一种树序列化嵌入的软件代码推荐方法
1.本发明属于信息检索技术领域,具体涉及一种树序列化嵌入的软件代码推荐方法,根据开发过程中的功能需求进行代码推荐。
背景技术:
2.面对it发展的黄金时期,越来越多的专业或非专业人员加入到开发行列中。在开发人员开发软件时,一些功能需求或者任务要求可能涉及开发人员此前没有接触过的编程方式或者领域。现有的搜索引擎,大多是根据自然语言的关键字匹配来寻找答案的,这样的搜索方式显然并不能够反应代码的语义和结构信息,也就难以找到真正符合功能需求的目标代码。这造成了开发人员需要浪费很多时间,浏览大量无用信息。
3.技术知识和开发经验的不足,使得软件的开发效率难以提升。互联网行业迎来裁员浪潮。为了降低开发门槛,提高开发效率,无代码开发和低代码开发成为人们关注的下一个焦点。无代码开发的一种体现形式就是利用自然语言的描述来实现开发过程。
4.为了响应无代码开发的时代需求,为了提高开发人员的编程效率,提出了根据开发需求自动生成代码段的代码推荐方法。
技术实现要素:
5.本发明要解决的技术问题是提供一种树序列化嵌入的软件代码推荐方法,通过直接描述功能需求的形式得到对应代码,有效节省开发时间,提高开发效率。
6.为解决上述技术问题,本发明的实施例提供一种树序列化嵌入的软件代码推荐方法,包括如下步骤:
7.s1、通过解析抽象语法树ast分别将向量化的代码和注释嵌入到向量空间中并计算相似度,建立tcdenn模型;
8.s2、收集java代码,通过ast节点提取进行预处理构建训练集和测试集,用来训练和测试tcdenn模型;
9.s3、收集高质量的java代码,建立代码搜索库,开发人员输入描述查询代码搜素库,对搜索代码库中的ast向量与功能描述向量计算相似度,将相似度值最高的k个代码向量返回给开发人员。
10.其中,步骤s1中的tcdenn模型包括三部分:ast嵌入、自然语言嵌入和相似度计算,其中,
11.s1.1、ast嵌入:将java代码解析成ast,并遍历节点,将ast嵌入到向量空间中;
12.s1.2、自然语言嵌入:将代码注释中用自然语言描述的代码功能内容嵌入到向量空间中;
13.s1.3、相似度计算:组合使用余弦相似度和曼哈顿距离来计算ast向量和功能描述向量在表达语义上的相似性。
14.其中,步骤s1.1包括如下步骤:
15.s1.1.1、使用eclipse的jdt编译器将java代码解析成可视化的ast,提取代码和注释;
16.s1.1.2、通过观察ast结构特征,递归遍历ast节点,将ast转化成节点序列astseq,假设输入序列astseq={b1,b2,b3,
…
,bn},使用gru网络将astseq嵌入向量:
17.h
t
=g(h
t-1
,b
t
),t∈{1,2,...,n};
18.其中,g是gru网络,b
t
是apiseq的词嵌入向量,h
t
是隐藏层状态值,最终的隐藏层状态hn代表astseq的模态表示,n表示输入词个数;
19.步骤1.1.3、通过对astseq各隐藏层输出做加权平均运算弥补因为将astseq长序列作为gru的输入所造成的必要信息丢失的问题,权重α计算方法为:
20.α
t
=softmax(hn·ht
),t∈{1,2,...,n};
21.其中,hn是astseq的模态表示,h
t
是隐藏层状态值,α
t
是h
t
对应权重,最终得到ast的向量表示ast_repr:
[0022][0023]
进一步,步骤s1.1.2包括如下步骤:
[0024]
s1.1.2.1、将java代码解析成ast,观察节点特点;在ast中,终端节点具有类型和值的特点,而非终端结点只有类型特点。
[0025]
s1.1.2.2、终端结点可以表示成一个二元组《ta,va》,而非终端节点表示为《ta》;其中,ta表示ast节点类型,va表示ast节点值;
[0026]
s1.1.2.3、从根节点开始,用一对括号表示树形结构,把树的根节点表示在右括号后面,递归遍历每一个子树,直到遍历完所有结点,得到含括号的节点序列,将括号去掉,根据ast序列的词汇表将这些节结点转换成数字得到astseq,并嵌入向量。
[0027]
其中,步骤s1.2包括如下步骤:
[0028]
s1.2.1、使用pycharm编译器对步骤s1.1得到的注释做字符串处理,提取每条注释中第一个@符号之前的、且不包括行首符号*和/的功能描述内容;
[0029]
s1.2.2、将功能描述输入gru中并求加权平均值,得到功能描述的向量表示desc_repr。
[0030]
