编码变换器与全新排序损失函数结合的异常检测方法保证了异常事件和正常事件的有效区分。
[0055]
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。
[0056]
a、实验条件
[0057]
1.实验数据库
[0058]
在ucf crime和自行设计的一个数据集(nut)上进行训练和测试。异常检测过程中将数据集分成训练类(有需要再细分成训练类和验证类)和测试集,在不同数据集上有不同的划分,训练类加验证类即为已知类别,测试类为未知类别,二者之间没有交集。详细介绍见如下表1。
[0059]
表1数据集的详细介绍
[0060][0061]
2.实验参数设置
[0062]
模型固定参数设置如下表2所示:
[0063]
表2模型固定参数
[0064]
lλβ1β2β3328
×
1058
×
1058
×
10
51×
102[0065]
b、实验结果评价标准
[0066]
此模型针对于异常检测设置,异常检测中测试类的类别有未知类别,也有已知类别,这里用auc来衡量检测效果。auc值越高,说明模型效果越好。auc的计算公式如下:
[0067][0068]
其中,m为正包样本数,n为负包样本数,分子为预测结果为正包的概率大于预测结果为负包的概率的组合总数。
[0069]
c、对比试验方案
[0070]
本实施例在两个数据集上与其他目前前沿的异常检测方法进行对比。
[0071]
表3异常检测方法性能比较:
[0072]
methodsucf crimenutbinary classififier50.0-conv-ae50.6-sparse65.5-mil75.482.1milr76.7-amil78.586.0
[0073]
amil是本文提出的方法,通过表3与目前前沿的异常检测方法对比结果表明本方法的异常检测效果超过了其它比较的方法。mil是本文所提出方法的基础模型,在加入注意力机制之后,我们的模型效果提升超过3%,客观说明了本文所提出的方法的有效性。
[0074]
图3为本文的方法与其他异常检测方法在ucf crime数据集上的roc曲线图对比,该曲线图很好地展现了本文的方法比目前存在的方法更加有效,特别是在,假正类率为0.3左右时,本文的方法获得了比其他方法更高的真正类率,从而说明了模型的有效性。
[0075]
以上所述仅为本发明的较佳实施方式,本发明的保护范围并不以上述实施方式为限,但凡本领域普通技术人员根据本发明所揭示内容所作的等效修饰或变化,皆应纳入权利要求书中记载的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1