基于几何感知的深度学习多视角图超分辨率方法
1.本发明属于数字图像智能处理技术领域,具体涉及一种超分辨率的方法,更具体地说,涉 及一种基于几何感知的深度学习多视角图超分辨率方法。
背景技术:
2.超分辨率是从观测到的低分辨率图像重建出相应的高分辨率图像的任务。超分辨率在监控 设备、卫星图像和医学影像等领域都有重要的应用价值。
3.高分辨率图片不仅大大改善了用户视觉体验,而且节省了存储空间和网络传输带宽。在虚 拟现实、街道视图、比赛直播等多视图多媒体应用中,人们往往需要在高分辨率多视图图片和 存储空间、网络带宽间进行权衡,因此多视图超分辨率可以有效解决只能传输低分辨率图片的 问题,具有重要研究价值。
4.超分辨率已经被广泛研究,并且学术和工业界已经提出了许多超分辨率的方法。近年来, 随着卷积超分辨率神经网络srcnn
1.的提出,基于神经网络的超分辨率方法已远远超过传统 方法,成为了超分辨率方法的主流。
5.图像超分辨率是最早提出的超分辨率任务之一,一些方法
[2-4]
通过设计精巧的模型结构从 数据集中学习图像的高频细节,另一些方法
[5]
尝试使用自参考的方式去寻找重复的纹理图案来 帮助超分辨率。然而,由于下采样的低分辨率图像中高频纹理信息被破坏,图像超分辨率很难 恢复高分辨率纹理细节。为了直接向网络提供有用的高频纹理细节,许多基于参考的图像超分 辨方法
[6-7]
试图在参考图像内寻找跨尺度重复出现的小块。由于视频有时间维度,视频超分辨 率比图像超分辨率具有更多相关的高频细节信息。他们利用光流
[8]
或可变形卷积
[9]
进行显式或 隐式视频帧对齐来进行超分辨率。此外,一些视频超分辨率方法
[10]
利用递归神经网络来获得 远距离视频帧的高频纹理信息。
技术实现要素:
[0006]
为了克服现有技术的不足,本发明的目的在于提供一种基于几何感知的深度学习多视角图 超分辨率方法。通过利用几何信息对同一场景下的所有多视角图的高频纹理信息进行提取和利 用,以提升超分辨率的结果质量。
[0007]
本发明提供的基于几何感知的深度学习多视角图超分辨率方法,具体步骤为:
[0008]
(1)将同一个多视角场景里面所有多视角图片及其对应的深度图、相机内外参数输入到 参考图片合成网络里,参考图片合成网络利用场景几何信息进行图像和深度图对齐;
[0009]
(2)参考图片合成网络利用步骤(1)中获得的距离几何信息,提取对齐图片里的高频细 节,来合成每张视角图片的多张多视角参考图和多张相邻视角参考图;
[0010]
(3)训练参考超分辨率网络,用步骤(2)中合成的所有参考图作为辅助,对低分辨率输 入视角图进行超分。
[0011]
进一步的,步骤(1)中,所述参考图片合成网络利用场景几何信息进行图像和深度
图对 齐,根据图2所示,具体做法为:参考图片合成网络先将深度图上采样到超分辨率目标倍数, 本方法的超分辨率上采样目标倍数为4倍,同时将相机内外参数依据超分辨率目标倍数进行修 改;然后使用这些几何信息通过单应性变换将所有多视角图片、深度图对齐到待超分的视角图 片、深度图,其对齐原理如下公式:
[0012][0013][0014][0015]
其含义为,将第i张多视角图片、深度图对齐到待超分辨率的视角图片、深度图,下标i、 t和i
→
t分别表示第i张多视角数据、待要超分辨率视角数据和将第i张多视角数据对齐到待要 超分辨率视角,上标lr和hr分别表示数据为低分辨率和高分辨率,d、p和i分别表示多视角深 度图、多视角相机内外参数和多视角图片,upsample表示上采样操作,w表示单应性变换。
[0016]
进一步的,步骤(1)中,所述单应性变换,其公式如下:
[0017][0018]
其中,下标i、t分别表示第i张多视角数据和待要超分辨率视角 数据,pi和p
t
是第i张多视角数据和待要超分辨率视角数据中相对应像素的坐标。k、r和t分别 是相机内参,相机外参旋转矩阵,相机外参平移矩阵。
[0019]
步骤(1)中的有益效果在于参考图片合成网络显式利用场景几何信息来通过单应性变换 进行多视图图片间的对齐。现今的图片超分辨率和视频超分辨率的方法没有利用几何信息进行 对齐,而是让网络隐式学习对齐,但由于视角间的间隔很大造成多视角图片对齐的跨度很大, 这加大了隐式对齐的难度,让隐式对齐产生错误。
