一种基于深度学习的斑岩浅成低温热液型矿产预测方法及系统与流程
1.本发明属于矿产资源预测技术领域,特别是关于一种基于深度学习的斑岩-浅成低温热液型矿产资源预测方法及系统。
背景技术:
2.随着地质大数据指数形式增长以及人工智能的兴起,现有技术中有尝试采用支持向量机、卷积神经网络等机器学习方法应用于矿产资源预测中。与传统方法相比,机器学习具有更高的预测精度,特别是针对数据量大、维数高并且输入变量之间存在复杂的非线性关系,或者输入变量有着较为复杂的统计分布特征具有明显的优势。
3.现有技术主要存在以下两方面的技术缺陷:
4.一是目前机器学习方法采用地质、地球物理、地球化学、遥感数据作为预测变量。但地质要素(如断裂、岩性)的不确定性不可避免地会给机器学习带来影响,特别是在青藏高原等西部艰险地区,基础地质调查相对薄弱。并且对于遥感数据,目前使用的是光谱测量数据,不是提取的矿物信息,而明矾石、叶腊石、地开石等蚀变矿物对斑岩型-浅成低温热液型矿床的勘查具有良好的指示作用,特别是明矾石是高硫型浅成低温热液矿床标志性矿物。
5.二是目前没有明确提取预测数据的空间分辨率。过小的空间分辨率会造成数据量过大、价值密度低、模型运行速度慢,而过大的空间分辨率会导致分类精度降低。
技术实现要素:
6.本发明的目的在于提供一种基于深度学习的斑岩-浅成低温热液型矿产资源预测方法及系统,其能够解决矿产资源预测精度低的技术问题。
7.本发明提供了一种基于深度学习的斑岩-浅成低温热液型矿产资源预测方法,包括以下步骤:
8.s1,获取目标矿区的高光谱遥感数据、地球化学数据及地球物理数据,并将各组数据均采样成60m分辨率;
9.s2,对所述地球化学数据及地球物理数据进行归一化处理,以去除数据量纲的影响;
10.s3,选择目标矿区及外延100m范围内为正样本,目标矿区外延400m以外为负样本,判定为无矿的地区为负样本,按照7:2:1分为训练集、验证集、测试集;
11.s4,构建基于自注意力机制的深度全连接神经网络的模型,并利用上一步构建的训练集对模型进行训练,同时利用验证集、测试集对模型进行精度验证,当验证精度收敛到稳定状态即完成训练;
12.s5,训练完成后得到预测结果数据,得到1表示有矿,得到0表示无矿。
13.优选地,所述目标矿区为浅成低温热液型矿床或斑岩型矿床。
14.优选地,所述s1具体包括:
15.首先,对目标矿区高光谱遥感数据进行预处理获得反射率数据,剔除受水汽影响的坏波段后再进行最小噪声分类变换(mnf)、纯净像元指数(ppi)分析;
16.然后,利用混合调谐匹配滤波方法(mtmf)和光谱角方法(sam)相结合的方式,提取矿物数据信息并重采样成60m分辨率。
17.优选地,所述矿物数据信息包括明矾石、叶腊石、地开石、高岭石、绿泥石/绿帘石、褐铁矿、高al绢云母、中al绢云母、低al绢云母、白云石、方解石、蒙脱石的数据信息。
18.优选地,所述s1具体包括:
19.对地球化学数据利用gs+软件优选变异函数模型,根据优选结果进行克里金插值成60m分辨率;
20.对地球物理数据进行化极、水平梯度膜、垂向一阶导数、向上延拓处理,采样成60m空间分辨率。
21.优选地,所述s4具体包括:
22.1)将高光谱遥感数据、地球化学数据及地球物理数据中所提取的各预测变量特征信息输入至模型,并进行相似度计算得到权重;
23.2)使用softmax函数对权重进行归一化;
24.3)将权重和相应的键值value进行加权求和得到最终的注意力分数。
25.优选地,所述模型包括1层自注意力机制和4层全连接神经网络。
26.本发明还提供了一种基于深度学习的斑岩浅成低温热液型矿产预测系统,所述系统用于实现基于深度学习的斑岩浅成低温热液型矿产预测方法的步骤,包括:
27.预测变量准备模块,获取目标矿区的高光谱遥感数据、地球化学数据及地球物理数据,并将各组数据均采样成60m分辨率;
28.预测变量数据处理模块,对所述地球化学数据及地球物理数据进行归一化处理,以去除数据量纲的影响;
29.训练样本选取模块,选择目标矿区及外延100m范围内为正样本,目标矿区外延400m以外为负样本,判定为无矿的地区为负样本,按照7:2:1分为训练集、验证集、测试集;
30.模型构建模块,构建基于自注意力机制的深度全连接神经网络的模型,并利用上一步构建的训练集对模型进行训练,同时利用验证集、测试集对模型进行精度验证,当验证集精度收敛到稳定状态即完成训练;