其中,步骤s1.3包括如下步骤:
[0031]
s1.3.1、在即考虑方向相似,又考虑大小相似的情况下,使用余弦相似度和曼哈顿距离组合计算向量ast_repr和desc_repr在向量空间上的距离:
[0032][0033]
其中,c表示向量ast_repr,d表示向量desc_repr,ci、di分别是向量c和d的一个分量,m表示c和d向量的维度;根据余弦相似度计算,余弦值的范围在[-1,1],余弦值越接近1,向量间越相似;将余弦相似度取负数再加一,余弦值范围在[0,2],余弦值越接近0,向量间越相似;根据曼哈顿距离越接近0越相似,所以它们的乘积越接近0,向量ast_repr和向量desc_repr越相似;
[0034]
s1.3.2、假设用一个三元组《co,td,fd》来表示训练过程中的每个训练实例,其中co表示代码片段向量,td表示正确的功能描述向量,fd表示错误的功能描述向量;
[0035]
《co,td》是训练集制作过程中得到的正例对,在训练过程中,用已有的功能描述向量集随机抽取一个向量得到fd,组织成负例对《co,fd》;
[0036]
训练过程中要让《co,td》和《co,fd》相似度差距超过一个阈值,使triplet loss最小化,可以表示为:
[0037][0038]
其中,β是模型参数,q是训练数据集,ε是阈值。
[0039]
进一步,步骤s1.3.2中,triplet loss计算包括如下三种情况:
[0040]
情况1:d(co,td)>d(co,fd)+ε,在这种情况下,《co,td》和《co,fd》相似度差距超过阈值,loss值等于0,网络参数不会再更新;
[0041]
情况2:d(co,td)<d(co,fd),在这种情况下,错误的功能描述向量比正确的描述向量更加接近代码片段向量,此时的loss值是一个大于ε的正数,网络可以继续更新:
[0042]
情况3:d(co,td)<d(co,fd)<d(co,td)+ε,在这种情况下,错误的功能描述向量比正确的描述向量更加接近代码片段向量,此时的loss值是一个小于ε的正数,网络可以继续更新。
[0043]
其中,步骤s2包括如下步骤:
[0044]
s2.1、使用github的高级索引功能,限制搜索条件,收集开源java项目代码;限制条件包括,语言为java,星标数大于等于1,年份在2011年到2020年之间。
[0045]
s2.2、提取开源项目中所有以java为后缀名的文件,以一个java方法为单位,收集代码片段;使用eclipse的jdt编译器将java代码解析成ast,根据ast上的每一个java方法结点的类型和方法注释结点值,提取出有注释的java方法,并划分数据的训练集和测试集。
[0046]
s2.3、制作ast序列词汇表,词汇表包含非终端节点《ta》和终端结点的二元组《ta,va》;保留出现频率最高的30000个ast序列词汇,对于不在词汇表内的终端节点,采用和非终端节点一样的表示方法,即使用节点类型《ta》表示。
[0047]
其中,步骤s3包括如下步骤:
[0048]
s3.1、从github上收集星标数大于50的java开源项目代码,使用eclipse的jdt编译器将java代码解析成ast,根据ast的方法结点的类型,提取java方法;对于方法体部分为空的java方法,不做提取;不需要java方法的注释。
[0049]
s3.2、将收集到的java方法代码片段,使用tcdenn模型的ast嵌入方法嵌入到向量空间中,得到代码搜索库;开发人员输入描述查询代码搜素库。
[0050]
s3.3、组合使用余弦相似度和曼哈顿距离计算代码搜素库中的ast向量与功能描述向量的相似度,将相似度值最高的k个代码向量返回给开发人员自主选择,k值任意确定。
[0051]
本发明的上述技术方案的有益效果如下:
[0052]
本发明提供一种树序列化嵌入的软件代码推荐方法tcdenn,通过直接描述功能需求的形式得到对应代码,有效节省开发时间,提高开发效率。
附图说明
[0053]
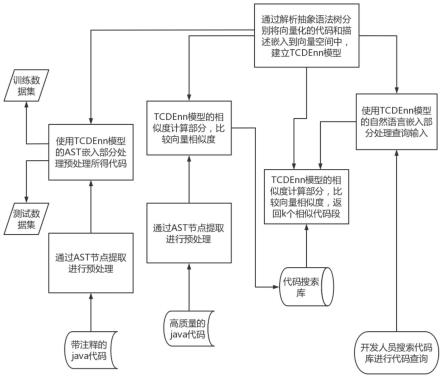
图1为本发明的流程图;
[0054]
图2为本发明中tcdenn模型总体框架图;
[0055]
图3为本发明中预处理的流程图;
[0056]
图4为本发明中代码片段举例图;
[0057]
图5为本发明中java代码解析成ast的结果图;
[0058]
图6为本发明中代码推荐结果图;
[0059]
图7为本发明中ast嵌入流程图;
