一种基于AIS数据的船舶航线提取与轨迹分类方法
一种基于ais数据的船舶航线提取与轨迹分类方法
技术领域
1.本发明涉及航运数据处理领域,特别涉及一种基于ais(自动识别系统)数据的船舶航线提取与轨迹分类方法。
背景技术:
2.随着船运在物流体系中占比的不断增大,海上运输的安全需求不断增长,为此国际海事组织提出安装ais系统。ais数据包括船舶实时的动态与静态信息,可以很好的描述船舶的运行状态。对于一个航运港口而言,存在多条来从不同方位驶入的航线,不同的航线之间有着不同的水文条件与各白的特性。港口和航运代理方面若能准确判断船舶的航线就能更好的为该船舶提供更好的个性化定制业务(如:更准确的到港时间预测,轨迹异常检测等),提高港口的运营效率、增强航运的安全性。
3.目前计算港口驶进存在的航线主要是通过将所有靠港船舶的完整轨迹进行聚类操作所得,这种方法得到的航线易受异常轨迹的干扰且计算成本较高。本发明提出了一种航线提取与轨迹分类的新思路,有效提高了算法对异常轨迹的鲁棒性,大大降低运算量。
技术实现要素:
4.本发明提供了一种船舶航线提取与轨迹分类方法。该方法在航线提取时能够有效降低异常轨迹的干扰,并通过得到的航线对船舶轨迹进行更精准的分类。
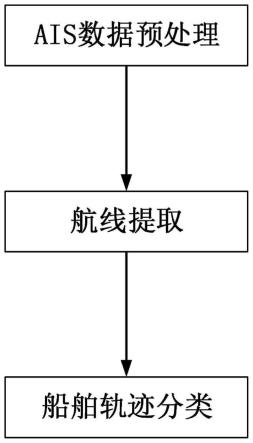
5.一种基于ais数据的船舶航线提取与轨迹分类方法,步骤如下:
6.s1:ais数据预处理,从ais数据中提取山有效的数据并进行进行降采样处理。
7.s2:航线提取,对得到的轨迹进行进一步处理尽可能多的减少轨迹点数,保留精简有效的路标点,最后连接路标点得到航线。
8.s3:轨迹分类,计算待分类的轨迹与所有得到的航线的距离实现轨迹的分类。
9.进一步的,步骤(1)具体方法如下:
10.1.1数据筛选:从所有的ais数据中筛选出目的地为目标港口的指定类型船舶ais数据,得到所有仅由驶入该港口船只产尘的数据。
11.1.2轨迹提取:将筛选后的ais数据按照mmsi字段重构为轨迹数据。
12.1.3轨迹分割:把相同mmsi字段的轨迹数据按timestamp进行差分,在差分值大于设定差分值阈值处将轨迹分割,确保每一条轨迹数据为同一次山航的数据。
13.1.4完整性检查:检查所有轨迹最后一个位置到港口的距离是否小于设定距离阈值,以及检查每条轨迹的持续时间是否长于设定时间,不满足这两个条件的轨迹将被舍弃。
14.1.5降采样:对检查后的轨迹进行降采样操作把轨迹点间的间隔扩大到等间隔的分钟级别,对于降采样后对应时间戳上缺失的ais信息采用线性插值方式补全。
15.进一步的,步骤(2)具体方法如下:
16.2.1轨迹压缩:采用dp压缩算法对轨迹进行压缩以减小轨迹点在空间上的冗余度。经过压缩后的轨迹点称之为关键点。
17.2.2重新计算cog信息:cog表示船舶当前时间的对地航向,通过关键点与后一个关键点的位置关系重新计算点的cog信息,使其能够正确描述一条轨迹中,当前点与后一个点的方位信息。
18.2.3关键点聚类:
19.经过步骤2.2后得到的是所有历史轨迹中的关键点,包括大量位置相近甚至重叠同时转向几乎相同的点以及一些开常轨迹中方向明显错误的点。通过基于滑动窗口的关键点聚类方法删除信息有误的点同时找山所有位置与转向部相近的点,开用路标点来表示它们。
20.具体步骤如下:
21.2.3.1空间位置聚类:通过滑动窗口扫描对所有落入到扫描区间内的关键点的位置进行dbscan聚类,找到点的集群。
22.2.3.2转向角cog聚类:在得到所有的集群上再依次进行对cog的聚类,并计算每个同一聚类中的所有关键点经纬度平均值以及cog的中位数作为路标点的经度lon,纬度lat,对地航向cog,用路标点来直接表示该聚类中的所有点。
23.2.4航线提取:从远端手动选择一个路标点作为出发点,在每个路标cog所指示的方向上寻找下一个路标点。在寻找下一个路标点时计算自定义加权距离函数,综合考量了路标点之间的距离以及方向变化的程度,选择加权距离最小的路标点作为下一个路标点,路标点的连接实现航线的提取。
24.进一步的,步骤(3)具体方法如下:
25.获取实时的船舶轨迹,将实时的船舶轨迹数据依次与得到的所有航线计算directed hausdorff距离,距离越近相似度越高,相似度最高的航线就是该条轨迹最有可能正在行驶的航线。
26.进一步的,步骤1.1数据筛选时,同时删除明显错误的信息,所述的明显错误的信息包括存在位置在目标海域以外,速度、船舶长度宽度以及吃水深度在目标船舶类型的正常范围以外。
27.进一步的,步骤2.1具体方法如下:
28.对轨迹进行dp(douglas-peucker)轨迹压缩算法:轨迹在经过降采样轨迹点间150秒的时间粒度上还存在着较大空间上的冗余度,对轨迹进行dp轨迹压缩算法只保留轨迹中较为关键的节点实现进一步减小冗余。
29.dp轨迹压缩算法的基本原理为:假设一条轨迹由点pa出发到pb终止,中间的点集记为p
ab
,dp压缩算法将轨迹的首尾点即pa和pb直接作为压缩后的关键点,连接首尾点得到线段l
ab
,计算点集p
ab
中所有的点到线段l
ab
的垂直距离,从点集中取得一个垂直距离最大的点记作p
max
即:
[0030][0031]
式中d(p,l
ab
)为点p到直线l
ab
的垂直距离,此时分为两种情况:1).若d(p
max
,l
ab
)<ε,ε为按实际情况提前设置的压缩阈值,则轨迹中点pa与pb之间的全部点都将被删除,当前轨迹的压缩终止;2).若d(p
max
,l
ab
)≥ε,则将p
max
作为压缩后的关键点写入到压缩后的轨迹中,同时在p
max
处将当前轨迹分割为两条轨迹。并分别对着两段轨迹进行dp压缩,直到所有的轨迹都因情况1)而终止时整条轨迹的压缩过程结束,再对压缩后得到的关键点集合按照
timestamp字段进行去重并排序,得到原轨迹压缩后的轨迹,此时压缩后的轨迹中关键点的数目会远远小于原始轨迹中的点数。显而易见压缩阈值ε的选取对dp压缩的结果会由决定性的影响,压缩阈值要综合考虑压缩率与轨迹压缩前后的相似度谨慎选择。其中压缩率是指轨迹压缩后删除的点占原来总点数的百分比用下式表示:
[0032][0033]
其中t
cp
,t
org
(ε)分别表示原轨迹和以ε为阈值压缩后的轨迹,运算符|*|表示取轨迹中的点数。提出一种基于损失区域的方法来度量压缩前后的相似度,用t
ref
来表示某较大阈值下进行dp压缩得到的轨迹,a
ref
为t
ref
与t
org
所围区域的面积,a(ε)表示以ε为阈值对轨迹进行压缩得到的压缩后轨迹t
cp
(ε)与原始轨迹t
org
所围部分的面积,轨迹压缩前后的相似度可以由下式计算:
[0034][0035]
进一步的,所述的基于滑动窗口的关键点聚类方法具体如下:
[0036]
经度方向上的滑动窗口聚类,定义一个带状滑动窗口沿着数据区域经度增加的方向移动,对落入到滑动窗口中的所有关键点进行dbscan聚类,可能会存在多有关键点簇分布于滑动窗口的不同位置上,通过dbscan聚类实现对干扰点的滤除,当活动窗口的移动覆盖过整个区域时在经度方向上的扫描结束,通过相同方法再进行纬度方向上的扫描,得到所有存在的关键点集群。滑动窗口的宽度以及滑动的步长根据实际情况选取。
[0037]
进一步的,2.4航线提取具体步骤如下:
[0038]
1)手动选择航线的远端出发点,将出发点当作一个当前点1)手动选择航线的远端出发点,将出发点当作一个当前点
[0039]
2)落入以当前点为中心的一个长为四个经度,高为两个纬度的矩形区域pm内的所有其他路标点为候选点即有其他路标点为候选点即
[0040]
3)通过下式计算当前点wm与所有候选点的加权距离:
[0041][0042]
其中pn∈pm,dn(pn,wm)为候选点pn到当前点wm的距离,δ(pn,wm)为当前点的变化到候选点pn方向上所需要的角度变化值,d
ref
与δ
ref
是两个归一化常数,根据案例灵活选取;
[0043]
4)下一个路标点选择使得该加权距离值最小的点即:
[0044][0045]
5)将w
m+1
作为当前点再继续通过步骤2)、3)、4)直到口标港口附近,得到一连串的路标点,即可得到一条航线,选择多个不同的起点就可以得到多条航线。
[0046]
