机器学习辅助建立岩石节理峰值抗剪强度预测模型的方法
1.本发明涉及岩石节理峰值抗剪强度预测模型领域,具体为机器学习辅助建立岩石节理峰值抗剪强度预测模型的方法。
背景技术:
2.天然岩体中存在大量随机分布的节理,与完整岩体相比,节理的存在一定程度上会降低岩体的强度和稳定性;在岩质边坡或者地下工程的设计中,节理的剪切强度是一个重要的需要考虑的参数;因此,准确评估和预测节理的剪切强度一直是岩土工程的热点问题,在过去的几十年里,研究人员基于剪切试验提出了大量的节理抗剪强度理论模型或者经验公式;然而节理面的抗剪强度受多因素影响,用于描述节理面抗剪强度的参数因人而异,研究人员从不同的角度研究可以采用不同的参数,因而得出了不同的抗剪强度模型。由于岩土材料的不确定性和复杂性,且随着计算机计算效率的不断提高,越来越多的研究人员倾向于使用机器学习算法来解决多因素影响的问题。机器学习算法可以在没有先验假设的条件下从原始数据进行学习,捕获信息间的潜在相关性,发现数据之间隐藏的模式,进而可以对未知数据进行预测。与传统的经验模型相比,机器学习算法由于具有强大的非线性映射能力,通常可以提高预测精度。
3.在节理面峰值抗剪强度的预测方面,传统的抗剪强度模型都是基于特定的试验数据集来建立的,其表达形式大多是对试验数据的分析和拟合得到。在未知的表达形式里面或许存在更加准确的抗剪强度预测模型,但由于目前模型所涉及的参数过多,多因素影响导致对试验数据的分析和深入越来越困难。因此,考虑到目前节理面抗剪强度与多个参数之间复杂非线性关系的描述仅限于传统的经验公式,基于机器学习算法的节理峰值抗剪强度预测模型鲜有报道,本文采用3种常见的机器学习算法,包括支持向量机(svm)、遗传算法改进的bp神经网络(ga-bpnn)和随机森林(rf),结合更大的剪切试验数据集,构建节理面峰值抗剪强度与相关参数间的非线性映射关系,建立节理峰值抗剪强度的机器学习回归预测模型。
技术实现要素:
4.本发明的目的在于针对背景技术的不足之处,提供一种机器学习辅助建立岩石节理峰值抗剪强度预测模型的方法。
5.本发明提供的一种机器学习辅助建立岩石节理峰值抗剪强度预测模型的方法,包括以下步骤:
6.s1、通过统计分析传统的岩石节理峰值抗剪强度模型中所使用的参数,初步选取与岩石节理峰值抗剪强度相关的参数,并建立用于机器学习的岩石节理峰值抗剪强度数据库;
7.s2、进行特征选择,对所选特征参数进一步处理和分析,排除或者合并冗余的参数,选择最合适的特征并确定最终的输入参数;
8.s3、采取标准化或者最大最小归一化的缩放方法,将最终选取的特征参数的值进行数据缩放,同时按照一定比例将处理好的数据集划分成训练集和测试集,训练集将用于机器学习模型的训练,训练好的模型将在测试集上进行预测;
9.s4、建立岩石节理峰值抗剪强度的机器学习模型及模型准确性评估。选取三种机器学习算法来分别建立回归分析模型来预测节理的峰值抗剪强度,包括支持向量机(svm)、遗传算法改进的bp神经网络(ga-bpnn)和随机森林(rf)。三种机器学习模型分别在训练集上训练,在测试集上预测,其模型性能的优劣使用以下三种指标进行评判:平均绝对误差(mae),均方根误差(rmse)以及决定系数(r2),计算公式如下:
[0010][0011][0012][0013]
式中,yi是真实值,是模型预测值,为真实值的平均值,即n为数据总个数。
[0014]
r2反映了模型回归拟合程度的优劣,越接近1说明拟合得越好,越接近于0则说明拟合得越差。mae计算的是实际值与预测值之间绝对误差的均值,反映的是误差的实际情况,而rmse计算的是实际值与预测值之间偏差的均方根,对较大的误差值(异常值)比较敏感,二者的量纲均与实际值保持一致。一般来说,r2越大,mae、rmse越小,说明训练模型的准确率越高。
