一种主客观可解释的双向图神经网络的蒙古语谣言检测方法
1.本发明属于人工智能技术领域,特别涉及一种主客观可解释的双向图神经网络的蒙古语谣言检测方法。
背景技术:
2.谣言检测被称为净化互联网生态不可或缺的一环,现有的谣言检测方法包括人工谣言检测方法、基于机器学习的谣言检测方法和基于深度学习的谣言检测方法。
3.近些年来,伴随着深度学习的快速发展,各类模型结构层出不穷。而与谣言检测中广泛被提及的推文深度传播模式相比较,谣言的广泛分散的结构被经常忽略;另外现有的谣言检测策略通常会提供检测标签,而忽略其解释,但是提供证据来解释为什么可疑文章是谣言是必不可少的。
4.对于蒙古语而言,由于谣言传播不仅包含传播的模式还包含谣言扩散的结构。其次谣言检测不仅需要是否谣言的标签,还需要支持其是否谣言标签的证据解释。所以其谣言检测中的传播模式分析和可解释性会面临更多的难题。
技术实现要素:
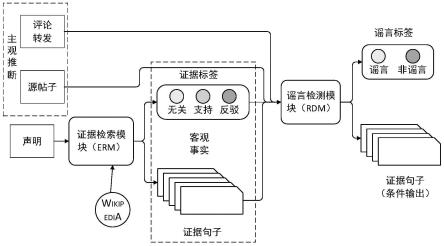
5.为了克服上述现有技术的缺点,本发明的目的在于提供一种主客观可解释的双向图神经网络的蒙古语谣言检测方法,采用证据检索子任务和谣言预测子任务双任务的方式,对谣言进行检测。
6.为了实现上述目的,本发明采用的技术方案是:
7.一种主客观可解释的双向图神经网络的蒙古语谣言检测方法,包括如下步骤:
8.步骤1,利用证据检索模块检索证据,包含三步:文档检索、证据检索和声明验证;
9.步骤2,构造双向树形图和证据星形图两个异构图,所述双向树形图是一个自底向上和自顶向下的双向图神经网络,其利用具有自顶向下的谣言传播有向图的图卷积神经网络学习谣言传播模式;利用具有自底向上的谣言扩散图的图卷积神经网络捕获谣言扩散模式;所述证据星形图中,将源帖子即检测对象位于中心,所有证据节点围绕其周围,表示星形结构中的一个角度;
10.步骤3,基于所述双向树形图,构造谣言检测模型;
11.步骤4,基于双向树结构和星形结构的信息传输的k次迭代后,得到两种嵌入结果的最终表示,将两种嵌入结果的最终表示连接在一起,然后传递到多层感知机中进行最终预测;
12.步骤5,利用该模型进行蒙古语谣言检测并得到分类标签和证据解释。
13.在一个实施例中,步骤1所述文档检索,是采用关键字匹配算法爬取百科类数据中的相关证据文章;所述证据检索,是从检索到的证据文章中提取句子级证据;所述声明验证,是基于句子级证据,预测声明与证据的关系为“支持”、“反驳”或“无关”。
14.在一个实施例中,步骤1利用语义nlp工具包从给定的声明中提取潜在实体,通过
分析实体,用api过滤证据文章,然后从检索到的文档中,erm以与声明相关的句子的形式提取客观事实作为预测证据;最后,erm中的一个验证组件对给定的陈述和检索到的证据进行预测,并验证声明与证据之间的关系是“支持”、“反驳”还是“无关”。
15.在一个实施例中,步骤2所述双向树形图中,对话结构是树形的,树的根节点为源帖子,每个节点代表一条评论,节点通过其回复关系连接。
16.在一个实施例中,步骤2所述证据星形图的创建如下所示:
17.ge=(ve,ge)
[0018]ve
=[c,e1,e
2,
,
…ek
]
[0019]ee
={(c,e1),(c,e2),
…
(c,ek)}
[0020]
其中,ge是一个由顶点集ve和边集ee组成的证据图对象,顶点集ve包括检测对象c和证据句子e1,e2,
…
,ek,ek表示第k个证据句子,边缘集ee表示各证据句子和检测对象之间的关系。
[0021]
