一种基于LSTM和语法距离的方面级情感分析方法
一种基于lstm和语法距离的方面级情感分析方法
技术领域
1.本发明涉及一种基于lstm和语法距离的方面级情感分析方法,主要涉及自然语言领域。
背景技术:
2.与传统情感分析不同的是,方面级情感分析(aspect-based sentiment analysis,absa)由于能分析出句子中特定方面的情感而受到广泛研究。近年来,深度学习方法被广泛用于方面级情感分析,并且大多依赖于长短时记忆网络(long-short term memory,lstm)和注意力机制。lstm由于可以避免梯度消失或爆炸的问题被广泛用于特征提取。tang等使用lstm的隐藏表示预测情感。ruder等使用双向长短时记忆网络(bidirectional lstm,bi-lstm)获得了更好的分类效果。li等提出了特定目标的转换网络(target-specific transformation networks,tnet),将上下文特征和转换后的特征卷积以获取最终表示。但以上模型采用传统的lstm,同等地看待上下文词,无法准确的匹配与方面词更相关的上下文词。因此,wang等引入注意力机制,并将方面嵌入直接拼接到上下文嵌入中,取得了不错的效果,证明了注意力机制在absa中的作用。xu等结合局部上下文焦点和依赖集群构建注意力用于方面级情感分析。basiri基于注意力机制,构建了一种融合cnn与rnn的情感分析模型。tang等提出深度记忆网络(deep memory network,memnet),采用多层注意力分配上下文权重获得了更好的分类效果。但是以上模型采用的注意力机制忽略了方面词与上下文的交互,限制了分类性能。为了实现方面词与上下文的交互,获取更好的特征表示,ma等和huang等分别提出了交互注意力网络(interactive attention networks,ian)和双重注意力网络(attention-over-attention,aoa)。让方面词与上下文词分别参与对方的建模,进一步提高了分类性能。然而,这些交互注意力机制由于没有逐词地计算方面词与上下文的一致性,可能错误地关联与方面词不相关的上下文词,限制了分类性能,此外,也缺少对语法特征的分析。图卷积网络(graph convolutional networks,gcn)由于能够捕获单词间的语法特征而被应用于absa。zhou提出一种基于语法和知识的图卷积网络。zhu提出一种利用局部和全局信息引导图卷积网络构建的模型。zhang等提出了特定方面的图卷积网络(aspect-specific gcn,asgcn),用gcn提取到方面词特征后再反馈给上下文表示,获得交互注意力权重作为情感分类的依据,取得了不错的效果。但是,上述及现有方法在进行absa任务是会存在以下缺陷:
3.(1)使用相对位置权重,缺乏语法距离的考虑,很可能错误地将方面词与语法上关联度不高的上下文错误匹配,导致情感分类错误。
4.(2)大部分方法缺乏方面词和上下文词的交互,很容易使得方面词匹配到与其情感极性判断无关的上下文词,影响情感极性的判断。
5.(3)在获取最终表示时,仅考虑方面词和上下文词的特征表示,忽略了其他特征。
6.因此,亟需一种能够同时解决上述缺陷的方面级情感分析方法。
技术实现要素:
7.针对以上现有技术的不足,本发明提出一种基于lstm和语法距离的方面级情感分析方法,从语义上改进了方面词和上下文错误匹配的情况,提升了方面词和上下文词的语义关联性;从语法上改进了图卷积网络的输入,使得方面词和上下文词的语法关联性更高;并在最终的信息交互时,使得位置权重层的输出也参与信息交互,从而获取了更多的位置权重特征。
8.为达到上述目的,本发明的技术方案是:
9.一种基于lstm和语法距离的方面级情感分析方法,其特征在于,包括以下步骤:
10.s1:特征输入:使用glove预训练模型对词向量进行映射,再分别让方面词和上下文词经过bi-lstm,得到方面词和上下文的隐藏表示;
11.s2:语义特征提取:采用图卷积网络和mlstm分别提取方面词和上下文的语义特征;
12.s3:方面词和上下文词语义交互阶段:将s2提取到的方面词和上下文的特征进行一个点积注意力操作;
13.s4:情感预测阶段:对s3中得到的特征进行一个最大池化操作后,再通过softmax操作得到最终预测的情感极性。
14.优选地,步骤s1中,使用glove预训练模型,将待进行情感分析的句子中每个词转换为词向量,并采用bi-lstm得到方面词和上下文词的隐藏表示。
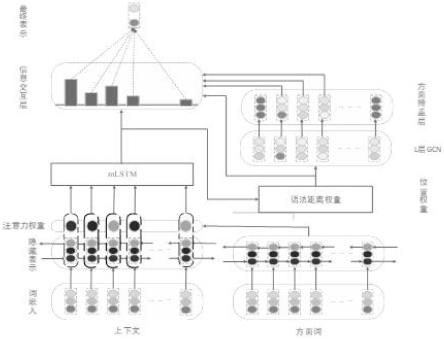
15.优选地,步骤s2中,采用图卷积网络和mlstm分别提取方面词和上下文的语义特征,具体包括:将步骤s1中得到的方面词的隐藏表示同上下文词逐一地计算关联程度,得到方面词对于上下文词的注意力向量,并将该注意力向量与上下文词的隐藏表示拼接起来,作为mlstm的输入,得到含有更多方面信息的上下文词的特征表示;然后使用spacy进行语法依赖分析得到语法依赖树,并引入语法距离作为位置权重,使得在语法依赖树上与方面词距离更近的上下文词获得更大的权重,同时与上下文词的最终表示和经过语法依赖树构建的邻接矩阵一同作为图卷积网络的输入,经由图卷积网络获取不相邻单词之间的依赖关系并获取到丰富的语法特征;然后经过方面掩盖层过滤掉非方面词,得到方面词的隐藏表示;然后将得到的上下文词表示、方面词表示和语法距离权重进行信息交互,用于方面级情感分析。
16.优选地,所述的模型包括mlstm层,位置权重层,图卷积层,方面掩盖层和信息交互层。
17.优选地,所述的mlstm层计算过程包括:
18.将通过bi-lstm得到的方面词和上下文词的隐藏表示和逐一的计算二者之间的关联性,表达式为:
[0019][0020]
其中,α
kj
是用来编码上下文词和方面词之间的的注意权重,表达式为:
[0021][0022]
其中,e
kj
,用来获取上下文词与不同方面词之间的关联,表达式为:
[0023][0024]
其中,we和所有的参数矩阵w
*
均为可学习的权重矩阵。是由mlstm产生的第k个位置的隐藏状态;
[0025]
然后将上下文中第k个单词的关于方面词的注意力权重ak与上下文中第k个单词的隐藏状态融合起来,作为mlstm的输入mk。经过mlstm得到含有方面信息的上下文表示
[0026][0027]
优选地,步骤s2中,引入语法距离权重代替相等距离,使得与方面词的语法关联更大的上下文词能够获得更大的权重,优化图卷积网络的输入,经过图卷积网络得到含有丰富语法特征的句子表示后,又通过方面掩盖层过滤掉非方面词,得到方面表示。
[0028]
优选地,语法距离权重由语法依赖树得到,其表达式为:
[0029][0030]
其中,d
i,a
为上下文中第k个单词与方面词的语法距离,d
max
表示d
s,a
中语法距离的最大值。然后位置权重层将语法距离权重与上下文的最终表示作为输入,得到位置权重层的输出:其中
[0031]
将位置权重层的输出h
pm
、上下文的隐藏表示hm和句子依赖树的邻接矩阵a
ij
作为图卷积网络的输入。假设图卷积网络为l层,则图卷积网络更新规则的表达式为:
[0032][0033]
其中,为第l层图卷积网络的第i个节点的隐藏表示,表示第(l-1)层的第j个节点的隐藏表示;a
ij
是n*n的邻接矩阵,由句法依赖树得到;a
ij
=1表示节点i和节点j之间有连接;自环设定为1;w
l
是权重矩阵,b
l
为偏差项,w
l
和b
l
都是可训练的;表示与第i个节点相关联的边数;
[0034]
最后得到l层图卷积网络的隐藏表示为
[0035]
方面掩盖层只让方面的隐藏表示通过,而对于非方面的单词,则不能通过;经过方面掩盖层的隐藏表示为其表达式为:
[0036][0037]
其中,代表方面词t的隐藏表示,τ+1表示方面词的起始位置,τ+q表示方面词的结束位置。
[0038]
优选地,所述的信息交互层使用上下文表示hm、位置权重层h
pm
和方面特征表示得到最终的注意力权重ra,其流程为:
[0039][0040][0041][0042]
然后情感分类层以最终的注意力权重ra作为输入,使用softmax函数获取到情感的概率分布p;
[0043]
p=softmax(w
p
ra+b
p
)
[0044]
其中,权重矩阵w
p
和偏置项b
p
为可训练的。
[0045]
优选地,步骤s4中,在训练阶段采用交叉熵和l2正则化来计算预测标签和真实标签之间的损失值,并通过dropout机制防止模型过拟合;在测试阶段根据预测值来评价模型的效果。
[0046]
本发明的技术原理及有益效果如下:
[0047]
1、使用mlstm将方面词逐一地与上下文词计算相关性,得到注意力向量,并将该注意力向量与上下文表示拼接起来,作为mlstm的输入,以获取到与方面词关联性更高的上下文表示,从而减少方面词与不相关上下文错误匹配的概率;
[0048]
2、引入语法距离权重代替相对距离权重,并使用该权重优化图卷积网络的输入,保证了语法距离小的上下文具有更大的位置权重,可以减小与目标方面无关的其他方面的情感词的影响;
[0049]
3、在计算最终的交互信息时,增加了位置权重层的输出,充分利用了文本提供的有用信息。
附图说明
[0050]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的其中两幅,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0051]
图1融合mlstm和语法距离的图卷积网络;
[0052]
图2“food”的句法依赖树。
具体实施方式
[0053]
下面将结合附图,对本发明中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明的较佳实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0054]
实施例
[0055]
如图1所示,本发明实施例一种基于lstm和语法距离的方面级情感分析方法,其特征在于,包括以下步骤:
[0056]
s1:特征输入:使用glove预训练模型对词向量进行映射,再分别让方面词和上下文词经过bi-lstm,得到方面词和上下文的隐藏表示。
[0057]
用高维的数字向量表示每一句话中的单词,并采用glove词嵌入进行词向量映射,然后将该映射作为方面级情感分析的输入,并进行一次bi-lstm层的计算,分别得到含有方面词和上下文语义信息的隐藏表示。
[0058]
s2:语义特征提取:采用图卷积网络和mlstm分别提取方面词和上下文的语义特征;
[0059]
s3:方面词和上下文词语义交互阶段:将s2提取到的方面词和上下文的特征进行一个点积注意力操作;
[0060]
s4:情感预测阶段:对s3中得到的特征进行一个最大池化操作后,再通过softmax操作得到最终预测的情感极性。
[0061]
步骤s1中,使用glove预训练模型,将待进行情感分析的句子中每个词转换为词向量,并采用bi-lstm得到方面词和上下文词的隐藏表示。
[0062]
步骤s1,用高维的数字向量表示每一句话中的单词,并采用glove词嵌入进行词向量映射,然后将该映射作为方面级情感分析的输入,并进行一次bi-lstm层的计算,分别得到含有方面词和上下文语义信息的隐藏表示。
[0063]
