一种内存故障处理方法、装置及计算机可读存储介质与流程
1.本技术涉及计算机技术领域,特别是涉及一种内存故障处理方法、装置及计算机可读存储介质。
背景技术:
2.服务器内存也是内存(ram),具有一些特有的技术,例如错误检查和纠正(error correcting code,ecc)等,从而有着极高的稳定性和纠错性能。而当前所有现代操作系统对于服务器内存的访问,并不是直接访问物理内存的,而是通过一个中间层,这个中间层在操作系统中被称为虚拟内存(virtual memory,vm);操作系统通过vm,去访问vm映射的对应的物理内存。同时也可以改变虚拟内存映射的物理内存地址,从而使操作系统访问该物理内存地址。
3.但是,在服务器的运行使用中,服务器硬件故障诊断和故障预测是服务器运行维护领域的痛点也是技术难点。其中由内存引起的服务器故障是所有故障中占比最高的,因此如果能够有效诊断服务器内存故障,并且对故障进行技术隔离,便可以有效降低服务器故障。
4.鉴于上述问题,设计一种可靠的内存故障处理方法,是该领域技术人员亟待解决的问题。
技术实现要素:
5.本技术的目的是提供一种内存故障处理方法、装置及计算机可读存储介质。
6.为解决上述技术问题,本技术提供一种内存故障处理方法,包括:监测服务器的内存的故障信息,以确认所述内存发生故障;获取所述内存的冗余空间;判断所述冗余空间是否小于第一阈值;若否,根据所述故障信息获取故障物理内存地址及其对应的虚拟内存地址;通过所述内存的冗余机制将所述故障物理内存地址隔离,并获取新的物理内存地址;其中,所述新的物理内存地址的空间与所述故障物理内存地址的空间大小相等;将所述虚拟内存地址对应的所述故障物理内存地址中的数据备份;映射所述虚拟内存地址至所述新的物理内存地址,以用于将所述数据迁移至所述新的物理内存地址。
7.优选地,所述监测服务器的内存的故障信息包括:通过mca技术监测所述内存的所述故障信息,将所述故障信息记录在中断屏蔽控制寄存器中,并生成故障日志。
8.优选地,所述监测服务器的内存的故障信息包括:判断所述故障信息的数量在第一预设时间内是否大于第二阈值;其中,所述故障信息的数量以第二预设时间为周期递减,所述第二预设时间小于所述第一预设时间;
若是,则确认所述内存发生故障,进入到所述获取所述内存的冗余空间的步骤。
9.优选地,所述根据所述故障信息获取故障物理内存地址及其对应的虚拟内存地址包括:解析所述中断屏蔽控制寄存器以获取到所述故障物理内存地址;根据所述故障日志通过内存管理单元获取所述故障物理内存地址对应的所述虚拟内存地址。
10.优选地,在所述映射所述虚拟内存地址至所述新的物理内存地址之后,还包括:标记所述故障物理内存地址。
11.优选地,在所述标记所述故障物理内存地址之后,还包括:触发内存故障告警。
12.优选地,若判断所述冗余空间小于第一阈值,还包括:输出提示更换所述内存的信息。
13.为解决上述技术问题,本技术还提供一种内存故障处理装置,包括:监测模块,用于监测服务器的内存的故障信息,以确认所述内存发生故障;第一获取模块,用于获取所述内存的冗余空间;判断模块,用于判断所述冗余空间是否小于第一阈值;若否,触发第二获取模块;所述第二获取模块,用于根据所述故障信息获取故障物理内存地址及其对应的虚拟内存地址;冗余模块,用于通过所述内存的冗余机制将所述故障物理内存地址隔离,并获取新的物理内存地址;其中,所述新的物理内存地址的空间与所述故障物理内存地址的空间大小相等;数据备份模块,用于将所述虚拟内存地址对应的所述故障物理内存地址中的数据备份;映射模块,用于映射所述虚拟内存地址至所述新的物理内存地址,以用于将所述数据迁移至所述新的物理内存地址。
14.为解决上述技术问题,本技术还提供另一种内存故障处理装置,包括:存储器,用于存储计算机程序;处理器,用于执行所述计算机程序时实现上述所述的内存故障处理方法的步骤。
15.为解决上述技术问题,本技术还提供一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现上述所述的内存故障处理方法的步骤。
