数据处理方法、装置、设备及存储介质与流程
1.本技术实施例涉及计算机和车联网技术领域,特别涉及一种数据处理方法、装置、设备及存储介质。
背景技术:
2.目前,在一些车联网产品中,通常会对新增的对象进行统计,使得开发者能够更加清晰地掌握使用者的情况,以作出相应的改变。
3.在相关技术中,如果想要计算新增对象,会将当前周期的对象集合进行排序,并将当前周期的对象集合中的对象逐个与历史时段内的全量对象集合进行比对,以筛选出当前周期的新增对象集合。这样,会尽可能地保证所有新增对象都能被筛选出来。
4.然而,在当前周期的对象较多时,这种逐个比对的数据处理方式存在耗时长、效率低的问题。
技术实现要素:
5.本技术实施例提供了一种数据处理方法、装置、设备及存储介质。所述技术方案如下:根据本技术实施例的一个方面,提供了一种数据处理方法,所述方法包括:获取历史时段内的全量对象集合以及当前周期的对象集合,所述全量对象集合包括所述历史时段内的全量对象的标识,所述当前周期的对象集合包括所述当前周期内的多个对象的标识;将所述当前周期的对象集合划分为k个子集,所述子集中包括所述当前周期内的部分对象的标识,k为大于1的整数;将所述k个子集分别与所述全量对象集合进行比对,得到所述当前周期的新增对象集合,所述当前周期的新增对象集合包括所述当前周期内出现且所述历史时段内未出现的对象的标识。
6.根据本技术实施例的一个方面,提供了一种数据处理装置,所述装置包括:获取模块,用于获取历史时段内的全量对象集合以及当前周期的对象集合,所述全量对象集合包括所述历史时段内的全量对象的标识,所述当前周期的对象集合包括所述当前周期内的多个对象的标识;划分模块,用于将所述当前周期的对象集合划分为k个子集,所述子集中包括所述当前周期内的部分对象的标识,k为大于1的整数;比对模块,用于将所述k个子集分别与所述全量对象集合进行比对,得到所述当前周期的新增对象集合,所述当前周期的新增对象集合包括所述当前周期内出现且所述历史时段内未出现的对象的标识。
7.根据本技术实施例的一个方面,提供了一种计算机设备,所述计算机设备包括处理器和存储器,所述存储器中存储有计算机程序,所述计算机程序由所述处理器加载并执
行以实现上述数据处理方法。
8.根据本技术实施例的一个方面,提供了一种计算机可读存储介质,所述可读存储介质中存储有计算机程序,所述计算机程序由处理器加载并执行以实现上述数据处理方法。
9.根据本技术实施例的一个方面,提供了一种计算机程序产品,该计算机程序产品包括计算机指令,该计算机指令存储在计算机可读存储介质中。计算机设备的处理器从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行上述数据处理方法。
10.本技术实施例提供的技术方案可以包括如下有益效果:通过将当前周期的对象集合划分成多个子集,分别与全量对象集合进行比对,得到当前周期的新增对象集合,使得多个子集可以同步与全量对象集合进行比对,节约了数据处理所需要的时间,提高了数据处理的效率。
附图说明
11.图1是本技术一个实施例提供的方案实施环境的示意图;图2是本技术另一个实施例提供的方案实施环境的示意图;图3是本技术一个实施例提供的数据处理方法的流程图;图4是本技术另一个实施例提供的数据处理方法的流程图;图5是本技术另一个实施例提供的数据处理方法的流程图;图6是本技术另一个实施例提供的数据处理方法的流程图;图7是本技术另一个实施例提供的数据处理方法的流程图;图8是本技术另一个实施例提供的数据处理方法的流程图;图9是本技术一个实施例提供的数据处理装置的框图;图10是本技术另一个实施例提供的数据处理装置的框图;图11是本技术一个实施例提供的计算机设备的结构框图。
具体实施方式
12.为使本技术的目的、技术方案和优点更加清楚,下面将结合附图对本技术实施方式作进一步地详细描述。
13.请参考图1,其示出了本技术一个实施例提供的方案实施环境的示意图。该方案实施环境可以是hadoop架构100,包括hadoop分布式文件系统(hadoop distributed file system,hdfs)120和mapreduce(映射归约)引擎140。
14.hadoop架构100是用来解决数据离线批处理问题的框架,其中核心部分是分布式文件系统120和mapreduce引擎140。hdfs是架构在hadoop之上的分布式文件系统,mapreduce是架构在hadoop之上用来做计算的框架。
15.分布式文件系统120是一个设计用于在普通硬件上运行的分布式文件系统。它与一些常规的分布式文件系统有许多相似之处。但是,与其他分布式文件系统的区别也非常明显。hdfs是高度容错的,设计用于部署在低成本的硬件上。hdfs提供对应用程序数据的高吞吐量访问,适用于具有大数据集的应用程序。hdfs放宽了对posix的一些要求,允许对文
件系统数据进行流访问。
16.mapreduce引擎140是以可靠的、容错的方式在大型集群(数千个节点)上并行处理大量数据的应用程序,其中map本意可以理解为地图、映射,这里可以理解为从现实世界获得或产生映射。reduce本意是减少,这里可以理解为归并前面map产生的映射。编程模型只包含map和reduce两个过程,map的主要输入是一对《key,value》值,经过map计算后输出一对《key,value》值;然后将相同key合并,形成《key,value集合》;再将结果输入reduce,经过计算输出零个或多个《key,value》对。
17.在一些实施例中,本技术技术方案中所示的数据处理方法可以运用于上述hadoop架构100中,由mapreduce引擎140执行。
18.请参考图2,其示出了本技术另一个实施例提供的方案实施环境的示意图。该方案实施环境可以是spark架构200,包括:driver(驱动程序)220、cluster manager(集群资源管理服务)240和至少一个woke node(工作节点)260。
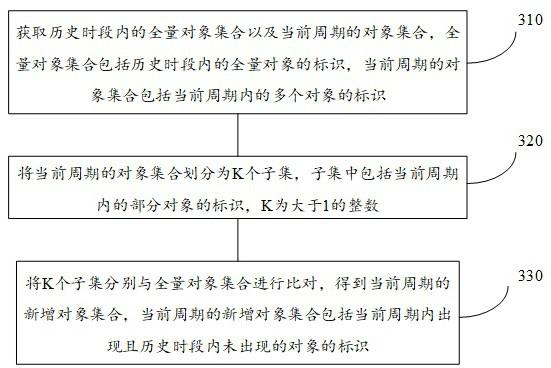
19.spark架构200是一个围绕速度、易用性和复杂分析构建的大数据处理框架。
20.driver(驱动程序)220是运行application(应用)的main函数。