31.找矿靶区识别模块,训练完成后得到预测结果数据,利用torch.max()函数进行输出,输出结果为预测概率最大的对应分类,作为二分类问题,得到1表示有矿,得到0表示无矿。
32.本发明还提供了一种电子设备,包括存储器、处理器,所述处理器用于执行存储器中存储的计算机管理类程序时实现基于深度学习的斑岩浅成低温热液型矿产预测方法的步骤。
33.本发明还提供了一种计算机可读存储介质,其上存储有计算机管理类程序,所述计算机管理类程序被处理器执行时实现基于深度学习的斑岩浅成低温热液型矿产预测方法的步骤。
34.与现有技术相比,根据本发明的一种基于深度学习的斑岩浅成低温热液型矿产预
测方法及系统,其中方法包括:预测变量准备、预测变量数据处理、训练样本选取、模型构建及找矿靶区识别。该方案基于60m空间分辨率提取地球物理、地球化学、高光谱矿物信息数据,不使用地质要素,有效避免了地质要素不确定性的影响,提高了模型的预测精度。在矿产预测领域中,首次构建自注意力机制全连接神经网络进行监督分类式矿产资源预测,增强了预测变量间关联信息的获取能力,提升预测变量有效特征的筛选能力,从而改善了矿产资源预测精度,为有效开展机器学习在矿产资源应用提供技术基础。
附图说明
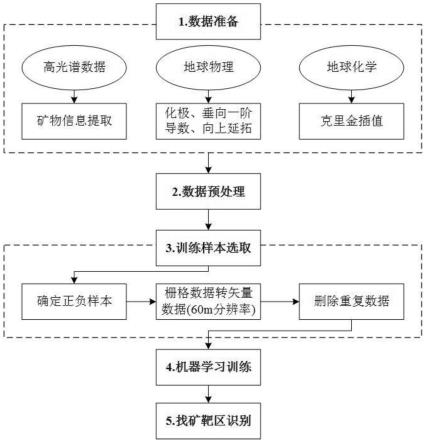
35.图1为本发明提供的一种基于深度学习的斑岩-浅成低温热液型矿产资源预测方法流程图;
36.图2为本发明提供的一种可能的电子设备的硬件结构示意图;
37.图3为本发明提供的一种可能的计算机可读存储介质的硬件结构示意图;
38.图4为本发明提供的一种基于深度学习的斑岩浅成低温热液型矿产预测方法的训练区与预测区划分示意图。
具体实施方式
39.下面结合附图,对本发明的具体实施方式进行详细描述,但应当理解本发明的保护范围并不受具体实施方式的限制。
40.除非另有其它明确表示,否则在整个说明书和权利要求书中,术语“包括”或其变换如“包含”或“包括有”等等将被理解为包括所陈述的元件或组成部分,而并未排除其它元件或其它组成部分。
41.如图1和图4所示,根据本发明优选实施方式的一种基于深度学习的斑岩浅成低温热液型矿产预测方法,包括以下步骤:
42.s1,获取目标矿区的高光谱遥感数据、地球化学数据及地球物理数据,并将各组数据均采样成60m分辨率;
43.s2,对所述地球化学数据及地球物理数据进行归一化处理,以去除数据量纲的影响;
44.s3,选择目标矿区及外延100m范围内为正样本,目标矿区外延400m以外为负样本,判定为无矿的地区为负样本,按照7:2:1分为训练集、验证集、测试集;
45.s4,构建基于自注意力机制的深度全连接神经网络的模型,并利用上一步构建的训练集对模型进行训练,同时利用验证集、测试集对模型进行精度验证,当验证集精度收敛到稳定状态即完成训练;
46.s5,训练完成后得到预测结果数据,利用torch.max()函数进行输出,输出结果为预测概率最大的对应分类,作为二分类问题,得到1表示有矿,得到0表示无矿。
47.斑岩成矿系统广义上指受控于同一构造-岩浆-热力学体系,围绕多期侵入的中-酸性岩体发育的,在时空上相依,成因上与浅成、超浅成侵入作用和陆相火山-次火山作用有关的一系列共生矿床类型组合。统计研究表明,这种斑岩成矿系统目前已为世界提供了约75%的铜、50%的钼、几乎全部的铼,以及20%以上的金,同时也是银、钯、碲、硒、铋、铅、锌等金属的主要来源之一,是目前矿床学界研究的热点和工业界最重要的勘查目标之一。
斑岩-浅成低温热液成矿系统是特指斑岩成矿系统中斑岩成矿系统中斑岩型矿化系统与其顶部或侧边部的浅成低温热液型矿化系统彼此共生的一种矿化共生组合类型。
48.在一个具体的实施场景中:
49.第一步,预测变量准备。预测变量包括高光谱遥感数据、地球化学数据及地球物理数据。通过对三种数据分别进行提取便可以得到均为60m分辨率的数据信息,以便于后续的数据处理。
50.1.高光谱遥感数据:对试验区高光谱数据进行预处理获得反射率数据,剔除受水汽影响等坏波段后进行最小噪声分类变换(mnf)、纯净像元指数(ppi)分析。利用混合调谐匹配滤波方法(mtmf)和光谱角方法(sam)相结合的方式,提取明矾石、叶腊石、地开石、高岭石、绿泥石/绿帘石、褐铁矿、高al绢云母、中al绢云母、低al绢云母等12种矿物。重采样成60m分辨率。
51.2.地球化学数据:即对优于1∶5万水系沉积物测量数据,利用gs+软件优选变异函数模型,根据优选结果进行克里金插值成60m分辨率。
