基于树型注意力机制的深度知识追踪方法
1.本发明属于计算机技术(智慧教育)领域,具体涉及一种基于树型注意力机制的深度知识追踪方法。
背景技术:
2.现有学生知识追踪研究可分为:概率模型,潜变量学习模型和基于深度学习的模型。
3.概率模型假设学习过程遵循马尔可夫过程。经典的贝叶斯追踪模型(bkt)用知识状态集合来表示学生的知识水平,用二元值(0,1)表示学生对每个知识点的掌握状况,根据学生以往的答题情况,用隐马尔可夫模型更新隐含变量的概率分布。
4.潜变量学习模型是以logistic函数为基础的一类模型,首先用学生与题目交互数据来表示学生和知识概念,然后利用logistic函数对学生做题结果(正确/错误)的概率进行建模。
5.然而,学生的认知过程受到许多因素的影响,用概率模型或潜变量学习模型捕捉这种复杂的认知过程是很困难的。深度学习具有强大特征提取能力且可以拟合任意复杂的函数,使其非常适合建模复杂的学习过程。piech等人提出深度知识追踪模型(dkt),使用循环神经网络模拟知识追踪中学生知识状态。jani等人基于记忆增强神经网络提出动态键值记忆网络(dkvmn)。pandey等人提出基于transformer架构的sakt,采用transformer中编码层捕捉题目与学生交互行为特征之间的依赖关系。choi等人提出基于transformer架构的saint,由自注意力层对题目序列和交互行为序列分别进行编码和解码。
6.然而,现有的深度知识追踪模型理想化的地将题目映射到单个粗粒度的知识概念,通常使用人工定义的特征编码题目,无法反映题目之间知识结构的相似性和差异性,忽略了题目之间的内在联系,忽略了题目的知识概念结构,使得知识追踪模型可能会错误地判别学生在细粒度知识概念上的掌握状态,导致目前的知识追踪模型在学习系统上的应用受到限制。此外,基于lstm,rnn及它们的变体的深度知识追踪模型使用隐向量模拟学生的知识状态,模型缺乏可解释性。
技术实现要素:
7.要解决的技术问题
8.学生知识追踪的核心任务是评估学生知识水平。从学生角度来说,学习是一个循序渐进的过程,学生的知识状态随着做题数量的增多动态变化,学生的知识水平影响着其答题表现。从习题角度来说,现实生活中,教师编写练习题通常有一定的教学目的,用于考察和评估学生对某些知识概念的掌握程度。练习题包含多个不同的知识概念,知识概念之间往往彼此关联,学科知识根据包含关系呈现层次树结构或森林结构。习题之间的相似性和差异性反映在知识概念结构上。习题间的关联关系影响着学生答题表现,学生在有相似知识或强关联关系的习题中可能会有相似的答题表现。
9.因此,本发明针对现有的知识追踪研究缺乏题目知识概念结构建模,忽略了题目之间知识结构的相似性和差异性,模型缺乏可解释性等问题,提出了一种基于树型注意力机制的深度知识追踪方法。本发明从学生对细粒度知识概念掌握程度研究学生知识水平,可以帮助教师客观的评价学生当前的知识水平,学习能力,从而帮助学生选择合适的学习资料,做到最大化每一个个体的学习收益,减少无效教学时间,提升学习效率。
10.技术方案
11.一种基于树型注意力机制的深度知识追踪方法,其特征在于步骤如下:
12.步骤1:构建数学模型
13.采用表示学生j在过去t-1道题上的答题序列,其中i
t
=(q
t
,kct
t
,r
t
,d
t
,sj),q
t
表示学生j作答的第t道题目;kct
t
表示题目q
t
的知识概念树;r
t
∈{0,1}表示学生是否作答正确;d
t
表示学生在作答题目q
t
时与平台的交互行为信息;sj表示学生j的人口统计特征;基于以上信息,学生知识追踪被定义为:根据学生j在过去t-1道题上的答题序列,预测学生j作答正确题目q
t
的概率p,即计算:
[0014][0015]
步骤2:定义知识概念树节点集合
[0016]
层次遍历知识概念树kct
t
并定义三个集合,分别是叶子节点集合非叶子节点集合以及非叶子节点的后代节点集合其中集合代表以非叶子节点nm为根节点的子树节点集合;
[0017]
步骤3:知识概念树三视图编码
[0018]
步骤3-1:知识概念特征视图编码
[0019]
