一种基于机器视觉注意力机制的静态手势识别方法与流程
1.本发明属于汽车座舱交互技术领域,特别涉及一种基于机器视觉注意力机制的静态手势识别方法。
背景技术:
2.近年来,随着计算机视觉和机器学习等相关科学的发展,人机交互技术也日趋成熟,在各个领域均有应用,特别地,在汽车智能座舱交互领域应用广泛。传统的座舱交互方式都是基于物理按键,慢慢发展到车机端的触屏操控,再后来发展到语音和手势交互控制,其中,手势识别因其自然且符合用户操控逻辑,能给用户带来无感交互体验的优势,能够很好的弥补语音操控不便和尴尬的缺点,使得交互方式愈发便捷和智能。因此,提高手势识别率,准确判断出用户手势意图,对提高用户智能操控体验尤为重要。
3.得益于计算机视觉和机器学习,特别是深度学习中卷积神经网络等相关科学的快速发展,手势识别领域研究成果较为成熟,运用在智能家居、智能娱乐等设备的场景中现已常见,在汽车智能座舱领域,基于手势识别的交互技术也得到较早应用。但因为各种端侧设备的性能不像服务器端那样强悍,计算力非常有限,导致手势识别的准确率还是相对较低。
4.中国专利201711102008.9公开了一种基于计算机视觉的动态手势识别方法,该专利提出一种端到端的动态手势识别方法,采集手势图像后,对人工标注的真实数据框进行聚类,以改进后的googlenet网络作为网络框架,构建端到端的可同时预测目标手势的位置、大小及类别的卷积神经网络并进行训练,此种方法将手部检测和分类放在一个网络里进行预测,从而减少计算开销达到端侧设备算力要求,但因为实际运用场景往往非常复杂,手势复杂度较高、环境干扰较强(如光线变换、人为干扰、遮挡等)等原因,导致识别率不高。
5.中国专利202110186152.5公开了一种基于kinect传感器静态手势识别方法,该方法提出利用kinect传感器获得静态手势深度图像信息,用深度中值滤波将手部深度图像进行预处理,并采用灰度直方图算法进行手势分割得到手部区域图像,然后对分割得到的手部区域图像提取hog特征,计算hog特征与标准模板的加权欧式距离进行分类识别。此方法依赖额外的手势识别传感器,增加成本,消费者接受意愿不强,很难商用。再者单纯通过与标准模板的距离计算进行分类识别,应对不了实际使用时车内的复杂场景,造成误识别和漏识别,影响用户体验。
技术实现要素:
6.针对现有技术存在的上述不足,本发明的目的就在于提供一种基于机器视觉注意力机制的静态手势识别方法,该方法不额外增加硬件,能大大节省计算开销和提高手势识别率,降低误识率,从而提升用户座舱手势操控功能体验。
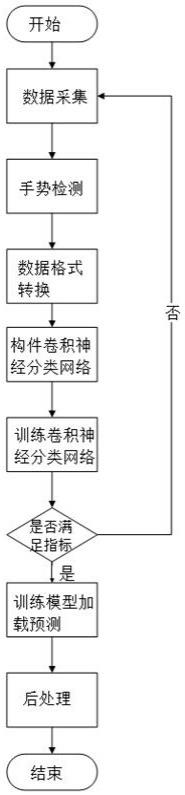
7.本发明的技术方案是这样实现的:一种基于机器视觉注意力机制的静态手势识别方法,具体包括以下步骤:(1)采用rgb摄像头采集多类别的静态手势图像;
(2)将静态手势图像中手势区域检测出来后进行裁剪得到手势图片,再进行保存,并将所有类别的手势图片划分成训练集、验证集和测试集;(3)将步骤(2)得到的手势图片由rgb格式转成yuv格式,使得训练集、验证集和测试集中的手势图片均为yuv格式;(4)以mobilenetv2网络作为网络框架,并加入注意力机制模块,并以类别分类损失函数构建卷积神经分类网络;(5)将步骤(3)的训练集输入卷积神经分类网络中进行多次网络训练,每训练完一个epoch,就采用步骤(3)的验证集进行测试,保留准确率最高的那个权重,待训练完成后得到训练模型,用步骤(3)的测试集进行测试,若满足设定指标,则进入步骤(7),否则进入步骤(6);(6)重新采集未覆盖的场景和错误分类手势对应的静态手势图像,重复步骤(2)和步骤(3)添加到训练集中进行持续迭代训练,对应地,不断更新训练模型;(7)将步骤(5)或步骤(6)中的训练模型加载到步骤(4)卷积神经分类网络中,直接采用rgb摄像头实时采集静态手势图像,并将静态手势图像中手势区域检测出来后进行裁剪得到手势图片,然后输入训练模型中进行识别,得到每个类别的概率分数,概率分数最高对应的那个类别即为识别到的手势类别。
8.进一步地,步骤(1)中至少包括四个类别,其中一类别为干扰静态手势,剩余类别包括但不限于点赞、比心、胜利、剪刀、石头和布中的任意三种或多种静态手势。
