一种意图泛化的可控制通用对话模型
1.本发明属于自然语言处理领域,涉及对话系统,具体是指一种意图泛化的可控制通用对话模型。
背景技术:
2.人机对话是自然语言处理领域的重要应用,其中任务型对话系统(task-oriented dialogue system,tod)与闲聊机器人(chatbot)吸引了学术与工业界的广泛研究;chatbot指的是用户不存在明确目的,系统只需要陪伴用户聊天,不需要完成某个具体目标,回合与回合之间往往不存在显式的联系。tod指的是用户具备明确目的,系统需要通过有限的对话回合,访问外部数据库,引导用户完成任务和实现目的,例如查询天气、推荐景点和预订酒店等。在实际开发中,tod的相关研究逐渐从单领域向多领域过渡,从追求在人工构建的测试集上提高预测准确率,转向去解决更加复杂的真实会话场景中的挑战迈进。
3.闲聊机器人一般是全数据驱动的,对话语料容易获取,不需要外部专家知识库或api,需要的监督信号少。相反tod由于涉及查询数据库以及跟踪任务的完成度,需要在用户与系统侧显式地识别槽值对信息与动作信息,这加大了构建数据集的成本。
4.经典的tod算法在处理多轮交互时将系统的工作流程划分为四个模块,分别是自然语言理解(nlu)、对话状态跟踪(dst)、对话策略管理(pol)和自然语言生成(nlg)。nlu模块负责理解用户的意图与行为;dst模块负责从理解的用户语义信息中抽取实体和属性,以跟踪当前任务的完成情况(记为对话状态);pol模块负责系统根据dst的结果查询知识库后,选取合适的动作;最后,nlg模块生成自然语言形式的系统回复,反馈给用户。
5.早期的多领域tod模型使用fixed-vocabulary based(基于静态词表)方法,该模型存在依赖预定义本体的全知性以及无法应对unseen slot values的问题。近年来,open vocabulary-based(基于开放词表)的方法逐渐取代了fixed-vocabulary based方法,将意图识别从多标签分类任务转化为了一个阅读理解,极大提升了模型的可扩展性。bert和gpt2预训练语言模型(pretrained language model,plm)的出现进一步促进了端到端(end-to-end)框架的发展,学术界利用plm对通用文本的建模能力,跳过nlu阶段直接作dst,降低了模型的算法复杂度与推理时延。
6.然而,在实际生活中,对话的过程不局限于单一任务,也不严格遵循预定义的任务完成的流程,而是融合了闲聊(chitchat)型对话与任务型对话(tod)的复合过程。显然,在单一类型的语料上学习到的参数化模型无法应对这种通用对话任务;其次,现有任务型对话模型所用语料内的监督信息过于复杂,不仅提升了数据收集和构建的成本,也损害了对话机器人在算法上的可维护性和在领域上的可迁移性。用户期待一个高质量的对话系统,既能反映多样化的个性喜好,又能联系到具体的业务和目标上,分别对应tod与chitchat两类模型。传统的对话系统在设计上并不具备这样的通用性。
7.现有的实现通用功能的工业界系统,大多是各部件无关的,通过独立地训练具有不同功能的对话模型组,然后额外学习一个文本分类器,来决策每一个回合将某一个模型
呈递给用户侧作交互。这些对话模型在所使用语料的数据结构、网络的设计、模型参数的训练,都是完全独立的,这意味着异质的对话数据集在异构的网络结构上分别训练,没有一个参数共享机制来学习语料间内在的语义特征与知识;而且模型参数量级非常大,不够轻量和方便迁移学习。
技术实现要素:
8.本发明基于上述考虑,提出了一种意图泛化的可控制通用对话模型,基于一个共享的语义信息编码器,可以同时支持闲聊和任务型对话等异构对话任务,而不需要对意图分类进行监督,整体摒弃了传统的数据标注方式,大幅降低了模型参数与监督学习的难度,可以轻松地实现领域与任务的迁移,并且降低了模型训练与维护的成本。
9.所述的可控制通用对话模型,包括编码-解码结构,外接数据库以及对文本风格进行控制的改写器;
10.编码-解码结构包括对话编码器、用于识别用户意图的解码器和产生系统回复的解码器;用于识别用户意图的解码器在查询外接数据库之前工作,称为nlu解码器;产生系统回复的解码器在查询外接数据库之后工作,称为nlg解码器。
11.针对用户的实际对话回合,首先,对话编码器读取对话历史、上轮对话状态和本轮用户输入,进行编码和特征提取,得到隐藏状态,经预处理后输出给nlu解码器和nlg解码器;
