基于动静态卷积融合神经网络的多视图三维点云分类方法
1.本发明属于三维点云分类技术领域,具体涉及一种基于动静态卷积融合神经网络的多视图三维点云分类方法。
背景技术:
2.近年来,随着人工智能和深度学习技术的飞速发展,三维感知和理解领域取得了突破性进展。而点云作为三维感知和理解的重要表现形式,其包含了更加丰富的几何形状和结构信息。三维点云主要是通过激光雷达、rgb-d相机以及其他传感器设备采集得到,其广泛应用城市环境的监测、城市形态的分析、道路自动驾驶、计算机视觉、机器人研发和逆向工程建模等诸多领域。与三维点云相关的研究领域又包括基于点云的分类、目标检测、分割、配准、去噪等等,而这其中三维点云的分类是最基础且重要的环节之一,因此对于点云的分类研究,特别是如何提高点云分类的准确度和效率成为相关学界广泛关注的热点。
3.当下对三维点云的分类方法主要包括基于体素、基于直接点云和基于多视图的方法,这三种方法又各自受到了大量学者的关注与研究。以下将对现有技术中的这三种方法及其问题、不足进行简要说明。
4.一、基于体素的三维点云分类
5.体素即体积像素,其用恒定的标量或者向量表示一个立体的区域,由于体素可以用可简化的、离散的单元如粒子来表示复杂的对象,所以它们在模拟真实世界中复杂对象的行为方面具有十分强大的功能,并且体素本身的结构表示也较为简单。victoria plaza等人提出了基于体素的自然环境三维点云数据分类方法,该模型利用多层感知机对内点的空间分布进行统计几何分析,对体素进行分类,点周围的局部空间分布特征由点位置协方差矩阵的主成分定义。体素和神经网络的结合比其他策略达到了更快的计算速度,但是并没有改变体素本身计算量大和耗时的本质缺点。zhijian liu等人提出了point-voxel的卷积神经网络模型,其将一个物体的整体结构和细节用两个模块来捕捉,整合了基于点云和网格的优点,拥有较其他体素模型而言较小的数据开销和较好的数据规整度,内存消耗也更低。该算法的分类精度好于当下各种基于体素的分类模型,但是其并未突破基于体素卷积的低效和基于体素和基于点云结构的刻板印象。victoria plaza-leiva等人提出了一种基于体素邻域的新的通用框架,用于实现和比较不同的监督学习分类器,该框架采用简单的基于体素本身定义的支持区域内特征,将规则网格中每个不重叠的体素中的点分配给同一类,有效地提高了3维空间形状特征分类的有效性,缩短了处理时间,易于并行化处理,但是其只是进行了初步实验,后续缺乏使用不同性能指标、环境、传感器等做深入的分析。zishu liu等人提出了一种基于体素的广义学习网络vb-net,并使用该模型来进行3d对象的分类。通过将原始点云转化为体素,再利用vb-net作为特征提取器,从体素中提取特征,并将特征用于广义学习系统(bls)的目标分类,显著地减少了系统训练消耗的时间,但模型分类的准确性还有待提高,尤其是随着三维物体分辨率的提高,分类精确度急剧下降。kazuma hamada等人考虑了体素密度沿深度方向的变化,进而提出了一种新的三投影体素
展开的三维场景分类方法。该方法根据位置和大小规范化3d场景,将3d场景投影到三个垂直平面上。通过合并三幅图像,应用深度学习预测每个场景的类别,其分类的准确性有很大的提高。但是由于三投影体素展开需要标准化来使得每个3d场景适合于一个体素,如果3d场景足够大,tri-projection voxel splatting(tvs)可能无法识别微小的对象。cheng wang等人提出了一种基于体素的卷积神经网络normalnet,使用一个反射卷积串联(rcc)模块实现卷积层,来为3d视觉任务提取可分辨特征,从而显著减少了参数数目和整个网络的性能。但是该方法并没有在关键模块rcc中找到最佳反射数,因而模型拥有进一步的优化空间。hui cao等人调查了二进制体素不适合三维卷积表征的原因,通过给每个体素指定距离值提高了约30%的准确度,并且设计了一个快速全连接和卷积混合级联网络用于三维对象的分类。其平均的推理时间快于基于点云和体素的方法,准确率也更高,但其使用的深层网络对于一部分困难样本的识别率却不如浅层网络。
6.基于体素的方式进行三维物体的分类,其最大的缺点就是存储代价太高。同时,将一幅用体素表示的庞大复杂的三维图像直接送入三维卷积中处理势必需要很大的计算代价,耗费大量计算时间。如果通过降低三维图像分辨率的方式来解决此类问题,又会造成最终训练出的模型精度的降低。
7.二、基于点云的直接处理分类
8.点云是由给定坐标系统定义的数据点的集合,每个点包含了丰富的信息,包括三维坐标x、y、z以及颜色、分类值、强度、时间等等,其具有无序性、稀疏性、旋转和平移的不变性等特点。相较于体素的方式,基于点云的直接处理方法无需进行额外的模型转换,直接将原始点云作为处理对象,其能够减少了大量的存储开销。charles r.qi等人设计了一种新的直接训练点云的神经网络pointnet,其使用了一个学习到的t-net转换矩阵来保证模型对特定空间转换的不变性.通过多层感知机(multi-layer perceptron,mlp)对各点云数据进行特征提取,在特征的各个维度上执行最大池化操作来得到最终全局特征,并依靠mlp来进行3d物体的分类操作。由于直接对点云操作而不需要复杂的预处理,因此网络模型十分高效,且抗扰动。但局部点与点之间的联系并没有被网络学习到,缺失了对于局部特征上信息的捕获。zhongyang zhao等人提出了一种结合多尺度特征和pointnet的深度神经网络,其利用多尺度提取点的邻域特征,然后与pointnet提取的全局特征相结合,完成对激光雷达点云的分类,其达到了比较好的分类效果,但需要进一步改进在提取局部特征时效率很低这一缺点。zhuangzhuang li等人基于pointnet提出了两种提高三维分类模型精度的方法,通过增加隐藏层的数量来获取更多的抽象特征,以及将softmax损失函数与中心损失函数相结合来获得判别特征,从而让改进后的模型比原始的pointnet具有更好的性能。但针对是否可以使用更加轻量化的网络或者深层卷积网络来对模型进一步优化,以及调整相关参数的范围从而增强目标的判别力等方面并未进行细致地探究。kuangen zhang等人针对一维信号和二维图像对环境进行分类可能面临的遮挡问题,提出了一种定向pointnet来直接对三维点云进行分类,其利用了点云的方向信息,可以对各种不同地形进行分类,从而帮助可穿戴机器人对象在复杂环境中行走,达到对环境进行鲁棒高效的分类,但是模型的高分类精度仅仅局限于特定应用领域。针对pointnet网络所存的问题,即不能捕捉到由度量空间点所产生的局部结构,从而限制了它识别细粒度模式的能力和对复杂场景的泛化能力,作者对此进行改进,提出了一种新的分层网络模型pointnet++。pointnet++网络通过一