21.cluster manager(集群资源管理服务)240在standalone(独立的)模式中即为master(控制器)主节点,控制整个集群,控制worker(工作点)。在yarn(yet another resource negotiator,另一种资源协调者)模式中为资源管理器。
22.woke node(工作节点)260是从节点,负责控制计算节点,启动executor(执行者)或者driver(驱动程序)。
23.在一些实施例中,本技术技术方案中所示的数据处理方法可以运用于spark架构200中,由woke node(工作节点)260执行。
24.上述图1和图2给出的两个方案实施环境,仅是示例性和解释性的,本技术技术方案除了能够应用于上述2种实施环境中之外,还可以应用于其他具有数据处理需求的实施环境或场景下,本技术对此不作限定。
25.请参考图3,其示出了本技术一个实施例提供的数据处理方法的流程图。该方法各步骤的执行主体可以是图1所示方案实施环境中的mapreduce引擎14,可以是图2所示方案实施环境中的woke node(工作节点)26。在下文方法实施例中,为了便于描述,仅以各步骤的执行主体为“计算机设备”进行介绍说明。该方法可以包括如下几个步骤(310~330)中的至少一个步骤。
26.步骤310,获取历史时段内的全量对象集合以及当前周期的对象集合,全量对象集合包括历史时段内的全量对象的标识,当前周期的对象集合包括当前周期内的多个对象的标识。
27.全量对象集合包括历史时段内的全量对象的标识,全量对象的标识是指在历史时段内发生某些/某种行为的对象的标识。全量对象集合可以基于对象行为数据,统计分析得到。在一些实施例中,计算机设备采集对象行为数据,并记录在存储器中。
28.对象行为包括但不限于注册行为、点击行为、浏览行为、停留行为、搜索行为。在一些实施例中,历史时段的全量对象集合是指基于当前周期以前的所有对象注册行为数据,统计分析得到的对象集合。在一些实施例中,历史时段的全量对象集合是指当前周期以前的所有对象点击行为数据,统计分析得到的对象集合。在一些实施例中,历史时段的全量对
象集合是指当前周期以前的所有对象浏览行为数据,统计分析得到的对象集合。在一些实施例中,历史时段的全量对象集合是指当前周期以前的所有对象停留行为数据,统计分析得到的对象集合。在一些实施例中,历史时段的全量对象集合是指当前周期以前的所有对象搜索行为数据,统计分析得到的对象集合。相应的,当前周期的对象集合也是如此,在此不作赘述。
29.在一些实施例中,当前周期是从第一时刻起算,到第二时刻为止,则第一时刻到第二时刻内,所有对象行为数据称为当前周期的对象集合。在一些实施例中,第一时刻是t1时刻,第二时刻是t2时刻,当前周期是从t1时刻起算,到t2时刻为止,则t1到t2时刻内,所有对象行为数据称为当前周期的对象集合。
30.相应地,历史时段是在第一时刻以前,全量对象集合是指第一时刻以前的所有对象行为数据的集合。在一些实施例中,第一时刻是t1时刻,则t1时刻以前的所有对象行为数据的集合称为全量对象集合。
31.全量对象集合包括历史时段内的全量对象的标识,当前周期的对象集合包括当前周期内的多个对象的标识。在一些实施例中,全量对象集合是基于历史时段内的对象行为数据,统计分析得到的对象集合,当前周期的对象集合是基于当前周期内的多个对象行为数据,统计分析得到的对象集合。在一些实施例中,对象的标识指对象的id(identifier,标识符)。对象的id可以是数字、字母、符号中的至少一种或者几种的组合。在一些实施例中,对象的id是数字,根据注册时间的长短,由大到小或者由小到大编号。在一些实施例中,对象的id是随机生成的字母数字组合,没有规律。在一些实施例中,对象的标识还可以是其他能够指代对象的标志,在此不作限定。
32.计算机设备获取历史时段内的全量对象集合以及当前周期的对象集合。在一些实施例中,计算机设备主动去存储历史时段内的全量对象集合以及当前周期的对象集合。可选地,计算机设备内部获取并存储历史时段内的全量对象集合以及当前周期的对象集合,在计算机设备需要历史时段内的全量对象集合以及当前周期的对象集合时,由计算机设备从内部进行获取。在一些实施例中,计算机设备从其他计算机设备获取历史时段内的全量对象集合以及当前周期的对象集合。可选地,其他计算机设备用于获取并存储历史时段内的全量对象集合以及当前周期的对象集合,在计算机设备需要历史时段内的全量对象集合以及当前周期的对象集合时,由其他计算机设备提供给计算机设备。
33.步骤320,将当前周期的对象集合划分为k个子集,子集中包括当前周期内的部分对象的标识,k为大于1的整数。
34.可选地,每个子集中包括当前周期内的部分对象的标识。不同子集中对象标识不存在重复。k个子集中分别包含的对象的总和,即为当前周期的对象集合中包含的所有对象。
35.子集的划分有很多种划分方式。在一些实施例中,按照每个子集的数量划分,划分可以是平均分配、随机分配中的至少一种,本技术对此不作限定。在一些实施例中,按照对象的标识划分,划分可以是升序划分、降序划分、随机划分中的至少一种。
36.在一些实施例中,假设k是10,当前周期的对象有10000个。计算机设备将当前周期的对象集合平均分配到10个子集,每个子集中有1000个对象,可选地,每个子集包括1000个对象标识。
37.在一些实施例中,假设k是10,当前周期的对象有10000个。计算机设备将当前周期的对象集合按照对象的标识升序平均分到10个子集,每个子集中有1000个对象标识,可选地,每个子集中的当前周期的对象标识是递增的。
38.步骤330,将k个子集分别与全量对象集合进行比对,得到当前周期的新增对象集合,当前周期的新增对象集合包括当前周期内出现且历史时段内未出现的对象的标识。
39.比对的目的是将k个子集中不同于全量对象集合中的对象筛选出来。在一些实施例中,比对的方式是逐一比对,将k个子集逐一分别与全量对象集合进行比对,k个子集同时并行进行比对。在一些实施例中,比对的方式是逐一比对,将k个子集逐一分别与全量对象集合进行比对,k个子集部分并行比对,k个子集中一半的子集和全量对象集合先同时进行比对,在结果出来之后,另一半子集同时和全量对象集合进行比对。