[0015]
机器学习模型的建立过程中需要根据各个模型中所涉及的参数特点进行超参寻优,选择最优的模型超参,包括支持向量机模型中的核函数、正则化系数c、核函数的参数g;神经网络模型中的隐含层数量、神经元的个数,遗传算法优化部分的最大进化代数、种群规模、交叉概率、变异概率;随机森林模型中最小叶子数量,树的数量。
[0016]
与此同时,进行10折交叉验证,即将训练集继续不重复地细分为10个子集,其中9个子集作为训练子集,剩下的一个作为验证子集,如此循环10次,可以得到10个训练模型和相应的模型性能评价。
[0017]
s5、分析所建立的岩石节理峰值抗剪强度预测模型的参数敏感性,在新数据集上进行预测和评估。为了确定新数据集的范围和控制变量,新数据集的建立过程是将原始数据集中每个输入参数的最小值和最大值作为该参数的上下界,生成1000个等间距变化的新数据。当进行模型中某个参数的敏感性分析时,只让该参数进行连续变化,其余参数保持不变,其余参数值的大小为原始数据集中对应参数的均值。最后评估所建立的机器学习模型
的泛化性能,选出性能较优者。
[0018]
与现有技术相比,本发明的有益效果是:
[0019]
1、与传统模型相比,机器学习所建立的节理峰值抗剪强度模型可以不依赖先验假设条件,无需事先确定模型的具体表达式形式,直接构建节理面峰值抗剪强度与多个参数之间复杂非线性映射,因此机器学习模型所建立的峰值抗剪强度预测模型的精度和准确性更高。2、机器学习模型基于更大的剪切数据集建立,泛化能力更强,适用性更好。3、机器学习所建立的节理峰值抗剪强度模型可拓展性更强。随着未来剪切试验数据库的不断丰富,节理峰值抗剪强度预测模型能够不断改进优化,由于更多的数据可以用于机器学习模型的训练,模型预测抗剪强度的准确性、鲁棒性、泛化能力将得到进一步提升。
附图说明
[0020]
图1是传统的节理峰值抗剪强度模型中主要参数使用频次的统计图;
[0021]
图2是所建立的峰值抗剪强度数据库中的抗剪强度分布图;
[0022]
图3是选取的四个输入参数的频率直方图及累计百分比图;
[0023]
图4是划分训练集和测试集的示意图;
[0024]
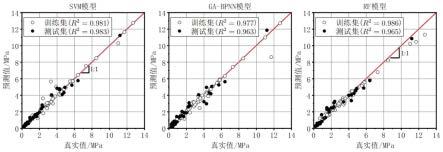
图5是三种机器学习模型在训练集和测试集中的预测值与真实值的比较图;
[0025]
图6是三种机器学习模型10折交叉验证的性能比较图;
[0026]
图7是三种机器学习模型10折交叉验证中r2,rmse,mae的平均值比较图;
[0027]
图8是对训练好的三种机器学习模型进行参数的敏感性分析结果图;
[0028]
图9是四种经验模型在整个数据集上的峰值抗剪强度预测值与真实试验值的对比图;
[0029]
图10是三种机器学习模型在整个数据集上的峰值抗剪强度预测值与真实试验值的对比图。
具体实施方式
[0030]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
[0031]
第一步、特征参数选取及数据库的建立:
[0032]
统计分析传统的岩石节理峰值抗剪强度模型中所使用的参数,共收集了24个传统的节理峰值抗剪强度模型,如表1所示:
[0033]
表1:
[0034]
[0035][0036]
统计本文所列模型使用的主要参数得到各参数的使用频次如图1所示。通过分析和比较传统模型中所使用的参数(图1),除了法向压力σn和节理面的基本摩擦角φb以外,三维粗糙度相关参数材料抗拉强度σ
t
以及jcs使用频次较高。进一步分析可知,模型中的三维粗糙度参数主要和抗拉强度σ
t
