图结构的查询方法、装置及存储介质
图结构的查询方法、装置及存储介质
【技术领域】
1.本技术属于图结构领域,特别涉及一种图结构的查询方法、装置及存储介质。
背景技术:
2.图结构作为一种灵活的数据结构,能以简洁的形式表达现实世界复杂的实体关系,被广泛应用在各个领域,如金融平台通过点边关系描述用户之间转账交易等信息,网络服务商利用图结构抽象网络节点之间的连通关系。其中,图查询是指基于图数据分析提取特定的关联信息,主要包含点边查询、路径查询以及子图查询等,在图数据相关研究当中,如何高效的进行图查询一直是研究重点之一。
3.随着数据规模的膨胀,图数据边和节点数量不断庞大,导致大图数据查询效率低下。尤其是要处理多跳查询和子图查询等复杂查询命令时,查询需要从起点出发遍历邻居节点,之后依次遍历邻居节点的邻居节点,这种层次扩展的查询代价十分昂贵。再者,真实世界抽象的图数据中,节点的邻居个数远远小于节点总数,也可以说节点和图上其他节点大概率是没有边连接。
4.因此,查询过程中的中间结果大多数都是无关结果,如社交网络中查询任意两人的共同好友,最终得到的结果远远要小于整体好友数量的,这种无用的查询代价增加了图查询的复杂程度。
技术实现要素:
5.本技术提供一种图结构的查询方法、装置及存储介质,可以减少图结构查询的耗时。
6.本技术第一方面提供了一种图结构的查询方法,包括:
7.获取针对图结构的输入查询集合,所述输入查询集合中包括至少一个输入查询边;
8.从图结构编码数据库中查询目标查询边所对应的第一顶点和第二顶点的编码,所述图结构编码数据库中包括所述目标查询边的两个顶点在内的多个顶点所对应的编码,所述目标查询边为所述输入查询集合中的任意一个查询边,所述多个顶点中每个顶点的编码类型为直接编码或组合编码;
9.根据所述第一顶点的编码和所述第二顶点的编码确定所述第一顶点的编码类型以及所述第二顶点的编码类型;
10.根据所述第一顶点的编码类型和第二顶点的编码类型确定所述目标查询边的查询结果。
11.本技术第二方面提供了一种图结构查询装置,包括:
12.获取单元,用于获取针对图结构的输入查询集合,所述输入查询集合中包括至少一个输入查询边;
13.查询装置,用于从图结构编码数据库中查询目标查询边所对应的第一顶点和第二
顶点的编码,所述图结构编码数据库中包括所述目标查询边的两个顶点在内的多个顶点所对应的编码,所述目标查询边为所述输入查询集合中的任意一个查询边,所述多个顶点中每个顶点的编码类型为直接编码或组合编码;
14.第一确定单元,用于根据所述第一顶点的编码和所述第二顶点的编码确定所述第一顶点的编码类型以及所述第二顶点的编码类型;
15.第二确定单元,用于根据所述第一顶点的编码类型和第二顶点的编码类型确定所述目标查询边的查询结果。
16.本技术实施例第三方面提供了一种计算机设备,其包括至少一个连接的处理器、存储器和收发器,其中,所述存储器用于存储程序代码,所述处理器用于调用所述存储器中的程序代码来执行上述第一方面所述的图结构的查询方法的步骤。
17.本技术实施例第四方面提供了一种计算机存储介质,其包括指令,当其在计算机上运行时,使得计算机执行上述任一方面所述的图结构的查询方法的步骤。
18.相对于相关技术,本技术提供的实施例中,通过将图数据通过直接编码和组合编码的方式进行预先编码,并将编码后的图结构编码存储至图结构编码数据库中,这样在输入查询边时可以确定查询边的两个顶点的编码类型,并根据编码类型进行查询,从而在确保查询结果正确的前提下兼顾时间和空间效率,可以减少图结构查询的耗时。
【附图说明】
19.图1为本技术实施例提供的图结构的查询方法的流程示意图;
20.图2为本技术实施例提供的图结构查询装置的虚拟结构示意图;
21.图3为本技术实施例提供的直接编码的编码组成示意图;
22.图4为本技术实施例提供的组合编码的编码组成示意图;
23.图5为本技术实施例提供的图结构查询装置的虚拟结构示意图;
24.图6为本技术实施例提供的服务器的硬件结构示意图。
【具体实施方式】
25.下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本技术一部分实施例,而不是全部的实施例。
26.本发明旨在提供一种图结构的查询方法及相关设备,通过高效的低维度图编码算法对图数据进行预先编码,在查询时通过解码过滤掉查询集中的无边结果,从而在确保查询结果正确的前提下兼顾时间和空间效率,达到大幅度加速图查询的目的。
27.为实现上述目的,本技术所采用的技术方案包含三大模块:离线编码模块、在线查询模块以及在线更新模块。
28.离线编码模块通过预加载图数据集和配置信息,利用图编码算法对图节点进行编码。
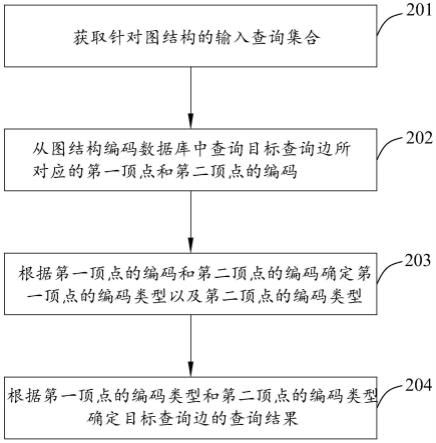