40.比对所选取的方式可以是mapreduce中leftjoin(左连)操作,也可以是其他用于筛选数据的操作,本技术在此不作限定。
41.当前周期的新增对象集合包括当前周期内出现且历史时段内未出现的对象的标识。在一些实施例中,新增对象是指在当前周期内出现且历史时段内未出现的对象,可选地,在历史时段内只出现了标识1~100的对象,在当前周期内出现了标识40~120的对象,则标识为101~120的对象是当前周期的新增对象,这两个新增对象所构成的集合是新增对象集合。
42.计算机设备采用分布式的k个处理节点,同步将k个子集分别与全量对象集合进行比对;其中,每一个处理节点用于将一个子集与全量对象集合进行比对。在一些实施例中,处理节点是服务器,计算机设备用k个服务器来将k个子集同步和全量对象集合进行比对。在一些实施例中,k是10,计算机设备通过10个服务器,对10个子集分别同步和全量对象集合进行比对,得到当前周期的新增对象集合。处理节点还可以是不同的虚拟机或者其他具备数据计算和处理能力的实体或虚拟设备,本技术对此不作限定。
43.计算机设备将当前周期的新增对象集合中包含的各个对象的标识,添加至全量对象集合中,得到更新后的全量对象集合。在一些实施例中,在t0到t1周期,新增对象集合包含的标识是101~120,全量对象集合包含的标识是1~100,则更新后的全量对象的集合是1~120,这是t1时刻的全量对象集合包含的标识。
44.计算机设备根据当前周期的新增对象集合,确定当前周期的新增对象数量。在一些实施例中,在t0到t1周期,新增对象集合包含的标识是101~120,则新增对象数量是20。
45.计算机设备根据当前周期的新增对象集合,确定当前周期的新增对象数量;根据当前周期的新增对象数量和历史时段的累计对象数量,确定更新后的累计对象数量。在一些实施例中,在t0到t1周期,新增对象集合包含的标识是110~120,新增对象的数量是20,全量对象集合包含的标识是1~100,历史时段的对象数量是100,则当前周期的新增对象数量是20,则更新后的累计对象数量是120。
46.计算机设备根据当前周期的新增对象集合,确定目标统计指标在当前周期的新增数量。目标统计指标包括以下至少一项:浏览量、点击量、搜索量。在一些实施例中,计算机设备根据所述当前周期的新增对象集合,确定浏览量在所述当前周期的新增数量。在一些实施例中,计算机设备根据所述当前周期的新增对象集合,确定点击量在所述当前周期的新增数量。在一些实施例中,计算机设备根据所述当前周期的新增对象集合,确定在所述当
前周期的新增数量。在一些实施例中,计算机设备根据所述当前周期的新增对象集合,确定搜索量在所述当前周期的新增数量。
47.计算机设备根据所前周期的新增对象集合,确定目标统计指标在当前周期的新增数量;根据目标统计指标在当前周期的新增数量,以及在历史时段的累计数量,确定目标统计指标更新后的累计数量。在一些实施例中,目标统计指标是浏览量,新增数量是第一浏览数量,历史时段的累计数量是第二浏览数量,则浏览量的更新后的累计数量是第一浏览数量加上第二浏览数量。其他目标统计指标的累计数量算法和浏览量指标的累计数量算法一致,在此不作赘述。
48.综上所述,本技术实施例提供的技术方案,通过将当前周期的对象集合划分成多个子集,分别与全量对象集合进行比对,得到当前周期的新增对象集合,使得多个子集可以同步与全量对象集合进行比对,节约了数据处理所需要的时间,提高了数据处理的效率。
49.请参考图4,其示出了本技术另一个实施例提供的数据处理方法的流程图。在本实施例中以标识类型是数值型为例,对本技术技术方案进行介绍说明。同样的,为了便于描述,仅以各步骤的执行主体为“计算机设备”进行介绍说明。该方法可以包括如下几个步骤(410~470)中的至少一个步骤。
50.数值型标识是数字尺度测量的标识,其结果表现为具体的数值,如1、2、3、4等按序编号的id。
51.步骤410,获取历史时段内的全量对象集合以及当前周期的对象集合,全量对象集合包括历史时段内的全量对象的标识,当前周期的对象集合包括当前周期内的多个对象的标识。
52.步骤420,将当前周期的对象集合划分为k个子集,子集中包括当前周期内的部分对象的标识,k为大于1的整数。
53.在一些实施例中,计算机设备按照目标顺序对当前周期的对象集合中包含的各个对象的标识进行排序,得到标识序列;将标识序列等分为k个子序列,得到k个子集。在一些实施例中,按照升序对当前周期的对象集合中包含的各个对象的标识进行排序,得到标识序列。在一些实施例中,按照降序对当前周期的对象集合中包含的各个对象的标识进行排序,得到标识序列。
54.步骤430,对于k个子集中的每一个子集,获取子集中包含的标识的最大值和最小值,得到k个最值对。
55.在一些实施例中,对象的标识是数值型的,对象的标识是根据对象的注册时间来确定的,由小到大赋予对象的。在一些实施例中,对象的标识是数值型的,对象的标识是根据注册对象的时间来确定的,由大到小赋予对象的。
56.在一些实施例中,分成的k个子集中必然存在最大值和最小值,将每个子集中的最大值和最小值都筛选出来,得到k个最值对。示例性的,当前周期的对象集合包含的标识是1~10000,平均分成10个子集,那么10个最值对分别是1,1000;1001,2000;2001,3000;3001,4000;4001,5000;5001,6000;6001,7000;7001,8000;8001,9000;9001,10000。在一些实施例中,最大值构成第一集合,第一集合包括1000、2000、3000、4000、5000、6000、7000、8000、9000、10000。在一些实施例中,最小值构成第二集合,第二集合包括1、1001、2001、3001、4001、5001、6001、7001、8001、9001。
57.步骤440,从k个最值对中,确定与目标最值对应的目标最值对;其中,目标最值是指全量对象集合中包含的标识的最值,目标最值大于或等于目标最值对中的最小值,且目标最值小于或等于目标最值对中的最大值。
