基于数据流特征的比较函数识别系统及识别方法
1.本发明属于比较函数识别技术领域,具体涉及一种基于数据流特征的比较函数识别系统及识别方法。
背景技术:
2.随着物联网的快速发展,越来越多的嵌入式设备走进我们的生活,它们往往出现于安全领域的关键位置和靠近终端的隐私场所,如路由器、交换机和打印机等设备。然而,最近的研究表明市场上有很多嵌入式设备存在后门,后门是指一种用于秘密绕过软件、计算机系统、密码机制等正常认证流程,获取计算机系统的访问权限或经密码系统加密后的明文的程序方法。其中披露最多的为硬编码后门(即口令后门)。如2013年在d-link路由器中发现的口令后门:浏览器 user-agent设置为"xmlset_roodkcableoj28840ybtide"后就可以远程控制路由器;2016年在fortinet的防火墙中发现的ssh后门,硬编码的密码口令为"fgtabc11*xy+qqz27";2021年在合勤科技公司zyxel 的防火墙、vpn等设备中发现的管理员级别账户{username:"zyfwp", password:"prow!an_fxp"},使用该账户就可以通过web管理面板对设备进行访问。
3.口令后门为最常见的后门之一,其危害严重,影响深远,造成的损失不可估量。在口令后门触发过程中,比较类函数不可或缺,因此有不少方法借助比较类函数检测口令后门。
4.在嵌入式设备中基于比较类函数的漏洞挖掘技术研究颇多。2015 年yan等提出的二进制分析框架firmalice就需要借助于strcmp和 strncmp等函数来定位关键路径,对关键路径进行切片,通过静态符号执行来判断是否存在确定性约束,若存在则有后门。2017年thomas 等提出的基于静态数据权重比较的后门识别方法stringer,原理为定位strcmp、memcmp和strstr等函数来查找定位参与比较的字符串,然后按提出的算法计算字符串的权重,根据权重比较识别出二进制程序的口令后门。2020年redini等提出的静态污点分析框架karonte 通过建模和跟踪多二进制文件交互来分析固件,在二进制文件之间传播污点信息以识别不安全的交互并识别漏洞,但其仍需要借助strcmp 和strncmp等函数的信息静态跟踪和传播污点数据。2021年,chen 等人提出的定向模糊测试工具satc匹配前端的关键字和后端的输入项,对敏感输入进行污点分析来识别漏洞,但satc同样需要strcmp 和strncmp等函数来定位敏感输入。
5.当前对剥除函数名等信息的二进制文件函数识别技术以静态分析方法为主。如ida pro中的库文件快速识别与鉴定技术(fast libraryidentification and recognition technology,flirt),首先分析二进制程序,找到程序使用的库函数名称和版本信息,然后在github或其他开源平台下载源码,编译库函数为目标程序架构,选取函数的二进制代码的前若干位字节制作函数签名,最后根据签名匹配的方式识别程序中的函数;然而flirt方法需要源码,函数识别效果会受到编译器类型、编译器版本、优化等级、优化选项等影响。在karonte和satc 中都提出了基于特征匹配的静态函数识别方法,但所采取的
特征较为简单:1)有循环结构;2)循环中有比较指令。然而满足上述条件的函数不一定具有比较字符串的功能,具有较高的误报率和漏报率。
6.而实际上,在嵌入式设备中,出于商业竞争或者软件安全的需要,厂商往往不公布开发文档或源码,而是以二进制的形式发行软件,甚至会剥除程序中的函数名、符号表等信息。在此情况下,比较类函数识别对口令后门的发现和修复具有重大意义和价值。但是当前函数识别方法存在以下问题:flirt方法需要源码制作函数签名,识别效果依赖编译环境,而二进制程序往往不公开源码,因此flirt难以识别程序中的比较类函数,尤其是自定义实现的比较类函数;karonte 和satc方法采用的函数特征较为简单,具有较高的误报率和漏报率。
技术实现要素:
7.针对目前的比较类函数识别方法存在误报率和漏报率高的缺陷和问题,本发明提供一种基于数据流特征的比较函数识别方法。
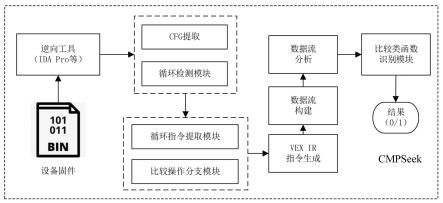