29.在线查询模块根据查询内容对查询点集的编码进行解码,并过滤部分无边查询集合,最终返回查询结果。
30.在线更新模块用于维护图编码数据,对于数据库进行的更新、删除、插入等操作同时更新图编码。
31.请参阅图1,图1为本技术实施例提供的图结构查询系统的架构图,包括:
32.图查询加速设备101、数据库设备102以及输入输出设备103;
33.其中,输入输出设备103负责与图查询加速模块101和数据库设备102进行数据交互,初始阶段将图数据集加载到图查询加速设备101中的离线编码模块101a进行编码,查询阶段首先输入查询集合到在线查询模块101b,返回部分结果后再查询数据库设备102,最终将从数据库设备102中查询到的查询结果返回给输入输出设备103。更新阶段首先将更新数据输入到在线更新模块101c进行编码更新,之后再基于编码后的更新数据对数据库设备102进行更新。其中,该数据库设备102包括但不限于图数据库以及关系型数据库等。
34.下面从图结构查询装置的角度对图结构的查询方法的进行说明,该图结构查询装置可以为服务器,也可以为服务器中的服务单元,具体不做限定。
35.请结合参阅图2,图2为本技术实施例提供的图结构的查询方法的流程示意图,包括:
36.201、获取针对图结构的输入查询集合。
37.本实施例中,图结构查询装置可以获取针对图结构的输入查询集合,该输入查询集合中包括至少一个输入查询边,例如输入查询集合中包括多个查询边(v1,v2),其中,v1为查询边的一个顶点,v2为查询边中的另一个顶点,针对输入查询集合中的多个查询边,只需要多次调用执行即可单个查询边(v1,v2)即可。
38.202、从图结构编码数据库中查询目标查询边所对应的第一顶点和第二顶点的编码。
39.本实施例中,图结构查询装置可以从图结构编码数据库中获取目标查询边所对应的第一顶点和第二顶点的编码,该图结构编码数据库中存储有包括目标查询边的两个顶点在内的多个顶点所对应的编码,目标查询边为输入查询集合中的任意一个查询边。
40.本技术中通过k-core的方式将图数据进行编码并添加至图结构编码数据库,其中,k-core是一种常用来挖掘图中紧密关联子图结构的算法,给定一个图g和参数k,k-core分解算法的目标就是进行子图划分,获取一个极大子图,使子图内的所有顶点度数都大于等于k,即子图内所有顶点至少有k条边与子图内其余顶点相连接,具体的分解方法可以通过对顶点度数排序,然后迭代移除度数最小的顶点以及与其相连接的边,并使其邻居节点度数减一,直到剩余顶点的度数都大于等于k,得到最终子图。主要分为两个内容:
41.1、通过k-core算法对图数据进行划分,得到划分结果,由此可以减少编码过程中的冗余信息;
42.2、根据划分结果,将顶点划分成已经移除的点和剩余的k-core子图顶点,按照顶点的类型不同,采取不同的编码方式对顶点进行编码,该编码方式主要有直接编码和组合编码这两种。
43.编码部分首先需要输入编码长度m,1个编码长度代表32位(为了方便描述,本技术中所提到位等同于bit),即一个顶点的编码总长度为32*m,输入参数m用于计算k-core算法中的参数k。编码长度m可以采用手动或者使用默认设置的方式,默认条件下编码长度m=5,也就是说每个节点的编码占据160位(20字节),这样可以利用较小的编码长度进行有效的图查询加速,兼顾了时间和空间。为了方便说明,下面编码过程的描述都采用m=5,但是对于不同大小的参数m仍然适用,下面进行具体说明:
44.步骤a1、对数据点集进行顶点序列号映射,得到数据点集所对应的目标数据集。
45.本步骤中,图结构查询装置可以读取数据点集,并对读取数据点集进行顶点序列号映射,用id表示顶点原序列号,用id表示顶点映射后序列号,那么第一个读取的点id为1,第二个读取的点id为2,直至点集读取完毕,若数据点集大小为n,那么顶点id为1到n。
46.步骤a2、计算目标数据集所对应的顶点标识最大位数和分解参数。
47.本步骤中,图结构查询装置可以通过如下公式分别计算顶点标识最大位数b和k-core的分解参数k:
48.b=[log2n],m为编码长度,可以采用手动设置或者使用默认设置的方式确定。
[0049]
步骤a3、确定目标数据集中每个数据所对应的顶点度数。
[0050]
步骤a4、确定第一目标顶点的顶点标识以及第一目标顶点的邻居顶点的顶点标识,第一目标顶点为目标数据集中顶点度数最小的顶点。
[0051]
本步骤中,某个顶点的顶点度数为与该顶点相连的边的数量,图结构查询装置可以计算数据点集中所有顶点的度数,并将度数按照升序进行排序,并获取度数最小的顶点(也即第一目标顶点)的顶点标识以及第一目标顶点的邻居顶点的顶点标识,第一目标顶点的邻居顶点指的是与该第一目标顶点有边连接的顶点。
[0052]
步骤a5、基于第一目标顶点的顶点标识以及第一目标顶点的邻居顶点的顶点标识进行直接编码,得到目标顶点所对应的编码。