种新的学习层来自适应地结合多尺度特征,同时结合局部点集地密度自适应,能够有效学习深层次的点集特征,从而达到更精准的分类效果。但是其所花费的时间较pointnet网络模型也大大增加,尤其体现在点云数据的预处理部分。mor joseph-rivlin等人使用三维坐标作为类标识符,比较形状矩的属性来进行分类,并且增加坐标的多项式函数让网络能够适应一个形状的高阶矩。实验表明了其在内存占用和计算复杂性上有很大的提升,能够很好处理刚性物体的分类问题,但将该模型应用于设计几何分析的其他领域是否仍能达到非常高的分类精确度,仍然是一个值得探究的问题。jancheng yang等人使用了参数高效的group shuffle attention来替换高代价的multi-head attention注意力机制,从而开发出了point attention的转换器,其能够处理尺寸变化的输入数据,并且具有变换的等价性。作者还首次提出端到端的学习和任务不可知的采样操作(gumble subset sampling,gss),通过选择代表层次结构中的子集,网络可以以较低的计算成本获得输入集更强的表示,实验也表明了该方法在三维图像分类上的有效性和效率,但并未将gss应用于通用数据集中,探索其在分层多实例学习中的有效性和可解释性。hengshuang zhao等人提出了一种从点云中的本地领域提取上下文特征的新方法pointweb,其将每个点紧密地连接在本地邻域,并使用了一个新颖的自适应特征调整模块,以查找点之间的相互作用,该框架可以更好地学习点表示以进行点云的处理,但将所提出的模块应用到3d场景的理解上则需要进一步考证。jiangwen xie等人基于能量模型,提出了一种无序点云的生成模型。在该模型中,能量函数学习每个点的坐标编码,然后将所有单独的点特征聚合为整个点云的能量。模型基于mcmc的最大似然学习及其变体进行训练,而不需要任何辅助网络,同时不依赖手工绘制距离度量来生成点云,因此用于点云分类的效率十分高。但是在实际应用过程中,模型的抗扰动以及对于存在较多离群点的点云的处理上表现较差。xu yan等人针对原始点云存在的离群值和噪声,提出了一种用于鲁棒点云处理的新型端到端网络(point adaptive sampling and local nonlocal module,pointasnl)。该网络模型包含两个模块,自适应采样模块和局部非局部模块。其中,自适应采样模块使用最远点采样算法fps采样初始点云并重新加权领域,而局部非局部模块则可以进一步捕获领域点和长程依赖。pointasnl在点云分类上的鲁棒性达到了最先进的水平,但是对于自适应采样模块中的微调策略则需要不断地进行探索。
9.基于点云方式的三维物体分类由于传感器、场景等因素的影响,实际采集到的点云其点的稀疏程度各不相同,从而影响到最终分类的精度。因此,对点云进行复杂的预处理操作也是不可避免的。此外,由于传感器的扰动,点云中也不可避免地会出现扰动和异常值,也就是说一个点可能会出现在其被采样的附近某一个半径范围内或是空间中的任意位置。对点云进行旋转,会产生不同的点云,但是却仍然代表相同的三维物体。因此点云异常值和扰动,以及刚性变换处理等问题,使得基于点云的三维物体分类变得更加复杂。
10.三、基于多视图的三维点云分类
11.基于多视图的三维点云分类方法是对于一个三维点云物体从不同的角度采集该物体的一幅幅二维图像,将采集到的多幅二维图像送入cnn模型中进行分类,用来表征最终的三维点云物体。xiaozhi chen等人针对自主驾驶场景下的高精度三维目标检测展开研究,提出了一个多视图的3d网络。该网络由两个子网络组成,一个用于生成3d对象的多视图表征,另一个用于多视图的特征融合。其中,特征融合子网络能将来自多个视图的区域性特
征结合起来,使得不同路径的中间层能够进行交互,大大提高了分类的准确性,同时计算的性能也有所降低。但由于模型使用的是基于区域的融合网络,因此对于从全局性角度提取物体的特征信息方面稍显不足。panagiotis papadakis等人使用大规模地面真实数据集和基于基线视图的识别方法,在不同的环境假设和观测能力下,对多个多视图假设融合方案进行了基准测试,突出了基于多视图识别方法应考虑的重要因素。但分析仅仅局限于三维形状,而没有考虑物体的纹理特征。xiaohui cheng等人提出了一种新的特征选择方法,将低秩约束、稀疏表示、全局和局部结构学习嵌入到统一框架中,利用基于超图的正则化项来构建拉普拉斯矩阵,并利用一种新颖的优化算法来求解目标函数。该方法在多视图数据集上达到了很好的分类性能,但并没有将该方法扩展到无监督学习和聚类学习中去。christopher pramerdorfer cogvis等人基于新颖的多视图卷积网络结构,提出了一种在深度图中联合分类物体和回归模型的三维边界框方法。该方法对遮挡具有很强的鲁棒性,网络能够处理编码对象几何体和遮挡信息的视图,并以世界坐标输出类分数和边界框坐标,无需任何后处理步骤。模型最大的优点是具有极高的分类准确率和很小的回归误差率,但能否通过不同的网络前端架构(如resnet)进一步提高性能,或者将方法集成到一个基于kinect的已部署检测系统中评估方法的性能仍是一个值得深入研究的问题。yifan feng等人针对多视图之间固有层次相关性和可分辨性尚未得到很好利用这一问题,提出一种用于区分3d形状描述和用于分层相关建模的组视图卷积神经网络group-view convolutional neural networks(gvcnn)。该方法引入了分层的形状描述框架,包括视图,组和形状级别描述符等。其也考虑了每种形状的视图之间的相关性,并将分组信息用于形状表示。实验证明了模型在3d形状分类和检索任务上获得了显著性能提升,但在使用更多且更完整的视图进行试验方面还不够完善。anan liu等人提出了多视图的分层融合网络multi-view hierarchical fusion network)(mvhfn)。该方法包含两个主要模块,即视觉特征学习模块和多视图层次融合模块。模块一应用2d卷积神经网络来提取围绕特定三维对象绘制的多个视图的视觉特征,而模块二将多个视图特征融合到一个紧凑的描述符中。该模型可以通过学习集群级特征信息来发现内容区分性,从而充分利用多视图的相关特性,大大提高分类的准确率。但是对于视图捕获的数量较少,视图的顺序也是固定的,并不能很好地模拟现实3d场景中地物体识别。jinxing li等人提出了一种概率层次模型应用于多视图分类,其首先学习一个潜在的变量用于融合从同一视图、传感器和形态中获取的多个特征,再使用某个视图的映射矩阵将潜在变量从共享空间投影到多个观测,使用期望最大化em算法估计参数和潜在变量,达到了多层次且有效地融合多视图、多特征的数据。相关参数计算具有真实性和可重复性,但多视图且多特征模型本身的复杂性太高,计算效率低。jia he等人提出了一种在线贝叶斯多视图学习算法,该算法以最大边距的原理学习预测子空间,定义了潜在的边际损失,利用伪似然和数据增强思想将学习问题最小化到各种贝叶斯框架上,并根据过去的样本得出近似后验变化,其较当下最先进的方法,模型可以实现更高的分类性能,并且能够自动推断权重和惩罚参数,但是对于样本数据集较大时计算稍显复杂。jinxing li等人设计了一种新的高斯过程潜在变量模型gpvlm,用来表示一个公共子空间中的多个视图。其通过高斯过程结构下的视图共享和特定于视图的内核参数,学习从观测数据到共享变量的另一种投影。并且通过高斯变换的方式,将潜在变量转换为标签信息,其很好地揭示了不同视图之间的相关性,模型也体现了较为优越的性能,但是特定的径向基函数(rbf)无