8.本发明解决其技术问题所采用的方案是:一种基于数据流特征的比较函数识别系统,该系统包括cfg提取和循环检测模块、循环指令提取模块、比较操作分支模块、vex ir指令生成模块、数据流构建模块、数据流分析模块和比较类函数识别模块;所述cfg提取和循环检测模块分析函数中是否包含循环路径;所述循环指令提取模块和比较操作分支模块分别用于提取循环块内和循环内比较操作分支到函数返回的指令;所述vex ir指令生成模块借助于开源库pyvex 将二进制代码转换为中间语言vex ir指令,方便系统支持多种指令集架构;所述数据流构建和数据流分析模块从vex ir指令中提取数据流中变量关系,生成数据流dfg并进行分析;所述比较类函数识别模块根据数据流特征检测循环路径和分支路径是否匹配,从而判断函数是否为比较类函数。
9.本发明还一种基于数据流特征的比较函数识别方法,包括以下步骤:
10.步骤一、提取函数的控制流cfg,将基本块视为顶点v,基本块之间的跳转关系视为有向边e,将函数cfg转为有向拓扑图g,
11.g={v,e}
12.其中:v={v1,v2,
…
,vn},e={e1,e2,
…
,em},
13.ek=(vi,vj)(1≤k≤m,1≤i,j≤n)
14.步骤二、识别有向图g中是否存在循环;
15.(1)若有向图g中不存在循环路径,直接认为其为非比较类函数;
16.(2)若有向图g中包含循环路径,提取循环路径和从循环跳出到函数返回的分支路径,将循环路径和分支路径转换为中间语言 vex ir指令,构建数据流dfg;然后根据数据流dfg特征是否匹配,若匹配则认为是比较类函数识别,否则认定为非比较类函数。
17.上述的基于数据流特征的比较函数识别方法,步骤一中调用idapro内置idapython插件的flowchart()类和self.succs()函数获取v和 e。
18.上述的基于数据流特征的比较函数识别方法,步骤二中使用开源库networkx的digraph()函数快速构建有向图g,并调用 simple_circles()识别图g中是否存在循环。
19.上述的一种基于数据流特征的比较函数识别方法,步骤二中若数据流dfg同时满足以下特征则识别为比较类函数,
20.(1)数据流上存在环结构,并且环上存在比较运算和算术运算;
21.(2)数据流上存在cz点和cmp对;
22.(3)存在cz点到cmp对的路径,并且cz点先于cmp对出现;
23.(4)环上cmp对跳出循环后,都能到达函数rt点。
24.本发明的有益效果:本发明分析比较类函数源码,将其编译成不同指令集架构,分析控制流和数据流的特征,构建基于数据流特征匹配的比较类函数识别模型,提出并实现了比较类函数识别方法 cmpseek,该方法不依赖源码、函数名、符号表等信息,识别效果几乎不受编译环境影响,能够识别任何方式实现的比较类函数,支持 arm、mips、powerpc(ppc)和x86指令集,具有良好的适用性。
25.从github、stack overflow等平台上收集比较类函数,构建开源库函数数据集a和自定义实现函数数据集b进行测试。实验结果表明,当缺少源码、函数名等信息时,相比于flirt和satc,cmpseek 在精准率和召回率上都有着更好的结果。
附图说明
26.图1为本发明识别系统cmpseek流程图。
27.图2为karonte中识别比较类函数。
28.图3为satc中识别比较类函数。
29.图4为glibc库中strcmp函数源码。
30.图5为arm架构下strcmp函数。
31.图6为strcmp函数dfg中的循环路径。
具体实施方式
32.在嵌入式设备中基于比较类函数的漏洞挖掘技术研究颇多。2015 年yan等提出的二进制分析框架firmalice就需要借助于strcmp和 strncmp等函数来定位关键路径,对关键路径进行切片,通过静态符号执行来判断是否存在确定性约束,若存在则有后门。
33.2017年thomas等提出的基于静态数据权重比较的后门识别方法 stringer,原理为定位strcmp、memcmp和strstr等函数来查找定位参与比较的字符串,然后按提出的算法计算字符串的权重,根据权重比较识别出二进制程序的口令后门。
34.2020年redini等提出的静态污点分析框架karonte(见图2)通过建模和跟踪多二进制文件交互来分析固件,在二进制文件之间传播污点信息以识别不安全的交互并识别漏洞,可见,仍需要借助strcmp 和strncmp等函数的信息静态跟踪和传播污点数据。
35.2021年,chen等人提出的定向模糊测试工具satc(见图3)匹配前端的关键字和后端的输入项,对敏感输入进行污点分析来识别漏洞,但是satc同样需要strcmp和strncmp等函数来定位敏感输入。