[0053]
本步骤中,直接编码的方式是将编码划分为三个部分,第一个部分为标志位,占1位,若顶点的编码第一位为0,则代表采取直接编码方式,第二部分占32*m-1位,第一目标顶点的邻居顶点进行升序排序所组成的比特串,每个邻居顶点id占b位,向后对齐(此处的向后对齐指的是,该第二部分的长度是固定的,某个邻居顶点的位数小于该长度,则将该邻居顶点的标识从第二部分的最后一个向前进行填充),即第2位到第2+b-1位代表最小邻居顶点的id。第三部分为剩余比特串,全部用0填充。
[0054]
步骤a6、将第一目标顶点及第一目标顶点所对应的边从目标数据集中剔除,得到第一数据集。
[0055]
本步骤中,图结构查询装置可以移除度数最小的顶点以及与该顶点连接的边,并将与该顶点相连的顶点的度数减一,这也就代表着剩余顶点与该顶点不再连接,由此可以得到第一数据集。
[0056]
步骤a7、基于第一数据集,迭代执行步骤3至步骤6,直至目标数据集中每个数据的顶点度数均大于分解参数。
[0057]
步骤a8、对目标数据集中顶点度数大于分解参数的顶点进行组合编码。
[0058]
本步骤中,对于目标数据集中顶点度数大于分解参数的顶点进行组合编码。因为剩余顶点的度数都大于k,所以无法直接将全部的邻居id写入编码之中,所以组合编码方式将一部分邻居id直接写入编码之中,剩余邻居id通过hash方式写入编码之中,具体直接写入多少邻居id是通过一个基于滑动窗口和贪心策略的得分方法实现。
[0059]
首先对组合编码所对应的编码组成进行说明:
[0060]
组合编码方式下编码被划分成了五个部分:
[0061]
第一个部分为标志位,占1位,0代表直接编码,1代表组合编码;
[0062]
第二个部分占2位,代表组合编码中的邻居id写入模式,分为三个模式:left-most、right-most和midlle,其中,left-most代表直接写入的id中包含了最小的邻居id,right-most则代表直接写入的id中包含了最大的邻居id,middle则代表直接写入的id中既不包含最小的邻居id,也不包含最大邻居id。若该部分第一位和第二位分别为0、0,则写入模式为leftmost模式,若该部分第一位和第二位为0、1,则写入模式为middle模式,若该部分第一位和第二位为1、1,则写入模式为right-most模式。
[0063]
第三个部分为直接写入的邻居个数,占log k位;
[0064]
第四个部分为直接写入的,是该顶点的邻居顶点的顶点id升序组成的比特串,每个id占b位,若第三部分大小为7,则代表直接写入了7个邻居id,该部分长度就为7*b位;
[0065]
第五部分为hash编码部分,长度为剩余的所有编码位数。
[0066]
下面对组合编码的编码流程进行详细说明:
[0067]
步骤b1、确定第二目标顶点所对应的标识序列以及第二目标顶点所对应的邻居节点的标识序列,第二目标顶点为目标数据集中顶点度数大于分解参数的顶点中的任意一个顶点;
[0068]
步骤b1中,输入一个顶点和其邻居节点id序列,并对
[0069]
步骤b2、确定滑动窗口所对应编码的编码得分;
[0070]
步骤b3、若所述编码得分大于预设最优得分,则确定所述滑动窗口的窗口状态,所述窗口状态包括所述滑动窗口的大小和位置;
[0071]
步骤b4、基于所述滑动窗口的大小和位置按照第一移动规则移动所述滑动窗口,并迭代执行步骤b2至步骤b3,直至达到预设终止条件;
[0072]
步骤b5、调整所述滑动窗口的大小,并基于调整后的所述滑动窗口迭代执行步骤b2至步骤b4,直至所述滑动窗口的大小大于预设值;
[0073]
步骤b6、基于目标滑动窗口所对应编码得分以及所述目标滑动窗口所对应的窗口状态进行编码得到所述第二目标顶点所对应的组合编码,所述目标滑动窗口为编码得分最高的所述滑动窗口。
[0074]
也即图结构查询装置可以输入第二目标顶点和其邻居节点id序列,并对邻居节点id序列升序排列,之后初始化一个大小为0个邻居节点的滑动窗口,窗口初始位置最左端指向邻居节点序列的第一个位置,最后通过得分函数,计算该滑动窗口所对应编码的编码得分,如果滑动窗口所对应编码的编码得分大于预设最优得分,则记录当前滑动窗口的窗口状态,该窗口状态包括滑动窗口的大小和位置。
[0075]
下面对滑动窗口所对应编码的编码得分进行具体说明:
[0076]
对滑动窗口外的邻居id分别应用hash函数,然后将函数结果对应的编码的第五部分位置置为1。其中,hash函数为id%h,h代表hash编码总位数,根据hash函数和邻居节点id,将编码第五部分的第id%h位设为1,然后调用得分函数计算得分,下面进行举例说明:
[0077]