9.更进一步地,步骤(1)中采集不同光照、不同角度场景下的静态手势图像。
10.进一步地,步骤(2)和步骤(6)中先将静态手势图像中的手势区域向外扩大后再进行裁剪,以得到手势图片。
11.更进一步地,所述手势图片左上角的坐标为(x1',y1'),右下角的坐标为(x2',y2'),外扩方法为:x1'=max(0,x
1-(x
2-x1)*0.1);y1'=max(0,y
1-(y
2-y1)*0.1)x2'=min(w,x
2-(x
2-x1)*0.1);y2'=min(h,y2+(y
2-y1)*0.1)其中:w和h分别为手势图片的分辨率的宽和高;x1和y1分别为手势区域左上角对应的横坐标和纵坐标;x2和y2分别为手势区域右下角对应的横坐标和纵坐标。
12.进一步地,rgb图片格式转换成yuv图片格式的方法为:y=0.257*r+0.504*g+0.098*b+16u=-0.148*r-0.291*g+0.439*b+28v=0.439*r-0.368*g-0.071*b+128其中:r,g,b分别为rgb图片对应通道的像素值;y,u,v分别为yuv格式图片对应通道的像素值。
13.进一步地,步骤(5)中训练集输入卷积神经网络中进行网络训练前,随机调整手势图片的亮度、对比度或色度,以提高训练模型的鲁棒性。
14.进一步地,还包括步骤(8),结合用户实际手势操控习惯,规定车内手势操控区域,提高识别准确率。
15.更进一步地,对步骤(7)得到的概率分数做中值滤波处理,若概率分数大于设定阈
值,则认为是有效事件。
16.与现有技术相比,本发明具有如下有益效果:1、本发明采用rgb摄像头采集静态手势图像,可以有效硬件成本,且在使用过程中采集的yuv格式图像可直接输入训练模型中进行识别,可以降低计算量。
17.2、虽然mobilenetv2网络中的精度有略微损失,但是可以有效减少8~9倍计算量,而注意力机制模块通过水平与垂直方向的注意力图的捕获特征的远程依赖关系,可以获得更加精确的位置信息,大大加强输入特征的表达能力,所以本发明将注意力机制模块加入mobilenetv2网络后,在只增加少量计算量的情况下,大大提高卷积神经分类网络的分类准确率,从而保证在深度卷积神经网络中的精度和性能取得最佳平衡,提高手势识别准确率。
附图说明
18.图1-本发明的流程图。
19.图2-注意力机制模块的结构示意图。
20.图3-注意力机制模块加入mobilenetv2网络的结构示意图。
具体实施方式
21.下面结合附图和具体实施方式对本发明作进一步详细说明。
22.一种基于机器视觉注意力机制的静态手势识别方法,其流程图如图1所示,具体包括以下步骤:(1)数据采集:采用rgb摄像头采集多类别的静态手势图像;(2)手势区域检测:将静态手势图像中手势区域检测出来后进行裁剪得到手势图片,再进行保存,并将将所有类别的手势图片划分成训练集、验证集和测试集;(3)数据格式转换:将步骤(2)得到的手势图片由rgb格式转成yuv格式,使得训练集、验证集和测试集中的手势图片均为yuv格式;(4)构建卷积神经分类网络:以mobilenetv2网络作为网络框架,并加入注意力机制模块,并以类别分类损失函数构建卷积神经分类网络;(5)训练卷积神经分类网络:将步骤(3)的训练集输入卷积神经分类网络中进行多次网络训练,每训练完一个epoch,就采用步骤(3)的验证集进行测试,保留准确率最高的那个权重,待训练完成后得到训练模型,用步骤(3)的测试集进行测试,若满足设定指标,则进入步骤(7),否则进入步骤(6);(6)重新采集未覆盖的场景和错误分类手势对应的静态手势图像,重复步骤(2)和步骤(3)添加到训练集中进行持续迭代训练,对应地,不断更新训练模型;(7)训练模型加载预测:将步骤(5)或步骤(6)中的训练模型加载到步骤(4)卷积神经分类网络中,直接采用rgb摄像头实时采集静态手势图像,并将静态手势图像中手势区域检测出来后进行裁剪得到手势图片,然后输入训练模型中进行识别,得到每个类别的概率分数,概率分数最高对应的那个类别即为识别到的手势类别。
23.基于倒置残差结构的mobilenetv2网络,通过将标准卷积拆分为两个分卷积,可以使得计算量减少8~9倍,而精度有略微损失。注意力机制模块通过水平与垂直方向的注意力图的捕获特征的远程依赖关系,可以获得更加精确的位置信息,大大加强输入特征的表达