12.nlu解码器生成反映了用户意图的序列片段,并根据用户意图映射成数据库的查库语句,通过查询外接数据库,返回匹配结果db status;nlg解码器根据匹配结果db status生成自然语言形式的回复语句,最终反馈给用户。
13.所述nlu解码器在多个维度上平行地生成反映了用户意图的序列片段,其中提供信息informed message和询问信息requested message是必备的基本维度,因此,nlu解码器的意图分解维度应大于等于2。
14.所述外接数据库sql query,使用提供信息informed message来更新上轮对话状态,得到本轮的对话状态;对话状态被表达成一组槽值对,含有3层含义:1、对目前任务的完成进度的度量;2、对用户意图的追踪;3、对数据库query的约束条件。同时,询问信息requested message表示本轮查库时用户所关心的目标属性;将提供信息informed message和询问信息requested message组合起来,以确定性的方式映射为sql语句,得到匹配结果。
15.所述nlg解码器功能是生成无风格的系统回复;根据可控制的标识了策略类型的动作标识符act flag,作为解码句子的起始单词,生成一个非词化delexicalized形式的粗略回复skeleton;
16.所述改写器为即插即用型,通过指定的文本风格类型对回复进行转译,使得语言更生动多样。首先,粗略回复skeleton通过填入对话状态belief state和数据库查询结果db search results中的信息,将自身词汇化为一个人类可读的回复,记为raw response;随后,通过指定的文本风格类型,将raw response“转译”为最终回复final response。
17.本发明的优点在于:
18.1、一种意图泛化的可控制通用对话模型,为端到端的通用对话模型,同时支持包
括闲聊型与任务型等多个异构下游对话任务;
19.2、一种意图泛化的可控制通用对话模型,上下文编码器共享知识,学习通用语义特征,对语境的建模能力更强。
20.3、一种意图泛化的可控制通用对话模型,同构的下游解码模块,实现了复合任务交互,在通用性上具有显著优势。
21.4、一种意图泛化的可控制通用对话模型,着眼于混合任务的复杂性以及输入的不可预期性,提出了新的问题建模方案,打通不同垂直领域间的壁垒。
22.5、一种意图泛化的可控制通用对话模型,面向复杂多变、不可预期的对话需求,提升模型的鲁棒性和可扩展性。
23.6、一种意图泛化的可控制通用对话模型,减少参数优化所需的监督信息,算法复杂度低,降低了维护成本与扩展成本,预测效率更高。
附图说明
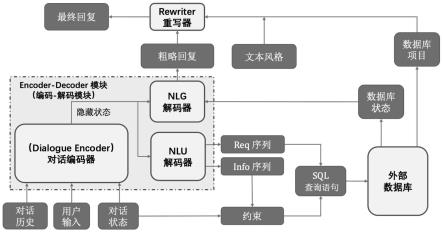
24.图1是本发明意图泛化的可控制通用对话模型的示意图;
25.图2是本发明nlu解码器中的soft-gated copy机制示意图;
26.图3是本发明可控制的动作标识符供用户选择的实施例;
27.图4是本发明改写网络期望rewriter达成的效果实例图。
具体实施方式
28.下面将结合附图和实施例对本发明作进一步的详细说明。
29.现有技术中根据是否涉及对知识库的查询,可以将某回合的人机交互分为查库型和非查库型两类。查库型的特点是在用户输入话语到系统产生回复的过程中,插入查库过程,并匹配出符合任务需求的实体表,基于匹配结果来生成回复。非查库型的主要形式则为闲聊型对话,在理解了用户输入后可以直接生成回复,不需要查询数据库,更加侧重于一个与人类情感的关联。
30.本技术将非查库型对话看作查库型对话的一种特殊情况,从而把两者统一起来,设计一个支持多轮的通用对话框架。假定第t轮的对话历史(dialogue history)为h
t
,对话状态(belief state)为b
t
。则每一个回合,对话模型的解码模块在查库之前与查库之后,需要依次执行两个子任务:用户意图识别和对话回复生成。其中,对话回复生成可以进一步嵌入一个风格改写(rewrite)的任务,以实现将无风格的系统回复转化为具有预定义的某几类风格的回复。
31.总体而言,本发明的通用对话框架包含三个任务,它们的输入输出对象以及依赖的外部资源如下表所示:
[0032][0033]