例如,如滑动窗口的长度为4,滑动窗口最右端指向邻居标识序列的第5个位置,除了第5至8个邻居id,其余邻居id应用hash函数,编码第五部分对应位置的比特置为1。因为编码第四部分则占了4*b位,所以hash位数h为32*m-3-log k-4*b位。
[0078]
具体的得分函数为:
[0079][0080]
其中,f为滑动窗口所对应编码得分,v
max
为第二目标顶点所对应的邻居节点中处于滑动窗口中最大的邻居标识,v
min
为第二目标定点所对应的邻居节点中处于滑动窗口中最小的邻居标识,如果v
max
刚好等于邻居id序列中的最大值,那么v
max
=n,如果v
min
刚好等于最小值,那么v
min
=0,w为滑动窗口的长度,h为哈希函数结果所对应的编码位置的长度(也即组合编码的第五部分的长度,是hash部分的位数),哈希函数结果为对处于滑动窗口为的第二目标顶点所对应的邻居节点的标识应用哈希函数得到的结果,h0为哈希函数结果所对应的比特串中0的个数。
[0081]
之后将滑动窗口右移一位,重复步骤执行上述步骤,直至滑动窗口的最右端达到邻居标识序列的最右端。
[0082]
之后将滑动窗口的大小增加1,重复步骤上述步骤,直到滑动窗口的大小大于t,其中,
[0083]
最后,图结构查询装置根据上述步骤得到的目标滑动窗口的最高分和目标滑动窗口的窗口状态进行编码,得到第二目标顶点所对应的组合编码。其中,编码第一部分置为1,如果目标滑动窗口包含了最小邻居id,那么写入模式就为left-most,第二部分设为00,如果目标滑动窗口包含了最大邻居id,那么写入模式为right-most,第二部分设为11,否则设为01,第三部分为目标滑动窗口大小,第四部分为目标滑动窗口内的顶点id组成的连续比特串,每个id占b位,拼接成b*w位的比特串,第五部分为其余点经过hash函数后得到的比特串。
[0084]
203、根据第一顶点的编码和第二顶点的编码确定第一顶点的编码类型以及第二顶点的编码类型。
[0085]
本实施例中,图结构查询装置在从图结构编码数据库中查询得到目标查询边所对应的第一顶点的编码和第二顶点的编码之后,可以对第一顶点的编码和第二顶点的编码进行解码,之后通过查看第一顶点的标识位和第二顶点的标识位来确定第一顶点和第二顶点的编码类型,若标识位为0,则是该顶点的编码类型为直接编码,若该标识位为1,则该顶点的编码类型为组合编码。
[0086]
204、根据第一顶点的编码类型和第二顶点的编码类型确定目标查询边的查询结果。
[0087]
本实施例中,图结构查询装置在确定第一顶点的编码类型和第二顶点的编码类型之后,可以根据第一顶点的编码类型和第二顶点的编码类型确定目标查询边的查询结果。可以理解的是,该第一顶点和第二顶点的编码类型有两种编码类型,直接编码和组合编码,为了便于理解,下面以第一顶点为v1,第二顶点为v2为例进行说明:
[0088]
一、第一顶点的编码类型和第二顶点的编码类型均为直接编码,也即目标查询边的两个顶点的编码类型均为直接编码。
[0089]
若第一顶点的编码类型和第二顶点的编码类型均为直接编码,图结构查询装置根
据第一顶点的编码类型和第二顶点的编码类型确定目标查询边的查询结果包括:
[0090]
对第一顶点的编码进行解码,得到第一顶点所对应的邻居标识序列;
[0091]
若第一顶点所对应的邻居标识序列中包含第二顶点,则确定第一顶点与第二顶点为邻居关系;
[0092]
若第一顶点所对应的邻居标识序列中不包含第二顶点,则确定第一顶点与第二顶点为非邻居关系;
[0093]
对第二顶点的编码进行解码,得到第二顶点所对应的邻居标识序列;
[0094]
若第二顶点所对应的邻居标识序列中包含第一顶点,则确定第二顶点与第一顶点为邻居关系;
[0095]
若第二顶点所对应的邻居标识序列中不包含第一顶点,则确定目标查询边不存在查询结果。
[0096]
也即,若第一顶点的编码类型和第二顶点的编码类型均为直接编码,图结构查询装置首先通过邻居检测算法判断v2相对于v1的邻居关系,若返回结果为邻居,那么针对该目标查询边的查询返回边存在结果,若返回结果为非邻居,则图结构查询装置可以通过邻居检测算法判断v1相对于v2的邻居关系,若v1与v2为邻居关系,对目标查询边的查询返回边存在结果,否则返回边不存在结果。下面对邻居检测算法进行详细说明:
[0097]
邻居检测算法主要通过一个顶点的编码与另一个顶点的连接关系。该邻居检测方法的返回结果分成三类:1、非邻居关系;2、邻居关系;3、无法确定邻居关系。
[0098]
下面对邻居检测算法进行描述,以查询v2相对于v1的关系为例,即通过v1的编码判断v2是否为v1的邻居,按照v1的编码类型分为两种方式:
[0099]
直接编码:
[0100]
