文本识别方法、装置、设备及存储介质与流程
本发明涉及计算机,尤其涉及一种文本识别方法、装置、设备、及存储介质。
背景技术:
1、随着ai技术的进步和应用的深入,基于机器学习的视觉、图像、语音、语言分析相关的技术核心效果、产品化成熟度、业务应用模式等方面都已达到了实用化程度。目前,ai技术已经广泛应用于电信运营商、银行、保险、证券、电力、交通等行业,已经成为现场业务合规、远程客户服务等场景下必备的技术支撑,也是国内各大保险公司的关注焦点。
2、智能双录质检(intelligent dual-recording system,简称idrs)针对保险、银行等金融领域的双录(录音、录像)场景合规性要求,利用ai技术实现对销售过程中各类关键动作、语音、证件的检测,以及关键角色的面部追踪,实现对销售过程的智能化监控。其中,智能双录质检提供的app终端检测能力,可以让绝大部分销售合规检测在现场完成,实时发现问题、实时提示、实时纠正,极大地提升了销售的友好度和一次性通过率。
3、在对智能双录质检获取到的音频文件进行流程识别时,目前一般是先通过asr(automatic speech recognition,自动语音识别技术)算法对音频文件进行语音识别,得到音频识别文本,然后对音频识别文本与标准的流程话术文本进行比对识别,以得到流程识别结果。由于当下人工智能领域asr算法在不同场景下转换出来的文本还不是很精准,所以流程匹配时就面临很大的难度。目前通常采用文本相似度算法进行文本的比对识别,然而,现有的文本相似度算法,其比对识别维度较为单一,从而导致文本识别结果的准确性较差。
技术实现思路
1、本发明的主要目的在于提供一种文本识别方法、装置、设备及存储介质,旨在解决现有的文本识别方法的准确性较差的问题。
2、为实现上述目的,本发明提供一种文本识别方法,所述文本识别方法包括:
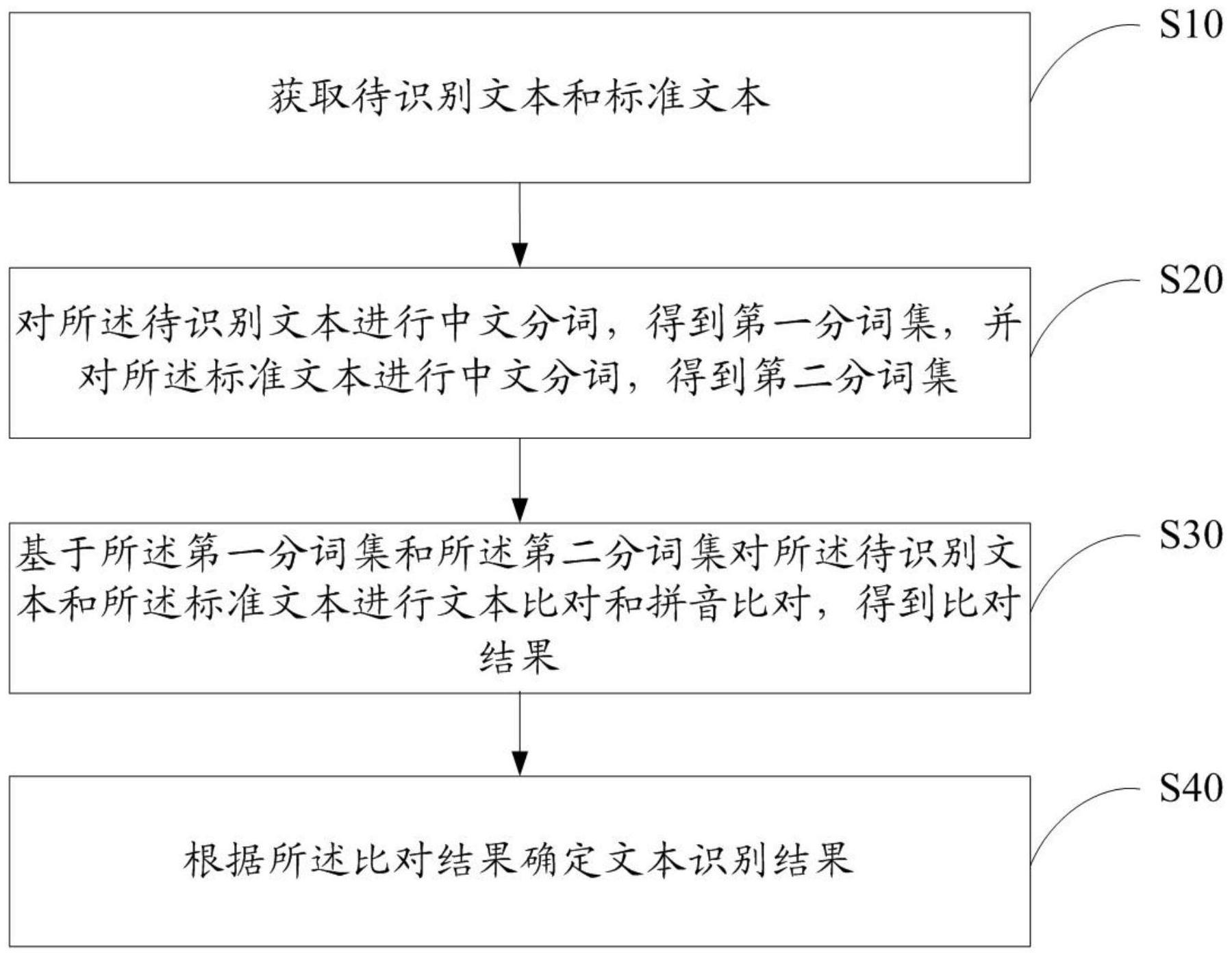
3、获取待识别文本和标准文本;
4、对所述待识别文本进行中文分词,得到第一分词集,并对所述标准文本进行中文分词,得到第二分词集;
5、基于所述第一分词集和所述第二分词集对所述待识别文本和所述标准文本进行文本比对和拼音比对,得到比对结果;
6、根据所述比对结果确定文本识别结果。
7、优选地,所述基于所述第一分词集和所述第二分词集对所述待识别文本和所述标准文本进行文本比对和拼音比对,得到比对结果的步骤包括:
8、获取所述第一分词集和所述第二分词集之间的第一交集;
9、获取所述第一分词集与所述第二分词集的第一差集,并获取所述第二分词集与所述第一分词集的第二差集;
10、将所述第一差集中的中文词转换成拼音,得到第一拼音集,并将所述第二差集中的中文词转换成拼音,得到第二拼音集;
11、获取所述第一拼音集和所述第二拼音集之间的第二交集;
12、根据所述第一分词集、所述第一交集和所述第二交集的元素数量,计算得到文本相似度。
13、优选地,所述根据所述第一分词集、所述第一交集和所述第二交集的元素数量,计算得到文本相似度的步骤之前,所述文本识别方法还包括:
14、获取所述第一拼音集与所述第二拼音集的第三差集,并获取所述第二拼音集与所述第一拼音集的第四差集;
15、对所述第三差集进行相似音匹配,得到第一相似音集,并对所述第四差集进行相似音匹配,得到第二相似音集;