52.3.地球物理数据:即对优于1∶5万高精度磁层数据,进行化极、水平梯度膜、垂向一阶导数、向上延拓处理,采样成60m空间分辨率。
53.第二步,预测变量数据处理。对地球化学数据、地球物理数据进行归一化(min-max方法)处理,去除数据量纲的影响。高光谱遥感数据的提取结果本身为0(无)、1(有)二值化,不需要进行归一化处理。
54.地球化学数据:即水系沉积物测量数据ag、as、au、bi、cr、cu、hg、mn、mo、ni、pb、sb、sn、w、zn共15种元素。
55.地球物理数据:高精度磁测数据,进行化极、水平梯度膜、垂向一阶导数、向上延拓处理。
56.高光谱遥感数据:明矾石、叶腊石、地开石、高岭石、绿泥石/绿帘石、褐铁矿、高al绢云母、中al绢云母、低al绢云母、白云石、方解石、蒙脱石共12种矿物。
57.第三步,训练样本选取。选择已知矿区及外延100m范围内为正样本;已知矿区外延400m以外,以及基于专家知识认为无矿的地区为负样本。按照7:2:1分为训练集、验证集、测试集。
58.第四步,模型构建。构建基于自注意力机制的深度全连接神经网络的模型,并利用上一步构建的训练集对模型进行训练,同时利用验证集、测试集对模型进行精度验证,当验证集精度收敛到稳定状态即可完成训练。
59.自注意力(self-attention)机制由google机器翻译团队在2017年提出(vaswani et al.,2017),基本思想是计算不同部分的权重后进行加权求和,最后的效果是对不同部分予以不同程度的关注。自注意力机制采用并行学习,不分先后顺序提取每个特征与其他特征的关系,即缩短计算时间,又解决长距离的依赖问题。对于输入ai∈r(i=1,2,
…
,n)通过线性映射到三个不同的空间,分别得到查询矩阵q(query)、键矩阵k(keys)和值矩阵v(value),通过训练得到ai线性映射到q、k、v的权重矩阵wq、wk、wv。
60.计算注意力分数时主要分为三步:
61.1)将ai的query和每个key(包括ai)进行相似度计算得到权重,常用的相似度函数有点积,感知机等;
62.2)使用softmax函数对权重进行归一化;
63.3)将权重和相应的键值value进行加权求和得到最终的注意力分数。注意力运算数学公式为(vaswani et al.,2017):
[0064][0065]
式中dk是k的向量纬度,主要对权重进行缩放,防止向量维度太高时计算出的点积结果过大。
[0066]
其中,自注意力机制的输入ai,即通过对高光谱遥感数据、地球化学数据及地球物理数据所提取的各预测变量特征信息,输出则为每个预测变量特征信息经过计算后的注意力分数,分数越高越重要。
[0067]
基于自注意力机制的深度全连接神经网络的模型由1层自注意力机制和4层全连接神经网络组成。该机器学习模型首次应用矿产预测中。
[0068]
第五步,找矿靶区识别。基于上一步模型运行获得的预测结果数据,得到0或1数值,1是有矿,0是无矿。专家结合地质资料进行找矿靶区筛选识别。
[0069]
本实施例方案具有以下两个创新点:
[0070]
1、预测变量的提取空间分辨率为60m;
[0071]
2、预测变量使用优于30m分辨率高光谱遥感数据提取的矿物信息,优于1:5万比例尺的地球物理、地球化学数据,不使用地质(如断裂、岩性、蚀变带等)。
[0072]
本发明实施例还提供了一种基于深度学习的斑岩浅成低温热液型矿产预测系统,所述系统用于实现如前面所述的基于深度学习的斑岩浅成低温热液型矿产预测方法的步骤,包括:
[0073]
预测变量准备模块,获取目标矿区的高光谱遥感数据、地球化学数据及地球物理数据,并将各组数据均采样成60m分辨率;
[0074]
预测变量数据处理模块,对所述地球化学数据及地球物理数据进行归一化处理,以去除数据量纲的影响;
[0075]
训练样本选取模块,选择目标矿区及外延100m范围内为正样本,目标矿区外延400m以外为负样本,判定为无矿的地区为负样本,按照7:2:1分为训练集、验证集、测试集;
[0076]
模型构建模块,构建基于自注意力机制的深度全连接神经网络的模型,并利用上一步构建的训练集对模型进行训练,同时利用验证集、测试集对模型进行精度验证,当验证精度收敛到稳定状态即完成训练;
[0077]
找矿靶区识别模块,训练完成后得到预测结果数据,得到1表示有矿,得到0表示无矿。