58.在一些实施例中,目标最值是全量对象集合的包含的标识的最值。可选地,最值是最大值或者最小值。在一些实施例中,目标最值是全量对象集合中的最大值。在一些实施例中,目标最值是最大值,目标最值是5006,那么从10个最值对中,确定出目标最值对应的目标最值对,也即5001,6000这一最值对。在一些实施例中,目标最值是最小值,目标最值是3400,那么从10个最值对中,确定出目标最值对应的目标最值对,也即3001,4000这一最值对。
59.步骤450,从k个子集中,根据目标子集确定包含的对象全部为新增对象的新增子集;其中,目标子集是指k个子集中与目标最值对对应的子集。
60.在一些实施例中,根据目标子集,确定出目标最值在目标子集中的位置。在步骤440中,已经确定出与目标最值对应的目标最值对,也即确定出于目标最值所在的目标子集。在一些实施例中,目标最值是最大值,目标最值是5006,目标最值对是5001,6000,新增子集即为包含的对象全部大于5006的子集,也即后四个子集6001~7000,7001~8000,8001~9000,9001~10000。在一些实施例中,目标最值是最小值,目标最值是3400,目标最值对是3001,4000,新增子集即为包含的对象全部小于3400的子集,新增子集也就是前三个子集1~1000,1001~2000,2001~3000。
61.步骤460,根据目标最值,确定目标子集中包含的新增对象。
62.通过将目标子集中的对象标识与目标最值进行比对,确认出大于/小于目标最值的对象的标识的集合,即为新增子集。在一些实施例中,根据目标子集,确定出目标最值在目标子集中的位置。在步骤440中,已经确定出与目标最值对应的目标最值对,也即确定出于目标最值所在的目标子集。在一些实施例中,目标最值是最大值,目标最值是5006,目标最值对是5001,6000,目标子集即为大于5006小于等于6000的对象的标识的集合,新增对象的标识也就是5007~6000。目标最值是最小值,目标最值是3400,目标最值对是3001,4000,目标子集即为小于3400大于等于3001的目标对象的标识的集合,新增对象的标识也就是3001~3399。
63.步骤470,根据新增子集和目标子集中包含的新增对象,得到当前周期的新增对象集合。
64.当前周期的新增对象是新增子集和目标子集中包含的新增对象的总和。在一些实施例中,当前周期的对象集合包含的标识是1~10000,平均分成10个子集,目标最值是最大值,目标最值是5006,目标最值对是5001,6000。新增子集为6001~7000,7001~8000,8001~9000,9001~10000。目标子集中新增对象的标识是5007~6000。因此,当期周期的新增对象的标识是5007~10000。
65.在一些实施例中,当前周期的对象集合包含的标识是1~10000,平均分成10个子集,目标最值是最小值,目标最值是3400,目标最值对是3001,4000。新增子集是1~1000,1001~2000,2001~3000。目标子集中新增对象的标识是3001~3399。因此,当前周期的新增对象的标识是1~3399。
66.在本实施例中,对象的标识是数值型,通过将当前周期的对象集合划分成多个子
集,获取子集中包含的标识的最大值和最小值,得到多个最值对,只需将目标最值分别与多个最值对进行比对,得到当前周期的新增对象集合,节约了数据处理所需要的时间,提高了数据处理的效率。
67.请参考图5,其示出了本技术另一个实施例提供的数据处理方法的流程图。在本实施例中以标识类型是数值型为例,对本技术技术方案进行介绍说明。同样的,为了便于描述,仅以各步骤的执行主体为“计算机设备”进行介绍说明。该方法可以包括如下几个步骤(510~590)中的至少一个步骤。
68.步骤510,获取历史时段内的全量对象集合以及当前周期的对象集合,全量对象集合包括历史时段内的全量对象的标识,当前周期的对象集合包括当前周期内的多个对象的标识。
69.步骤520,将当前周期的对象集合划分为k个子集,子集中包括当前周期内的部分对象的标识,k为大于1的整数。
70.步骤530,对于k个子集中的每一个子集,获取该子集中包含的标识的最大值和最小值,得到k个最值对。
71.步骤540,从k个最值对中,确定与目标最值对应的目标最值对;其中,目标最值是指全量对象集合中包含的标识的最值,目标最值大于或等于目标最值对中的最小值,且目标最值小于或等于目标最值对中的最大值。
72.步骤550,从k个子集中,根据目标子集确定包含的对象全部为新增对象的新增子集;其中,目标子集是指k个子集中与目标最值对对应的子集。
73.步骤560,以目标子集为初始的待检测集,获取待检测集中包含的各个对象的标识的中位数。
74.中位数是指将一组数据按照大小依次排序,处在最中间位置的那个数叫做这组数据的中位数。在一些实施例中,对象的标识是数值型,可以对其进行排序并且求得中位数。在一些实施例中,一组数据是自然数列或者等差数列,中位数是该数列的平均数。在一些实施例中,待检测集是1001~2001,1001个整数,那么中位数是1501。
75.步骤570,判断目标最值与中位数是否相等。
76.若相等,则执行步骤580;若不相等,则执行步骤572。
77.计算机设备判断目标最值与中位数是否相等,如果目标最值与中位数相等,说明找到了目标最值在待测子集中的位置,则可以直接计算待测子集中的新增对象。反之,如果目标最值与中位数不相等,说明还未找到目标最值在待测子集中的位置,还需继续与下一个中位数进行比较。
78.在一些实施例中,待检测集是1001~2001,那么中位数是1501,目标最值是1700,那么目标最值大于中位数,目标最值与中位数不相等,则执行步骤572。
79.在一些实施例中,待检测集是1001~2001,那么中位数是1501,目标最值是1501,那么目标最值等于中位数,则执行步骤580。
80.步骤572,根据中位数将待检测集划分为第一检测子集和第二检测子集。
81.在一些实施例中,按照目标顺序对所述当前周期的对象集合中包含的各个对象的标识进行排序,得到标识序列。待测子集也同样是顺序排列的,待测子集中必然存在最大值和最小值,以及中间的中位数,中位数将待测子集划分成第一检测子集和第二检测子集,第
一检测子集包括最大值到中位数之间的序列,第二检测子集包括中位数到最小值之间的序列。或者,第一检测子集包括最小值到中位数之间的序列,第二检测子集包括中位数到最大值之间的序列。