本发明有益效果如下:
[0047]
本发明提供了一种在未知航线海域下通过历史数据提取航线并用所得到的航线对船舶轨迹进行实时分类的方法。该方法对能克服开常轨迹带来的影响,同时计算成本也很小。
附图说明
[0048]
图1为本发明基于ais数据的船舶航线提取与轨迹分类方法总体流程图;
[0049]
图2为ais数据预处理流程图;
[0050]
图3为航线提取部分的流程图;
[0051]
图4为本发明提出的基于区域的轨迹相似度度量示意图;
[0052]
图5为不同压缩阈值下的压缩率与相似度曲线图;
[0053]
图6为本发明提出的基于滑动窗口的聚类示意图;
[0054]
图7为本发明一项实施例中提取得到的航线。
具体实施方式
[0055]
为使本发明实施例的目的、技术方案和优点更加明确,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚完整的描述,显然所描述的发明实施例是本发明一部分的实施例,而不是全部的实施例,基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,部属于本发明保护的范围。
[0056]
本发明实施例中所用到的ais数据集来自dma(danish maritime authority)提供的历史ais数据,dma提供的历史ais数据以“*.csv”格式提供,包含26个字段,包括船舶识别信息(如mmsi)、航海相关信息(,lon,lat,cog)以及船舶航次信息(如destination),下表为实施例所用到的几个主要ais字段含义:
[0057][0058][0059]
本发明提供的一种基于ais数据的船舶航线提取与轨迹分类方法如图1所示主要有二个部分构成,首先对ais数据进行预处理确定目标海域内的研究对象,然后在目标海域上进行航线的提取,最后根据得到的航线实现对实时船舶轨迹的分类识别工作。具体实施步骤如下:
[0060]
s1:ais数据预处理从原始数据中进行初步的数据清洗删除明显错误的信息并聚焦到目标海域上的数据,经过预处理部分将得到完整的经过目标海域同时目的地为目标港口的完整轨迹(在本实施例中为丹麦skagen港口附近的海域)。如图2所示该部分的具体实
施步骤为:
[0061]
1.1数据筛选:从所有的ais数据中根据destination、ship type、latitude、longitude四个字段筛选出目的地为目标港口经过目标海域的指定类型船舶(在本实施例中为长度大于180米的大型油轮)的所有ais数据。同时删除明显错误的信息,如存在位置在目标海域以外,速度、船舶长度宽度以及吃水深度在目标船舶类型的正常范围以外。
[0062]
1.2轨迹提取:由于ais数据是离散的信息,原数据为不同时刻不同船只的状态(经纬度、速度、转向等)每条数据之间无任何关联。需要把离散的数据联系起来称为完整的轨迹。为此找山ais数据中所有的mmsi,将ais数据按照mmsi进行分组,mmsi相同的数据来自同一艘船舶,将其按照timestamp字段进行排序并去重,得到该船的轨迹数据。但此时得到的数据可能包括该船多次山航的轨迹。
[0063]
1.3轨迹分割:轨迹分割目的是将一艘船的多条轨迹分割不,具体做法是对同一船舶的轨迹数据按timestamp字段进行差分操作,差分值表示两次汇报ais数据的时间间隔,间隔在2小时内认为是同一次山航的轨迹,当间隔大于2小时时,以该时刻为分界,该时刻之前的数据和该时刻之后的数据(包括该时刻)作为两次不同山航记录将轨迹分为两段,经过轨迹分割操作后能确保每条轨迹中的数据都是同一次山航产生的。
[0064]
1.4轨迹有效性检查:对所得到的每一条轨迹进行有效性的检查,一方面检查该轨迹的持续时间是否足够长,以6小时作为阈值,持续时间小于6小时的轨迹将被删除;另一方面检查轨迹末端所在地理位置是否离目标港口足够近,若这个距离人于10千米该轨迹也会被删除。最后仅保留持续时间大于6小时同时末端离港口距离小于10千米的轨迹。
[0065]