知识概念特征视图反映了题目包含的多知识概念和概念间结构关系;首先将叶子节点和非叶子节点通过embedding()函数映射到d维空间,得到和定义映射函数将知识概念树kct
t
映射为张量
[0020][0021]
式中,(i={1,2,...,m+1},j={1,2,...,n'})是f
t
的第i行j列的元素,0表示d维零向量;f
t
行和列的排列保留了树节点之间的层级关系;
[0022]
步骤3-2:知识概念广度视图编码
[0023]
定义分支嵌入映射函数构造张量
[0024][0025]
式中,(i∈{1,2,...,m+1},j∈{1,2,...,n'})是张量g
t
第i行j列的元素,表示从叶子节点lj到祖先节点n
p
之间的节点集合,表示
集合中元素的个数;embedding(
·
)函数将值映射到d维空间,0表示d维零向量;
[0026]
步骤3-3:知识概念等级视图编码
[0027]
定义层次嵌入映射函数构造张量
[0028][0029]
式中,(i∈{1,2,...,m+1},j∈{1,2,...n'})是张量h
t
第i行j列的元素,level(
·
)表示知识概念树中节点的等级;
[0030]
步骤3-4:在特征维度连接知识概念树的三视图编码:
[0031][0032]
步骤4:将知识概念树三视图编码t
t
进行层次平均累积、分支零填充、分支注意力计算和分支聚合,得到知识概念树的d维表示qkc;
[0033]
步骤4-1:层次平均累积
[0034]
首先对知识概念树的三视图编码t
t
执行层次平均累积操作以自下而上的方式组合树节点得到树的每个分支表示b
t
中每个元素bj都是通过对其在某一分支中的所有后代进行平均累加得到,即:
[0035][0036]
式中,是指示函数,即如果t
ij
≠0,则计算集合中非零元素的个数;
[0037]
步骤4-2:分支零填充
[0038]
定义一个零填充函数将题目序列的所有分支向量b
t
填充为统一长度k,即这里pi为填充的0向量,k为所有知识概念树中叶子节点个数的最大值;
[0039]
步骤4-3:分支注意力计算
[0040]
考虑到树分支概念之间的关联关系,定义注意力函数学习分支间知识概念树的表示,得到即:
[0041][0042]
式中,式中,分别是查询、键和值投影矩阵,将映射为q
t
,k
t
和v
t
;屏蔽注意力通过将查询向量和键向量的内积定义为一个无穷负值实现,使得注意力权重在softmax函数之后变为零,这里需屏蔽步骤3中填充的与树结构无关的零向量,因此掩码函数定义为:
[0043][0044]
式中,p为第三步中填充的零向量;
[0045]
步骤4-4:分支聚合
[0046]
通过映射函数聚合树分支关联向量得到每棵知识概念树的d维表示qkc
t
,即:
[0047][0048]
综上所述,知识概念树的层次积累过程可以表述为:
[0049][0050]
步骤5:将知识概念树序列qkc=[qkc1,qkc2,...,qkc
t
]和题目特征序列嵌入qe=[qe1,qe2,...,qe
t
]输入编码器;然后将编码器的输出和交互行为序列嵌入ie=[ie1,ie2,...,ie
t
]输入解码器;解码器输出与学生嵌入se拼接后输入到全连接网络拟合非线性映射预测学生是否作答正确c'=[c'1,c'2,...,c'
t
];这个过程可以表述为:
[0051][0052]
本发明进一步的技术方案:所述的编码器encoder:
[0053]
编码器由顺序对齐的n个编码层堆叠组成,单个编码层由一个上三角掩码多头自注意力层、前馈网络、残差连接和层归一化组成,即:
[0054][0055]
式中,q
enc
=qkc,k
enc
=v
enc
=qe;
[0056]
所述的上三角掩码多头注意力网络multihead
[0057]
上三角掩码多头注意力网络是将输入序列用不同的投影矩阵投影h次的自注意力网络;对于每个i∈[1,h],查询qi,键ki,值vi通过以下公式得到:
[0058][0059]
式中,分别是查询,键和值的映射矩阵;在知识追踪模型中,当预测学生能否正确作答q
