一种风电场样板机选择方法
1.本发明属于风电场理论发电量计算领域,具体涉及一种风电场样板机选择方法。
背景技术:
2.针对弃风限电问题,需要科学、高效地评估其整场理论发电量和弃风电量水平,从而 准确掌握风电场的运行状况,并在此基础上采取相应的技术手段减少弃风现象,从而减少 风能资源的浪费。
3.2012年底,国家电力监管委员会发布了风电场弃风电量计算办法,在国内推广样板机 法来计算弃风电量。样板机法能准确统计弃风电量,但样板机能否合理选择是影响其计算 准确度的关键因素,研究场内样板机选择方法,提高样板机选择的合理性和代表性,对于 风电场理论发电量评估及电力系统运行调度具有重要意义。
4.常用的传统样板机选择方法规定样板机数量原则上不超过风电场机组总数的10%,并 且传统的样板机法没有固定的样板机选取方法,常常依据工作人员的经验和风电机组相关 数据来选取。而在计算风电场的理论发电量进而得到弃风电量时,分配系数也倾向于平均 分配。传统样板机法的理论发电量计算的相对误差较大,且存在较强的不确定性,在计算 风电场的理论发电量时,计算精度亦显著降低。
5.近年来,一种新的样板机选择方法通过应用双步k-means聚类算法可辨识不良数据和 剔除离群点,为后续划分机群、选择样板机来估算整场理论发电量提供依据。该方法既能 体现单机代表性,又避免了逐个计算的复杂性,但该方法无法使分类后的机群内部之间差 异性最小、不同类的机群之间差异性最大,因而无法更有效地选择出更具代表性的样板机 来计算风电场理论发电量及弃风电量。
技术实现要素:
6.本发明的目的是为克服现有技术的不足之处,提出一种风电场样板机选择方法。本发 明基聚类算法选取风电场样板机,可提高选取样板机的合理性和代表性,在保证计算效率 的同时又能提高发电量计算的精度。
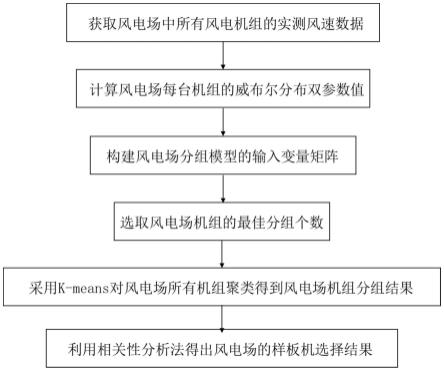
7.本发明实施例提出一种风电场样板机选择方法,包括:
8.获取风电场中每台风电机组的风速数据;
9.根据所述风速数据,计算所述每台风电机组的风速威布尔分布曲线参数;
10.对所述每台风电机组的风速数据降维后进行归一化,对所述每台风电机组的风速威布 尔分布曲线参数进行归一化,利用归一化后的结果构建风电场分组模型的输入变量矩阵;
11.确定所述风电场机组最佳分组个数,根据所述最佳分组个数对所述风电场分组模型的 输入变量矩阵进行聚类,得到所述风电场中各风电机组的分组结果;
12.根据所述分组结果,利用相关性分析法选取每个分组的样板机,以得到所述风电场的 样板机选择结果。
13.在本发明的一个具体实施例中,所述风速威布尔分布曲线参数包括形状参数和尺度参 数。
14.在本发明的一个具体实施例中,所述根据所述分组结果,利用相关性分析法选取每个 分组的样板机,以得到所述风电场的样板机选择结果,具体方法如下:
15.1)对于任一分组中第i台机组,计算该机组与该分组中其他机组相关系数的均值:
[0016][0017]
式中,rm(i)为任一分组中第i台机组与该分组中其他机组风速相关系数的均值, i=1,2,...,q;q为该分组的机组数量;r(ij)为该分组中第i台机组和第j台机组的风速相关系 数;
[0018]
2)将每个分组中rm(i)最高的机组作为该分组的样板机,所有分组的样板机构成该风 电场的样板机选择结果。
[0019]
在本发明的一个具体实施例中,所述形状参数和尺度参数计算方法如下:
[0020]
1)将第i台机组的风速数据均匀划分为n个区间,其中每个区间的风速上限值记为 j=1,2,...,n,;
[0021]
2)统计第i台机组每个风速区间对应风速数据出现的频率记为j=1,2,...,n;
[0022]
3)利用第i台机组每个区间的风速上限值和该区间的频率进行曲线拟合,得到第 i台机组对应的风速威布尔分布曲线,表达式如下:
[0023]
f(x)=a(i)b(i)x
(b(i)-1)
exp(-a(i)x
b(i)
)
[0024]
分别计算该曲线对应的威布尔分布的形状参数k和尺度参数c:
[0025]
k(i)=b(i))
[0026][0027]
其中,a(i)是将第i台机组的双参数威布尔分布函数的数学形式对数变换成线性形式后 的常数项,b(i)是将第i台机组的双参数威布尔分布函数的数学形式对数变换成线性形式 后的斜率;
[0028]
k(i)为第i台机组风速威布尔分布曲线的形状参数,c(i)为第i台机组风速威布尔分布 曲线的尺度参数。
[0029]
在本发明的一个具体实施例中,所述对所述每台风电机组的风速数据降维后进行归一 化,对所述每台风电机组的风速威布尔分布曲线参数进行归一化,利用归一化后的结果构 建风电场分组模型的输入变量矩阵,包括:
[0030]
1)对每台风电机组的的风速数据进行降维;
[0031]
对于第i台机组,计算表达式如下:
[0032]
[0033][0034]
式中,vm(i)为第i台机组的风速平均值;v
sd
(i)为第i台机组风速均方差值;p(i)代表为 第i台机组的风速数据总数;
[0035]
2)对每台风电机组降维后的风速数据以及该机组风速威布尔分布曲线的形状参数和 尺度参数分别归一化;
[0036]
对于第i台机组,计算表达式如下:
[0037][0038][0039][0040][0041]
式中,v
m1
(i)为归一化后第i台机组的风速平均值,v
sd2
(i)为归一化后第i台机组的风 速均方差值;
[0042]
k3(i)为归一化后第i台机组风速威布尔分布曲线的形状参数,c4(i)为归一化后第i台 机组风速威布尔分布曲线的尺度参数;
[0043]
vm(max)和vm(min)分别为风电场所有机组风速平均值的最大值和最小值,v
sd
(max)和 v
sd
(min)分别为分别为风电场所有机组风速均方差值的最大值和最小值,k(max)和k(min)分 别为风电场所有机组风速威布尔分布曲线形状参数的最大值和最小值,c(max)和c(min)分 别为风电场所有机组风速威布尔分布曲线尺度参数的最大值和最小值;
[0044]
3)建立风电场分组模型的输入变量矩阵为:
[0045][0046]
其中,a为风电场中风电机组总数。
[0047]
在本发明的一个具体实施例中,所述频率的计算方法为:
[0048]
频率=可用频数/(组距*总数)
[0049]
其中,可用频数为任一区间内的风速数据数目,组距为相邻两个区间的风速的上限差 值。
[0050]
在本发明的一个具体实施例中,所述确定所述风电场机组最佳分组个数,根据所述最 佳分组个数对所述风电场分组模型的输入变量矩阵进行聚类,得到所述风电场中各风电机 组的分组结果,包括:
[0051]
1)设定若干初始分组个数;
[0052]
2)在每个初始分组个数下,对所述风电场分组模型的输入变量矩阵进行聚类,根据聚 类结果计算该初始分组个数下风电场中各风电机组分组结果对应的ch指标值;
[0053]
3)将ch指标值的最大值对应的初始分组个数作为风电场机组最佳分组个数;该最佳 分组个数下的聚类结果即为所述风电场中各风电机组的组中分组结果。
[0054]
在本发明的一个具体实施例中,所述聚类方法为k-means聚类。
[0055]
本发明的特点及有益效果:
[0056]
本发明利用ch指标确定的最佳聚类数,然后基于聚类算法进行风电场分组,为样板 机的选取提供了较为可靠的依据;
[0057]
根据本发明得到的样板机选择结果可获得更为精确的风电场理论发电量计算结果,同 时保证了计算效率,为风电场运行状况评估提供了重要信息。
附图说明
[0058]
图1为本发明实施例的一种风电场样板机选择方法的整体流程图。