在一个实施例中,步骤3谣言检测模型中,通过自顶向下的图卷积神经网络获得谣言传播特征,通过自底向上的图卷积神经网络获得谣言扩散特征;所述自底向上的图卷积神经网络,递归访问从底部的叶子节点到根节点的每个节点,为每个子树生成一个特征向量,使得具有相似上下文的子树被投影到表示空间中的邻近区域;所述自顶向下的图卷积神经网络,为每个源帖子生成一个考虑其传播路径的增强特征向量,每个节点的表示通过组合它自己的输入和它的父节点计算,从根节点递归地进行到其子节点,直到到达所有叶子节点,其中根节点代表源帖子,子节点代表对父节点做出的评论和转发,每个节点通过其回复关系连接起来。
[0022]
在一个实施例中,步骤4基于双向树结构和星形结构的信息传输的k次迭代,每迭代一次,两个结构即更新一次参数;利用最大聚合器将谣言检测嵌入结果和证据嵌入结果的表示聚合并连接在一起,传递到多层感知机中进行最终预测,得到谣言标签和证据解释。
[0023]
与现有技术相比,本发明通过主观推断和客观事实来解释谣言检测策略,提供证据来解释谣言。通过构造两个图对象结构:证据星形图和双向树形图。双向树形图还考虑到了谣言传播的两种模式,并通过自底向上和自顶向下的图卷积神经网络来提取谣言的两种特征。本发明可以在蒙古语谣言检测方面展示出较好的功能和优点,训练出的模型显著的提高了谣言检测的准确性。
附图说明
[0024]
图1是本发明整体框架图。
[0025]
图2是双向树形图结构。
[0026]
图3是证据星形图结构。
具体实施方式
[0027]
下面结合附图和实施例详细说明本发明的实施方式。
[0028]
本发明提供了一种主客观可解释的双向图神经网络的蒙古语谣言检测方法,其中,主观代表的是主观事实,源帖子、基于帖子的转发和评论。客观代表的是客观事实,指的是维基百科等百科类数据中的相关证据文章。双向图神经网络,指自底向上和自顶向下的
图神经网络。
[0029]
如图1所示,本发明具体包括
[0030]
步骤1,使用证据检索模块(erm)来检索证据,证据检索模块基于三步管道方法,证据检索包含三步:文档检索、证据检索和声明验证。证据检索模块是fever官方提供的检索模块,是最广泛使用的证据检索手段之一。
[0031]
具体地:
[0032]
文档检索,是采用关键字匹配算法爬取维基百科等百科类数据中的相关证据文章。
[0033]
证据检索,是从检索到的证据文章中提取句子级证据。
[0034]
声明验证,是基于句子级证据,预测声明与证据的关系为“支持”、“反驳”或“无关”。
[0035]
证据检索模块首先利用语义nlp工具包从给定的声明中提取潜在实体,通过分析实体,用api过滤证据文章维基百科等证据文章;然后从检索到的文档中,该模块以与声明相关的句子的形式提取客观事实作为预测证据;最后,该模块中的一个验证组件对给定的陈述和检索到的证据进行预测,并验证声明与证据之间的关系是“支持”、“反驳”还是“无关”。
[0036]
步骤2,参考图2,构造异构图:双向树形图。
[0037]
双向树形图是一种特殊的回复关系拓扑结构,由社交媒体自然形成,为谣言检测提供了重要线索。具体地,双向树形图是一个自底向上和自顶向下的双向图神经网络,它利用具有自顶向下的谣言传播有向图的图卷积神经网络学习谣言传播模式,利用具有自底向上的谣言扩散图的图卷积神经网络捕获谣言扩散模式。在双向树形图中,对话结构是树形的,树的根节点为源帖子(检测对象),每个节点代表一条评论,节点通过其回复关系连接。
[0038]
步骤3,参考图3,构造异构图:证据星形图。
[0039]
根据检索到的证据信息,使用深度bilstm来提取词嵌入后的单词之间的信息并生成句子表示,构造一个证据星形图。证据星形结构表明每条证据都是对源帖子的补充描述,因此与源帖子直接相关的每个证据句子形成星形拓扑。在证据星形图中,将源帖子(检测对象)位于中心,所有证据节点围绕其周围,表示星形结构中的一个角度。
[0040]
在本发明的一个实施例中,证据星形图的创建如下所示:
[0041]
ge=(ve,ge)
[0042]ve
=[c,e1,e
2,
,
…ek
]
[0043]ee
={(c,e1),(c,e2),
…
(c,ek)}
[0044]
其中,ge是一个由顶点集ve和边集ee组成的证据图对象,顶点集ve包括检测对象c和证据句子e1,e2,
…
,ek,ek表示第k个证据句子,边缘集ee表示各证据句子和检测对象之间的关系。
[0045]
步骤4,基于双向树形图,构造谣言检测模型。
[0046]
谣言检测模型采用自底向上和自顶向下的双向图神经网络结构来捕获谣言的两个传播特征。具体地,通过自顶向下的图卷积神经网络获得谣言传播特征,通过自底向上的图卷积神经网络获得谣言扩散特征。自底向上的图卷积神经网络核心思想是通过递归访问从底部的叶子节点到根节点的每个节点,为每个子树生成一个特征向量。以这种方式,具有
相似上下文的子树,例如那些具有拒绝父节点和子节点支持的子树,将被投影到表示空间中的邻近区域。因此,这种局部谣言指示特征沿着不同的分支聚合成整棵树的一些全局表示;自顶向下的图卷积神经网络旨在利用自顶向下的结构来捕获谣言复杂的传播模式,这种自上而下方法的想法是为每个帖子生成一个考虑其传播路径的增强特征向量,每个节点的表示是通过组合它自己的输入和它的父节点来计算的,这个过程从根节点递归地进行到其子节点,直到到达所有叶子节点。其中根节点代表源帖子(检测对象),子节点代表对父节点做出的评论和转发,每个节点通过其回复关系连接起来。
[0047]
本发明使用dropedge(丢弃法)来减少模型的过拟合,即在每个训练阶段,它都会从输入图中随机删除边,以一定的速率生成不同的变形副本。因此,这种方法增加了输入数据的随机性和多样性,就像随机旋转或翻转图像一样。形式上,假设图a中的总边数为ne,丢弃率为d,则dropedge之后的邻接矩阵 a
′
计算如下:
[0048]a′
=a-a
drop
[0049]
其中a
drop
是使用从原始边缘集中随机采样的ne×
d边构造的矩阵,a
′
是使用dropedge之后的邻接矩阵。
[0050]
步骤5,基于双向树结构和星型结构的信息传输的k次迭代后,得到对话嵌入结果和证据嵌入结果的最终表示,如下:
[0051][0052][0053]
其中p,e是第i个事件的答复和证据。
[0054]
由于每迭代一次,两个图信息结构就更新一次参数。因此,利用最大聚合器将信息聚合成固定大小,再将这两部分的信息连接在一起,然后传递到多层感知机中进行最终预测,得到谣言标签和证据解释,公式如下:
[0055][0056]
其中yr是谣言预测标签,p,e是第与源帖子相关的第i个事件的答复和证据, v和by是多层感知机输出层中的参数。
[0057]
步骤6,利用该模型,即可进行蒙古语谣言检测并得到分类标签和证据解释。
[0058]
例如,对于声明(张三是中国的一名歌手。)”,将其和其相关的回复、转发放进该模型中,首先证据检索模块 (erm)从给定的声明中提取潜在的实体(艺人名称:张三)”(歌手)”,然后分析实体,并与api接口过滤百科库里的证据文章。然后,从这些检索到的文档中,erm以与声明相关的句子的形式提取客观事实作为预测证据。erm给出“支持”的标签,并将检索到的证据作为证据星形图的星型结构,并一起进入谣言检测模块。即可得到“张三是一名中国的歌手。”此声明“非谣言”的标签与支持此声明的百科库里的证据文章。的标签与支持此声明的百科库里的证据文章。
[0059]
(张三,1979年出生于xx省xx市,祖籍xx省xx市xx 县,
中国流行乐歌手、音乐人、演员、导演、编剧)”。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1