[0020]
进一步的,步骤(2)中,所述参考图片合成网络提取对齐图片里的高频细节来合成每张 视角图片的多张多视角参考图和多张相邻视角参考图,根据图3所示,具体做法为:参考图片 合成网络使用从单应性变换获得的对齐深度图作为距离几何信息,并首先将所有对齐的深度图 分块为小方块,再用每一方块的平均深度值赋予这一个深度方块,取平均值的目的是减少由深 度图不准确带来的影响,其原理如下公式:
[0021][0022][0023]
其中,1≤j≤h
×
w/162,j表示第j小方块,h和w表示深度图的高度和宽度,每个方块 的边长为16,unfold和mean分别表示深度图分块和深度值平均操作,di→
t,j
和表 示第i张多视角对齐深度图、对齐深度图的第j小方块和对齐深度图的第j平均小方块;本发明比 较每个位置深度方块的深度值大小来获得最小深度块的索引;接着依据获得的索引对从单应性 变换获得的对齐视角图片提取图片块;最后将提取的图片块组合成合成参考图片,其原理如下 公式:
[0024]
[0025][0026]
r=fold(r1,r2,
…
,rj),
ꢀꢀꢀ
(9)
[0027]
其中,j=h
×
w/162,hj、rj和r分别表示第j深度小方块的索引、从索引获得的第j小方 块图片和由所有小方块图片组合成的合成参考图,fold表示组合成参考图操作;参考图片合成 网络重复此过程6次,获得由前6小深度图索引得到6张合成多视角参考图这里上标m表示参考合成图是由所有视角合成的。
[0028]
进一步的,步骤(2)中,本发明输入每个视角相邻6张视角图对应的对齐深度图和对齐 视角图到参考图片合成网络中,获得6张合成相邻视角参考图这里上标n表 示参考合成图是由相邻视角合成的。
[0029]
步骤(2)中的有益效果在于,参考图片合成网络通过利用距离几何信息从所有对齐图片 中提取到了超分辨率需要的高频信息并将其组合到合成参考图中,根据图5所示,本发明合成 的参考图拥有很多的纹理细节,比如卡车上的英文字母更加清晰。现今的图片超分辨率方法只 能利用自身图片信息,视频超分辨率的方法只能利用相邻帧信息,而本发明的参考图片合成网 络利用了多视角场景里面所有的视角图片信息,这个特点是之前超分辨率网络所不具备的。
[0030]
进一步的,步骤(3)中,根据图4所示,参考超分辨率网络首先进行特征编码,用一个 参考图特征提取器,分别提取多视角参考图和相邻视角参考图的多尺度参考特征,再在每个尺 度以残差的方式融合进输入视角的特征里;参考超分辨率网络用一个输入视角特征提取器来提 取输入视角特征;整个参考超分辨率网络由卷积层和relu组成,每个尺度输入视角特征的上 采样方式为pixelshuffle。
[0031]
进一步的,步骤(3)中,所述参考超分辨率网络使用的损失函数为重构损失函数,参考 超分辨率网络的输出为目标输出为因此,损失函数的计算方式如下:
[0032][0033]
步骤(3)中的有益效果在于,参考超分辨率网络通过参考图特征提取器以多尺度残差方 式来提取并传递合成参考图里高频信息到超分辨率过程中,提高了超分辨率的质量。根据表1 所示,相比较的其他方案包括edsr
[2]
、rcan
[4]
、rbpn
[8]
、iconvsr
[10]
、ttsr
[6]
和masa
[7]
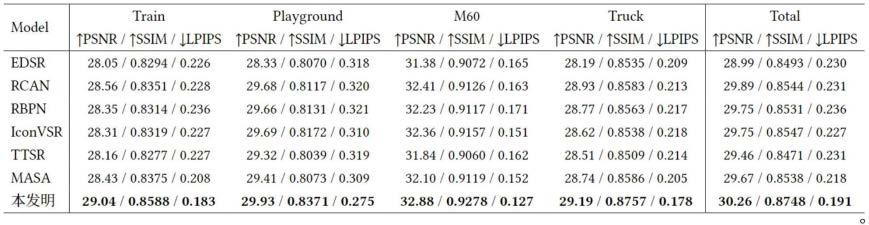
, 从图中最后一行可以得知我们的指标相比于其他方案是表现最好的。根据图5所示,从本发明 的结果图来看,我们的参考超分辨率网络充分利用了合成参考图生成了具有丰富细节的高质量 高分辨率视角图片,比如卡车上的英文字母更加清晰。
附图说明
[0034]
图1为本发明的多视角超分辨率网络框架图。
[0035]
图2为本发明的参考图片合成网络利用场景几何信息的结构图。
[0036]
图3为本发明的参考图片合成网络利用距离几何信息的结构图。
[0037]
图4为本发明参考超分辨率网络的结构图。
[0038]
图5为本发明的多视角超分辨率网络与其他方案的超分辨率可视化结果图上的对比。