82.在一些实施例中,待检测集是1001~2001,那么中位数是1501,目标最值是1700,那么目标最值大于中位数,目标最值与中位数不相等,第一检测子集是1001~1501,第二检测子集是1501~2001。
83.步骤574,根据目标最值与中位数的大小关系,确定目标最值所属的目标检测子集,目标检测子集是第一检测子集和第二检测子集中的一个。
84.在一些实施例中,在判断出目标最值与中位数不相等之后,判断目标最值是的大于中位数还是小于中位数。在一些实施例中,待测子集是升序排列的,判断出目标最值大于中位数之后,确定出目标最值处于第二检测子集,第二检测子集是待测子集中中位数到最大值的集合。在一些实施例中,待测子集是降序排列的,判断出目标最值大于中位数之后,确定出目标最值处于第一检测子集,第一检测子集是待测子集中最大值到中位数的集合。
85.在一些实施例中,待检测集是1001~2001,那么中位数是1501,目标最值是1700,那么目标最值大于中位数,目标最值与中位数不相等,第一检测子集是1001~1501,第二检测子集是1501~2001。目标最值1700大于中位数1501,因此目标检测子集是第二检测子集1501~2001。
86.步骤576,将目标检测子集作为更新后的待检测集;获取待检测集中包含的各个对象的标识的中位数。
87.在一些实施例中,将第一检测子集作为目标检测子集,同时作为更新后的待测子集,获取第一检测子集中的中位数。在一些实施例中,第一检测子集是等差序列并且递增的,则第一检测子集的中位数是第一检测子集的平均数。在一些实施例中,第二检测子集是等差序列并且递减的,则第二检测子集的中位数是第二检测子集的平均数。
88.在一些实施例中,待检测集是1001~2001,那么中位数是1501,目标最值是1700,第一检测子集是1001~1501,第二检测子集是1501~2001。目标最值1700大于中位数1501,目标检测子集也即更新后的待测子集是第二检测子集1501~2001。待测子集的中位数是1751。之后,将1700继续与中位数1751进行比对,一直到目标最值等于中位数为止。
89.执行完步骤576之后,再次执行步骤570。
90.步骤580,根据中位数确定目标子集中包含的新增对象。
91.在一些实施例中,目标最值是最大值,根据中位数确定目标子集中包含的新增对象的标识即目标子集中包含的对象的标识大于中位数小于或等于最大值的标识。在一些实施例中,目标最值是最小值,根据中位数确定目标子集中包含的新增对象的标识即目标子集中包含的对象的标识大于或等于最小值且小于中位数的标识。
92.在一些实施例中,目标子集是1001~2001,目标最值是1700,根据上述步骤,得到中位数等于目标最值也即1700。在一些实施例中,目标最值是最大值,目标子集中的包含的新增对象的标识是1701~2001。在一些实施例中,目标最值是最小值,目标子集中的包含的新增对象的标识是1001~1699。
93.步骤590,根据新增子集和目标子集中包含的新增对象,得到当前周期的新增对象集合。
94.在本实施例中,对象的标识是数值型,通过目标子集的中位数与目标最值进行比对,得到当前周期的新增对象集合,节约了数据处理所需要的时间,提高了数据处理的效率。
95.请参考图6,其示出了本技术另一个实施例提供的数据处理方法的流程图。在本实施例中以标识类型是字符串型为例,对本技术技术方案进行介绍说明。同样的,为了便于描述,仅以各步骤的执行主体为“计算机设备”进行介绍说明。该方法可以包括如下几个步骤(610~640)中的至少一个步骤。
96.字符串或串(string)是由数字、字母、下划线组成的一串字符。一般记为s="a1a2
···
an"(n》=0)。它是编程语言中表示文本的数据类型。在程序设计中,字符串为符号或数值的一个连续序列,如符号串(一串字符)或二进制数字串(一串二进制数字)。
97.步骤610,获取历史时段内的全量对象集合以及当前周期的对象集合,全量对象集合包括历史时段内的全量对象的标识,当前周期的对象集合包括当前周期内的多个对象的标识。
98.步骤620,将当前周期的对象集合划分为k个子集,子集中包括当前周期内的部分对象的标识,k为大于1的整数。
99.在一些实施例中,将当前周期的对象集合中包含的各个对象的标识,等分为k份,得到所述k个子集。在一些实施例中,当前周期的对象标识是字符串型,对当前周期的对象标识随机等分成k份。在一些实施例中,当前周期的对象标识是串型,对当前周期的对象标识随机等分成k份。
100.步骤630,对于k个子集中的每一个子集,将子集中包含的对象的标识与全量对象集合中包含的对象的标识进行比对,确定子集中包含的新增对象。
101.在一些实施例中,k个子集中的每个子集中包含的对象的标识都与历史时段的全量对象集合中的对象标识进行比对,确定出每个子集中包含的新增对象。在一些实施例中,将每个子集中包含的每个对象的标识逐一与全量对象集合的对象的标识进行比对,比对出每个子集中不同于全量对象集合的对象的标识。
102.步骤640,根据k个子集中分别包含的新增对象,确定当前周期的新增对象集合。
103.在本实施例中,对象的标识是字符串型,通过将当前周期的对象集合划分成多个子集,多个子集同步与全量对象集合进行比对,得到当前周期的新增对象集合,节约了数据处理所需要的时间,提高了数据处理的效率。
104.请参考图7,其示出了本技术另一个实施例提供的数据处理方法的流程图。在本实施例中以标识类型是字符串型为例,对本技术技术方案进行介绍说明。同样的,为了便于描述,仅以各步骤的执行主体为“计算机设备”进行介绍说明。该方法可以包括如下几个步骤(710~750)中的至少一个步骤。
105.步骤710,获取历史时段内的全量对象集合以及当前周期的对象集合,全量对象集合包括历史时段内的全量对象的标识,当前周期的对象集合包括当前周期内的多个对象的标识。
106.步骤720,将当前周期的对象集合划分为k个子集,子集中包括当前周期内的部分对象的标识,k为大于1的整数。
107.步骤730,将子集作为左表,全量对象集合作为右表,以对象的标识作为连接字段,
确定左表和右表中有重合的重复子集。