36.当前对剥除函数名等信息的二进制文件函数识别技术以静态分析方法为主。如ida pro中的库文件快速识别与鉴定技术(fast libraryidentification and recognition technology,flirt),首先分析二进制程序,找到程序使用的库函数名称和版本信息,然后在github或其他开源平台下载源码,编译库函数为目标程序架构,选取函数的二进制代码的前若干位字节制作函数签名,最后根据签名匹配的方式识别程序中的函数。
然而flirt方法需要源码,函数识别效果会受到编译器类型、编译器版本、优化等级、优化选项等影响。在karonte和satc 中都提出了基于特征匹配的静态函数识别方法,但所采取的特征较为简单:1)有循环结构;2)循环中有比较指令。然而满足上述条件的函数不一定具有比较字符串的功能,具有较高的误报率和漏报率。
37.而当前函数识别方法存在以下问题:flirt方法需要源码制作函数签名,识别效果依赖编译环境,而二进制程序往往不公开源码,因此flirt难以识别程序中的比较类函数,尤其是自定义实现的比较类函数;karonte和satc方法采用的函数特征较为简单,具有较高的误报率和漏报率。为解决比较类函数识别问题,提出一种基于特征匹配的函数识别系统cmpseek及识别方法。下面结合附图和实施例对本发明进一步说明。
38.实施例1:本实施例提供一种基于数据流特征的比较函数识别系统cmpseek,如图1所示,该系统包括cfg提取和循环检测模块、循环指令提取模块、比较操作分支模块、vex ir指令生成模块、数据流构建模块、数据流分析模块和比较类函数识别模块;其中cfg 提取和循环检测模块分析函数中是否包含循环路径;循环指令提取模块和比较操作分支模块分别用于提取循环块内和循环内比较操作分支到函数返回的指令;vex ir指令生成模块借助于开源库pyvex将二进制代码转换为中间语言vex ir指令,方便系统支持多种指令集架构;数据流构建和数据流分析模块从vex ir指令中提取数据流中变量关系,生成数据流dfg并进行分析;比较类函数识别模块根据数据流特征检测循环路径和分支路径是否匹配,从而判断函数是否为比较类函数。
39.实施例2:本实施例提供一种基于数据流特征的比较函数识别方法,该方法通过提取函数的控制流cfg,将基本块视为顶点v,基本块之间的跳转关系视为有向边e,将函数cfg转为有向拓扑图g,
40.g={v,e}
41.其中:v={v1,v2,
…
,vn},e={e1,e2,
…
,em},
42.ek=(vi,vj)(1≤k≤m,1≤i,j≤n)
43.由于ida pro内置的idapython插件提供了flowchart()类和 self.succs()函数来可以获取函数基本块和基本块间的关系,因此本实施例直接调用flowchart()和self.succs()获取v和e(下方算法1中第 3-8行)。
44.然后使用开源库networkx的digraph()函数快速构建有向图g (算法1中第9行),并调用simple_circles()识别图g中是否存在循环(算法1中第10行)。
45.(1)若有向图g中不存在循环路径,直接认为其为非比较类函数;
46.(2)若有向图g中包含循环路径,提取分支路径,将循环路径和分支路径转换为中间语言vex ir指令,构建数据流dfg;然后根据数据流dfg特征是否匹配,若匹配则认为是比较类函数识别,否则认定为非比较类函数。考虑到函数cfg中可能有多条循环路径,因此只要有其中一条路径满足条件,就识别为比较类函数。
47.具体的识别算法示例如算法1所示。
48.算法1:
49.输入:(ea)/*函数起始地址*/
50.输出:(0/1)/*是否为比较类函数*/
[0051]1ꢀꢀ
func
←
get_func(ea)
[0052]2ꢀꢀv←
[],e
←
[]
[0053]3ꢀꢀ
for block in flowchart(func)do
[0054]4ꢀꢀv←
v∪block/*获取顶点*/
[0055]5ꢀꢀ
for succor in block.succs()do
[0056]6ꢀꢀe←
e∪(block,succor)/*获取有向边*/
[0057]7ꢀꢀ
end for
[0058]8ꢀꢀ
end for
[0059]9ꢀꢀ
cfg
←
generate_cfg(v,e)/*生成控制流图*/
[0060]
10 loops
←
simple_cycles(cfg)/*提取循环路径*/
