一种基于Redis的关系型数据库全量内存化的方法
本发明涉及计算机数据处理,尤其涉及一种基于redis的关系型数据库全量内存化的方法。
背景技术:
1、在经历了人工管理、文件管理之后,数据管理技术在数据库阶段迎来了里程碑式的发展。数据库能够高效有序地存储大量数据信息,并方便用户进行有效检索、访问和管理,是信息技术发展过程中管理数据的主要方式。自2013年以来,排名前三位的数据库均是rdb(关系型数据库)。虽然目前非关系型数据库(not only sql,nosql)发展迅速,但rdb仍然是大多数应用程序的数据存储介质,是整个社会的信息基础设施。为满足存储需求,数据库技术的发展中衍生出了以下几种数据库架构。
2、最简单的数据库架构是单体数据库,它使用单个数据库存储全部数据,并通过配置数据库连接池管理数据库连接,客户端可从连接池中获取连接管理数据库中的数据。在小型应用系统中,通过数据连接池直连rdb的方案比较常见。
3、为避免数据库单点故障和单个数据库压力过大,针对不同规模的读写请求出现了一主多从的数据库方案。但主从架构的读写分离方案存在写延迟的问题,会导致主从数据库实时数据不一致。为了降低数据呈指数级增长场景下的单个数据库的负载,分库分表技术应运而生。但分库分表技术会带来分布式事务和跨数据库join等问题。数据库不同架构产生的本质原因在于rdb将数据存储在磁盘上,在频繁读写的高并发场景下会存在读写i/o瓶颈,带来操作效率低和高异常率等问题。综上所述,rdb在高并发场景下的读写和扩展性等方面具有自身局限性。
4、而随着nosql的发展,出现了在数据库层面使用缓存技术实现读写分离,利用内存组件减轻rdb的读压力,使得mmdb+rdb组合使用成为趋势。目前缓存方案广泛应用于企业信息管理,且缓存组件多使用nosql内存组件(memcache)或nosql内存数据库(redis)。在缓存式数据库架构中,rdb作为主库存储所有数据,缓存组件存储热点数据(高频率使用的数据),并设置内存数据淘汰策略来保证缓存的命中率。客户端每次从缓存中读取数据,缓存未命中的数据将从rdb中读取再写入缓存。缓存更新有多种策略,目前流行的有先删除缓存再更新rdb、先更新rdb再删除缓存、先更新rdb再更新缓存、缓存代理和写回(只更新缓存,缓存组件异步批量地更新rdb)五种策略。其中,前三种更新策略均无法避免脏数据的产生。