108.在一些实施例中,第一子集中包含的标识中标识1、标识2、标识3、标识4、标识5,全量对象集合包括标识1、标识2,其中标识1、标识2、标识3、标识4、标识5是字符串型,彼此之间并不相同且没有关联。将第一子集作为左表,全量对象集合作为右表,以对象的标识作为连接字段,确定左表和右表中有重合的重复子集。重复子集包含的对象标识有标识1、标识2。
109.步骤740,将子集去掉重复子集,得到子集中包含的新增对象。
110.在一些实施例中,第一子集中包含的标识中标识1、标识2、标识3、标识4、标识5,全量对象集合包括标识1、标识2,其中标识1、标识2、标识3、标识4、标识5是字符串型,彼此之间并不相同且没有关联。重复子集包含的对象标识有标识1、标识2。将第一子集去掉重复子集,得到子集中包含的新增对象。新增对象的标识有标识3、标识4、标识5。
111.步骤750,根据k个子集中分别包含的新增对象,确定当前周期的新增对象集合。
112.在本实施例中,对象的标识是字符串型,通过多个子集同步与全量对象集合采用左连的操作,得到当前周期的新增对象集合,节约了数据处理所需要的时间,提高了数据处理的效率。
113.请参考图8,其示出了本技术另一个实施例提供的数据处理方法的流程图。该方法各步骤的执行主体可以是图1所示方案实施环境中的mapreduce引擎14,可以是图2所示方案实施环境中的woke node(工作节点)26。在下文方法实施例中,为了便于描述,仅以各步骤的执行主体为“计算机设备”进行介绍说明。该方法可以包括如下几个步骤(s1~s29)。
114.对本实施例中提到的词作以下解释:uv(unique visitor,独立访客量)、pv(page view,页面浏览量)。
115.本方案整体流程主要可分为以下四个阶段:初始(t0)数据输入阶段、数据类型判断阶段、初始(t0)对象集tu0及初始浏览次数tpv0和初始访问对象数tuv0获取阶段、t1周期数据分布式打散阶段、t1时刻对象集tu1及tpv1和tuv1获取阶段、tn周期数据分布式打散阶段、tn时刻对象集tun及tpvn和tuvn获取阶段。
116.s1.初始数据输入阶段。输入t0周期阶段的对象数据作为初始输入。
117.s2.数据类型判断阶段。输入s1的t0周期的初始对象id数据,采用判别函数判断对象id类型,对于对象id存储格式是字符串型,但其内容是数值型数据,需要先转换为数值型,并输出转换后的对象id数据集u0。如果对象数据是数值型,则执行步骤s3~s12。如果对象数据是字符串型,则执行步骤s20~s29。
118.s3.初始(t0)对象集tu0及初始对象uv、初始pv获取阶段。输入s1的初始对象数据u0。采用去重方式并按对象id从小到大进行排序得到初始全量对象集合tu0,采用mapreduce分布式方式计算初始累计uv()、初始累计pv()。
119.s4.t1周期数据分布式打散阶段。输入t1周期对象id数据u1。
120.s5.对u1按照从大到小进行降序排列,将数据等分为k个子集,并按顺序依次存放到k个处理节点中。
121.s6.获取每个子集中的最值对。对每个处理节点中排第一位的对象id与最后一位对象id分别构成的序列,(其中,
表示第1个统计周期下第j个处理节点中存储对象id第一位的对象id,表示第1个统计周期下第j个处理节点中存储对象id最后一位的对象id,m表示每个处理节点中存储的对象数为m)。
122.s7.将和分别与上一周期全量对象集合中排第一位对象id(最大的对象id)对比,必然得到中点位置及对象id(),而将前的每个处理节点对象按先后顺序进行合并得到新增对象集合,并且得到新增对象数量为。从而根据迭代公式,对象数量和次数,输入s2的初始累计uv()、初始累计pv(),从而根据迭代公式,计算t1时刻累计对象数量,计算t1时刻累计对象次数。同时,将t1周期第一个子集的第一位的对象id至组成新增对象集,直接插入t0统计周期的全量对象集合tu0中得到t1周期的全量降序对象集合={union(并集)}。
123.s8.tn周期数据分布式打散阶段。输入tn周期对象id数据un。
124.s9.对un按照从大到小进行降序排列,将数据等分为k个子集,并按顺序依次存放到k个处理节点中。
125.s10.对每个处理节点中排第一位的对象id与最后一位对象id分别构成的序列,(其中,表示第n个统计周期下第j个处理节点中存储对象id第一位的对象id,表示第n个统计周期下第j个处理节点中存储对象id最后一位的对象id,m表示每个处理节点中存储的对象数量为m)。
126.s11.将和分别与上一周期全量对象集合中排第一位对象id(最大的对象id)对比,必然得到中点位置及对象id(),而将前的每个处理节点对象按先后顺序进行合并得到新增对象集合,并且得到新增对象数量为。从而根据迭代公式,对象数和次数,输入上一周期的累计uv()、累计pv(),从而根据迭代公式,计算tn时刻累计对象数量,计算tn时刻累计对象次数。同时,将tn周期第一个子集的第一位的对象id至组成新增对象集合
,直接插入t
n-1
统计周期的全量对象集合tun-1中得到tn周期的全量降序对象集合={union}。
127.s21.初始(t0)对象集合tu0及初始对象uv、初始pv获取阶段。输入s1的初始对象数据u0。采用去重方式并按对象id从小到大进行排序得到初始全量对象集合tu0,采用mapreduce分布式方式计算初始累计uv()、初始累计pv()。
128.s22.t1周期数据分布式打散阶段。输入t1周期对象id数据u1。
129.s23.将u1随机等分为k个子集,并存放到k个处理节点中。
130.s24.将t0统计周期的全量去重对象集分别上传到k个处理节点中,对每个子集采用mapreduce的leftjoin操作。
131.s25.得到每个处理节点的新增对象集合,记为:表示第1个统计周期第j个处理节点的新增对象集合,并统计每个新增对象集合的新增对象数量uv,记为:。从而得到当前周期新增对象集合为:,当前周期新增对象数量为:。对于t1周期的浏览量计算,则在每个处理节点中均采用mapreduce的count(聚合)操作,得到每个处理节点的浏览量pv,记为:。从而得到t1周期各个处理节点的浏览量为:,则t1周期的总浏览量为:。输入step2的初始累计uv()、初始累计pv(),从而根据迭代公式,计算t1时刻累计对象数量,计算t1时刻累计对象次数。同时,将t1周期新增对象集合,直接插入t0统计周期的全量对象集tu0中得到t1周期的全量降序对象集={union}。