[0061]
11 [0062]
12 branchs
←
get_branch(cfg)/*提取分支路径*/
[0063]
13 dfg
←
generate_dfg(loops,branchs)/*生成数据流图*/
[0064]
14 if is_cmp_func(dfg)/*数据流特征是否匹配*/
[0065]
15 return 1
[0066]
16 end if
[0067]
17 end if
[0068]
18 return 0
[0069]
通过cfg提取循环路径和分支路径后,分析路径中的数据流向,将寄存器或者内存地址视为顶点v,数据的传递方向转为有向边e,按相同的方式构建dfg(算法1中第13行)。为更好地说明数据流中的特征,下表1列出相关释义和例子。
[0070]
表1数据流中的特殊值
[0071][0072]
*注:在不同架构中函数返回值存放的寄存器不同,如arm中为r0,mips中为ra,表1为 arm架构。
[0073]
若函数满足以下4个特征,即识别为比较类函数,否则不是比较类函数。
[0074]
(1)数据流上存在环结构,并且环上存在比较运算和算术运算;
[0075]
(2)数据流上存在cz点和cmp对;
[0076]
(3)存在cz点到cmp对的路径,并且cz点先于cmp对出现;
[0077]
(4)环上cmp对跳出循环后,都能到达函数rt点。
[0078]
具体的,glibc库中strcmp函数源码见图4,arm架构下strcmp 函数见图5。
[0079]
提取图5中的循环路径和分支路径,转为vex ir指令后构建dfg,循环路径dfg如图6所示(分支路径较为简单,分别为(r2
→ꢀ
r1,r3
→
r1)和(r2
→
r1),限于篇幅不给出分支路径的dfg)。在图中cz={t11},add={t10,t14},cmp={(r3,r2)},cr={t33}。循环中存在比
较运算cmp对{(r3,r2)}和算术运算add点{t10,t14}(特征a),并且还有cz点t11以及t11到r3的路径(特征b和c),最后分支路径中都有从cmp对{(r3,r2)}到rt点r0的路径(特征d),因此cmpseek识别strcmp为比较类函数。
[0080]
试验例:本实施例从不同的角度评估本发明的方法(cmpseek) 的比较类函数识别效果,并与现有方法flirt、karonte、satc进行对比,分别对glibc库函数和自定义比较类函数进行实验,对比三种函数识别方法受编译器选项、编译器版本、优化等级和不同指令集架构的影响。
[0081]
数据集:分为数据集a和数据集b,a为c语言glibc库中的比较类函数,如表2所示,共计有25个。b为自定义实现的比较类函数,从github(openwrt和mirai源码)和stack overflow等平台上收集比较类函数,整合到一个c程序中进行编译测试。
[0082]
表2glibc库中的比较类函数
[0083][0084]
对比方法:flirt,karonte和satc(如图2和图3所示,karonte 和satc对比较类函数识别方法完全相同,因此两者中选择satc即可)。考虑到flirt制作函数签名时需要源码,而且识别效果受编译环境的影响,因此flirt中使用的签名来自于glibc库函数,编译器类型及版本为gcc 5.5.0,优化等级为-o0,选择arm架构为目标程序。
[0085]
工具实现:cmpseek是基于idapython和pyvex进行实现,并借助于networkx对cfg和dfg进行处理。表3展示了各个方法实现主要依赖的工具和支持的指令集架构。
[0086]
表3三种方法对比
[0087][0088]
*注:实验中flirt使用的函数签名对应arm架构,因此后续实验中将数据集编译为arm架构。
[0089]
评价指标:使用精准率p和召回率r来评估所提方法的效果,精准率和召回率越高,效果越好。
[0090]
p=tp/(tp+fp)
[0091]
r=tp/(tp+fn)
[0092]
式中:tp为真正例,即比较类函数被识别为比较类函数;fp为假正例,即非比较类函数被识别为比较类函数;fn为假反例,即比较类函数被识别为非比较类函数。
[0093]
编译器以及优化等级:如表4所示为实验评估中使用的编译器类型,编译器版本和
优化等级,使用gcc和clang两个编译器进行测试,并使用buildroot构建了不同指令集的交叉工具链,用于生成不同指令架构的程序。