一同使用,如模型(11)、(12)、(14)、(15)、(19),而参数jcs则主要用于jrc-jcs模型及其改进的模型,如(4)、(8)、(16)、(21)。
[0037]
在众多的模型和参数中,基于grasselli三维粗糙度的模型及其改进模型的研究较多,参数较为统一,初步选择与岩石节理峰值抗剪强度相关的特征参数为:法向压力σn、基本摩擦角φb、节理面三维形貌参数a0、c以及材料抗拉强度σ
t
。根据选取的特征参数,统计不同文献中的127组研究数据建立数据库,数据库中的峰值抗剪强度分布如图2所示。
[0038]
第2步、特征选择:
[0039]
grasselli采用的形式用作三维粗糙度的评价指标,并作为其模型的一个输入参数,tatone et al.通过对grasselli描述节理面三维粗糙度的表达式在0到进行积分得到曲线下方的面积,提出了一个使用更加广泛的粗糙度参数:
[0040][0041]
因此,为了降低数据维度,本文将和c合并为一个输入参数
[0042]
yang et al.、liu et al.、tian et al.对参数a0进行过统计分析,其基本分布在0.45~0.55这个较小的范围内,且均值在0.5附近,因此认为a0不是一个合适的描述节理面三维粗糙度的参数。liu et al.还通过假定a0为常数0.5,并将a0=0.5代入grasselli模型中计算,发现计算值与原始的grasselli模型计算值相关系数达到99%以上,认为可以忽略a0的小范围变化所带来的影响。为了进一步降低特征的维度,本文中也假定a0为常数即忽略参数a0的影响,不将a0作为模型训练的输入参数。
[0043]
最终,本文选择四个特征:σn、φb、和σ
t
作为模型的输入参数,以此建立四个输入参数与剪切强度间的机器学习回归预测模型,即建立四个输入参数与剪切强度间的机器学习回归预测模型,即输入参数的频率直方图及累计百分比如图3所示,输入参数以及抗剪强度的统计值如表2所示。
[0044]
表2:
[0045][0046]
第3步、数据缩放和划分数据集:
[0047]
选择最小最大归一化方法对每一列特征进行缩放处理,使特征均位于区间[0,1],便于机器学习模型的训练和预测,通过下面的公式可以计算出缩放后的每个样本点的值:
[0048][0049]
式中,x
norm
是缩放后的值,x是某一样本点,x
min
和x
max
分别代表该组样本数据中的最小和最大值。
[0050]
将处理好的数据集划分成比例为7:3的训练集和测试集,训练集包含89组数据,测试集包含38组数据,划分数据集的示意图如图4所示。训练集将用于机器学习模型的训练,训练好的模型将在测试集上进行预测。
[0051]
第4步、建立岩石节理峰值抗剪强度的机器学习预测模型:
[0052]
选取三种机器学习算法来分别建立回归分析模型来预测节理的峰值抗剪强度,包括支持向量机(svm)、遗传算法改进的bp神经网络(ga-bpnn)和随机森林(rf)。三种机器学习模型分别在训练集上训练,在测试集上预测,其模型性能的优劣使用以下三种指标进行评判:平均绝对误差(mae),均方根误差(rmse)以及决定系数(r2),计算公式如下:
[0053][0054][0055][0056]
式中,yi是真实值,是模型预测值,为真实值的平均值,即n为数据总个数。
[0057]
机器学习模型的建立过程中需要根据各个模型中所涉及的参数特点进行超参寻优,选择最合适的模型超参。通过超参寻优,选择支持向量机模型中的核函数为高斯核函数、正则化系数c=2
5.2
、核函数的参数g=2-2.4