[0059]
图2为本发明实施例中拟合后的风速威布尔分布曲线图。
[0060]
图3为本发明实施例中不同分组个数下的ch指数示意图。
具体实施方式
[0061]
本发明提出一种风电场样板机选择方法,下面结合附图和具体实施例进一步详细说明 如下
[0062]
本发明实施例提出一种风电场样板机选择方法,整体流程如图1所示,包括以下步骤:
[0063]
1)获取风电场中所有风电机组的实测风速数据;本实施例中,在条件允许的情况下时 间越长,数据越多,计算效果越好;本发明一个具体实施例中数据的时间分辨率为2h,数 据的时间长度不少于半年。
[0064]
2)根据步骤1)的风速数据,计算风电场每台机组的威布尔分布双参数值。
[0065]
其中,第i台机组的威布尔分布双参数值获取方法如下:2-1)对步骤1)获取的第i台 机组的实测风速数据进行分组,本实施例中,从风速为0开始将该机组风速区间均匀划分 为n个,其中每个区间的风速上限值记为表示第i台机组的第j个区间的风速上限 值,j=1,2,
…
,n,;
[0066]
需要说明的是,区间个数n的取值无特殊要求,区间划分的越多就越精细,可根据风 速数据集的大小划分为50、100等等均可,每台机组的风速区间个数n相同;
[0067]
2-2)根据步骤2-1)的结果,统计第i台机组每个风速区间对应风速数据出现的频率 记为表示第i台机组的风速数据出现在第j个风速区间的频率;
[0068]
本实施例中,所述频率可用频数/(组距*总数)来计算,在本发明的一个具体实施例 中,统计了一年8760个小时的每小时风速,总的风速范围为0m/s-20m/s,按照0.5m/s为 组距将上述风速范围均匀划分为40个区间,其中出现在0-0.5m/s的风速区间有3个风速 值,那么该风速区间对应的频率就是3/(0.5*40);
[0069]
2-3)利用第i台机组每个区间的风速上限值速度和该区间的频率使用
matlab 的内置函数库进行曲线拟合,令误差平方和的值最小,得到第i台机组对应的风速威布尔 分布曲线;
[0070]
本发明一个具体实施例拟合后的风速威布尔分布曲线如图2所示,,其中该实施例将 实测风速范围0-20m/s按照0.5m/s为组距将上述风速范围均匀划分为40个区间,图2中 每个点的横坐标代表该点对应风速区间的风速上限值,每个点的纵坐标代表该点对应风速 区间风速的频率值,通过拟合,得到如图2中所示的曲线,该曲线是即为根据散点区间风速的频率值,通过拟合,得到如图2中所示的曲线,该曲线是即为根据散点拟合出来的威布尔分布曲线。
[0071]
其中,该曲线拟合模型的表达式为:
[0072]
f(x)=a(i)b(i)x
(b(i)-1)
exp(-a(i)x
b(i)
)
ꢀꢀꢀ
(1)
[0073]
计算该曲线对应的威布尔分布的形状参数k和尺度参数c:
[0074]
k(i)=b(i)
ꢀꢀꢀ
(2)
[0075][0076]
其中,a(i)是将第i台机组的双参数威布尔分布函数的数学形式对数变换成线性形式后 的常数项,b(i)是将第i台机组的双参数威布尔分布函数的数学形式对数变换成线性形式 后的斜率。
[0077]
其中,k(i)为第i台机组风速威布尔分布曲线的形状参数,c(i)为第i台机组风速威布 尔分布曲线的尺度参数。
[0078]
3)对每台风电机组的风速数据降维后进行归一化,对每台机组的风速威布尔分布曲线 参数进行归一化,利用归一化后的结果构建风电场分组模型的输入变量矩阵;
[0079]
本发明实施例中,具体步骤如下:
[0080]
3-1)对按步骤1)获取的风电场每台机组的风速数据进行降维处理,从而较快把握利 于聚类目标函数收敛的主要属性以提高计算效率。
[0081]
对于第i台机组,计算表达式如下:
[0082][0083][0084]
式中,vm(i)为第i台机组的风速平均值;v
sd
(i)为第i台机组风速均方差值。p(i)代表为 第i台机组的风速数据总数。
[0085]
3-2)对经过步骤3-1)降维处理每台机组的风速数据(风速平均值和风速均方差值) 以及步骤2)得到的每台机组的风速威布尔分布曲线的形状参数和尺度参数(即每台风电 机组有4个数据特征值)分别归一化处理,使其分别变换为[0,1]区间的数据,降低聚类难 度。
[0086]
对于第i台机组,计算表达式如下:
[0087]
来评估该初始分组个数下对应的聚类效果,通过计算每个初始分组个数下聚类结果对应的 ch指标中ck函数值来确定最佳分组个数。
[0103]
其中,在本发明一个具体实施例中,在每个初始分组个数下,使用python软件对步骤 3)得到的风电场分组模型的输入变量矩阵进行k-means聚类的计算,具体过程为:
[0104]
①
使用pandas库中的read语句读取输入变量矩阵;
[0105]
②
使用sklearn库中的minmaxscaler函数对其进行归一化处理;
[0106]
③
使用sklearn库中的fit方法进行k-means聚类计算;
[0107]
得出风电场分组结果。4-3)将ch指标值的最大值对应的初始分组个数作为风电场机 组最佳分组个数;该最佳分组个数下的聚类结果即为所述风电场中各风电机组的组中分组 结果。
[0108]
本实施例中,通过ch指标值的最大值确定最佳分组个数为m,通过将风电机组分成 m个机群,基本上实现有效聚类,每个机群的机组数目较为均匀,基本实现了类内相似性 与类间排他性的目标,即使每个机群内风电机组的运行特性差异性最小,不同机群间风电 机组的运行特性差异性最大。
[0109]
在本发明一个具体实施例中,不同分组个数下聚类结果对应的ch指数结果如图3所 示,其中每个点的横坐标代表不同的初始分组个数,纵坐标代表该分组个数下聚类结果对 应的ch指数(即ck函数值),图3中ch指数在分组数为5时达到最大,故可以确定风 电场分组个数为5时聚类效果最好,即本实施例中最佳分组个数m为5。
[0110]
5)根据步骤4)的分组结果,利用相关性分析法选出每个分组中最能代表该分组出力 特性的样板机,得到风电场的样板机选择结果。
[0111]
本实施例中,利用相关性分析法(correlation analysis)中的典型相关系数r来研究两 个或多个随机变量之间的相关程度,从而得到m个分组中每台机组与同组中其他机组的风 速相关系数的平均值。
[0112]
对于任一机分组中第i台机组,计算表达式如下:
[0113][0114]
式中,rm(i)为任一分组中第i台机组与该分组中其他机组风速相关系数的均值, i=1,2,...,q;q为该分组的机组数量。r(ij)为该分组中第i台机组和第j台机组的风速相关系 数,由相关性分析法(correlation analysis)获得。
[0115]
对于按最佳分组个数分组后的每个风电机组分组,该分组中风速相关系数均值rm(i)最 高的机组为最能代表该分组出力特性的机组,即风电场的样板机之一,由此选出m个分组 内的m个样板机(每个分组内选择一个样板机)。
[0116]
在本发明一个具体实施例中,对33台风电机组分组后,某一分组内机组间的相关性系 数如表1所示:
[0117]
表1组内机组间的相关性系数
[0118][0119]
表1中为处于同一分组内的六台风电机组(3#,15#,16#,17#,19#,20#)间的风速 相关性系数,可见,16#机组与其他几台机组相比,风速相关性系数的平均值最髙(0.967), 因此选取该机组为风电场的样板机之一。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1