16.本技术所提供的内存故障处理方法,通过监测服务器的内存的故障信息,获取内存的冗余空间,判断冗余空间是否小于第一阈值;若否,根据故障信息获取故障物理内存地址及其对应的虚拟内存地址;通过内存的冗余机制将故障物理内存地址隔离,并获取新的物理内存地址;其中,新的物理内存地址的空间与故障物理内存地址的空间大小相等;将虚拟内存地址对应的故障物理内存地址中的数据备份,映射虚拟内存地址至新的物理内存地址,以用于将数据迁移至新的物理内存地址。由此可知,上述方案通过内存冗余机制将故障内存实现永久隔离,同时能够在操作系统运行过程中,通过改变虚拟内存映射位置将故障内存在软件层面隔离,不丢失故障内存中的数据;不但可以有效降低由于内存故障导致的
宕机率,而且可以有效减少不必要的内存更换,极大降低运行维护的成本。
17.此外,本技术实施例还提供了一种内存故障处理装置及计算机可读存储介质,效果同上。
附图说明
18.为了更清楚地说明本技术实施例,下面将对实施例中所需要使用的附图做简单的介绍,显而易见地,下面描述中的附图仅仅是本技术的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
19.图1为本技术实施例提供的一种内存故障处理方法的流程图;图2为本技术实施例提供的另一种内存故障处理方法的流程图;图3为本技术实施例提供的一种内存故障处理装置的结构示意图;图4为本技术实施例提供的另一种内存故障处理装置的结构示意图。
具体实施方式
20.下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本技术一部分实施例,而不是全部实施例。基于本技术中的实施例,本领域普通技术人员在没有做出创造性劳动前提下,所获得的所有其他实施例,都属于本技术保护范围。
21.本技术的核心是提供一种可靠的内存故障处理方法、装置及计算机可读存储介质。
22.为了使本技术领域的人员更好地理解本技术方案,下面结合附图和具体实施方式对本技术作进一步的详细说明。
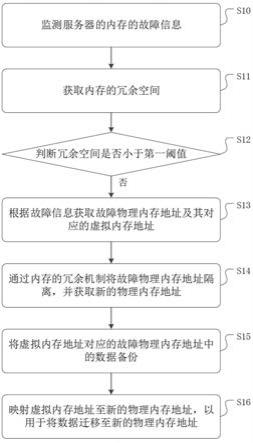
23.在服务器的运行使用中,服务器硬件故障诊断和故障预测是服务器运行维护领域的痛点也是技术难点。其中由内存引起的服务器故障是所有故障中占比最高的,因此如果能够有效诊断服务器内存故障,并且对故障进行技术隔离,便可以有效降低服务器故障。因此,本技术实施例提供了一种内存故障处理方法。图1为本技术实施例提供的一种内存故障处理方法的流程图。如图1所示,方法包括:s10:监测服务器的内存的故障信息,以确认内存发生故障。
24.s11:获取内存的冗余空间。
25.s12:判断冗余空间是否小于第一阈值;若否,进入步骤s13。
26.s13:根据故障信息获取故障物理内存地址及其对应的虚拟内存地址。
27.s14:通过内存的冗余机制将故障物理内存地址隔离,并获取新的物理内存地址;其中,新的物理内存地址的空间与故障物理内存地址的空间大小相等。
28.s15:将虚拟内存地址对应的故障物理内存地址中的数据备份。
29.s16:映射虚拟内存地址至新的物理内存地址,以用于将数据迁移至新的物理内存地址。
30.可以理解的是,在服务器运行过程中,内存可能会因为一些原因发生故障。其中,内存发生的故障分为两类,一类是可纠正错误(corrected error,ce),另一类错误是不可纠正错误(uncorrected error,uce)。发生ce,内存通过ecc机制可以自动进行纠正,但是过
多或者频繁的ce往往可能预示着uce的发生;而如果内存发生uce,一般会伴随服务器宕机的发生,属于服务器严重故障。所以发现ce后,要根据情况进行相应处理。因此在本实施例中,首先对内存的故障信息进行监测,通过发现作为故障信息的ce,跟进ce发生的情况采取相应的策略,来避免uce的发生。在本实施例中对于故障信息的监测方式不做限制,根据具体的实施情况而定。
31.在得到内存发生故障的信息后,对内存的冗余空间进行获取。可以理解的是,内存的生产厂商在生产内存时,为了防止内存的部分物理空间损坏导致内存无法使用,采用的方法是内存空间冗余。例如一个标称128m的内存颗粒,往往实际的可以使用的内存空间可能是130m;而多出来的2m便是内存的冗余空间。内存出厂之前,厂商会对内存进行全面的测试,发现正常物理内存的损坏区域,然后将通过内存固件地址编码的方式,将损坏的物理内存空间重定向到冗余物理内存空间相同大小的区域。这样便可以保证128m的空间都是可以使用的。需要注意的是,如果损坏的空间大于2m,则冗余已不够,则此内存必须废弃。因此为了确定发生故障的内存的冗余空间是否能够对故障内存进行冗余,在获取到内存的冗余空间后判断其是否小于第一阈值。本实施例中对于第一阈值不做限制,根据具体的实施情况而定。如果冗余空间不小于第一阈值,则确定该内存的冗余空间足够,可以进行后续的冗余操作。