1.5降采样:轨迹有效性检查后的轨迹保持在最初的时间粒度上,也就是几秒的量级。由于船只在几秒钟内不会移动很远,所以在如此短的时间间隔内,状态的变化往往很小。这意味着轨迹数据中存在较高的冗余,为进一步减少冗余,将每个轨迹降采样,使同轨迹中每两个在时间上相邻的轨迹点之间的时间间隔为150秒。对于每个采样时刻上的ais信息采用线性插值方式补全,具体的线性插值方式表述为下式:
[0066]
t
i+1
=ti+150
[0067][0068][0069]
式中ti为上一个插入点的时间戳,t
i+1
为后一个插入点的时间戳它们间隔为150秒,loni和lati为需要求的插值时刻的经度和纬度值lona,lata,lonb,latb分别表示插值时刻前后两条数据的经纬度值。需要注意的是在本发明的后续操作步骤中只需要用到时间戳和经纬度以及转向四个字段,而转向角在后续步骤还需要单独重新计算因此在线性插值中只涉及到了时间戳与经纬度的插值而不对其他字段进行处理。
[0070]
s2:提取山所有历史轨迹中的点构成一个关键点集合,从关键点集中分析整块海域的航线分布情况,从中提取山存在的航线信息。如图3所示具体有如下步骤:
[0071]
2.1对轨迹进行dp(douglas-peucker)轨迹压缩算法:因为船舶航行速度缓慢的特点带来一个好处就是短时间内的运动状态改变不会对整体轨迹的形态上产生较大的影响,所以轨迹在经过降采样轨迹点间150秒的时间粒度上还存在着较大空间上的冗余度,对轨
迹进行dp轨迹压缩算法只保留轨迹中较为关键的节点实现进一步减小冗余。具体而言dp轨迹压缩算法的基本原理为:假设一条轨迹由点pa出发到pb终止,中间的点集记为p
ab
,dp压缩算法将轨迹的首尾点即pa和pb直接作为压缩后的关键点,连接首尾点得到线段l
ab
,计算点集p
ab
中所有的点到线段l
ab
的垂直距离,从点集中取得一个垂直距离最大的点记作p
max
即:
[0072][0073]
式中d(p,l
ab
)为点p到直线l
ab
的垂直距离,此时分为两种情况:1).若d(p
max
,l
ab
)<ε(ε为按实际情况提前设置的压缩阈值),则轨迹中点pa与pb之间的全部点都将被删除,当前轨迹的压缩终止;2).若d(p
max
,l
ab
)≥ε,则将p
max
作为压缩后的关键点写入到压缩后的轨迹中,同时在p
max
处将当前轨迹分割为两条轨迹。并分别对着两段轨迹进行dp压缩,直到所有的轨迹部因情况1)而终止时整条轨迹的压缩过程结束,再对压缩后得到的关键点集合按照timestamp字段进行去重并排序,得到原轨迹压缩后的轨迹,此时压缩后的轨迹中关键点的数目会远远小于原始轨迹中的点数。显而易见压缩阈值ε的选取对dp压缩的结果会由决定性的影响,压缩阈值要综合考虑压缩率与轨迹压缩前后的相似度谨慎选择。其中压缩率是指轨迹压缩后删除的点占原来总点数的百分比用下式表示:
[0074][0075]
其中t
cp
,t
org
(ε)分别表示原轨迹和以ε为阈值压缩后的轨迹,运算符|*|表示取轨迹中的点数。另外由于目前的轨迹相似度衡量算法不适用与当前场景下压缩前后轨迹相似度的计算,为此我们提出一种基于损失区域的方法来度量压缩前后的相似度,如图4所示用t
ref
来表示某较人阈值下进行dp压缩得到的轨迹,a
ref
为t
ref
与t
org
所围区域的面积,a(ε)表示以ε为阈值对轨迹进行压缩得到的压缩后轨迹t
cp
(ε)与原始轨迹t
org
所围部分的面积,轨迹压缩前后的相似度可以由下式计算:
[0076][0077]
在选择压缩阈值时事前选取一个较大的阈值作为参考,然后再分别设置多个阈值进行试验,计算山相似度与压缩率并绘制一条相似度与压缩率的曲线如图5所示,在本实施例中参考阈值选取的是10千米,图5中曲线上的每个点表示不同是阈值从左到右依次是100m,200m,300m,...,1500m,2000m,2500m,...,5000m。根据曲线的变化情况本实施例中最终选择压缩阈值ε=500m。另外需要注意压缩后轨迹中的点在后续的操作中称之为关键点。
[0078]