能力,注意力机制模块的结构示意图如图2所示,图中c为feture map的通道数channel,h和w为feature map的高和宽,r为一个超参数,c/r即为channel的缩放倍数,1代表feature map的某一维度大小为1。注意力机制模块加入mobilenetv2网络后,在只增加少量计算量的情况下,大大提高卷积神经分类网络的分类准确率,从而保证在深度卷积神经网络中的精度和性能取得最佳平衡,注意力机制模块加入mobilenetv2网络得到的结构示意图如图3所示,图中1
×
1和3
×
3代表卷积核的大小。
24.同时,采用rgb摄像头采集静态手势图像,常规车内都安装有rgb摄像头,不需要添加硬件,可以节约成本,即使要添加,rgb摄像头的成本便宜,也可以在一定程度上降低成本。同时rgb摄像头采集的图像为yuv格式,在实车应用过程中,不需数据格式转换,就可以输入训练模型中进行识别,从而可以进一步减少计算量,即节约训练模型部署后前向推理时将摄像头视频数据转为rgb格式的计算开销。
25.这里的设定指标根据实际需要进行设定,具体可以是识别准确率,一般地识别准确率大于等于0.9,大于设定指标即为满足设定指标。
26.具体实施时,步骤(1)中至少包括四个类别,其中一类别为干扰静态手势,剩余类别包括但不限于点赞、比心、胜利、剪刀、石头和布中的任意三种或多种静态手势。
27.具体实施时,步骤(1)中采集不同光照、不同角度场景下的静态手势图像。这样可以有效提高数据采集的丰富性,从而提高训练模型的鲁棒性。
28.具体实施时,步骤(2)和步骤(6)中先将静态手势图像中的手势区域向外扩大后再进行裁剪,以得到手势图片。
29.这样可以有效降低因手势检测对分类准确率的影响。
30.具体实施时,所述手势图片左上角的坐标为(x1',y1'),右下角的坐标为(x2',y2'),外扩方法为:x1'=max(0,x
1-(x
2-x1)*0.1);y1'=max(0,y
1-(y
2-y1)*0.1)x2'=min(w,x
2-(x
2-x1)*0.1);y2'=min(h,y2+(y
2-y1)*0.1)其中:w和h分别为手势图片的分辨率的宽和高;x1和y1分别为手势区域左上角对应的横坐标和纵坐标;x2和y2分别为手势区域右下角对应的横坐标和纵坐标。
31.这样,手势图片的框向外最大扩大0.1倍,最小与静态手势图像的外框重合,即无法向外扩。
32.具体实施时,rgb图片格式转换成yuv图片格式的方法为:y=0.257*r+0.504*g+0.098*b+16u=-0.148*r-0.291*g+0.439*b+28v=0.439*r-0.368*g-0.071*b+128其中:r,g,b分别为rgb图片对应通道的像素值;y,u,v分别为yuv格式图片对应通道的像素值。
33.具体实施时,步骤(5)中训练集输入卷积神经网络中进行网络训练前,随机调整手势图片的亮度、对比度或色度,以提高训练模型的鲁棒性。
34.为加快网络收敛,提升训练速度,通常采用批训练方式。批大小(batchsize)设置为256,每个batch输入网络训练前,进行数据增强,增强方式为在一定范围内随机调整手势
图片亮度、对比度、色度等,提高模型的鲁棒性。
35.具体实施时,还包括步骤(8)后处理,结合用户实际手势操控习惯,规定车内手势操控区域,提高识别准确率。
36.一般地,车内手势操控区域限制在前后排居中区域,从而降低其他区域的误识别问题。
37.具体实施时,后处理还包括对步骤(7)得到的概率分数做中值滤波处理,若概率分数大于设定阈值,则认为是有效事件。
38.这里的阈值可参数化,并可经过实验调整至合适值,使得手势识别更加准确。
39.最后需要说明的是,本发明的上述实施例仅是为说明本发明所作的举例,而并非是对本发明实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其他不同形式的变化和变动。这里无法对所有的实施方式予以穷举。凡是属于本发明的技术方案所引申出的显而易见的变化或变动仍处于本发明的保护范围之列。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1