t
时,预测过程应该只基于前t-1次答题数据;因此,对于查询qi和键ki,当j>i时,查询qi和键ki的点积qikj应该被置为-∞,使得在softmax函数之后变为零;屏蔽机制用-∞替换矩阵qikj的上三角部分,屏蔽了多头注意力网络中来自未来输入信息,防止无效参与;然后,值vi乘以掩码注意力权重得到headi,即:
[0060]
[0061]
多头注意力的输出o
att
是串联headi,i∈[1,h]后再做线性变换,即:
[0062]oatt
=multihead(q,k,v)=concat(head1,head2,...,headh)woꢀꢀ
(15)
[0063]
式中,是网络可学习的线性变换矩阵;
[0064]
所述的前馈网络ffn
[0065]
前馈网络在模型中引入非线性变换,考虑了不同潜在维度之间的相互作用;前馈网络定义为:
[0066]
f=ffn(o
att
)=relu(o
att
w1+b1)w2+b2ꢀꢀ
(16)
[0067]
式中,均为网络参数。
[0068]
本发明进一步的技术方案:所述的解码器decoder:
[0069]
解码器与编码器相似,由顺序对齐的n个解码层堆叠组成,单个解码层由两个上三角掩码多头自注意力层、前馈网络、残差连接和层归一化组成,即:
[0070][0071]
式中,q
dec
=k
dec
=v
dec
=ie,o
enc
是编码器n层堆叠的最后一层的输出,第一个上三角掩码多头注意力网络用于学习交互序列之间的关联关系,第二个上三角掩码多头注意力网络用于学习题目和交互行为序列之间的关联关系。
[0072]
本发明进一步的技术方案:所述的全连接网络fcn
[0073]
解码器的输出和学生特征嵌入se拼接后传递给全连接网络,最终使用sigmoid函数计算预测概率,产生最终输出c'=[c'1,c'2,...,c'
t
],即:
[0074]
c'=fcn(se;o
dec
)
ꢀꢀ
(18)
[0075]
综上所述,基于树型注意力机制的深度知识追踪方法可以表示为:
[0076][0077]
通过最小化真实标签c
t
和预测标签c'
t
的交叉损失来训练网络参数,即:
[0078][0079]
式中,x是批量数据样本,n是批次的大小。
[0080]
有益效果
[0081]
本发明提出的一种基于树型注意力机制的深度知识追踪方法,该方法从知识概念特征视图,知识概念广度视图,知识概念等级视图三个角度构建树状结构编码张量对题目知识概念树进行编码;然后利用编码器学习题目间关联关系,使用解码器建模学生交互行为,最后将解码器深度特征与学生背景特征拼接后拟合一个线性分类器来预测学生能否正确作答目标题目。相比于基线方法,本发明具有更高的预测准确率。另外,通过分析编码器注意力网络层权重和知识概念树结构可以解释模型预测结果。
附图说明
[0082]
附图仅用于示出具体实施例的目的,而并不认为是对本发明的限制,在整个附图
中,相同的参考符号表示相同的部件。
[0083]
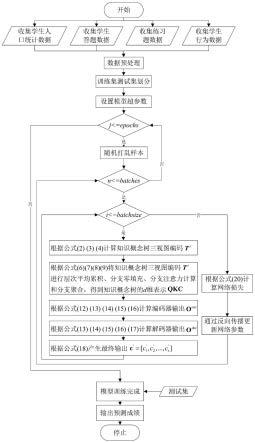
图1是本发明整体系统流程图。
[0084]
图2是知识概念树的三视图嵌入示意图。
[0085]
图3是本发明模型框架图。
[0086]
图4是本发明与基线方法预测结果对比图。
[0087]
图5是知识概念树的三视图消融实验结果对比图。
具体实施方式
[0088]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图和实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。此外,下面描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
[0089]