[0060]
图8为本发明中自然语言嵌入流程图;
[0061]
图9为本发明中递归遍历ast案例图。
具体实施方式
[0062]
为使本发明要解决的技术问题、技术方案和优点更加清楚,下面将结合附图及具体实施例进行详细描述。
[0063]
本发明提供一种树序列化嵌入的软件代码推荐方法tcdenn,主要用于解决开发过程中出现的代码功能实现问题。
[0064]
如图1所示,一种树序列化嵌入的软件代码推荐方法tcdenn主要包含如下步骤:
[0065]
步骤1、通过解析抽象语法树ast分别将向量化的代码和注释嵌入到向量空间中并计算相似度,建立tcdenn模型;
[0066]
步骤2、收集java代码,通过ast节点提取进行预处理构建训练集和测试集,用来训练和测试tcdenn模型;
[0067]
步骤3、收集高质量的java代码,建立代码搜索库,开发人员输入描述查询代码搜素库,对搜索代码库中的ast向量与功能描述向量计算相似度。将相似度值最高的k个代码向量返回给开发人员。
[0068]
图2为tcdenn模型的结构图,主要包括三个部分,ast嵌入、自然语言嵌入和相似度计算,具体如下:
[0069]
步骤1.1、ast嵌入:将java代码解析成ast,并遍历节点,将ast嵌入到向量空间中;
[0070]
步骤1.2、自然语言嵌入:将代码注释中用自然语言描述的代码功能内容嵌入到向量空间中;
[0071]
步骤1.3、相似度计算:组合使用余弦相似度和曼哈顿距离来计算ast向量和功能描述向量在表达语义上的相似性。
[0072]
如图7所示,关于构建tcdenn模型ast嵌入部分的具体步骤如下:
[0073]
步骤1.1.1、使用eclipse的jdt编译器将java代码解析成可视化的ast(如图5所示),提取代码和注释。
[0074]
步骤1.1.2、通过观察ast结构特征,递归遍历ast节点(见图9),将ast转化成节点序列astseq。假设输入序列,astseq={b1,b2,b3,
…
,bn}。使用gru网络将astseq嵌入向量:
[0075]ht
=g(h
t-1
,b
t
),t∈{1,2,...,n};
[0076]
其中,g是gru网络,b
t
是apiseq的词嵌入向量,h
t
是隐藏层状态值,最终的隐藏层状态hn代表astseq的模态表示,n表示输入词个数。
[0077]
因为将astseq长序列作为gru网络的输入会造成必要信息丢失的问题。所以,步骤1.1.3需要对astseq各隐藏层输出做加权平均运算。权重α计算方法为:
[0078]
α
t
=softmax(hn·ht
),t∈{1,2,...,n};
[0079]
其中,hn是astseq的模态表示,h
t
是隐藏层状态值,α
t
是h
t
对应权重。最终得到ast的向量表示ast_repr:
[0080][0081]
进一步的,步骤1.1.2的具体步骤如下:
[0082]
步骤1.1.2.1、将java代码解析成ast,观察节点特点。如图5所示,在ast中,终端节点具有类型和值的特点,而非终端结点只有类型特点。
[0083]
步骤1.1.2.2、终端结点可以表示成一个二元组《ta,va》,而非终端节点表示为《ta》。其中,ta表示ast节点类型,va表示ast节点值。
[0084]
步骤1.1.2.3、从根节点开始,用一对括号表示树形结构,把树的根节点表示在右括号后面。递归遍历每一个子树,直到遍历完所有结点,得到含括号的节点序列。将括号去掉,根据ast序列的词汇表将这些节结点转换成数字得到astseq,并嵌入向量。
[0085]
如图8所示,关于构建tcdenn模型自然语言嵌入部分的具体步骤如下:
[0086]
步骤1.2.1、使用pycharm编译器对步骤1.1.1得到的注释做字符串处理,提取每条注释中第一个’@’符号之前的,且不包括行首符号’*’和’/’的功能描述内容。
[0087]
步骤1.2.2、将功能描述输入gru中并求加权平均值,得到功能描述的向量表示desc_repr。
[0088]
关于构建tcdenn模型相似度计算部分,做如下讨论。
[0089]
在一般的相似度计算中,余弦相似度只包含方向的相似性,对大小不敏感,而曼哈顿距离只包含大小的相似性,不论方向。因此,在既考虑方向相似性,又考虑大小相似性的情况下,使用余弦相似度和曼哈顿距离组合计算向量ast_repr和desc_repr在向量空间上的距离。具体步骤如下:
[0090]
步骤1.3.1、计算向量ast_repr和desc_repr在向量空间上的距离:
[0091][0092]
其中,c表示向量ast_repr,d表示向量desc_repr,ci、di分别是向量c和d的一个分量,m表示c和d向量的维度。
[0093]
根据余弦相似度计算,余弦值的范围在[-1,1],余弦值越接近1,向量间越相似。将余弦相似度取负数再加一,余弦值范围在[0,2],余弦值越接近0,向量间越相似。根据曼哈顿距离越接近0越相似,所以它们的乘积越接近0,向量ast_repr和向量desc_repr越相似。
[0094]
步骤1.3.2、假设用一个三元组《co,td,fd》来表示训练过程中的每个训练实例。其中co表示代码片段向量,td表示正确的功能描述向量,fd表示错误的功能描述向量。
[0095]
《co,td》是训练集制作过程中得到的正例对。在训练过程中,用已有的功能描述向量集随机抽取一个向量得到fd,组织成负例对《co,fd》。
[0096]
训练过程中要让要让《co,td》和《co,fd》相似度差距超过一个阈值,使triplet loss最小化,可以表示为:
[0097][0098]
其中,β是模型参数,q是训练数据集,ε是阈值。
[0099]
在上述相似度计算方法中,步骤1.3.2所述的triplet loss计算有三种情况:
[0100]
情况1、d(co,td)>d(co,fd)+ε。在这种情况下,《co,td》和《co,fd》相似度差距超过阈值,loss值等于0,网络参数不会再更新。
[0101]
情况2、d(co,td)<d(co,fd)。在这种情况下,错误的功能描述向量比正确的描述向量更加接近代码片段向量,此时的loss值是一个大于ε的正数,网络可以继续更新。
[0102]
情况3、d(co,td)<d(co,fd)<d(co,td)+ε。在这种情况下,错误的功能描述向量比正确的描述向量更加接近代码片段向量,此时的loss值是一个小于ε的正数,网络可以继续更新。
[0103]
下一步,如图3所示,步骤2具体步骤如下:
[0104]
步骤2.1、使用github的高级索引功能,限制搜索条件,收集开源java项目代码。限制条件包括,语言为java,星标数大于等于1,年份在2011年到2020年之间。
[0105]
步骤2.2、提取开源项目中所有以java为后缀名的文件,以一个java方法为单位,收集代码片段。使用eclipse的jdt编译器将java代码解析成ast,根据ast上的每一个java方法结点的类型和方法注释结点值,提取出有注释的java方法,并划分数据的训练集和测试集。
[0106]
步骤2.3、制作ast序列词汇表。词汇表包含非终端节点《ta》和终端结点的二元组《ta,va》。保留出现频率最高的30000个ast序列词汇,对于不在词汇表内的终端节点,采用和非终端节点一样的表示方法,即使用节点类型《ta》表示。
[0107]
最后,步骤3的具体步骤如下:
[0108]
步骤3.1、从github上收集星标数大于50的java开源项目代码,使用eclipse的jdt编译器将java代码解析成ast,根据ast的方法结点的类型,提取如图4所示java方法。对于方法体部分为空的java方法,不做提取。不需要java方法的注释。
[0109]
步骤3.2、将收集到的java方法代码片段,使用tcdenn模型的ast嵌入方法嵌入到向量空间中,得到代码搜索库。开发人员输入描述查询代码搜素库。
[0110]
步骤3.3、组合使用余弦相似度和曼哈顿距离计算代码搜素库中的ast向量与功能描述向量的相似度。将相似度值最高的k个代码向量返回给开发人员自主选择。k值任意确定。
[0111]
相似度计算也可以采用其他方法。搜索结果如图6所示。以余弦相似度为例。k值为6,一个括号为一条输出。小数部分为相似度计算结果。字符串为推荐的代码片段。
[0112]
本发明提供的一种树序列化嵌入的软件代码推荐方法tcdenn(tree-based code-description neural network),主要用于解决开发过程中出现的代码功能实现问题,可以通过直接描述功能需求的形式得到对应代码,有效节省开发时间,提高开发效率。
[0113]
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员
来说,在不脱离本发明所述原理的前提下,还可以作出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1