32.在确定该内存的冗余空间足够之后,根据故障信息获取故障物理内存地址,及其对应的虚拟内存地址。需要注意的是,当前所有现代操作系统访问内存的访问并不是直接访问真实物理地址,操作系统对物理内存的管理是通过一种叫虚拟内存(vm)的机制来进行的。具体地,程序访问内存并不是真实的物理内存地址,而是操作系统通过中央处理器(central processing unit,cpu)的内存管理单元(memory management unit,mmu)地址转换单元进行转换的,vm与真实物理地址之间存在映射关系。操作系统会将内存划分为多个空间,划分给不同的程序来使用,应用程序通过虚拟内存地址空间来使用内存。因此,故障的内存的故障物理内存地址也存在其对应的虚拟内存地址。在本实施例中,对于故障内存地址和虚拟内存地址的获取方式不做限制,根据具体的实施情况而定。
33.进一步地,在得到故障物理内存地址后,需要通过内存的冗余机制将故障内存地址隔离,并获取新的物理内存地址。具体地,内存的冗余是通过封装后修复(post package repair,ppr)技术实现。这是一种内存修复手段,ppr技术可以把内存中损坏的部分行,用冗余的行代替,从而实现内存的冗余;新的物理内存地址的空间与故障物理内存地址的空间大小相等,这样才能存储故障物理内存地址的数据。同时,将上述获取到的虚拟内存地址对应的故障物理内存地址中的数据进行备份,防止故障物理内存地址中的数据丢失。最后将该虚拟内存地址映射至新的物理内存地址,以用于将备份好的故障物理内存地址中的数据迁移至新的物理内存地址中,最终实现对故障内存的处理。
34.本实施例中,通过监测服务器的内存的故障信息,获取内存的冗余空间,判断冗余空间是否小于第一阈值;若否,根据故障信息获取故障物理内存地址及其对应的虚拟内存地址;通过内存的冗余机制将故障物理内存地址隔离,并获取新的物理内存地址;其中,新的物理内存地址的空间与故障物理内存地址的空间大小相等;将虚拟内存地址对应的故障物理内存地址中的数据备份,映射虚拟内存地址至新的物理内存地址,以用于将数据迁移至新的物理内存地址。由此可知,上述方案通过内存冗余机制将故障内存实现永久隔离,同
时能够在操作系统运行过程中,通过改变虚拟内存映射位置将故障内存在软件层面隔离,不丢失故障内存中的数据;不但可以有效降低由于内存故障导致的宕机率,而且可以有效减少不必要的内存更换,极大降低运行维护的成本。
35.在上述实施例的基础上:作为一种优选的实施例,监测服务器的内存的故障信息包括:通过mca技术监测内存的故障信息,将故障信息记录在中断屏蔽控制寄存器中,并生成故障日志。
36.在上述实施例中,对于故障信息的监测方式不做限制,根据具体的实施情况而定。作为一种优选的实施例,本实施例中,通过mca技术监测内存的故障信息,将故障信息记录在中断屏蔽控制寄存器中,并生成故障日志。
37.需要注意的是,英特尔(intel)从奔腾4开始的cpu中增加了一种机制,称为硬件错误检测架构(machine check architecture,mca)。它用来检测硬件错误,比如系统总线错误、误差校正码(error correcting code,ecc)错误、奇偶校验错误等等。这套系统通过一定数量的特殊模块寄存器(model specific register,msr)来实现,这些msr分为两个部分,一部分用来进行设置,另一部分用来描述发生的硬件错误。mca技术架构中,将双列直插式存储模块(dual-inline-memory-modules,dimm)作为内存,这是一种奔腾cpu推出后出现的新型内存条,它提供了64位的数据通道。
38.通过mca技术,无论是发生ce还是发生uce,发生的故障详细信息都会记录到中断屏蔽控制寄存器(imc)当中。imc为mca架构的一组寄存器,可以用于存储故障的详细信息。如果内存发生ce故障,则cpu会基于mca技术架构上报该错误的详细信息。在linux系统中,操作系统同时会将该错误的详细信息记录到故障日志mcelog中,以用于后续的操作。