查询获取v1对应的编码,对v1所对应的编码进行解码得到v1所对应的邻居标识序列,因为直接编码采用连续比特串形式,所以很容易解码,即第2至1+b位为第一个顶点id,以此类推,判断该v1所对应的邻居标识序列中是否包含v2,若不包含,则确定v2相对于v1为非邻居关系,若包含,则确定v2相对于v1为邻居关系。其中,直接编码的编码构成如图3所示。
[0101]
组合编码:
[0102]
查询获取v1对应的编码,首先获取编码中直接邻居id的比特串长度,即编码第4至3+log k位对应的十进制数字,若用w表示,则从第4+log k位开始截取w*b位长度的比特串,等额切分成w个子串,即每个字串长度为b,每个子串转换为十进制形式,最终组成v1编码中可知的邻居id序列。
[0103]
之后确定邻居id序列中idv
max
和最小idv
min
,并查询v1所对应的编码中的第2位和第3位,若为00,则将v
min
置为0,v
max
为v1所对应的邻居id序列中的最大id;若为11,则将v
max
置为n,n为数据点集中的顶点最大id;之后,比较v2和v
max
、v
min
的大小。
[0104]
若v
min
≤v2≤v
max
,则直接查询v1所对应的邻居id序列中是否包含v2,若不包含,则返回结果为非邻居关系,若包含则返回结果为邻居关系。
[0105]
若v2≤v
min
或者v
max
≤v2,计算hash长度h,h=m*32-3-log k-w*b,将v2带入到hash函数f(v)=v%h中,若hash函数的结果为i,则查询v1编码中第3+log k+w*b+i位,若第3+lok+w*b+i位为0,则返回结果为非邻居,若第3+log k+w*b+i位为1,则返回结果为无法确定邻居关系。其中,组合编码的编码构成如图4所示。
[0106]
二、若所述第一顶点的编码类型为直接编码,且所述第二顶点的编码类型为组合编码,也即目标查询边中的一个顶点的编码类型为直接编码,另一个顶点的编码类型为组合编码。
[0107]
若第一顶点的编码类型为直接编码,且第二顶点的编码类型为组合编码根据第一顶点的编码类型和第二顶点的编码类型确定目标查询边的查询结果包括:
[0108]
确定第二顶点所对应的编码中邻居标识的邻居标识序列;
[0109]
根据邻居标识的邻居标识序列确定最大邻居标识和最小邻居标识;
[0110]
根据第二顶点所对应的编码中特定位置参数确定最大邻居标识的目标值和最小邻居标识的目标值;
[0111]
将第一顶点的顶点标识、最大邻居标识的目标值与最小邻居标识的目标值进行对比,得到对比结果;
[0112]
根据对比结果确定目标查询边所对应的查询结果;
[0113]
也即,若v1,v2中一个为直接编码,另一个为组合编码,假如v1为直接编码方式,v2为组合编码方式,图结构查询装置可以首先通过邻居检测算法判断v2相对于v1的邻居关系,若确定v2和v1为邻居关系,那么该目标查询边所对应的查询结果为边存在结果,若确定v2和v1不为邻居关系,则确定该目标查询边所对应的查询结果为边不存在结果。
[0114]
需要说明的是,上述已经对邻居检测算法中组合编码的检测进行详细说明,具体此处不在赘述。
[0115]
三、若第一顶点的编码类型和第二顶点的编码类型均为组合编码,也即目标查询边的两个顶点的编码类型均为组合编码。
[0116]
若第一顶点的编码类型和第二顶点的编码类型均为组合编码,根据第一顶点的编码类型和第二顶点的编码类型确定目标查询边的查询结果包括:
[0117]
基于第一顶点所对应的编码确定目标查询边所对应的第一查询结果;
[0118]
基于第二顶点所对应的编码确定目标查询边所对应的第二查询结果
[0119]
若第一查询结果和所述第二查询结果中包含第一顶点与第二顶点为邻居关系,则确定目标查询边的查询结果为边存在结果;
[0120]
若第一查询结果和第二查询结果中包含第一顶点与第二顶点为非邻居关系,则确定目标查询边的查询结果为边不存在结果;
[0121]
若第一查询结果和第二查询结果中不包含第一顶点与第二顶点为邻居关系,且不包括第一顶点与第二顶点为非邻居关系,则通过查询底层顶点信息图数据库的方式确定目标查询边的查询结果。
[0122]
也即,若v1,v2都是组合编码方式,图结构查询装置分别通过邻居检测算法判断v2相对于v1的邻居关系(也即第一查询结果)和v1相对于v2的邻居关系(也即第二查询结果),若两个查询结果中存在有一个为邻居关系,那么该目标查询边所对应的查询结果为边存在结果;若两个查询结果都为非邻居关系,那么该目标查询边所对应的查询结果为边不存在结果;若无法确定两个顶点之间是否为邻居关系,则可以通过查询顶底存储点信息的数据得到两个顶点之间的关系。
[0123]
需要说明的是,当对图数据进行更新操作时,根据操作性质分为了插入和删除操作,以下内容说明的是单边插入、删除对应的编码维护,对于多边情况下,只需要分解成多
个点单边多次执行即可。此外,为了方便说明,记插入/删除的边为(v1,v2)。