本发明所述意图泛化的可控制通用对话模型,如图1所示,包括对话编码器(dialogue encoder)、用于识别用户意图的解码器(nlu decoder)、外接数据库(external database)、产生系统回复的解码器(nlg decoder)以及对文本风格进行控制的改写器(controlled rewriter)。
[0034]
对话编码器、用于识别用户意图的解码器和产生系统回复的解码器共同组成编码-解码(encoder-decoder)结构;
[0035]
用于识别用户意图的解码器在查询数据库前工作一次,将查库前的过程记为自然语言理解(nlu);产生系统回复的解码器在查询数据库后工作一次,将查库后的过程记为自然语言生成(nlg)。
[0036]
意图泛化的通用对话模型的工作过程为:
[0037]
针对用户的实际对话回合,首先,对话编码器(dialogue encoder)读取对话历史c
t
、上轮对话状态b
t-1
和本轮用户输入u
t
,进行编码和特征提取,得到隐藏状态h
t
,并将隐藏状态经过处理后,输出给用于识别用户意图的解码器和产生系统回复的解码器。
[0038]
用于识别用户意图的解码器(nlu decoder)生成反映了用户意图的序列片段,并根据用户意图映射成数据库的查库语句,通过查询外接数据库,返回匹配结果db status;用于产生系统回复的解码器(nlg decoder)根据匹配结果db status生成自然语言形式的回复语句,最终反馈给用户。
[0039]
所述nlu解码器在多个维度上平行地生成反映了用户意图的序列片段,根据模型所期望所能够处理的业务的复杂度,用户意图根据特定的方案,分解成若干个相互平行的维度,例如提供信息(informed message)、询问信息(requested message)、办理预订信息(booked message)、后台编辑信息(edited message)等。其中提供信息(informed message)和询问信息(requested message)是必备的基本维度,因此,nlu解码器的意图分解维度应大于等于2。
[0040]
如针对risawoz数据集,意图维度分解为用户提供的信息(informed message,简记inf
t
)与询问的信息(requested message,简记req
t
)两个角度;解码时,通过控制gru隐藏单元的初始输入(initial input),decoder对两个角度的信息平行地预测;使用同一网络的目的是增强复合维度的意图相互间的知识共享。
[0041]
在本实例中,nlu decoder利用了soft-copy机制加强的gru-based decoder,把message视作槽值对(slot-value pairs)的序列化形式,使用生成式方法(generative approach)来产生序列。两个message的生成共享相同的网络参数,功能则由所使用的起始触发词(《inf》还是《req》)来区分,从而有助于两个生成任务的联合学习。
[0042]
inf
t
=nludecoder(h
t
,《inf》)
[0043]
req
t
=nludecoder(h
t
,《req》)
[0044]
如果req
t
与inf
t
均为空,表示用户在本轮对话中与数据库没有任何交互,在nlg阶段,系统将以闲聊(chichat)的形式予以回复;如图2所示,为nlu解码器中的soft-gated copy机制;
[0045]
soft-gated copy机制(软门限复制机制)加强的gru-based decoder,别名pointer-generator(指针生成网络),是最早在机器翻译领域提出的解码模型。它可以在解码的每一个time step,使得解码器能够选择是从对话上下文中复制token,还是由生成器由词表生成一个token,从而有助于准确地复制上下文内出现的信息,同时保留通过生成器产生新单词的能力。软门限复制机制的优势是所需的监督更少,提高了灵活性。
[0046][0047]
在解码的第k个time step,gru的隐藏状态以为初始输入迭代更新,直到生成了终止符[eos]结束。
[0048][0049][0050][0051][0052]
具体地,分别计算gru的隐藏状态在h
t
与e上的分布。h
t
是bert encoder编码后的隐藏状态矩阵,e是bert encoder的词嵌入矩阵。两个分布加权求和作为最终的分布来生成the next word。通过合并两个源,decoder可以生成未显式地出现在对话上下文内的词。