法适应实际分布复杂的数据,而且作者也未将多内核学习考虑在内。qian yu等人提出了了一种新的多视图卷积神经网络latent-mvcnn(lmvcnn),它利用预定义或随机视图的多视图图像来识别三维形状,由三个子卷积神经网络组成。其中,第一个cnn输出多类别的概率分布,第二个cnn输出一个潜在向量,帮助第一类cnn选择合适分布,第三个cnn输出一个视图的类别概率分布到另一个视图的类别概率分布中。lmvcnn对于预先定义的视图和随机的视图都有很好的识别性能,并且在视图数量较少时也能表现出良好的性能,但是其并没有解决无背景干扰的三维形状识别问题。因此,如何解决在真实三维环境中检测和识别物体也是一项艰巨的挑战。tan yu等人从图像块之间的相似性度量角度考虑,提出了用于三维对象识别的多视图协调双线性网络(multi-view harmonized bilinear network for 3d object recognition,mhbn)。该模型对局部卷积应用双线性池化来获得一个紧凑的全局表征,并且通过协调集合特征的奇异值来产生更具判别能力的表征。作者通过实验佐证了该方法在三维物体识别中的有效性,达到了很高的分类准确率。但是,依然采用固定视点选取多视图,以及传统静态卷积提取特征等,分类精度有进一步提升的空间。
12.相比较体素和直接点云处理的方式,由于只需要存储多张二维视图,所以该方法将占用更少的存储空间。同时,对于转换后的二维视图,可以充分利用当下发展已经十分成熟的二维cnn模型,因此其训练所耗费的时间大大减少,同时模型分类的精度也是三者中最高的。然而,在三维点云转换为二维视图的过程中,多数基于多视图的方法都是直接使用了传统的固定视点投影方式,显然这种方法容易造成视图数据间的相似性过高。因此,对于与测试集上相似性相差较大的视图,模型判别力会变差,进而降低了模型整体的泛化能力。而且,在特征提取的过程中,这些方法常常使用一个预训练好的cnn骨干模型来提高特征提取效率,但多数骨干模型使用的是传统静态卷积,其无法在不同数据间做到自适应性。此外,在特征融合的过程中,仅仅使用最大池化、平均池化等方法,使得大量细节信息丢失,融合效率十分低下。
技术实现要素:
13.本发明是为解决上述问题而进行的,目的在于提供一种总体泛化性更好、计算复杂度相对更低、整体分类性能更好且融合效率高的三维点云分类方法,本发明采用了如下技术方案:
14.本发明提供了一种基于动静态卷积融合神经网络的多视图三维点云分类方法,其特征在于,包括如下步骤:
15.步骤s1,通过fsdc-net的多视图选取部分将输入的三维点云投影变换为多视图表征;
16.步骤s2,通过fsdc-net的局部特征处理部分提取多视图表征的局部特征;
17.步骤s3,通过fsdc-net的全局特征融合部分将局部特征融合为全局特征;
18.步骤s4,fsdc-net基于全局特征对所述三维点云进行分类,
19.其中,步骤s1包括如下子步骤:
20.步骤s1-1,对所述三维点云的各个点的位置信息进行归一化;
21.步骤s1-2,选取固定视点,并基于该固定视点对归一化后的所述三维点云进行投影,得到固定视图集;
22.步骤s1-3,选取随机视点,并基于该随机视点对归一化后的所述三维点云进行投影,得到随机视图集;
23.步骤s1-4,按预定比例分别从所述固定视图集和所述随机视图集中选取部分视图,并将其组合成多视图初始阶段的表征,即所述多视图表征,
24.步骤s2包括如下子步骤:
25.步骤s2-1,将每个所述视图进行卷积和最大池化;
26.步骤s2-2,将每个所述视图串行地经过所述fsdc-net中的多个fsdc层,其中,每个所述fsdc层对输入特征并行地应用静态卷积和轻量化动态卷积分别生成算子并分别提取特征,再通过两个可学习权重自适应地融合两个分支提取的特征,进而通过激活层得到输出特征作为所述局部特征,
27.其中,用于进行所述轻量化动态卷积的动态卷积核通过以下子步骤得到:
28.步骤s2-2-1,通过batchpool函数对所述输入特征在batch维度进行融合,从而达到轻量化的效果,如下式:
[0029][0030]
式中,xi,z1分别表示batchpool前后的输入和输出特征,xi(j,c,h,w)表示输入的某一幅图像,b表示batchsize的大小,c,h,w分别表示输入特征在通道、高度、宽度方向的集合;
[0031]
步骤s2-2-2,分别采用不同尺寸的卷积矩阵从不同感受野上对原始输入特征进行卷积操作,从而提取不同感受野上的信息;
[0032]
步骤s2-2-3,融合不同感受野上提取到的所述信息;
[0033]
步骤s2-2-4,通过dropout层使所述fsdc层中的神经元按预定比例随机失活,从而避免过拟合问题;
[0034]
步骤s2-2-5,对每个所述fsdc层,通过卷积将原始动态权重改变至预定的通道数,并通过激活函数sigmoid获得概率值作为所述fsdc层的动态权重,从而得到多个所述fsdc层的动态权重集合;
[0035]
步骤s2-2-6,将原始的多组卷积核与所述动态权重集合进行乘加,生成最终的所述动态卷积核。
[0036]
本发明提供的基于动静态卷积融合神经网络的多视图三维点云分类方法,还可以具有这样的技术特征,其中,步骤s3包括如下子步骤:
[0037]
步骤s3-1,对n个所述局部特征进行平均池化,得到一个n维向量,表示每个动态权重的初始值集合;
[0038]
步骤s3-2,对所述n维向量依次应用两个输入输出均为n维的1
×
1卷积,并在两个所述1
×
1卷积之间应用非线性激活函数swish,再通过激活函数softmax得到各个所述视图的特征权重;
[0039]
步骤s3-3,将每个所述视图与对应的所述特征权重相乘,再在视图维度进行相加,得到所述全局特征。
[0040]
本发明提供的基于动静态卷积融合神经网络的多视图三维点云分类方法,还可以具有这样的技术特征,其中,步骤s2-1中,用7
×
7卷积矩阵进行卷积,步骤s2-2中,所述激活