[0094]
表4实验评估中使用的编译环境选项
[0095][0096]
编译器选项对函数识别效果的影响
[0097]
为比较编译器选项对函数识别效果的影响,使用gcc和clang 编译器,优化等级为-o0,将数据集a和b编译成arm指令集架构的二进制程序,函数识别效果如表5和6所示。
[0098]
表5不同编译器下对数据集a识别效果对比
[0099][0100]
表6不同编译器下对数据集b识别效果对比
[0101][0102]
从表5和6可以看出,对于数据集a(glibc库中的比较类函数), flirt函数识别效
果最好,在gcc和clang编译器下p分别为1.00 和0.71,但受编译器选项影响较大,cmpseek和satc的p相差不大,但cmpseek的r能达到0.80,而satc只有0.16;对于数据集 b(自定义实现的比较类函数),flirt的p和r都为0.00,完全识别不出比较类函数,cmpseek的p在0.56以上,r在0.67以上,p 和r都优于satc,整体表现较为稳定。当有函数源码时,flirt函数识别效果最佳,但受编译器选择影响较大,在gcc-5.1.0中有着最好的识别效果,p和r分别为1.00和0.88,cmpseek也有着较为不错的识别效果,在gcc-4.5.4中表现最好,p和r分别为0.62和0.80;当没有源码时,cmpseek函数的识别效果好于satc和flirt,且在gcc和clang编译器下识别效果基本一致。
[0103]
编译器版本对函数识别效果的影响
[0104]
为进一步比较编译器版本对函数识别效果的影响,选择gcc编译器,版本如上表4所示,优化等级为-o0,将数据集a和b编译为 arm架构的二进制文件,函数识别效果如表7和8所示。
[0105]
表7不同版本下对数据集a识别效果对比
[0106][0107]
表8不同版本下对数据集b识别效果对比
[0108][0109]
从表7和表8中可以看出,对于数据集a,flirt识别效果最好, p为1.00,r在0.80以上,cmpseek次之,p和r分别在0.52和0.72 以上,satc最差,召回率r最高只有0.20。对于数
据集b,cmpseek 识别效果最好,p和r分别在0.58和0.68以上,flirt的p和r依然为0.00。
[0110]
三种方法受编译器版本影响不大,对于数据集a,flirt在 gcc-5.5.0中表现最佳,p和r达到1.00,因为flirt中函数签名的编译环境也是gcc-5.5.0-o0;satc和cmpseek在gcc-4.5.4下表现最好;对于数据集b,三种方法在gcc-5.3.0及以上版本表现最好。
[0111]
优化等级对函数识别效果的影响
[0112]
为比较不同优化等级对函数识别效果的影响,选择gcc-5.5.0编译器,优化等级为-o0~o3,将数据集a和b编译为arm架构的二进制文件,函数识别效果如表9和10所示。
[0113]
表9不同优化等级下对数据集a识别效果对比
[0114][0115]
表10不同优化等级下对数据集b识别效果对比
[0116][0117]
从表9和10可以看出,flirt受优化等级影响较大,p和r随优化程度的上升而不断下降,相对而言,cmpseek和satc基本不受优化等级的影响。对数据集a来说,即使在-o3优化等级,综合p 和r来看,依旧是flirt效果最好,p和r分别为0.73和0.76;对数据集b而言,则是cmpseek识别效果最优,p和r都在0.70以上。无论是数据集a还是数据集b,cmpseek的p和r都高于satc。
[0118]
指令集对函数识别效果的影响
[0119]
本实验只测试cmpseek对于四种指令集的识别效果,因此不再分别对数据集a和b进行测试,将a和b的源码整合成一个文件,使用gcc 5.5.0编译器,优化等级选择-o0~o3,分别编译成4种不同架构的二进制文件,实验结果如表11所示。
[0120]
表11不同指令集对函数识别效果的影响
[0121][0122]
从表11中可以看出,cmpseek支持对多指令集架构的函数识别,对不同架构中比较类函数识别效果相差不大,在mips架构优化等级为-o0中表现最好,p和r分别为0.67和0.80。
[0123]
以上所述仅为本发明的较佳实施例,并不限制本发明,凡在本发明的精神和原则范围内所做的任何修改、等同替换和改进,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1