具体实施方式
[0039]
下面对本发明实施方案进行详细说明,但是本发明的保护范围不局限于所述实施例。
[0040]
采用图1中的模型框架,通过一个参考图片合成网络对每一个输入视角合成其专有的多张 参考图片,接着一个参考超分辨率网络利用合成的参考图片对输入的视角图进行超分辨率的模 型训练。
[0041]
具体步骤为:
[0042]
(1)训练前,本发明使用tanks and temple数据集训练参考超分辨率网络,数据集中除 了train、m60、playground和truck场景用于测试外,其他场景用于训练。
[0043]
将同一个场景的所有多视角图片及其对应的深度图和相机参数输入到参考图片合成网络 中。根据图2所示,参考图片合成网络利用输入的图片、深度图和相机参数这些场景几何信息, 通过单应性变化将所有视角图及其深度图对齐到场景里每一张视角图和深度图。根据图3所示, 参考图片合成网络以对齐的深度图作为距离几何信息,从对齐的视角图中提取出高分辨率图片 方块,再将这些方块组合成参考图。合成参考图不仅与输入的待超分视角对齐,而且还具备丰 富的高频纹理细节,因此可以大大提高超分辨率的质量。
[0044]
(2)训练时,随机裁剪图像到80
×
160,并将图像像素归一化到-1到1区间,设初始学 习率为10-4
,最终学习率为10-7
,并采用余弦退火学习率下降方式,批大小(batch size)设为2, 训练200000个迭代,使用的优化器为adam来训练参考超分辨率网络。根据图4所示,参考 超分辨率网络用一个参考图特征提取器,分别提取多视角参考图和相邻视角参考图的多尺度参 考特征,再在每个尺度以残差的方式融合进输入视角的特征里。本发明对参考超分辨率网络生 成的高分辨率图片使用重构损失来约束整体网络的训练。
[0045]
(3)测试时,只需要将训练好的模型参数加载即可,不需要裁剪图像,直接将每个输入 视角及其合成的参考图输入到参考超分辨率网络中,就能够获得高分辨率参考图。
[0046]
本发明中多视角超分辨率网络与其他方案在psnr、ssim、lpips
[12]
指标上的对比见表1。 其中psnr、ssim的指标越高表明图像质量越好,lpips指标越小表明图像对人类的感知越 好。相比较的其他方案包括edsr
[2]
、rcan
[4]
、rbpn
[8]
、iconvsr
[10]
、ttsr
[6]
和masa
[7]
, 从图中最后一行可以得知我们的指标相比于其他方案是表现最好的。
[0047]
图5为本发明的多视角超分辨率网络与其他方案的超分辨率可视化结果图上的对比。可以 看到,本发明合成的参考图拥有很多的纹理细节,比如卡车上的英文字母更加清晰,这说明本 发明从所有视角图片中提取到了有用信息。从本发明的结果图来看,我们的参考超分辨率网络 充分利用了合成参考图生成了具有丰富细节的高质量高分辨率视角图片。
[0048]
表1
[0049]
p.aitken,rob bishop, daniel rueckert,and zehan wang.2016.real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network.in proceedings of the ieee conference on computer vision and pattern recognition(cvpr).
[0062]
[12]richard zhang,phillip isola,alexei a.efros,eli shechtman,and oliverwang.2018.theunreasonable effectiveness of deep features as a perceptual metric.in proceedings of the ieeeconference on computer visionand pattern recognition(cvpr).。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1