层为bn+relu。
[0041]
本发明提供的基于动静态卷积融合神经网络的多视图三维点云分类方法,还可以具有这样的技术特征,其中,步骤s2-2-2中,分别用1
×
1卷积矩阵和3
×
3卷积矩阵从不同感受野上对所述原始输入特征进行卷积,如下式:
[0042]
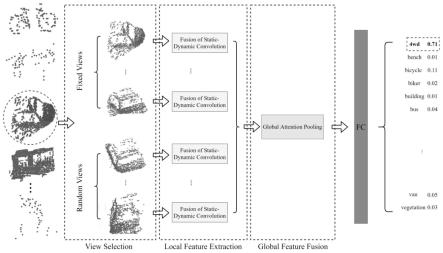
z2=w1(z1)
[0043]
z3=w2(z1)
[0044]
式中,w1,w2分别表示1
×
1和3
×
3卷积矩阵,z2,z3分别表示对应产生的输出特征,
[0045]
步骤s2-2-3中,对输出特征z2,z3进行逐元素相加,再经过一个空间平均池化函数,将其收缩为1
×c×1×
1维度的输出特征z4,如下式:
[0046][0047]
式中,h
×
w为局部特征的宽和高,
[0048]
步骤s2-2-4中,按下式进行随机失活:
[0049]
z5=f
dropout
(z4,p)
[0050]
式中,p代表失活的比例,且0《p《1。
[0051]
本发明提供的基于动静态卷积融合神经网络的多视图三维点云分类方法,还可以具有这样的技术特征,其中,步骤s1-1中,基于以下公式进行所述归一化:
[0052][0053]
式中,p
i,j,k
表示三维点云中的任意一个点,min(p
x,y,z
)和max(p
x,y,z
)分别表示对三维点云中三维笛卡尔坐标系x,y,z三个坐标轴取最小值和最大值得到的点。
[0054]
本发明提供的基于动静态卷积融合神经网络的多视图三维点云分类方法,还可以具有这样的技术特征,其中,步骤s1-2中,将虚拟相机摆放在固定位置,保持所述三维点云的中的两个坐标轴不变,在第三个坐标轴上等间隔角度地进行旋转,再使用所述虚拟相机进行二维投影,从而得到所述固定视图集。
[0055]
本发明提供的基于动静态卷积融合神经网络的多视图三维点云分类方法,还可以具有这样的技术特征,其中,步骤s1-4中,根据以下公式进行选取及组合:
[0056][0057]
式中,fixed(θ)为固定视图集,rand(θ)为随机视图集,n为视图总数,t为随机视图数量,fi为第i个视图,p为多视图表征。
[0058]
发明作用与效果
[0059]
根据本发明的基于动静态卷积融合神经网络的多视图三维点云分类方法,针对传统固定视点选取多视图方法可能存在预处理阶段过拟合的问题,采用了固定-随机视点的多视图预处理算法,提高了模型在不同视图上的泛化性能;同时为了提取更丰富的细粒度特征信息,采用了静态和动态卷积的自适应权重融合算子,用于局部特征提取;此外,采用
了自适应的全局注意力池化的方法,能够更加有效地融合不同视图上的局部特征,获得点云全局表征中的最关键细节。综上所述,相较于现有技术中最先进的一些三维点云分类算法模型及方法,本发明的方法总体泛化性能更好、整体分类性能更好且融合效率高。
附图说明
[0060]
图1是本发明实施例中基于动静态卷积融合神经网络的多视图三维点云分类方法的流程图;
[0061]
图2是本实施例中fsdc-net网络模型的工作原理图;
[0062]
图3是本发明实施例中固定-随机视点的多视图预处理算法的流程示意图;
[0063]
图4是本发明实施例中局部特征提取过程的示意图;
[0064]
图5是本发明实施例中轻量化动态卷积的流程示意图;
[0065]
图6是本发明实施例中自适应注意力池化的流程示意图;
[0066]
图7是本发明实施例中modelnet40数据集的示例图;
[0067]
图8是本发明实施例中悉尼城市数据集的示例图。
具体实施方式
[0068]
为了使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,以下结合实施例及附图对本发明的基于动静态卷积融合神经网络的多视图三维点云分类方法作具体阐述。
[0069]
《实施例》
[0070]
图1是本实施例中基于动静态卷积融合神经网络的多视图三维点云分类方法的流程图。
[0071]
图2是本实施例中fsdc-net网络模型的工作原理图。
[0072]
如图1和图2所示,本实施例中,fsdc-net网络模型包含三个部分:(a)固定-随机视点的多视图选取部分:用于对原始点云进行预处理,通过固定和随机两种视点转换为二维视图,然后按照一定比例组合在一起;(b)局部特征处理部分:通过并行地将轻量化的动态卷积与传统静态卷积结合在一起,构成点云特征提取的局部算子,以提高局部特征的提取效率;(c)全局特征融合部分:使用注意力池化方式,在将多视图的局部特征融合为全局特征的过程中,给予不同局部特征以不同影响力权重,从而达到更高的分类准确率。
[0073]
基于该fsdc-net网络模型的多视图三维点云分类方法具体包括如下步骤:
[0074]
步骤s1,通过fsdc-net网络模型的多视图选取部分将输入的三维点云投影变换为多视图表征。
[0075]
本实施例所涉及的是多视图的点云分类方法,首先要将三维点云投影变换为视图。常见的三维点云投影方法包括正交投影和透视投影。由于原始点云是由一个个三维坐标点构成的三维对象,无法直接通过二维cnn来进行处理,因此需要首先将三维点云以二维视图的方式进行正交或者透视投影。这里我们选择使用正交投影,因为其保证了每个点的大小都是一样的,不会因为与相机的距离远近而大小不同。
[0076]
从mvcnn以及其他点云分类方法被提出以来,点云到多视图的转换方式,都是通过固定一个角度,然后在该角度上对点云进行360度旋转。如果想要得到多幅视图的投影,则
每隔360/n度做一次二维透视投影,其中n代表所需要的视图数量。
[0077]
很显然,这种固定的视点不利于模型进行泛化,并且可能会造成过拟合的问题。这是因为cnn是从预处理好的固定视点的二维视图中学习到物体的特征,而对于那些与固定视点差异较大的视图,cnn模型的判别力会下降。也就是说,固定视点的预处理方式使得cnn模型可能在某些角度的多视图上表现效果好,而在另一些角度上表现效果则比较差。为此,本实施例提出了一种固定-随机视点生成点云的多视图预处理算法,fsdc-net网络模型的多视图选取部分即采用该算法。
[0078]
图3是本实施例中固定-随机视点的多视图预处理算法的流程示意图。
[0079]
如图3所示,以汽车的三维点云为例,该算法共分为四步:
[0080]
步骤s1-1,对所有点云的各个点的位置信息进行归一化处理。
[0081]
也即点云空间位置的标准化。受到采集设备以及相关扫描参数设置的不同,原始点云的位置分布可能存在不统一的问题,进而造成虚拟相机针对不同物体需要频繁移动位置。因此,对所有点云各个点的位置信息进行归一化处理,让其位置分布围绕在三维坐标系原点周围,具体归一化方法见以下公式(1):
[0082][0083]
式中,p
i,j,k
表示点云中的任意一个点,min(p