步骤s2中,采用图卷积网络和mlstm分别提取方面词和上下文的语义特征,具体包括:将步骤s1中得到的方面词的隐藏表示,同上下文词逐一地计算关联程度,得到方面词对于上下文词的注意力向量,并将该注意力向量与上下文词的隐藏表示拼接起来,作为mlstm的输入,得到含有更多方面信息的上下文词的特征表示;然后使用spacy进行语法依赖分析得到语法依赖树,并引入语法距离作为位置权重,使得在语法依赖树上与方面词距离更近的上下文词获得更大的权重,并将经过mlstm得到的上下文隐藏表示与语法距离权重作为位置权重层的输入,经过位置权重层的输出连同邻接矩阵作为图卷积网络的输入,得到含
有丰富语法特征的句子表示,再通过方面掩盖层过滤掉上下文词,得到方面词的特征表示。
[0064]
所述的模型包括mlstm层,位置权重层,图卷积层,方面掩盖层和信息交互层。
[0065]
所述的mlstm层计算过程包括:
[0066]
将通过bi-lstm得到的方面词和上下文词的隐藏表示和逐一的计算二者之间的关联性,表达式为:
[0067][0068]
其中,α
kj
是用来编码上下文词和方面词之间的的注意权重,表达式为:
[0069][0070]
其中,e
kj
,用来获取上下文词与不同方面词之间的关联,表达式为:
[0071][0072]
其中,we和所有的参数矩阵w
*
均为可学习的权重矩阵。是由mlstm产生的第k个位置的隐藏状态;
[0073]
然后将上下文中第k个单词的关于方面词的注意力权重ak与上下文中第k个单词的隐藏状态融合起来,作为mlstm的输入mk。经过mlstm得到含有方面信息的上下文表示
[0074][0075]
步骤s2中,引入语法距离权重代替相等距离,使得与方面词的语法关联更大的上下文词能够获得更大的权重,优化图卷积网络的输入,经过图卷积网络得到含有丰富语法特征的句子表示后,又通过方面掩盖层过滤掉非方面词,得到方面表示。
[0076]
语法距离权重由语法依赖树得到,其表达式为:
[0077][0078]
其中,d
i,a
为上下文中第k个单词与方面词的语法距离,d
max
表示d
s,a
中语法距离的最大值。然后位置权重层将语法距离权重与上下文的最终表示作为输入,得到位置权重层的输出:其中
[0079]
将位置权重层的输出h
pm
、上下文的隐藏表示hm和句子依赖树的邻接矩阵a
ij
作为图卷积网络的输入。假设图卷积网络为l层,则图卷积网络更新规则的表达式为:
[0080][0081]
其中,为第l层图卷积网络的第i个节点的隐藏表示,表示第(l-1)层的第j个节点的隐藏表示;a
ij
是n*n的邻接矩阵,由句法依赖树得到;a
ij
=1表示节点i和节点j之间有连接;自环设定为1;w
l
是权重矩阵,b
l
为偏差项,w
l
和b
l
都是可训练的;表示与第i个节点相关联的边数;
[0082]
最后得到l层图卷积网络的隐藏表示为
[0083]
方面掩盖层只让方面的隐藏表示通过,而对于非方面的单词,则不能通过;经过方面掩盖层的隐藏表示为其表达式为:
[0084][0085]
其中,代表方面词t的隐藏表示,τ+1表示方面词的起始位置,τ+q表示方面词的结束位置。
[0086]
所述的信息交互层使用上下文表示hm、位置权重层h
pm
和方面特征表示得到最终的注意力权重ra,其流程为:
[0087][0088][0089][0090]
然后情感分类层以最终的注意力权重ra作为输入,使用softmax函数获取到情感的概率分布p;
[0091]
p=softmax(w
p
ra+b
p
)
[0092]
其中,权重矩阵w
p
和偏置项b
p
为可训练的。
[0093]
步骤s3,将(2)得到的方面词和上下文的隐藏表示进行点积注意力操作,获取对于方面词的情感判断重要的信息。
[0094]
步骤s4中,在训练阶段采用交叉熵和l2正则化来计算预测标签和真实标签之间的损失值,并通过dropout机制防止模型过拟合;在测试阶段根据预测值来评价模型的效果。
[0095]