132.s26.tn周期数据分布式打散阶段。输入tn周期对象id数据un。
133.s27.将un随机等分为k个子集,并存放到k个处理节点中。
134.s28.将t
n-1
统计周期的全量去重对象集合分别上传到k个处理节点中,对每个子集采用mapreduce的leftjoin操作。
135.s29.得到每个处理节点的新增对象集合,记为:表示第n个统计周期第j个处理节点的新增对象集合,并统计每个新增对象集合的新增对象数量uv,记为:。从而得到当前周期新增对象集合为:,当前周期新增对象数量为:
。对于tn周期的浏览量计算,则在每个服务其中均采用mapreduce的count操作,得到每个处理节点的浏览量pv,记为:。从而得到tn周期各个处理节点的浏览量为:,则t1周期的总浏览量为:。输入上一周期的累计uv()、累计pv(),从而根据迭代公式,计算tn时刻累计对象数量,计算tn时刻累计对象次数。同时,将tn周期新增对象集合,直接插入t0统计周期的全量对象集合tun-1中得到tn周期的全量降序对象集={union}。
136.在本实施例中,通过判断数据类型,分别对数值型和字符串型的数据进行处理,对数值型的数据采取顺序等分成多个子集,与全量对象集合的目标最值进行比对;对字符串型的数据采取随机等分成多个子集,分别与全量对象集合进行比对,得到新增对象的集合,节约了数据处理所需要的时间,提高了数据处理的效率。
137.下述为本技术装置实施例,可以用于执行本技术方法实施例。对于本技术装置实施例中未披露的细节,请参照本技术方法实施例。
138.请参考图9,其示出了本技术一个实施例提供的数据处理装置的框图。该装置具有实现上述方法示例的功能,所述功能可以由硬件实现,也可以由硬件执行相应的软件实现。该装置可以是上文介绍的计算机设备,也可以设置在计算机设备中。如图9所示,该装置900可以包括:获取模块910、划分模块920和比对模块930。
139.获取模块910,用于获取历史时段内的全量对象集合以及当前周期的对象集合,所述全量对象集合包括所述历史时段内的全量对象的标识,所述当前周期的对象集合包括所述当前周期内的多个对象的标识。
140.划分模块920,用于将所述当前周期的对象集合划分为k个子集,所述子集中包括所述当前周期内的部分对象的标识,k为大于1的整数。
141.比对模块930,用于将所述k个子集分别与所述全量对象集合进行比对,得到所述当前周期的新增对象集合,所述当前周期的新增对象集合包括所述当前周期内出现且所述历史时段内未出现的对象的标识。
142.在一些实施例中,所述标识为数值型。如图10所示,所述比对模块930包括:最值获取单元931、最值对确定单元932、新增子集确定单元933、新增对象确定单元934和集合确定单元935。
143.最值获取单元931,用于获取所述子集中包含的标识的最大值和最小值,得到k个最值对。
144.最值对确定单元932,用于确定与目标最值对应的目标最值对;其中,所述目标最
值是指所述全量对象集合中包含的标识的最值,所述目标最值大于或等于所述目标最值对中的最小值,且所述目标最值小于或等于所述目标最值对中的最大值。
145.新增子集确定单元933,用于确定包含的对象全部为新增对象的新增子集;其中,所述目标子集是指所述k个子集中与所述目标最值对对应的子集。
146.新增对象确定单元934,用于确定所述目标子集中包含的新增对象。
147.集合确定单元935,用于得到所述当前周期的新增对象集合。
148.可选地,所述新增对象确定单元934,用于:以所述目标子集为初始的待检测集,获取所述待检测集中包含的各个对象的标识的中位数。
149.若所述目标最值与所述中位数不相等,则根据所述中位数将所述待检测集划分为第一检测子集和第二检测子集;根据所述目标最值与所述中位数的大小关系,确定所述目标最值所属的目标检测子集,所述目标检测子集是所述第一检测子集和所述第二检测子集中的一个;将所述目标检测子集作为更新后的待检测集,再次从所述获取所述待检测集中包含的各个对象的标识的中位数的步骤开始执行。
150.若所述目标最值与所述中位数相等,则根据所述中位数确定所述目标子集中包含的新增对象。
151.在一些实施例中,所述标识为字符串型。如图10所示,所述比对模块930包括:标识比对单元936和集合确定单元935。
152.标识比对单元936,用于将所述子集中包含的对象的标识与所述全量对象集合中包含的对象的标识进行比对,确定所述子集中包含的新增对象。
153.集合确定单元935,用于根据所述k个子集中分别包含的新增对象,确定所述当前周期的新增对象集合。
154.可选地,所述标识比对单元936,用于:将所述子集作为左表,所述全量对象集合作为右表,以对象的标识作为连接字段,确定所述左表和所述右表中有重合的重复子集;将所述子集去掉所述重复子集,得到所述子集中包含的新增对象。
155.在一些实施例中,所述标识为数值型。所述划分模块920,用于按照目标顺序对所述当前周期的对象集合中包含的各个对象的标识进行排序,得到标识序列;将所述标识序列等分为k个子序列,得到所述k个子集。
156.在一些实施例中,所述标识为字符串型。所述划分模块920,用于将所述当前周期的对象集合中包含的各个对象的标识,等分为k份,得到所述k个子集。
157.在一些实施例中,如图10所示,所述装置900还包括:添加模块940,用于将所述当前周期的新增对象集合中包含的各个对象的标识,添加至所述全量对象集合中,得到更新后的全量对象集合。
158.在一些实施例中,采用分布式的k个处理节点,同步将所述k个子集分别与所述全量对象集合进行比对;其中,每一个处理节点用于将一个子集与所述全量对象集合进行比对。
159.在一些实施例中,如图10所示,所述装置900还包括确定模块950,用于:根据所述当前周期的新增对象集合,确定所述当前周期的新增对象数量。
160.或者,
根据所述当前周期的新增对象集合,确定所述当前周期的新增对象数量;根据所述当前周期的新增对象数量和所述历史时段的累计对象数量,确定更新后的累计对象数量。