[0124]
一个实施例中,图结构查询装置还执行如下操作:
[0125]
获取目标更新边,所述目标更新边包括第三顶点和第四顶点;
[0126]
确定第三顶点的编码类型和第四顶点的编码类型;
[0127]
根据第三顶点的编码类型和第四顶点的编码类型将目标更新边更新至图结构编码数据库。
[0128]
本实施例中,图结构查询装置可以获取目标更新边,目标更新边包括第三顶点和第四顶点,此处的目标更新边可以是新增的,也可以是删除的,具体不做限定,之后,图结构查询装置可以确定第三顶点的编码类型和第四顶点的编码类型,并根据两个顶点的编码类型将目标更新边更新至图结构编码数据库中。下面根据目标更新边的两个顶点的编码类型对如何新增和删除进行详细说明:一、目标更新边为新加入图结构编码数据库中的边。
[0129]
步骤c1、查询目标更新边的两个顶点v1,v2对应的编码,查看编码标志位,进而确定目标更新边的两个顶点的编码类型。
[0130]
步骤c2、若v1,v2中有一个顶点为直接编码,并且编码中邻居个数小于邻居个数上界b(上述已经对b的计算方式进行详细说明,具体此处不再赘述),若都满足,则随机挑选一个顶点进行更新,具体更新如下:
[0131]
假设满足上述两个情况的顶点为v1,根据原有编码解析v1的邻居标识序列。之后将v2插入到v1的邻居标识序列之中,保持id升序,通过直接编码方式更新编码(上述已经对直接编码的方式进行详细说明,具体此处不再赘述),之后基于顶点v1更新后的编码执行图结构编码数据库的更新操作。
[0132]
步骤c3、若v1,v2中有一个顶点为直接编码,并且编码邻居个数等于邻居个数上界b,另一个编码方式为组合编码。
[0133]
假设顶点v1的编码方式为直接编码,那么只对顶点v1进行编码更新,确定顶点v1的邻居标识序列,将顶点v2插入到顶点v1的邻居标识序列之中,保持id升序,执行组合编码方式更新编码(上述已经对组合编码的方式进行详细说明,具体此处不再赘述),之后基于顶点v1更新后的编码执行图结构编码数据库的更新操作。
[0134]
步骤c4、若v1,v2中两个顶点都是直接编码方式,并且两个顶点的邻居个数都等于邻居个数上界b。
[0135]
获取两个顶点的邻居标识序列,将v1添加到v2的邻居标识序列,应用组合编码方式,得到添加顶点v1的邻居标识序列后的顶点v2的编码得分s1和编码e1,之后将v2添加到v1的邻居标识序列之中,应用组合编码方式,得到添加顶点v2的邻居标识序列后的顶点v1编码得分s2和编码e2。比较两个得分,假设得分s1》s2,那么只更新v1点的编码,用e1代替v1原有编码。
[0136]
步骤c5、若v1,v2中两个顶点都是组合编码方式,那么首先从图结构编码数据库中查询v1的邻居节点作为初始化邻居标识序列,之后查询v1所对应的邻居顶点的编码,以顶点v1为输入运行邻居检测算法(上述已经对邻居检测算法进行详细说明,具体此处不在赘述),若返回结果为邻居关系,那么将该邻居顶点从v1的邻居标识序列中移除,然后执行组合编码方式得到编码得分s1和编码e1,对v2执行相同操作得到编码得分s2和编码e2,比较两个得分,假设得分s1》s2,那么只更新v1点的编码,用e1代替v1原有编码。
[0137]
二、目标更新边为从图结构编码数据库中删除的边。
[0138]
步骤d1、查询目标查询边所对应的两个顶点v1和v2对应的编码,查看编码标志位,以确定两个顶点v1和v2的编码类型。
[0139]
步骤d2、若v1,v2都是直接编码,首先对v1解码,获得v1所对应的邻居id序列,若v1所对应的邻居id序列中包含v2,则删除v1所对应的邻居id序列中的v2,基之后重新进行直接编码,并用重新编码后得到的编码更新v1对应的编码;
[0140]
若v1所对应的邻居id序列不包含v2,则对v2解码,获得v2所对应的邻居id序列,若v2所对应的邻居id序列不包含v1,则删除v2所对应的邻居id序列的v1,用删除后得到的序列对v2进行重新编码,并用重新编码后得到的编码更新v2所对应的编码。
[0141]
步骤d3、若v1,v2中有一个为直接编码方式,另一个为组合编码方式,假设v1为直接编码,首先对v1解码,获得v1所对应的邻居id序列,若v1所对应的邻居id序列中包含v2,则删除v1所对应的邻居id序列中的v2,重新进行直接编码,更新v1对应的编码。若v1所对应的邻居id序列中不包含v2,则直接进行数据库更新操作。
[0142]
步骤d4、若v1,v2都为组合编码方式,首先通过v1的编码判断能否确定v2不是v1的邻居,上述已经对如何确定两个顶点的邻居关系进行详细说明,具体此处不在赘述。
[0143]