39.本实施例中,通过mca技术监测内存的故障信息,将故障信息记录在中断屏蔽控制寄存器中,并生成故障日志,从而实现了对故障信息的监测与保存。
40.在上述实施例的基础上:作为一种优选的实施例,监测服务器的内存的故障信息包括:判断故障信息的数量在第一预设时间内是否大于第二阈值;其中,故障信息的数量以第二预设时间为周期递减,第二预设时间小于第一预设时间;若是,则确认内存发生故障,进入到获取内存的冗余空间的步骤。
41.在具体实施中,监测服务器的内存的故障信息的过程中,可能会监测到一些可以纠正的或在允许范围内的内存故障,因此不能因为出现了故障信息就认定该内存发生了故障。具体地,监测服务器的内存的故障信息的过程中,判断故障信息的数量在第一预设时间内是否大于第二阈值,即判断故障信息的数量在一个时间段内的数量是否超过允许的故障数量;其中,故障信息的数量以第二预设时间周期递减,第二预设时间小于第一预设时间,即当出现一些可以纠正或在允许范围内的故障,故障信息的数量以一个时间周期进行递减,最终使其数量归零,不会触发内存故障处理。在本实施例中,对于第二阈值不做限制,根据具体的实施情况而定,对于第一预设时间和第二预设时间不做限制,根据具体的实施情况而定。当确定故障信息的数量在第一预设时间内大于第二阈值,则确定在第一预设时间内故障信息的数量超过允许范围,因此确定内存发生了故障,可以进入后续对内存故障进行处理的步骤。
42.本实施例中,通过判断故障信息的数量在第一预设时间内是否大于第二阈值;其中,故障信息的数量以第二预设时间为周期递减,第二预设时间小于第一预设时间;若是,则确认内存发生故障,进入到获取内存的冗余空间的步骤,实现了内存是否发生故障的准确判断。
43.在上述实施例的基础上:作为一种优选的实施例,根据故障信息获取故障物理内存地址及其对应的虚拟内存地址包括:解析中断屏蔽控制寄存器以获取到故障物理内存地址;根据故障日志通过内存管理单元获取故障物理内存地址对应的虚拟内存地址。
44.在上述实施例中,对于故障内存地址和虚拟内存地址的获取方式不做限制,根据具体的实施情况而定。作为一种优选的实施例,由于发生的故障详细信息都会记录到中断屏蔽控制寄存器(imc)当中,因此在本实施例中通过解析imc中的故障的详细信息获取到故障物理内存地址。由于在linux系统中,操作系统同时会将该错误的详细信息记录到故障日志mcelog中,同时操作系统对物理内存的管理是通过虚拟内存实现,因此根据故障日志通过mmu地址转换单元能够获取故障物理内存地址对应的虚拟内存地址。
45.本实施例中,通过解析中断屏蔽控制寄存器以获取到故障物理内存地址,并根据故障日志通过内存管理单元获取故障物理内存地址对应的虚拟内存地址,实现了故障物理内存地址和虚拟内存地址的获取,以便于后续更改映射地址。
46.图2为本技术实施例提供的另一种内存故障处理方法的流程图。如图2所示,在映射虚拟内存地址至新的物理内存地址之后,还包括:s17:标记故障物理内存地址。
47.s18:触发内存故障告警。
48.在具体实施中,对出现故障的物理内存地址在操作系统内核做一下标记,保证后面的应用程序不会分配到该物理内存,防止再次出现内存故障。
49.在标记故障物理内存地址之后,触发内存故障告警,以提示维修人员对故障内存进行维护。
50.如图2所示,在具体实施中,若判断冗余空间小于第一阈值,还包括:s19:输出提示更换内存的信息。
51.可以理解的是,当判断冗余空间小于第一阈值,则确认当前内存的故障空间大于内存的冗余空间,因此冗余空间不足以对故障内存空间进行冗余替换,此时该内存故障则无法处理,只能更换对该内存进行更换。因此当判断冗余空间小于第一阈值时,输出提示更换内存的信息,从而提示维修人员对故障内存进行更换。
52.在上述实施例中,对于内存故障处理方法进行了详细描述,本技术还提供内存故障处理装置对应的实施例。需要说明的是,本技术从两个角度对装置部分的实施例进行描述,一种是基于功能模块的角度,另一种是基于硬件结构的角度。
53.图3为本技术实施例提供的一种内存故障处理装置的结构示意图,如图3所示,内存故障处理装置包括:监测模块10,用于监测服务器的内存的故障信息,以确认内存发生故障。
54.第一获取模块11,用于获取内存的冗余空间。
55.判断模块12,用于判断冗余空间是否小于第一阈值;若否,触发第二获取模块。
56.第二获取模块13,用于根据故障信息获取故障物理内存地址及其对应的虚拟内存地址。