第一种更新策略有明显的缺陷,当更新操作删除缓存但还没来得及更新rdb中的数据时,此时的查询操作会因为未命中缓存而读取rdb中旧的数据并写入缓存,导致写入缓存的数据变成脏数据。第二种更新策略是目前使用最广泛的,但也有小几率产生脏数据。第三种更新策略需要提前准备数据,比第二种更新策略具备更高的读性能,但要更新rdb和缓存两部分数据会导致其较低的写性能,也同样会产生脏数据。第四种更新策略不适用于高并发场景。第五种更新策略不保证强一致性,会造成部分数据丢失问题。
5、综上所述,在缓存读写分离架构中的读请求情况相对简单,但数据更新逻辑复杂,容易出现数据一致性问题,导致数据命中率降低。同时,缓存式读写分离方案不能避免高并发场景下更新rdb中的数据引起的i/o读写瓶颈问题。此外,当大量恶意请求故意查询不在缓存中的数据时会引发缓存穿透问题,导致所有的请求会同时转向请求rdb。目前最流行的解决缓存穿透的方案是增加前置布隆过滤器和设置无效缓存方案。但布隆过滤器会带来误识别率和删除困难问题,无效缓存方案在实际应用中情况复杂且会增加内存占用。缓存雪崩是缓存式方案存在的另一个问题,因为缓存具有时效性,缓存失效引发的缓存雪崩也会给rdb带来巨大压力,甚至导致系统崩溃。目前可以使用锁/队列、多级缓存和设置不同的缓存时效三种方案来减轻以上问题,但会降低应用整体性能且实际应用情况复杂。
6、近年来随着内存技术的发展,利用内存访问技术减少与磁盘之间的交互频率提升数据库实时响应能力成为一个研究热点。同时,随着动态随机存取存储器(dram)容量的增加,计算机内存可配置到tb级,在dram中存储和处理企业数据成为可能。一些商用数据库推出了企业级的内存化方案,但大多方案都存在配置复杂、系统过重、商业技术使用限制和硬件要求较高等问题。
技术实现思路
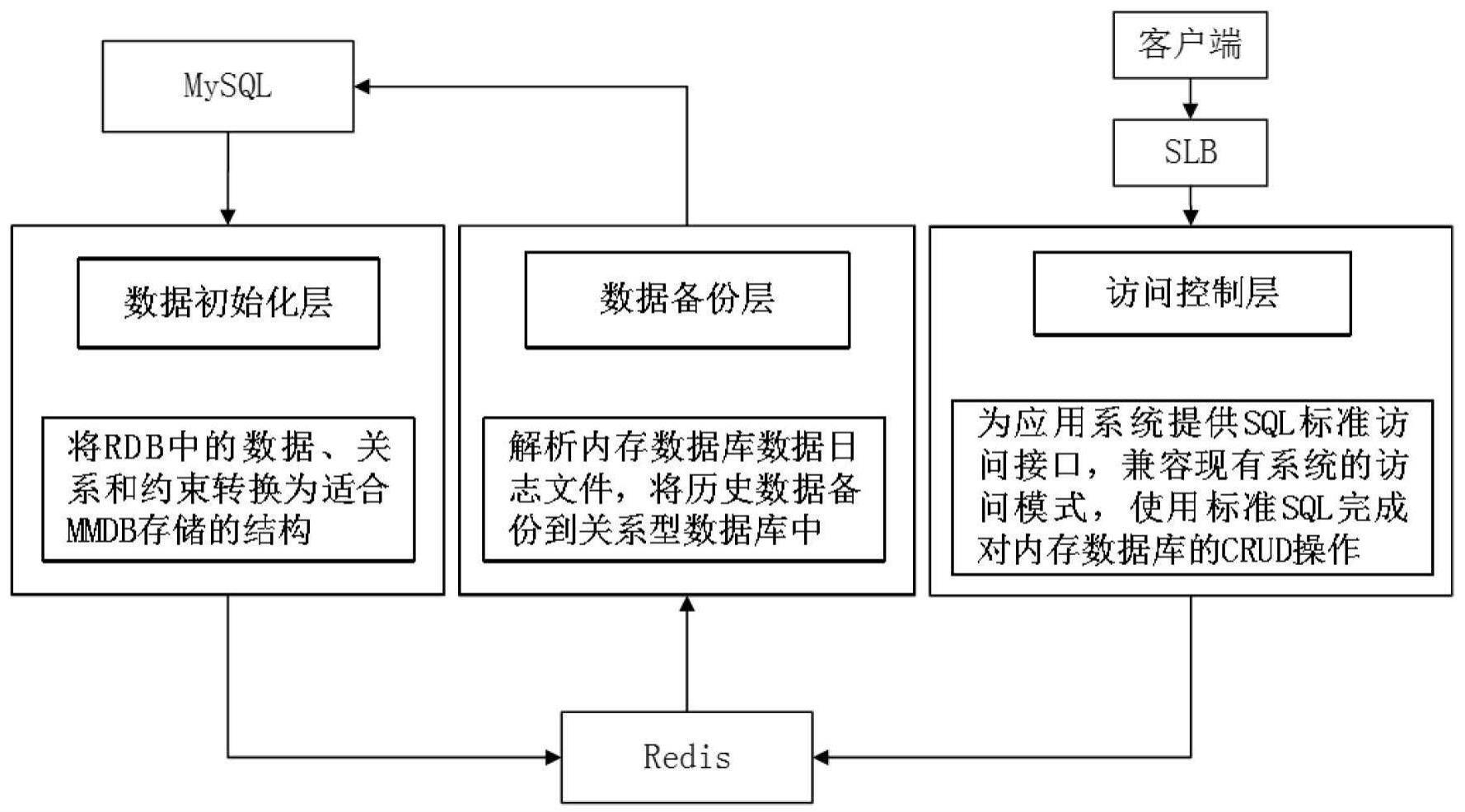
1、本发明的目的在于克服现有技术的缺点,提供了一种基于redis的关系型数据库全量内存化的方法,利用开源轻量级redis将mysql内存化的全量式内存化方案(含数据、关系和约束),利用内存数据库高效的内存计算和数据处理能力解决高并发环境下mysql的i/o读写瓶颈问题。
2、本发明的目的通过以下技术方案来实现:一种基于redis的关系型数据库全量内存化的方法,所述方法包括:
3、构建基于对象的行式存储模式orb-kvm、基于属性的行式存储模块arb-kvm和分段列式键值交叉存储模式pcb-kvcm将rdb中的数据、关系和约束转换为适合redis存储的对象,并通过迁移控制组件实现批量快速的数据库迁移;