16、获取所述第一相似音集和所述第二相似音集之间的第三交集;
17、所述根据所述第一分词集、所述第一交集和所述第二交集的元素数量,计算得到文本相似度的步骤包括:
18、根据所述第一分词集、所述第一交集、所述第二交集和所述第三交集的元素数量,计算得到文本相似度。
19、优选地,所述根据所述比对结果确定文本识别结果的步骤包括:
20、检测所述文本相似度是否大于预设值;
21、若所述文本相似度大于预设值,则判定所述待识别文本与所述标准文本相似;
22、若所述文本相似度小于或等于预设值,则判定所述待识别文本与所述标准文本不相似。
23、优选地,所述对所述待识别文本进行中文分词,得到第一分词集,并对所述标准文本进行中文分词,得到第二分词集的步骤包括:
24、通过ansj中文分词器对所述待识别文本进行中文分词,得到第一分词集;
25、通过所述ansj中文分词器对所述标准文本进行中文分词,得到第二分词集。
26、优选地,所述通过ansj中文分词器对所述待识别文本进行中文分词,得到第一分词集的步骤包括:
27、检测ansj中文分词器中是否存在自定义词库;
28、若不存在自定义词库,则通过所述ansj中文分词器加载预设词库对所述待识别文本进行中文分词,得到第一分词集;
29、若存在自定义词库,则通过所述ansj中文分词器加载所述预设词库和所述自定义词库对所述待识别文本进行中文分词,得到第一分词集。
30、此外,为实现上述目的,本发明还提供一种文本识别装置,所述文本识别装置包括:
31、获取模块,用于获取待识别文本和标准文本;
32、分词模块,用于对所述待识别文本进行中文分词,得到第一分词集,并对所述标准文本进行中文分词,得到第二分词集;
33、比对模块,用于基于所述第一分词集和所述第二分词集对所述待识别文本和所述标准文本进行文本比对和拼音比对,得到比对结果;
34、识别模块,用于根据所述比对结果确定文本识别结果。
35、此外,为实现上述目的,本发明还提供一种文本识别设备,所述文本识别设备包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述计算机程序被所述处理器执行时实现如上所述的文本识别方法的步骤。
36、此外,为实现上述目的,本发明还提供一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现如上所述的文本识别方法的步骤。
37、此外,为实现上述目的,本发明还提供一种计算机程序产品,包括计算机程序,所述计算机程序被处理器执行时实现如上所述的文本识别方法的步骤。
38、本发明提供一种文本识别方法、装置、设备及存储介质,先获取待识别文本和标准文本,然后,对待识别文本进行中文分词,得到第一分词集,并对标准文本进行中文分词,得到第二分词集;进而,基于第一分词集和第二分词集对待识别文本和标准文本进行文本比对和拼音比对,得到比对结果;最后根据比对结果确定文本识别结果。本发明实施例中,通过文本比对和拼音比对相结合的方式进行文本识别,增加了比对维度,从而可增加文本识别结果的准确性。此外,现有的文本相似度算法,大多不能适用于所有行业,对不同的行业需要事先收集此行业的专业术语,然后集中训练,最终形成算法模型,而本发明中实施例采用中文分词+文本比对和拼音比对的方式,可适用于各种行业的文档,且无须进行训练,更加方便快捷。
- 还没有人留言评论。精彩留言会获得点赞!