如果不能确定v2不是v1的邻居,通过数据库查询v1的邻居标识序列,并邻居标识序列中删除v2,如果删除后邻居标识序列的长度≤k,采用直接编码方式对v1重新编码,否则采用组合编码的方式对v1重新编码。之后,基于顶点v2迭代执行上述步骤。最后,基于重新编码后得到的两个顶点的编码对数据库进行更新。
[0144]
综上所述,可以看出,本技术提供的实施例中,通过将图数据以直接编码和组合编码的方式进行预先编码,并将编码后的图结构编码存储至图结构编码数据库中,这样在输入查询边时可以确定查询边的两个顶点的编码类型,并根据编码类型进行查询,从而在确保查询结果正确的前提下兼顾时间和空间效率,可以减少图结构查询的耗时。
[0145]
上面从图结构的查询方法对本技术进行说明,下面从图结构查询装置的角度对本技术进行说明。
[0146]
请参阅图5,图5为本技术实施例提供的图结构查询装置的虚拟结构示意图,该图结构查询装置500包括:
[0147]
获取单元501,用于获取针对图结构的输入查询集合,所述输入查询集合中包括至少一个输入查询边;
[0148]
查询装置502,用于从图结构编码数据库中查询目标查询边所对应的第一顶点和第二顶点的编码,所述图结构编码数据库中包括所述目标查询边的两个顶点在内的多个顶点所对应的编码,所述目标查询边为所述输入查询集合中的任意一个查询边,所述多个顶点中每个顶点的编码类型为直接编码或组合编码;
[0149]
第一确定单元503,用于根据所述第一顶点的编码和所述第二顶点的编码确定所述第一顶点的编码类型以及所述第二顶点的编码类型;
[0150]
第二确定单元504,用于根据所述第一顶点的编码类型和第二顶点的编码类型确定所述目标查询边的查询结果。
[0151]
一种可能的设计中,若所述第一顶点的编码类型和所述第二顶点的编码类型均为直接编码,所述第二确定单元504具体用于:
[0152]
对所述第一顶点的编码进行解码,得到所述第一顶点所对应的邻居标识序列;
[0153]
若所述第一顶点所对应的邻居标识序列中包含所述第二顶点,则确定所述第一顶点与所述第二顶点为邻居关系;
[0154]
若所述第一顶点所对应的邻居标识序列中不包含所述第二顶点,则确定所述第一顶点与所述第二顶点为非邻居关系;
[0155]
对所述第二顶点的编码进行解码,得到所述第二顶点所对应的邻居标识序列;
[0156]
若所述第二顶点所对应的邻居标识序列中包含所述第一顶点,则确定所述第二顶点与所述第一顶点为邻居关系;
[0157]
若所述第二顶点所对应的邻居标识序列中不包含所述第一顶点,则确定所述目标查询边不存在查询结果。
[0158]
一种可能的设计中,若所述第一顶点的编码类型为直接编码,且所述第二顶点的编码类型为组合编码,所述第二确定单元504还具体用于:
[0159]
确定所述第二顶点所对应的编码中邻居标识的邻居标识序列;
[0160]
根据所述邻居标识的邻居标识序列确定最大邻居标识和最小邻居标识;
[0161]
根据所述第二顶点所对应的编码中特定位置参数确定所述最大邻居标识的目标值和所述最小邻居标识的目标值;
[0162]
将所述第一顶点的顶点标识、所述最大邻居标识的目标值与所述最小邻居标识的目标值进行对比,得到对比结果;
[0163]
根据所述对比结果确定所述目标查询边所对应的查询结果。
[0164]
一种可能的设计中,若所述第一顶点的编码类型和所述第二顶点的编码类型均为组合编码,所述第二确定单元504还具体用于:
[0165]
基于所述第一顶点所对应的编码确定所述目标查询边所对应的第一查询结果;
[0166]
基于所述第二顶点所对应的编码确定所述目标查询边所对应的第二查询结果
[0167]
若所述第一查询结果和所述第二查询结果中包含所述第一顶点与所述第二顶点为邻居关系,则确定所述目标查询边的查询结果为边存在结果;
[0168]
若所述第一查询结果和所述第二查询结果中包含所述第一顶点与所述第二顶点为非邻居关系,则确定所述目标查询边的查询结果为边不存在结果;
[0169]
若所述第一查询结果和所述第二查询结果中不包含所述第一顶点与所述第二顶点为邻居关系,且不包括所述第一顶点与所述第二顶点为非邻居关系,则通过查询底层顶点信息图数据库的方式确定所述目标查询边的查询结果。
[0170]
一种可能的设计中,所述第一确定单元503还用于:
[0171]
步骤1、对数据点集进行顶点序列号映射,得到所述数据点集所对应的目标数据集;
[0172]
步骤2、计算所述目标数据集所对应的顶点标识最大位数和分解参数;
[0173]
步骤3、确定所述目标数据集中每个数据所对应的顶点度数;
[0174]
步骤4、确定第一目标顶点的顶点标识以及所述第一目标顶点的邻居顶点的顶点标识,所述第一目标顶点为所述目标数据集中顶点度数最小的顶点;
[0175]
步骤5、基于所述第一目标顶点的顶点标识以及所述第一目标顶点的邻居顶点的顶点标识进行直接编码,得到所述目标顶点所对应的编码;
[0176]