x,y,z
)和max(p
x,y,z
)分别表示对点云中三维笛卡尔坐标系x,y,z三个坐标轴取最小值和最大值得到的点。
[0084]
步骤s1-2,选取固定视点,并基于该固定视点对归一化后的三维点云进行投影,得到固定视图集。
[0085]
通过标准化处理后的点云,需要对其进行视点选取。本实施例中,为操作方便,等价地将其转换为另一种方法,即固定虚拟相机,然后对物体在空间位置上进行旋转操作。具体地,通过人为定义一个旋转角度集合θ={(θ
x
,θy,θz)|θ
x
,θy,θz∈[0,360
°
)},其中θ
x
,θy,θz分别表示对原始点云在x,y,z上旋转的角度。将虚拟相机摆放在一个固定的位置,然后保持点云x,y,z中的某两个坐标轴不变,只在第三个坐标轴上等间隔角度地进行旋转,再使用虚拟相机进行二维投影,在该固定视点上选取所需要的视图。
[0086]
步骤s1-3,选取随机视点,并基于该随机视点对归一化后的三维点云进行投影,得到随机视图集。
[0087]
对原始点云在旋转角度集合ω上随机生成一个(θ
x
,θy,θz),将物体的中心点旋转到该角度。这时,再使用虚拟相机进行投影,即在该随机视点上获取所需要的视图。
[0088]
步骤s1-4,按照预定比例分别从固定视图集以及随机视图集中选取部分视图,并将其组合成多视图初始阶段的表征(以下简称为多视图表征)。
[0089]
若已经通过固定和随机的投影方法获得了固定视图集合fixed(θ)和随机视图集合rand(θ),视图总数量为n,随机视图数量为t,而第i个视图记作fi,则最终生成的多视图组合(表征)为ρ,可以表征为以下公式(2):
[0090][0091]
本实施例中,对于组合视图数的数量小于6张时,即n《6,直接取固定视点获得的视
图,即t=0;对于其他情况,则按照每5张固定视图,增加一张随机视图的方式,即过程如以下公式(3)所示:
[0092][0093]
如上所述,通过步骤s1,通过对三维点云投影得到了多视图。
[0094]
步骤s2,通过fsdc-net网络模型的局部特征处理部分提取所述多视图表征的局部特征。
[0095]
图4是本实施例中局部特征提取过程的示意图。
[0096]
如图4所示,局部特征提取过程是将经步骤s1得到的三维点云的多视图表征p中的第i个视图转换为局部的视图表征其中,对每个视图,转换过程包括如下步骤:
[0097]
步骤s2-1,将视图进行7
×
7卷积和最大池化。
[0098]
步骤s2-2,将经卷积和最大池化后的视图串行地经过n个fsdc层,其中,第i个fsdc层对输入特征xi并行地应用静态卷积和轻量化动态卷积这两个分支分别生成算子并分别提取特征,再通过两个可学习权重β和γ自适应地融合两个分支输出的特征,进而通过bn和relu层得到输出特征x
i+1
,作为该视图的局部特征。
[0099]
其中,步骤s2-2中,结合了传统静态卷积以及本实施例提出的轻量化动态卷积。
[0100]
卷积神经网络通过对图像进行一系列的卷积池化等操作来提取特征,其优点在于卷积核共享,适合高维数据的处理。但其缺点在于整个网络的参数在训练完成后不再发生改变,自适应差且不够灵活。而动态卷积能够很好地避免传统静态卷积的缺点,但其计算复杂度和内存开销又过于庞大。因此,针对动态卷积存在的缺点,本实施例中提出了一种更加轻量化的动态卷积。
[0101]
图5是本实施例中轻量化动态卷积的结构示意图。
[0102]
如图5所示,轻量化动态卷积生成算子的过程可以为分以下6步:
[0103]
步骤s2-2-1,batchsize维度的池化:定义batchpool函数,该函数通过对原始输入的特征图在batch维度进行融合,从而达到轻量化的效果,融合了batch维度最关键的特征信息,如以下公式(4)所示:
[0104][0105]
上式中,xi,z1分别表示batchpool前后的输入和输出特征,xi(j,c,h,w)表示输入的某一幅图像,b表示batchsize的大小,c,h,w分别表示输入的特征在通道、高度、宽度方向的集合。
[0106]
原始xi的维度为b
×c×h×
w,经过batchpool函数处理后x的i,z1的维度为1
×c×h×
w。
[0107]
步骤s2-2-2,不同感受野上的卷积操作:分别采用不同尺寸的卷积矩阵从不同感受野上对原始输入特征进行卷积操作。
[0108]
本实施例中,分别用1
×
1和3
×
3卷积矩阵从不同感受野上对原始输入特征进行卷积,即有以下公式(5),(6):
[0109]
z2=w1(z1)
ꢀꢀꢀ
(5)
[0110]
z3=w2(z1)
ꢀꢀꢀ
(6)
[0111]
上式中,w1,w2分别表示1
×
1和3
×
3卷积矩阵,z2,z3分别表示对应产生的输出特征。显然1
×
1卷积矩阵的感受野较小,是用来整合空间维度的每个像素点,而3
×
3卷积矩阵的感受野则较大,可以获得更多像素点周围的领域信息。
[0112]
步骤s2-2-3,融合不同感受野上提取到的信息:对输出特征z2,z3进行逐元素相加,然后经过一个空间平均池化函数,将其收缩为1
×c×1×
1维度的z4,见以下公式(7):
[0113][0114]
步骤s2-2-4,dropout避免过拟合:使用dropout层,使得fsdc层中的神经元按照一定比例随机失活,从而避免动态生成卷积过程中网络的过拟合问题,如以下公式(8):
[0115]
z5=f
dropout
(z4,p)
ꢀꢀꢀ
(8)
[0116]
上式中,p代表失活的比例,且0《p《1。
[0117]
步骤s2-2-5,动态权重的生成:通过使用一个1
×
1的卷积矩阵w3将原始动态权重改变至合适的通道数,然后使用激活函数sigmoid,使其具有非线性表征的同时,获得一个(0,1)之间的概率值,作为用于生成最终卷积层的动态权重,如以下公式(9)所示:
[0118]
ω=(ω1,...,ωi,...,ωn,)=σ
sigmoid
w3(z5)
ꢀꢀꢀ
(9)
[0119]
上式中,ω表示最终生成的动态卷积权重集合,ω=(ω1,ω2,
…
,ωn),其维度为1
×
n。
[0120]
步骤s2-2-6,动态卷积核的生成:将原始的n组卷积核表征为k,即k=(conv1,...,convi,...,convn),将其与动态生成的权重集合ω进行乘加操作,进而生成最终的动态卷积核,如以下公式(10):
[0121][0122]
通过上述步骤s2-1,即通过得到了用于进行轻量化动态卷积的动态卷积核。本实施例中,还对该轻量化动态卷积进行了性能分析,如表1所示。
[0123]
表1静态卷积、动态卷积和fsdc性能比较表
[0124][0125]
性能分析包括以下几部分:
[0126]
(1)参数量分析
[0127]
为便于说明,假设卷积操作的输入输出通道数为c
in
和c
out