2.2重新计算关键点cog信息:在经过步骤1.5.插值操作与步骤2.1.dp压缩后原始ais数据中的cog信息不再准确捕捉压缩轨迹中当前关键点到下一个关键点的方向,需要在新轨迹上重新计算点与点之间的cog信息,使其能够正确描述方位信息。具体实现为在每条轨迹上遍历相邻的关键点取两点的经纬度信息,运用vincenty公式计算后一个关键点对前一个关键点的前向角度将其作为前一个关键点的cog进行更新,由于利用vincenty公式来求已知经纬度的两个位置的前向角与后向角过程较为繁琐,在此不再赘述。重新计算cog之后的每个关键点用一个元组(λi,φi,θi)来表示,其中λi,φi,θi分别为该关键点的经度纬度与cog。
[0079]
2.3关键点聚类:此时的每一个关键点都蕴含了海域内存在的航线信息,在关键点
越多的地方航线信息就越丰富。但是关键点过多也会影响到后续航线的判断同时数量越多干扰点也就越多。通过dbscan聚类算法进一步减少关键点的点数同时保留关键信息,具体山以下两个步骤实现:
[0080]
2.3.1空间位置聚类:对空间位置的聚类指根据关键点的(λi,φi)进行聚类。将结合图6解释基于滑动窗口的关键点聚类方法,图6为经度方向上的滑动窗口聚类,定义一个宽度为0.1度的带状滑动窗口沿着数据区域经度增加的方向移动,每次移动的距离也为0.1度,对落入到滑动窗口中的所有关键点进行dbscan聚类,可能会存在多有关键点簇分布于滑动窗口的不同位置上(如图6中的圆圈所示),通过dbscan聚类可以实现对干扰点的滤除,当活动窗口的移动覆盖过整个区域时在经度方向上的扫描结束,通过相同方法再进行纬度方向上的扫描,得到所有存在的关键点集群。
[0081]
2.3.2转向角cog聚类:经过步骤2.3.1后已经基本能够得到航线的位置分布信息,距离航线提取还需要关键点的θ即cog信息。为此该步骤将对2.3.1得到的关键地集群中再对关键点的θ进行dbscan聚类操作。一方面滤除存在干扰的θ,一方面是从集群中计算一个点(λi,φi,θi)来替代整个集群的点,这个点称为路标点,记为路标点的经纬度为整个集群中所有关键点经纬度的平均,路标点的转向信息θ为整个集群中所有关键点θ的中位数。经过步骤2.3.1和2.3.2后绝大部分异常点都被删除同时也将关键点的数量缩小了一个数量级得到了数量较少且蕴含航线资料更加清晰的路标点。
[0082]
2.4航线提取:航线提取是根据路标点的经纬度与转向角寻找下一个距离最近的路标点开连接成为最终的航线。具体而言航线提取包括以下步骤:
[0083]
1)手动选择航线的远端山发点,将出发点当作一个当前点1)手动选择航线的远端山发点,将出发点当作一个当前点
[0084]
2)落入以当前点为中心的一个矩形区域pm(长为四个经度,高为两个纬度)内的所有其他路标点为候选点即有其他路标点为候选点即
[0085]
3)通过下式计算当前点wm与所有候选点的加权距离:
[0086][0087]
其中pn∈pm,dn(pn,wm)为候选点pn到当前点wm的距离,δ(pn,wm)为当前点的变化到候选点pn方向上所需要的角度变化值,d
ref
与δ
ref
是两个归一化常数,根据案例灵活选取;
[0088]
4)下一个路标点选择使得该加权距离值最小的点即:
[0089][0090]
5)将w
m+1
作为当前点再继续通过步骤2)、3)、4)直到目标港口附近,得到一连串的路标点,即可得到一条航线,选择多个不同的起点就可以得到多条航线,图7为本实施例提取得到的八条航线。
[0091]
s3:轨迹分类:将待分类的轨迹输入(支持实时轨迹数据),计算输入的轨迹与每一条得到的航线的directed hausdorff距离。距离越近则说明该轨迹与这条航线的相似度越高,而相似度最高的航线就是该条轨迹正在行驶的航线,加以输出实现轨迹的分类。
[0092]
最后需要说明的是以上所述仅为本发明的较佳实施例,仅仅用于说明本发明的技
术方案,并非用于限定本发明的保护范围。对于本领域普通技术人员而言,在不脱离本发明精神和实质的情况下,可以做出各种变型和改进,这些变型和改进也视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1