步骤6、将所述第一目标顶点及所述第一目标顶点所对应的边从所述目标数据集中剔除,得到第一数据集;
[0177]
步骤7、基于所述第一数据集,迭代执行步骤3至步骤6,直至所述目标数据集中每个数据的顶点度数均大于所述分解参数;
[0178]
步骤8、对所述目标数据集中顶点度数大于所述分解参数的顶点进行组合编码。
[0179]
一种可能的设计中,所述第一确定单元503对所述目标数据集中顶点度数大于所述分解参数的顶点进行组合编码包括:
[0180]
步骤1、确定第二目标顶点所对应的标识序列以及所述第二目标顶点所对应的邻居节点的标识序列,所述第二目标顶点为所述目标数据集中顶点度数大于所述分解参数的顶点中的任意一个顶点;
[0181]
步骤2、确定滑动窗口所对应编码的编码得分,所述滑动窗口为大小为零个邻居节点个数的滑动窗口;
[0182]
步骤3、若所述编码得分大于预设最优得分,则确定所述滑动窗口的窗口状态,所述窗口状态包括所述滑动窗口的大小和位置;
[0183]
步骤4、基于所述滑动窗口的大小和位置按照第一移动规则移动所述滑动窗口,并迭代执行步骤2至步骤3,直至达到预设终止条件;
[0184]
步骤5、调整所述滑动窗口的大小,并基于调整后的所述滑动窗口迭代执行步骤2至步骤4,直至所述滑动窗口的大小大于预设值;
[0185]
步骤6、基于目标滑动窗口所对应编码得分以及所述目标滑动窗口所对应的窗口状态进行编码得到所述第二目标顶点所对应的组合编码,所述目标滑动窗口为编码得分最高的所述滑动窗口。
[0186]
一种可能的设计中,所述第一确定单元503基于目标滑动窗口所对应编码得分以及所述目标滑动窗口所对应的窗口状态进行编码得到所述第二目标顶点所对应的组合编码包括:
[0187]
将所述第二目标顶点所对应的第一位置编码置为1;
[0188]
根据所述目标滑动窗口中包含所述第二目标顶点所对应的邻居标识确定第二位置编码;
[0189]
将所述目标滑动窗口的大小设置为第三位置编码;
[0190]
将所述目标滑动窗口中包含的邻居节点的标识所对应的连续比特串设置为第四位置编码;
[0191]
对所述第二目标顶点所对应的邻居节点中的剩余节点进行哈希函数处理,得到第五位置编码;
[0192]
所述第二目标顶点所对应的组合编码包括所述第一位置编码、所述第二位置编码、所述第三位置编码、所述第四位置编码以及所述第五位置编码。
[0193]
一种可能的设计中,所述装置还包括:
[0194]
更新单元505,所述更新单元505用于:
[0195]
获取目标更新边,所述目标更新边包括第三顶点和第四顶点;
[0196]
确定所述第三顶点的编码类型和所述第四顶点的编码类型;
[0197]
根据所述第三顶点的编码类型和所述第四顶点的编码类型将所述目标更新边更
新至所述图结构编码数据库。
[0198]
图6为本技术服务器的结构示意图,如图6所示,本实施例的服务器600包括至少一个处理器601,至少一个网络接口604或者其他用户接口603,存储器605,和至少一通信总线602。该服务器600可选的包含用户接口603,包括显示器,键盘或者点击设备。存储器605可能包含高速ram存储器,也可能还包括非不稳定的存储器(non-volatilememory),例如至少一个磁盘存储器。存储器605存储执行指令,当服务器600运行时,处理器601与存储器605之间通信,处理器601调用存储器605中存储的指令,以执行上述图结构的查询方法。操作系统606,包含各种程序,用于实现各种基础业务以及处理根据硬件的任务。
[0199]
本技术实施例提供的服务器,可以执行上述的图结构的查询方法的实施例的技术方案,其实现原理和技术效果类似,此处不再赘述。
[0200]
本技术实施例还提供了一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被计算机执行时实现上述任一方法实施例中与图结构查询装置相关的方法流程。对应的,该计算机可以为上述图结构查询装置。
[0201]
本技术实施例还提供了一种计算机程序或包括计算机程序的一种计算机程序产品,该计算机程序在某一计算机上执行时,将会使所述计算机实现上述任一方法实施例中与图结构查询装置相关的方法流程。对应的,该计算机可以为上述的图结构查询装置。
[0202]
在上述图1对应的实施例中,可以全部或部分地通过软件、硬件、固件或者其任意组合来实现。当使用软件实现时,可以全部或部分地以计算机程序产品的形式实现。
[0203]
以上所述实施例仅用以说明本技术的技术方案,而非对其限制;尽管参照前述实施例对本技术进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本技术各实施例技术方案的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1