[0078]
请参阅图2为本发明实施例提供的电子设备的实施例示意图。如图2所示,本发明实施例提了一种电子设备,包括存储器1310、处理器1320及存储在存储器1310上并可在处理器1320上运行的计算机程序1311,处理器1320执行计算机程序1311时实现以下步骤:s1,获取目标矿区的高光谱遥感数据、地球化学数据及地球物理数据,并将各组数据均采样成60m分辨率;
[0079]
s2,对所述地球化学数据及地球物理数据进行归一化处理,以去除数据量纲的影
响;
[0080]
s3,选择目标矿区及外延100m范围内为正样本,目标矿区外延400m以外为负样本,判定为无矿的地区为负样本,按照7:2:1分为训练集、验证集、测试集;
[0081]
s4,构建基于自注意力机制的深度全连接神经网络的模型,并利用上一步构建的训练集对模型进行训练,同时利用验证集、测试集对模型进行精度验证,当验证集精度收敛到稳定状态即完成训练;
[0082]
s5,训练完成后得到预测结果数据,利用torch.max()函数进行输出,输出结果为预测概率最大的对应分类,作为二分类问题,得到1表示有矿,得到0表示无矿。
[0083]
请参阅图3为本发明提供的一种计算机可读存储介质的实施例示意图。如图3所示,本实施例提供了一种计算机可读存储介质1400,其上存储有计算机程序1411,该计算机程序1411被处理器执行时实现如下步骤:s1,获取目标矿区的高光谱遥感数据、地球化学数据及地球物理数据,并将各组数据均采样成60m分辨率;
[0084]
s2,对所述地球化学数据及地球物理数据进行归一化处理,以去除数据量纲的影响;
[0085]
s3,选择目标矿区及外延100m范围内为正样本,目标矿区外延400m以外为负样本,判定为无矿的地区为负样本,按照7:2:1分为训练集、验证集、测试集;
[0086]
s4,构建基于自注意力机制的深度全连接神经网络的模型,并利用上一步构建的训练集对模型进行训练,同时利用验证集、测试集对模型进行精度验证,当验证集精度收敛到稳定状态即完成训练;
[0087]
s5,训练完成后得到预测结果数据,利用torch.max()函数进行输出,输出结果为预测概率最大的对应分类,作为二分类问题,得到1表示有矿,得到0表示无矿。
[0088]
有益效果:
[0089]
1.通过增加高光谱遥感矿物信息提取数据、不使用地质要素,有效避免了地质要素不确定性的影响,提高了模型的预测精度。
[0090]
2.对于空间分辨率优于30m的高光谱数据,比例尺优于1:5万的地球化学、地球物理测量数据,合理地确定了预测变量的提取空间分辨率为60m。结果表明,模型预测的找矿靶区占研究区总面积的~2.96%,覆盖了100%的潜在矿床。目前,通过机器学习圈定的找矿靶区占研究区总面积7-~25%,覆盖77-~100%的潜在矿床。本技术有效提高了预测精度,缩小了潜在的找矿靶区。
[0091]
本领域内的技术人员应明白,本技术的实施例可提供为方法、系统、或计算机程序产品。因此,本技术可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本技术可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
[0092]
本技术是参照根据本技术实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实
现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0093]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0094]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0095]
前述对本发明的具体示例性实施方案的描述是为了说明和例证的目的。这些描述并非想将本发明限定为所公开的精确形式,并且很显然,根据上述教导,可以进行很多改变和变化。对示例性实施例进行选择和描述的目的在于解释本发明的特定原理及其实际应用,从而使得本领域的技术人员能够实现并利用本发明的各种不同的示例性实施方案以及各种不同的选择和改变。本发明的范围意在由权利要求书及其等同形式所限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1