并且大小都为c,输出特
征图的大小为n,n=h
out
×wout
,h
out
和w
out
即为输出特征图的高和宽,卷积核大小为k
×
k,batchsize大小为b。fsdc动态卷积由于使用了batchsize维度的池化操作,其将原来动态卷积的bc2k2的参数量减少到了c2k2,而传统的静态卷积其参数量也为c2k2,因此最终的参数量为2c2k2,如表1所示。
[0128]
(2)计算量分析
[0129]
由于传统静态卷积的计算量约为,如以下公式(11):
[0130][0131]
而本实施例的fsdc动态卷积部分,其主要的计算量为最终生成的动态卷积核参与卷积运算的部分。因此,其计算量可以参照传统静态卷积,同样也近似为2nc2k2,如公式(11)。所以总的计算量为4nc2k2,而一般的动态卷积计算量为bnc2k2,如表1所示。本实施例的fsdc卷积其参数量和计算量较传统静态卷积只是增加了一倍,而在一般情况下却远小于以往的动态卷积方法,因为以往的动态卷积方法其计算量会随着b的增大而增大,而相关文献也表明了为使模型获得更好的效果,b的取值往往会很大(b>>4)。因此,本实施例的方法在参数量和计算量大大减少的情况下却能很好地结合了传统静态卷积和动态卷积的优势。
[0132]
此外,步骤s2-2中,还涉及融合静态卷积和动态卷积的自适应过程。
[0133]
鉴于传统卷积和动态卷积各自有相应的优势,因此本实施例中,将静态卷积和轻量化动态卷积二者相结合,以充分利用二者的优势。具体地,如上所述,在对输入特征xi应用两个不同的卷积分支,分别得到输出特征xs和xd.这里xs表示静态卷积得到的输出特征,xd表示动态卷积得到的输出特征。并引入了两个可学习参数β和γ,作为输出特征xs和xd相应的权重。因此,最终的输出特征x
i+1
可以表征为以下公式(12):
[0134]
x
i+1
=β
·
xs+γ
·
xdꢀꢀꢀ
(12)
[0135]
显然,当β=1,γ=0时,输出特征x
i+1
将会退化为传统静态卷积所提取到的特征xs,而当β=0,γ=1时,输出特征x
i+1
将会变成轻量级动态卷积所提取到的特征xd。因此,通过β和γ两个参数进行不断优化,根据输入数据的不同能够自动赋予不同的权值,即表示更加强调静态卷积或者动态卷积学习到的特征,从而达到更好的特征提取效果。
[0136]
步骤s3,通过fsdc-net网络模型的全局特征融合部分将步骤s2得到的多个局部特征融合为全局特征。
[0137]
通过fsdc局部特征处理算子提取到的是一个个局部视图特征,需要通过某种方式将其融合为一个全局特征用于最终的分类。传统的方法使用最大池化、和池化等及其组合的方式来融合生成全局特征,这些方法虽然操作较为简单,但是没有考虑到不同视图的重要性程度,而是对所有视图使用同样的池化方法,效率不高。显然,对于具有较高区分度的局部视图特征,其需要具有一个较高的权重,而对于那些与其他物体相似性很高的局部视图特征则应该给予一个较低的权重。为此,本实施例提出了自适应的全局注意力池化,用于
将局部的多个视图特征根据自身的重要性程度融合为最终的一个全局视图表征,用于分类任务。
[0138]
图6是本实施例中自适应全局注意力池化的流程示意图。
[0139]
如图6所示,本实施例的自适应全局注意力池化能够很好地考虑到不同视图的影响力,使得最终的全局视图表征更具典型性和代表性,具体包括以下3个步骤:
[0140]
步骤s3-1,局部特征的全局平均池化(gap):对n个局部特征平均池化,得到一个n维向量,表示每个动态权重的初始值集合a1,过程可以表征为公式(13):
[0141][0142]
上式中,a1∈rn,而h
×
w为局部特征的宽和高,通常情况下h和w有一个值为1,而f
i,j
表示具体某个特征在某个下标位置的特征值。
[0143]
步骤s3-2,局部特征动态权重的生成:对全局平均池化后的n维向量依次应用两个输入输出均为n维的1
×
1卷积,并在两个1
×
1卷积之间加入一个非线性激活函数swish。这类似于senet注意力机构,但本实施例中没有使用通道压缩和扩展。此外,本实施例中使用swish来增加非线性表征,然后通过softmax激活函数得到各个视图的特征权重。具体生成过程如图6(a)和以下公式(14)所示:
[0144]
a2=σ
softmax
(conv1×1(σ
swish
(conv1×1(a1))))
ꢀꢀꢀ
(14)
[0145]
上式中,a2代表动态生成的权重集合,σ
softmax
,σ
swish
分别代表softmax和swish激活函数,conv1×1为输入输出通道均为n的1
×
1卷积。
[0146]
步骤s3-3,全局特征的融合:通过将每个视图与其学习到的特征权重相乘,然后再在视图维度进行相加,最终产生的一个全局视图特征f,其包含了所有局部视图的特征信息,全局特征融合处理过程如图6(b)所示,并表征为以下公式(15):
[0147][0148]
步骤s4,fsdc-net网络模型基于步骤s3得到的全局特征对输入的三维点云进行分类。
[0149]
基于上述步骤,本实施例中,所采用的训练和测试的数据集分别是modelnet40数据集和悉尼城市对象数据集。modelnet40是稠密点云数据集的代表,其完全由计算机合成,模拟了理想化条件下的点云数据。同时,又由于其没有任何噪声数据,因此可以用于测试本实施例的方法在点云分类上的精度。而悉尼城市数据集则是稀疏点云数据集的代表,其是通过lidar对城市户外场景物体扫描得到的数据,其含有大量的噪声,同时也存在局部残缺、点密度不均等问题,可以用于测试本实施例的方法在真实稀疏点云分类任务上的鲁棒性和高准确度。
[0150]
作为多视图三维点云分类常用的数据集之一,modelnet数据集是由普林斯顿大学所公开的数据集,其包含了662个对象类别,共127915个cad模型。而modelnet40则是选取了其中包含有飞机、浴缸、床、长凳在内的40个类别的物体,共12314个cad模型。悉尼城市对象数据集是通过使用激光雷达对澳大利亚悉尼城市的室外物体扫描所获得的真实稀疏点云数据集,其包含了车辆、行人、高楼和树木等常见的城市道路对象在内的26个物体类别,共631个点云。两个数据集的示例数据分别如图7和图8所示。
[0151]
本实施例中,基础硬件环境为nvidia titan xp双显卡以及64gb的ram,操作系统为ubuntu20.04,使用到的软件包括blender2.92.0,主要是对点云进行预处理操作。pytorch版本为1.7.1,cuda版本为10.1,学习率设置为0.0001,单视图的batchsize为128,6视图的batchsize为16,12视图的batchsize设置为8。对于原始modelnet40网格数据集,我们通过对每个网格采点来构造原始modelnet40对应的点云数据集;对于悉尼城市点云数据集,由于已经是扫描得到的点云格式,所以不需要再进行采点操作。对于训练的周期而言,modelnet40数据集为30epoch,悉尼城市数据集为50个epoch。