步骤s4在训练阶段采用交叉熵和l2正则化来计算预测标签和真实标签之间的损失值,并通过dropout机制防止模型过拟合;在测试阶段根据预测值来评价模型的效果。
[0096]
从语义上改进了方面词和上下文错误匹配的情况,提升了方面词和上下文词的语义关联性;从语法上改进了图卷积网络的输入,使得方面词和上下文词的语法关联性更高;并在最终的信息交互时,使得位置权重层的输出也参与信息交互,从而获取了更多的位置权重特征。
[0097]
提升了方面词与重要上下文正确匹配的概率,并通过引入语法距离权重代替相对距离,进一步在语法层面上提取与方面词语法关联程度大的上下文,最终提升了方面级情感分析的准确率。
[0098]
本发明方法的实施过程包括如下具体步骤:
[0099]
步骤1:对长度为n的语句其中方面词表示为由glove预训练模型分别得到方面词和上下文的词向量和后,经过bi-lstm,分别得到方面词的隐藏表示和上下文隐藏表示
[0100]
步骤2:使用和分别表示方面词和上下文词的隐藏状态。用ak表示方面隐藏状态对上下文中单词的注意力向量,其表达式为:
[0101][0102]
其中,α
kj
是用来编码上下文词和方面词之间的的注意权重,其表达式为:
[0103][0104]
其中,e
kj,
用来获取上下文词与不同方面词之间的关联,其表达式为:
[0105][0106]
其中,we和所有的参数矩阵w
*
均为可学习的权重矩阵。是由mlstm产生的第k个位置的隐藏状态。这里,将上下文中第k个单词的关于方面词的注意力权重ak与上下文中第k个单词的隐藏状态融合起来,作为mlstm的输入mk。
[0107][0108]
最后得到逐词匹配后上下文词的隐藏表示
[0109]
其次,在获取方面词的特征表示时,用spacy构建语法依赖树,再使用语法依赖树得到上下文词的权重值lk为:
[0110][0111]
其中d
k,a
为上下文中第k个单词与方面词的语法距离,d
max
表示d
s,a
中语法距离的最大值。保证了语法距离小的上下文具有更大的位置权重,可以减小与目标方面无关的其他方面的情感词的影响。
[0112]
位置权重层的输出为其中
[0113]
使用图卷积网络来获取情感特征。将位置权重层的输出h
pm
、上下文的隐藏表示hm和句子依赖树的邻接矩阵a
ij
作为图卷积网络的输入。假设图卷积网络为l层,则图卷积网络更新规则的表达式为:
[0114][0115]
其中,为第l层图卷积网络的第i个节点的隐藏表示,表示第(l-1)层的第j个节点的隐藏表示。a
ij
是n*n的邻接矩阵,由句法依赖树得到。a
ij
=1表示节点i和节点j之间有连接。特别地,自环设定为1。w
l
是权重矩阵,b
l
为偏差项,w
l
和b
l
都是可训练的。表示与第i个节点相关联的边数。
[0116]
最后得到l层图卷积网络的隐藏表示为
[0117]
方面掩盖层只让方面的隐藏表示通过,而对于非方面的单词,则不能通过。经过方面掩盖层的隐藏表示其表达式为:
[0118][0119]
其中,代表方面词t的隐藏表示,τ+1表示方面词的起始位置,τ+q表示方面词的结束位置。
[0120]
步骤3:在计算最终的注意力权重时,本文考虑了包含上下文语义,位置权重和带有语法信息的方面特征等多重因素,充分利用了文本信息。使用上下文表示hm、位置权重层h
pm
和方面特征表示得到最终的注意力权重ra。
[0121]
[0122][0123][0124]
步骤4:对于上一层得到的最终的注意力权重ra进行softmax操作得到用于情感极性分类的最终表示,其表达式为:
[0125]
p=softmax(w
p
ra+b
p
)
[0126]
其中,权重矩阵w
p
和偏置项b
p
为可训练的。
[0127]
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1