本发明提出一种基于树型注意力机制的深度知识追踪方法,如图1所示,展示了本发明的整体流程图。首先从知识概念特征视图、知识概念广度视图和知识概念等级视图三个角度编码题目知识概念树,合并三视图编码后进行层次平均累积运算,引入注意力零填充屏蔽网络学习知识概念树分支间关系,进行分支聚合得到知识概念树表示;然后,使用transformer-编码器整合题目树结构嵌入,题目背景特征嵌入,使用多头注意力网络学习学生答题序列中题目之间的关联关系,使用transformer-解码器整合学生交互行为特征与编码器隐特征,使用多头注意力网络学习题目和学生答题行为之间的关系;最后,将解码器深度特征与学生背景特征拼接后拟合一个线性分类器来预测学生能否正确作答目标题目。具体包括以下步骤:
[0090]
步骤1:构建数学模型。
[0091]
本发明用表示学生j在过去t-1道题上的答题序列,其中i
t
=(q
t
,kct
t
,r
t
,d
t
,sj),q
t
表示学生j作答的第t道题目;kct
t
表示题目q
t
的知识概念树;r
t
∈{0,1}表示学生是否作答正确(正确为1,错误为0);d
t
表示学生在作答题目q
t
时与平台的交互行为信息(例如反应时间,答题次数,教师是否干预等);sj表示学生j的人口统计特征。基于以上信息,学生知识追踪被定义为:根据学生j在过去t-1道题上的答题序列,预测学生j作答正确题目q
t
的概率p,即计算:
[0092][0093]
步骤2:定义知识概念树节点集合。
[0094]
层次遍历知识概念树kct
t
并定义三个集合,分别是叶子节点集合非叶子节点集合以及非叶子节点的后代节点集合其中集合代表以非叶子节点nm为根节点的子树节点集合。
[0095]
步骤3:知识概念树三视图编码。
[0096]
步骤3-1:知识概念特征视图编码。
[0097]
知识概念特征视图反映了题目包含的多知识概念和概念间结构关系。首先将叶子节点和非叶子节点通过embedding()函数映射到d维空间,得到和
本发明定义映射函数将知识概念树kct
t
映射为张量
[0098][0099]
式中,(i={1,2,...,m+1},j={1,2,...,n'})是f
t
的第i行j列的元素,0表示d维零向量。f
t
行和列的排列保留了树节点之间的层级关系。
[0100]
步骤3-2:知识概念广度视图编码。
[0101]
题目的知识概念广度反映一个题目包含具体知识概念的数量,表现在知识概念树的每个分支稠密结构中,分支稠密差异反映了题目考察侧重点。本发明定义分支嵌入映射函数构造张量
[0102][0103]
式中,(i∈{1,2,...,m+1},j∈{1,2,...,n'})是张量g
t
第i行j列的元素,表示从叶子节点lj到祖先节点n
p
之间的节点集合,表示集合中元素的个数。embedding(
·
)函数将值映射到d维空间,0表示d维零向量。
[0104]
步骤3-3:知识概念等级视图编码。
[0105]
知识概念的等级表示了一个知识概念的难易程度,即一个概念在知识概念树中距离其根节点的深度。本发明定义层次嵌入映射函数构造张量
[0106][0107]
式中,(i∈{1,2,...,m+1},j∈{1,2,...n'})是张量h
t
第i行j列的元素,level(
·
)表示知识概念树中节点的等级。
[0108]
步骤3-4:在特征维度连接知识概念树的三视图编码:
[0109][0110]
步骤4:将知识概念树三视图编码t
t
进行层次平均累积、分支零填充、分支注意力计算和分支聚合,得到知识概念树的d维表示qkc。
[0111]
步骤4-1:层次平均累积。
[0112]
首先对知识概念树的三视图编码t
t
执行层次平均累积操作以自下而上的方式组合树节点得到树的每个分支表示b
t
中每个元素bj都是通过对其在某一分支中的所有后代进行平均累加得到,即:
[0113][0114]
式中,是指示函数,即如果t
ij
≠0,则计算集合中非零元素的个数。
[0115]
步骤4-2:分支零填充。
[0116]
学生答题序列中题目的知识概念树结构不同,导致每棵树的分支表示b
t
长度不等。因此本发明定义一个零填充函数将题目序列的所有分支向量b
t
填充为统一长度k,即这里pi为填充的0向量,k为所有知识概念树中叶子节点个数的最大值。
[0117]
步骤4-3:分支注意力计算。
[0118]