[0053][0054][0055][0056]
nlu阶段生成过程的损失函数是在给定三个输入的情况下,最小化inf
t
与req
t
的负对数似然分数(negative log-likelihood):
[0057]
l1=-logp(inf
t
|c
t-1
,u
t
,b
t-1
)
[0058]
l2=-logp(req
t
|c
t-1
,u
t
,b
t-1
)
[0059]
所述外接数据库sql query,使用提供信息info msg来更新上轮对话状态last belief state,得到本轮的对话状态;对话状态被表达成一组槽值对,含有3层含义:1、对目前任务的完成进度的度量;2、对用户意图的追踪;3、对数据库query的约束条件。同时,询问信息req msg表示本轮查库时用户所关心的目标属性;将提供信息info msg和询问信息req msg组合起来,以确定性的方式映射为sql语句,得到匹配结果。特别地,如果用户输入为闲聊型话语,则系统匹配结果用一种特别情况表示。
[0060]
匹配结果分为两部分:匹配实体表(db items)和匹配状态(db status)。匹配实体表是指当前领域内满足条件的所有具体实体的集合,只决定response内可能出现的槽值信
息,而与系统的策略无关;匹配状态则是匹配结果的抽象化,直接影响系统选取什么策略来进行交互。
[0061]
在本实例中,查询数据库的过程,用如下的确定性映射表示:
[0062]bt
=f(b
t-1
,inf
t
)
[0063]
sql
t
=γ(b
t
,req
t
)
[0064]
db
t
=database(sql
t
)
[0065]
上式中,inf
t
用于对last belief stateb
t-1
进行修改,以确定性的函数(deterministic function)f。更新了的b
t
就是查询数据库时的约束条件(constraint)。req
t
是查库时的库名及目标字段名,也是用户所关心的领域和槽位名称。γ代表基于约束条件与目标字段名构建的sql语句。匹配到的实体结果记为db
t
,info msg作为新增信息对last belief state作更新,得到的current belief state作为查库的约束条件(constraint),req msg作为查库的目标字段名,以确定性的方式映射为sql语句,访问外部数据库后,查库结果用具体的项目表(db items)和抽象的“匹配状态”(db status)表示。
[0066]
所述nlg decoder功能是生成无风格的系统回复;根据可控制的标识了策略类型的动作标识符(act flag),作为解码句子的起始单词,生成一个非词化(delexicalized)形式的粗略回复skeleton;skeleton通过填入belief state和db search results中的信息,将delexicalized response词汇化(lexicalized)为一个人类可读的回复。
[0067]
考虑到实际交互场景中回复策略的多样性,动作标识符是可控制的,如图3所示,可以在同一对话上下文(用户寻找餐厅)的条件下反馈不同的策略,通过标识符进行控制:推荐实体,要求用户添加条件或提供若干个条件供用户选择,提高用户的参与感和交互兴趣。
[0068]
本实例根据匹配到实体数量与用户所关心的槽位类型,首先将db
t
分类为基本策略动作a
t
。基础动作是指由对话状态(belief state)和用户意图(user goal)通过数据库匹配后,反应了系统最核心的回复略。基于动作,从可学习的词表矩阵里访问(look up)一个embedding然后将它作为decoder的起始触发词(starting token),生成系统的delexicalized response(非词汇的回复,即skeletion)
[0069]
skeleton是指由占位符代替了具体项目值的回复模板,在本算法中,占位符用special token[value_]包裹槽位名(slot name)构成,通过结合查库结果填词化(lexicalize)为raw response。lexicalize是一个rule-based的槽值替换过程,例如“给您推荐[value_名称]。”,填词后的结果就是“给您推荐周庄古镇”。所谓的raw response,是指剔除了一切与文风相关的特点,仅蕴含了需要反馈给用户的所有核心关键信息的句子。下一步,可以使用改写器(rewriter)将raw response转化为最终回复(final response)。