161.或者,根据所述当前周期的新增对象集合,确定目标统计指标在所述当前周期的新增数量。
162.或者,根据所述当前周期的新增对象集合,确定目标统计指标在所述当前周期的新增数量;根据所述目标统计指标在所述当前周期的新增数量,以及在所述历史时段的累计数量,确定所述目标统计指标更新后的累计数量。
163.其中,所述目标统计指标包括以下至少一项:浏览量、点击量搜索量。
164.综上所述,本技术实施例提供的技术方案,通过将当前周期的对象集合划分成多个子集,分别与全量对象集合进行比对,得到当前周期的新增对象集合,使得多个子集可以同步与全量对象集合进行比对,节约了数据处理所需要的时间,提高了数据处理的效率。
165.需要说明的是,上述实施例提供的装置,在实现其功能时,仅以上述各功能模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即将设备的内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。另外,上述实施例提供的装置与方法实施例属于同一构思,其具体实现过程详见方法实施例,这里不再赘述。
166.请参考图11,其示出了本技术一个实施例提供的计算机设备1100的结构框图。具体来讲:计算机设备1100包括中央处理单元(英文:central processing unit,简称:cpu)1101、包括随机存取存储器(英文:random access memory,简称:ram)1102和只读存储器(英文:read-only memory,简称:rom)1103的系统存储器1104,以及连接系统存储器1104和中央处理单元1101的系统总线1105。计算机设备1100还包括帮助计算机内的各个器件之间传输信息的基本输入/输出系统(i/o系统)1106,和用于存储操作系统1113、应用程序1114和其他程序模块1115的大容量存储设备1107。
167.基本输入/输出系统1106包括有用于显示信息的显示器1108和用于用户帐号输入信息的诸如鼠标、键盘之类的输入设备1109。其中显示器1008和输入设备1109都通过连接到系统总线1105的输入/输出控制器1110连接到中央处理单元1101。基本输入/输出系统1106还可以包括输入/输出控制器1110以用于接收和处理来自键盘、鼠标、或电子触控笔等多个其他设备的输入。类似地,输入/输出控制器1110还提供输出到显示屏、打印机或其他类型的输出设备。
168.大容量存储设备1107通过连接到系统总线1105的大容量存储控制器(未示出)连接到中央处理单元1101。大容量存储设备1107及其相关联的计算机可读介质为计算机设备1100提供非易失性存储。也就是说,大容量存储设备1007可以包括诸如硬盘或者只读光盘(英文:compact disc read-only memory,简称:cd-rom)驱动器之类的计算机可读介质(未示出)。
169.不失一般性,计算机可读介质可以包括计算机存储介质和通信介质。计算机存储介质包括以用于存储诸如计算机可读指令、数据结构、程序模块或其他数据等信息的任何
方法或技术实现的易失性和非易失性、可移动和不可移动介质。计算机存储介质包括ram、rom、可擦除可编程只读存储器(英文:erasable programmable read-only memory,简称:eprom)、电可擦除可编程只读存储器(英文:electrically erasable programmable read-only memory,简称:eeprom)、闪存或其他固态存储器技术,cd-rom、数字通用光盘(英文:digital versatile disc,简称:dvd)或其他光学存储、磁带盒、磁带、磁盘存储或其他磁性存储设备。当然,本领域技术人员可知计算机存储介质不局限于上述几种。上述的系统存储器1004和大容量存储设备1107可以统称为存储器。
170.根据本技术的各种实施例,计算机设备1100还可以通过诸如因特网等网络连接到网络上的远程计算机运行。也即计算机设备1100可以通过连接在系统总线1105上的网络接口单元1111连接到网络1112,或者说,也可以使用网络接口单元1111来连接到其他类型的网络或远程计算机系统(未示出)。
171.在一示例性实施例中,还提供了一种计算机可读存储介质,所述存储介质中存储有计算机程序,所述计算机程序在被处理器执行时以实现上数据处理方法。
172.可选地,该计算机可读存储介质可以包括:rom(read-only memory,只读存储器)、ram(random access memory,随机存取存储器)、ssd(solid state drives,固态硬盘)或光盘等。其中,随机存取存储器可以包括reram(resistance random access memory,电阻式随机存取存储器)和dram(dynamic random access memory,动态随机存取存储器)。
173.在一示例性实施例中,还提供了一种计算机程序产品,所述计算机程序产品包括计算机指令,所述计算机指令存储在计算机可读存储介质中。计算机设备的处理器从所述计算机可读存储介质中读取所述计算机指令,所述处理器执行所述计算机指令,使得所述计算机设备执行上述数据处理方法。
174.应当理解的是,在本文中提及的“多个”是指两个或两个以上。“和/或”,描述关联对象的关联关系,表示可以存在三种关系,例如,a和/或b,可以表示:单独存在a,同时存在a和b,单独存在b这三种情况。字符“/”一般表示前后关联对象是一种“或”的关系。另外,本文中描述的步骤编号,仅示例性示出了步骤间的一种可能的执行先后顺序,在一些其它实施例中,上述步骤也可以不按照编号顺序来执行,如两个不同编号的步骤同时执行,或者两个不同编号的步骤按照与图示相反的顺序执行,本技术实施例对此不作限定。
175.以上所述仅为本技术的示例性实施例,并不用以限制本技术,凡在本技术的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本技术的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1