;选择神经网络模型中的隐含层数量为1、隐含层神经元的个数为5,遗传算法优化部分的最大进化代数为100、种群规模为30、交叉概率为0.3、变异概率为0.1;随机森林模型中最小叶子数量为2,树的数量为100。
[0058]
三种机器学习模型在相同的训练集上训练以及在相同的测试集上验证,结果如图5所示。在训练集上,三种机器学习模型的预测准确率均达到了97%以上,均方根误差在0.3~0.4mpa之间,其中rf模型准确率最高。在测试集上,三种机器学习模型的预测准确率均在96%以上,均方根误差在0.3~0.44mpa之间,其中svm模型的准确率最高,达到了98.3%。三种机器学习模型在训练集和测试集上的准确率及均方根误差相近,说明通过超参优化后的模型未出现过拟合。
[0059]
与此同时,训练模型时进行了10折交叉验证,即将训练集继续不重复地细分为10个子集,其中9个子集作为训练子集,剩下的一个作为验证子集,如此循环10次,可以得到10个训练模型和相应的模型性能评价,如图6所示。统计10折交叉验证中三种性能指标r2,rmse,mae的平均值如图7所示。从图7可以看出在训练集和测试集上,svm模型的三种指标均优于其他两种模型;ga-bpnn模型在训练集上的三种指标均优于rf模型。
[0060]
第5步、在新数据集上进行预测,分析所建立的岩石节理峰值抗剪强度预测模型的参数敏感性,评估其泛化性能:
[0061]
为了确定新数据集的范围和控制变量,新数据集的建立过程是将原始数据集中每个输入参数的最小值和最大值作为该参数的上下界,生成1000个等间距变化的新数据。当进行模型中某个参数的敏感性分析时,只让该参数进行连续变化,其余参数保持不变,其余参数值的大小为原始数据集中对应参数的均值。例如,分析参数的变化时,以其在数据集中的最小值5.13和最大值16.95作为该参数的上下界,并在该范围内产生1000个等间距的数据。与此同时,其余三个参数保持不变,取原始数据集中的均值即φb=35.8
°
,σ
t
=3.73mpa,σn=1.57mpa。图8为四个输入参数变化时,机器学习模型对峰值抗剪强
度的预测结果。从图8可以看出,svm模型和ga-bpnn模型预测的剪应力τ
p
与连续变化的输入参数之间存在连续光滑的函数关系,说明其泛化能力较好;而rf模型尽管在趋势上与svm模型和ga-bpnn模型相似,但rf模型预测的剪应力比上述两种模型偏小,曲线呈阶梯状不够光滑,泛化性能较差。
[0062]
对比例
[0063]
为了进一步说明本发明模型预测节理峰值抗剪强度的性能更优,采用第一步中表1所列的四种经验模型(tian et al.模型、tatone模型、xia et al.模型、tang and wong模型)与本发明的模型在整个原始数据集上进行预测,进一步对比验证。经验模型峰值抗剪强度的预测值与试验值的分布如图9所示,本发明模型的峰值抗剪强度的预测值与试验值的分布如图10所示。可以看出,机器学习模型预测的剪应力整体上波动不大,只有少量预测值的误差较大,且预测的准确率均在97%以上;而在剪应力试验值超过3mpa后,经验模型计算的预测值波动很大,无法准确地进行预测。进一步,为了更加量化的进行对比,表3统计了机器学习模型和经验模型在三种评估指标上的性能以及机器学习模型相对于经验模型在三种指标上的性能提升。相较于经验模型,机器学习模型在预测的准确率上有5%~12%的提升,在减小均方根误差上有38%~60%的提升,在减小平均绝对误差上有47%~70%的提升。
[0064][0065]
注:性能提升百分比中的三个数分别代表svm模型
①
、ga-bpnn模型
②
以及rf模型
③
与经验模型相比的性能提升。
[0066]
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1