[0152]
本实施例中,采用以下度量准则:
[0153]
对于modelnet40数据集,主要使用总体准确度(overall accuracy,oa)和平均准确度(average accuracy,aa)来对比本实施例的fsdc-net与现有技术中的网络模型,评价模型的好坏。为便于说明,假设δ表示测试集的总体样本数,δ
true
表示测试集上被模型分类正确的样本数,δi表示测试集上某一类别的样本数,δ
i(true)
表示测试集上该类别被模型正确分类的样本数,ci为第i类别的准确度,n为类别数,则oa和aa具体计算过程分别如公式(16),(17):
[0154][0155][0156]
对于悉尼城市对象数据集,每个类别物体的数据量差异较大。例如car的样本数为88,而scooter的样本数只有1。显然,这是不公平的,因为正确判断小样本相对大样本需要更少的推理消耗,但对最终的aa影响权重确实相同的。aa会受到小样本类别的影响,产生剧烈的波动。取而代之,使用f1分数值来代替aa,其能够有效减少此类问题对最终评价的影响。因此,悉尼城市对象数据集的度量准则为oa和f1分数值。f1分数值的计算方法见公式(18):
[0157][0158]
上式中,p为所有类别的平均精确率(precision),r为所有类别的平均召回率(recall)。
[0159]
以下的表2-7示出了本实施例的方法与现有技术中其他分类方法(模型)的比较结果。
[0160]
表2 modelnet40数据集上的分类性能比较表
[0161][0162]
表3悉尼城市数据集上的分类性能比较表
[0163][0164][0165]
如表2-3所示,将本实施例的fsdc-net与现有技术中最先进的多种点云分类模型进行了比较。最先进的点云分类模型又可进一步分为三类:基于体素的voxelnet、vrn、orion、lightnet,基于直接点云的pointnet、pointnet++、pointgrid、pointasnl、ecc以及基于视图的mvcnn、gvcnn和mhbn。
[0166]
从表2可以看出,在modelnet40数据集上,本实施例的fsdcnet在6视图上的oa和aa分别达到了94.6%和93.3%,其他方法中最好的mhbn在6视图上的oa和aa分别为94.1%和92.2%,我们的模型与之相比分别高出了0.5%和1.1%。而12视图下的fsdcnet其oa和aa更是达到了95.3%和93.6%,在所有算法模型中的oa和aa指标都是最高的。
[0167]
从表3可以看出,在悉尼城市对象数据集上,我们的fsdcnet在6视图上的oa为85.3%,f1分数值为83.6%。所列举的上述点云分类算法模型当中,分类准确度性能最高的模型为lightnet,其f1分数值为79.8%。我们的模型比lightnet在f1分数值上提高了3.8%。fsdcnet在12视图上的oa为85.5%,f1分数值为83.7%,与另外几个点云分类算法模型相比,在悉尼城市数据集上的各项评价指标也是最优异的。
[0168]
因此,表2-3的结果表明了本实施例的fsdc-net模型具有广泛的适用性,在稠密点
云和稀疏点云上均能够取得最先进的分类效果。一方面,传统的固定视点选取多个视图,其不利于模型的泛化,即在未见过的视点或者差异较大的视点上,模型的准确率会大幅度下降。与之相比较,我们采用的是固定加随机的视点选取方法,可以增加模型的泛化性能,即提高模型在未知视点上分类的准确率,更加灵活。另一方面,动态和静态卷积融合的方式,作为我们的局部特征提取算子,通过自适应的方式可以结合二者的优势,达到更好的特征提取效果,而与之相比较的算法模型大多数采用的是传统的静态卷积,无法提取到更加丰富的细粒度信息。此外我们所提出的模型是通过自适应的全局注意力池化,为每一幅视图根据其重要性程度赋予不同权重,使得最终融合生成的一幅全局视图更具表征性。这也是其他点云的分类的池化方法如平均池化、最大池化等所达不到的效果。
[0169]
表4 modelnet40数据集上不同视点选取方法的分类性能比较表
[0170][0171]
表5悉尼城市数据集上不同视点选取方法的分类性能比较表
[0172][0173][0174]
如表4-5所示,使用两种不同的视点选取方法,第一种为固定视点选取多视图,第二种为固定加随机视点选取多视图,并且在6视图和12视图上比较了两种方法的aa度量指标。依据上述公式(3),在固定加随机的视点选取方法中,6视图为5幅固定视图加1幅随机视图,12视图为10幅固定视图和2幅随机视图。
[0175]
从表4-5可以看出,无论是modelnet40数据集还是悉尼城市对象数据集,其在6视图和12视图上的aa指标在使用固定加随机视点选取多视图方法后,都有一定比例的提高。
[0176]
从表4可以看出,在modelnet数据集上,6视图和12视图的数据,如果使用固定加随机视点,其oa分别为94.6%、95.3%,而只使用固定视点,其oa分别为94.1%和94.7%,提高了0.5%和0.6%。
[0177]
从表5可以看出,在悉尼城市对象数据集上,fsdcnet在6视图和12视图上,如果使用固定加随机视点,其oa分别为85.3%和85.5%,而只使用固定视点,其oa分别为84.1%和84.9%,分别提高了0.7%和0.8%。
[0178]
因此,可以得出,在传统的固定视点选取到的视图中,组合一些由随机视点获得的视图,可以增加模型分类精度的准确性,甚至是鲁棒性,使得模型能够学习到一些在固定视点下学习不到的特征,进而提高最终的性能。但是随机视点选取视图的数量不能过多,否则模型的准确度会急剧下降。这是因为这些随机视点生成的不同视图间的差异性较大,进而
会降低训练集和测试集上数据的相关性,甚至完全不同,最终影响到分类的准确性。因此,本实施例中,采用了每6张视图插入一张随机视点选取视图的方法。
[0179]
表6 modelnet40数据集上不同视图数量的分类性能比较表
[0180][0181]
表7悉尼城市数据集上不同视图数量的分类性能比较表
[0182][0183][0184]
如表6-7所示,通过评价fsdcnet在不同视图数量上的分类性能,能够在分类性能和计算存储代价之间取得平衡。在实验中设定视图数量包括单视图、6视图、12视图,来比较fsdcnet与其他最先进的多视图分类模型在modelnet40和悉尼城市对象数据集上的oa、aa和f1的评价指标。
[0185]