考虑到树分支概念之间的关联关系,定义注意力函数学习分支间知识概念树的表示,得到即:
[0119][0120]
式中,式中,分别是查询、键和值投影矩阵,将映射为q
t
,k
t
和v
t
。屏蔽注意力通过将查询向量和键向量的内积定义为一个无穷负值实现,使得注意力权重在softmax函数之后变为零,这里需屏蔽第三步中填充的与树结构无关的零向量,因此掩码函数定义为:
[0121][0122]
式中,p为第三步中填充的零向量。
[0123]
步骤4-4:分支聚合。
[0124]
通过映射函数聚合树分支关联向量得到每棵知识概念树的d维表示qkc
t
,即:
[0125][0126]
综上所述,知识概念树的层次积累过程可以表述为:
[0127][0128]
步骤5:本发明将知识概念树序列qkc=[qkc1,qkc2,...,qkc
t
]和题目特征序列嵌入qe=[qe1,qe2,...,qe
t
]输入编码器;然后将编码器的输出和交互行为序列嵌入ie=[ie1,ie2,...,ie
t
]输入解码器;解码器输出与学生嵌入se拼接后输入到全连接网络拟合非线性映射预测学生是否作答正确c'=[c'1,c'2,...,c'
t
]。这个过程可以表述为:
[0129][0130]
步骤6:编码器(encoder)。
[0131]
编码器由顺序对齐的n个编码层堆叠组成。单个编码层由一个上三角掩码多头自注意力层(步骤6-1),前馈网络(步骤6-2),残差连接和层归一化(步骤6-3)组成,即:
[0132][0133]
式中,q
enc
=qkc,k
enc
=v
enc
=qe。
[0134]
步骤6-1:上三角掩码多头注意力网络(multihead)。
[0135]
上三角掩码多头注意力网络是将输入序列用不同的投影矩阵投影h次的自注意力网络。对于每个i∈[1,h],查询qi,键ki,值vi通过以下公式得到:
[0136][0137]
式中,分别是查询,键和值的映射矩阵。在知识追踪模型中,当预测学生能否正确作答q
t
时,预测过程应该只基于前t-1次答题数据。因此,对于查询qi和键ki,当j>i时,查询qi和键ki的点积qikj应该被置为-∞,使得在softmax函数之后变为零。屏蔽机制用-∞替换矩阵qikj的上三角部分,屏蔽了多头注意力网络中来自未来输入信息,防止无效参与。然后,值vi乘以掩码注意力权重得到headi,即:
[0138][0139]
多头注意力的输出o
att
是串联headi,i∈[1,h]后再做线性变换,即:
[0140]oatt
=multihead(q,k,v)=concat(head1,head2,...,headh)woꢀꢀ
(35)
[0141]
式中是网络可学习的线性变换矩阵。
[0142]
步骤6-2:前馈网络(ffn)。
[0143]
前馈网络在模型中引入非线性变换,考虑了不同潜在维度之间的相互作用。前馈网络定义为:
[0144]
f=ffn(o
att
)=relu(o
att
w1+b1)w2+b2ꢀꢀ
(36)
[0145]
式中,均为网络参数。
[0146]
步骤6-3:残差连接和层归一化(skipconct&layernorm)。
[0147]
残差连接将较低层的特征传播到较高层。在知识追踪背景下,残差连接可以帮助模型将最近练习的习题嵌入传播到最后一层,使模型更容易利用低层信息。层归一化有助于提高模型的学习能力,并使数据更加标准,加快收敛。
[0148]
步骤7:解码器(decoder)。
[0149]
解码器与编码器相似,由顺序对齐的n个解码层堆叠组成。单个解码层由两个上三角掩码多头自注意力层(步骤6-1),前馈网络(步骤6-2),残差连接和层归一化组成(步骤6-3),即:
[0150][0151]
式中,q
dec
=k
dec
=v
dec
=ie,o
enc
是编码器n层堆叠的最后一层的输出,第一个上三角掩码多头注意力网络用于学习交互序列之间的关联关系,第二个上三角掩码多头注意力网络用于学习题目和交互行为序列之间的关联关系。
[0152]
步骤8:全连接网络fcn。
[0153]