57.冗余模块14,用于通过内存的冗余机制将故障物理内存地址隔离,并获取新的物理内存地址;其中,新的物理内存地址的空间与故障物理内存地址的空间大小相等。
58.数据备份模块15,用于将虚拟内存地址对应的故障物理内存地址中的数据备份。
59.映射模块16,用于映射虚拟内存地址至新的物理内存地址,以用于将数据迁移至新的物理内存地址。
60.由于装置部分的实施例与方法部分的实施例相互对应,因此装置部分的实施例请参见方法部分的实施例的描述,这里暂不赘述。
61.图4为本技术实施例提供的另一种内存故障处理装置的结构示意图,如图4所示,内存故障处理装置包括:存储器20,用于存储计算机程序。
62.处理器21,用于执行计算机程序时实现如上述实施例中所提到的内存故障处理的方法的步骤。
63.本实施例提供的内存故障处理装置可以包括但不限于智能手机、平板电脑、笔记本电脑或台式电脑等。
64.其中,处理器21可以包括一个或多个处理核心,比如4核心处理器、8核心处理器等。处理器21可以采用数字信号处理器(digital signal processor,dsp)、现场可编程门阵列(field-programmable gate array,fpga)、可编程逻辑阵列(programmable logic array,pla)中的至少一种硬件形式来实现。处理器21也可以包括主处理器和协处理器,主处理器是用于对在唤醒状态下的数据进行处理的处理器,也称 中央处理器(central processing unit,cpu);协处理器是用于对在待机状态下的数据进行处理的低功耗处理器。在一些实施例中,处理器21可以在集成有图像处理器(graphics processing unit,gpu),gpu用于负责显示屏所需要显示的内容的渲染和绘制。一些实施例中,处理器21还可以包括人工智能(artificial intelligence,ai)处理器,该ai处理器用于处理有关机器学习的计算操作。
65.存储器20可以包括一个或多个计算机可读存储介质,该计算机可读存储介质可以是非暂态的。存储器20还可包括高速随机存取存储器,以及非易失性存储器,比如一个或多个磁盘存储设备、闪存存储设备。本实施例中,存储器20至少用于存储以下计算机程序201,其中,该计算机程序被处理器21加载并执行之后,能够实现前述任一实施例公开的内存故障处理方法的相关步骤。另外,存储器20所存储的资源还可以包括操作系统202和数据203等,存储方式可以是短暂存储或者永久存储。其中,操作系统202可以包括windows、unix、linux等。数据203可以包括但不限于内存故障处理方法涉及到的数据。
66.在一些实施例中,内存故障处理装置还可包括有显示屏22、输入输出接口23、通信接口24、电源25以及通信总线26。
67.本领域技术人员可以理解,图4中示出的结构并不构成对内存故障处理装置的限定,可以包括比图示更多或更少的组件。
68.最后,本技术还提供一种计算机可读存储介质对应的实施例。计算机可读存储介
质上存储有计算机程序,计算机程序被处理器执行时实现如上述方法实施例中记载的步骤。
69.可以理解的是,如果上述实施例中的方法以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本技术的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,执行本技术各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(read-only memory,rom)、随机存取存储器(random access memory,ram)、磁碟或者光盘等各种可以存储程序代码的介质。
70.以上对本技术所提供的一种内存故障处理方法、装置及计算机可读存储介质进行了详细介绍。说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。应当指出,对于本技术领域的普通技术人员来说,在不脱离本技术原理的前提下,还可以对本技术进行若干改进和修饰,这些改进和修饰也落入本技术权利要求的保护范围内。
71.还需要说明的是,在本说明书中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1