从表6可以看出,本实施例的fsdc-net在modelnet40数据集上,单视图上的oa和aa指标分别为93.8%、91.2%,明显比mvcnn在6视图和12视图上的oa指标高出1.8%和2.3%,比gvcnn在12视图上的oa指标高出1.2%。而fsdcnet在6视图上的oa和aa指标为94.6%和93.2%,同类型的mhbn其对应指标达到了94.1%和92.2%,与其相比我们的fsdcnet分别高出了0.5%和1.0%。fsdcnet在12视图上达到了95.3%和93.6%,oa和aa指标更是远远高于当下这些最先进的多视图分类模型。
[0186]
从表7可以看出,本实施例的fsdc-net在悉尼城市对象数据集上,其oa指标和f1分数值为81.2%和80.1%,6视图为85.3%和83.6%,12视图的oa则达到了85.5%和83.7%。而与之相比较的模型当中性能指标很好的lightnet,其f1分数值仅为79.8%,而本实施例的fsdc-net仅在单视图上的f1指标已经比其高出了0.3%,在6视图和12视图上更是高出了3.8%和3.9%,这也论证了其效果是最优异的。值得注意的是,无论在modelnet40还是悉尼城市对象数据集上,fsdc-net在单视图上的分类性能已经好于绝大多数所比较的点云分类
模型。这也证明本实施例的模型所达到的的最为先进的水平。
[0187]
总体来看,随着视图数量的增加,本实施例的fsdc-net关于衡量模型好坏的oa、aa和f1等度量指标值也在增加,而相比之下mhbn在12视图上的分类性能却比6视图上的还要差,这表明了fsdc-net相比较mhbn具有更加突出的稳健性,模型不容易出现抖动现象。但modelnet40数据集上的相应指标值增加的效果明显好于悉尼城市对象数据集。这主要是由于悉尼城市数据集作为真实场景下的稀疏点云数据集,其整体样本数量较少,因此模型没有足够的学习数据。此外,由于悉尼城市对象数据集是真实场景下通过激光雷达扫描得到的数据,其中包含大量噪声,而视图数量增加的同时,噪声也在增加,因此模型不可避免地学习到了更多的噪声数据,这最终也会影响到分类的性能。
[0188]
表8不同局部特征提取架构上分类性能的比较表
[0189][0190][0191]
如表8所示,fsdc-net局部特征提取算子可以分为静态卷积和动态卷积两部分,而静态卷积部分事实上我们又可以使用现有的任意二维cnn模型的卷积。在这里,我们使用了最为常用的三个模型,分别是resnet50、resnext50、senet50,并且分别比较了加入和不加入我们所提出的轻量化动态卷积情况下,模型的oa、aa和f1指标。需要注意的是,这里为了权衡存储开销和精度提升,所有的比较均是在6视图下进行的。从表5中可以看出,在加入我们所提出的轻量化动态卷积以及自适应的权重参数融合后,两个数据集上的分类精度均有一定的提高。对于resnet50网络,其在modelnet40数据集上的oa和aa分别为93.0%和92.0%。在加入了轻量化动态卷积分支后,其oa和aa分别为93.8%和92.6%,整体提高了0.8%,0.6%。而在悉尼城市对象数据集上,原始的resnet50其oa和f1分别为83.1%和81.7%,在加入了轻量化动态卷积后,oa和f1变为了84.5%和82.3%,分别提高了1.4%和0.6%。同理,在表8中,可以看出,对于resnext50网络,其在modelnet40数据集上的oa和aa分别提高了1.2%和0.5%,而在悉尼城市数据集上的oa和f1分别提高了1.0%和0.8%。对于senet50网络,其在modelnet40数据集上的oa和aa分别提高了1.1%,1.0%,而在悉尼城市对象数据集上则提高了1.3%和1.4%。通过上述的比较,不难发现并行地使用传统静态卷积和我们所提出的轻量化动态卷积分支后,度量指标均有了不同程度的提高。
[0192]
究其原因,本实施例的轻量化动态卷积可以提取到传统静态卷积提取不到的一些细粒度特征信息,而这些细节特征将更加有助于最终的模型分类,使得分类效果普遍好于没有加入动态卷积分支的模型。同时,轻量化动态卷积和传统静态卷积以自适应方式结合在一起,其能够更好地将不同维度的特征整合在一起,因此与传统的静态卷积模型相比,获得了更高的分类性能。
[0193]
表9不同全局池化方法分类性能的比较表
[0194][0195]
如表9所示,为了在存储开销和精度提升上做出权衡,可将9视图作为相应的评价基准。通过将最为常用的几种池化方法,包括最大池化、平均池化、最大池化加平均池化、软池化方法与fsdc-net的自适应注意力池化方法进行比较,证明本实施例的fsdc-net池化方法的最佳有效性。由表9可以看出,fsdc-net在modelnet40上的oa和aa分别为94.6%和93.3%,对应的最大池化为94.2%和92.5%。fsdc-net的池化方法比最大池化分别高出0.4%和0.8%。而在悉尼城市对象数据集上,fsdc-net的oa和f1分别为85.3%和83.6%,对应的最大池化为84.9%和83.1%,本实施例的池化方法比最大池化分别高出了0.4%和0.5%。这也证明了本实施例的自适应全局注意力池化在已有的方法中达到了最高的性能。这是因为自适应全局注意力池化能够对每一幅不同的局部视图特征,根据其重要性程度学习出一个权重,然后将不同视图特征以学到的权重融合到最终的一幅全局视图表征中去,即强化重要特征,弱化不明显的特征,整合多幅局部视图中的最关键信息,从而有助于最终的三维点云的分类判定。
[0196]
本实施例中,未详细说明的部分为本领域的公知技术。
[0197]
实施例作用与效果
[0198]
根据本实施例提供的基于动静态卷积融合神经网络的多视图三维点云分类方法,针对传统固定视点选取多视图方法可能存在预处理阶段过拟合的问题,采用了固定-随机视点的多视图预处理算法,提高了模型在不同视图上的泛化性能;同时为了提取更丰富的细粒度特征信息,采用了静态和动态卷积的自适应权重融合算子,用于局部特征提取;此外,采用了自适应的全局注意力池化的方法,能够更加有效地融合不同视图上的局部特征,获得点云全局表征中的最关键细节。综上所述,相较于现有技术中最先进的一些三维点云分类算法模型及方法,本发明的方法总体泛化性能更好、整体分类性能更好且融合效率高。
[0199]
实施例中,可以看到,本实施例的方法在oa、aa和f1等度量指标上都取得了最高的分类水平。通过在modelnet40数据集和悉尼城市对象数据集上进行实验,显示了本实施例的方法不仅适用于稠密点云数据的分类,对于有噪声、局部块残缺的稀疏点云同样也能取得最优异的效果,这证明了本实施例的方法及神经网络fsdcnet具有广泛的适用性。
[0200]
上述实施例仅用于举例说明本发明的具体实施方式,而本发明不限于上述实施例的描述范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1