解码器的输出和学生特征嵌入se拼接后传递给全连接网络,最终使用sigmoid函数计算预测概率,产生最终输出c'=[c'1,c'2,...,c'
t
],即:
[0154]
c'=fcn(se;o
dec
)
ꢀꢀ
(38)
[0155]
综上所述,本发明提出的基于树型注意力机制的深度知识追踪方法可以表示为:
[0156][0157]
本发明通过最小化真实标签c
t
和预测标签c'
t
的交叉损失来训练网络参数,即:
[0158][0159]
式中,x是批量数据样本,n是批次的大小。
[0160]
实施例:
[0161]
步骤1:本实施实例使用在线学习平台eedi提供的公开数据集。数据集中的每个问题都由多个知识概念组成,专家根据知识层次关系将这些知识概念组织成树型结构。此外,数据集还包括题目背景信息(例如题目编号,题目难度,题目出现的频率,题目所属知识类等),学生与平台的交互行为信息(例如是否作答正确c,对答案的置信分数等),学生背景信息(例如性别,是否经济困难,做题数量等)。
[0162]
步骤2:数据预处理。
[0163]
本实施实例将学生答题序列分割或填充为长度等于40,当序列长度小于40时,在题目知识概念树序列,题目背景特征序列,学生交互行为序列的左侧填充问答对,且记录填充位置以便在后续计算注意力权重以及损失时屏蔽这些填充序列;当序列长度大于40时,将序列划分为长度为40的子序列集,子序列作为本发明的输入。
[0164]
步骤3:训练集测试集划分。
[0165]
本实施例以学生为单位按照比例8:2将数据集划分为训练集和测试集。
[0166]
步骤4:设置超参数,学习目标函数。
[0167]
如图3所示,展示了本发明的模型框架图。本实施实例设置编码器和解码器堆叠层数n=8、多头注意力head=8,嵌入维度d=256、batch-size=64,迭代次数epochs=200。使用adam优化器,其中lr=0.001,β1=0.9,β2=0.999,epsilon=1e-8,并设置预热学习率为4000。
[0168]
步骤5:模型开始训练,判断当前迭代次数是否小于epochs,若是,随机打乱样本开始当前训练迭代;若否,到步骤14。
[0169]
步骤6:判断当前训练批次是否小于batches,若是,到步骤7;若否,到步骤5。
[0170]
步骤7:判断当前训练样本是否小于batchsize,若是,到步骤8;若否,到步骤13。
[0171]
步骤8:根据公式(2)(3)(4)计算知识概念树三视图编码t
t
,如图2所示。
[0172]
步骤9:根据公式(6)(7)(8)(9)将知识概念树三视图编码进行层次平均累积、分支零填充、分支注意力计算和分支聚合,得到知识概念树的d维表示qkc,如图2所示。
[0173]
步骤10:根据公式(12)(13)(14)(15)(16)计算编码器输出o
enc
,如图3所示。
[0174]
步骤11:根据公式(13)(14)(15)(16)(17)计算解码器输出o
dec
,如图3所示。
[0175]
步骤12:根据公式(18)产生最终输出c'=[c'1,c'2,...,c'
t
],回到步骤7。
[0176]
步骤13:根据公式(20)计算网络损失,并通过反向传播更新网络参数;回到步骤6。
[0177]
步骤14:模型训练完成,在测试集进行测试,最终得到学生在目标题目上的预测结果。
[0178]
实施实例结果:
[0179]
如图4所示,展示了本发明(tsakt)与基线方法在真实教育数据集上的预测结果,可知本发明在知识追踪任务上取得了比最新的知识追踪模型更高的预测准确率,说明本发明受益于题目的知识概念树结构编码。
[0180]
如图5所示,展示了知识概念树三视图编码消融实验结果,说明了知识概念树的每一种视图都对本发明的预测效果做出了贡献。
[0181]
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明公开的技术范围内,可轻易想到各种等效的修改或替换,这些修改或替换都应涵盖在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1