[0070][0071]
在本实例中,nlg decoder是一个attention机制增强的解码器,在每一步计算encoder隐藏状态h
t
,直到生成[eos]结束符号为止。
[0072][0073]
[0074][0075][0076][0077][0078]
nlg阶段生成过程的损失函数是在给定三个输入的情况下,最小化的负对数似然分数(negative log-likelihood):
[0079]
l3=-logp(r
rawt
|c
t-1
,u
t
,b
t-1
)
[0080]
encoder-decoder的最终损失函数是上述三个解码任务的loss的加权和。
[0081]
l
ed
=αl1+βl2+γl3[0082]
所述改写器为即插即用型,与编码-解码模块在训练与部署阶段都相互独立的生成网络。考虑到实际交互场景中回复策略的多样性,通过指定的文本风格类型对回复进行转译,使得语言更生动多样,提高用户的参与感和交互兴趣。此外,为了保证rewriter的转译功能不影响encoder-decoder部分预测的效果,这两个模块使用不同的训练集独立训练。
[0083]
首先,skeleton通过填入belief state和db search results中的信息,词汇化(lexicalized)为一个人类可读的回复,记为raw response。随后,通过指定的文本风格类型,将raw response“转译”为最终回复final response。final response相比于raw response,与上下文联系共紧密、语言更生动多样、风格更可控。
[0084]
改写网络是通过个性化构建语料微调后的gpt2语言模型,期望rewriter达成如图4所示的效果。skeleton在填充了来自匹配结果的具体的景点名称“同里古镇”后,根据风格类型,可以转译为语义相同而风格不同的新句子。
[0085]
所述编码-解码结构中,编码器为预训练中文bert语言模型,框架输入是对话上下文(dialogue comtext)c
t-1
、上轮对话状态(last belief state)b
t-1
和本轮用户输入(user input)u
t
三者的拼接序列。所有子序列通过分隔符[sep]拼接。[cls]是bert编码方法中prepend到每一个句子开头的特殊token,其对应的嵌入向量记为通过一个池化层映射为代表句子特征的句向量
[0086][0087]ht
=encoder(x
t
)
[0088][0089][0090]
其中h
t
是经过编码和特征提取后的encoder的隐藏状态,i是输入序列长度。
[0091]
本发明扩展了bert预训练模型的词嵌入(token embedding)层,增加了一些特殊的token,在编码与解码时从扩展后的词嵌入层访问到对应token的embedding。这些特殊token包括6种基本系统动作《chitchat》,《inform》,《return_one》,《return_multi》,《
return_zero》,《not_return》;两个nlu触发词《inf》,《req》;一个nlg生成阶段的占位符《value_》,以及一个表征句子终止的符号[eos]。
[0092]
本实施例中改写器是一个文本生成网络,将raw response“转译”为最终回复final response。final response相比于raw response,与上下文联系共紧密、语言更生动多样、风格更可控。在本文中,rewriter是通过个性化构建语料微调后的gpt2语言模型实现的,。rewriter以本轮用户输入u
t
及raw response共同作prompt,以表征文本风格的control codeyj作为分隔符,以自回归的方式生成final response。
[0093][0094]
对于序列长度为l的训练样本,损失函数为自回归的交叉熵损失,其中b
<k
表示k之前的所有token。
[0095]
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1