4、设置sql操作中间件,通过其中的sql解析器组件、操作预检查组件和sql适配器组件对redis进行标准sql访问;
5、设置数据备份架构,分析redis的离线rdb数据文件,通过解析rdb日志文件,将文件中的数据内容转换为mysql支持的sql语句,批量执行sql实现数据从redis到mysql的备份存储。
6、所述数据库迁移包括以下内容:
7、a1、从mysql schema中获取指定数据库中每个表的表对象,记录每个表的表名、列属性、主键属性和记录行数信息,然后将每个表的表对象组合为全局表对象;
8、a2、判断mysql数据库中的所有关系是否转换完成,如果是,则跳转步骤a4,如果不是,则跳转步骤a3;
9、a3、使用存储转换模式中的关系转换算法实现所有关系转换,生成关系转换对象;
10、a4、判断mysql数据库中所有表的约束是否转换完成,如果是,则跳转步骤a6,如果不是,则跳转步骤a5;
11、a5、使用存储转换模式中的约束转换算法实现所有约束转换,生成约束转换对象;
12、a6、判断mysql数据库中的所有表的数据是否转换完成,如果是,则跳转步骤a8,如果不是,则选择任意未完成数据转换的表,跳转步骤a7;
13、a7、使用存储转换模式中的数据转换算法构建数据键值对象,生成数据转换对象;
14、a8、当需要迁移的转换结果对象个数超过预设的阈值时,通过迁移控制组件批量迁移关系转换对象、约束转换对象和数据转换对象;
15、a9、判断所有转换对象是否迁移完成,如果没有完成则跳转步骤a8。
16、所述基于对象的行式存储模式orb-kvm中的数据转换算法包括:
17、输入数据库对象db,初始化全局map类型表对象tabobjmap,以表名称为键,以表对象为值;
18、输入全局表对象tabobjmap,输出db中的所有表的自增主键tpk,设置ti(i<tcount)中的主键为pki,若主键存在,则通过公式获取到表中的主键pki,否则为主键值为默认值dpk;
19、针对每一个数据库表,输入数据库名称db、表名ti和主键pki,根据公式ki=m(db,ti,pki)拼接为redis中的key对象ki;
20、针对数据集djsonarr,jsonarr的长度为trlen,设置行对象为rowi,行记录中主键值为rkvali,行json对象为jrowi,根据公式jrow′i=r(jrowi,pki)移除json对象中主键及其对应的值,根据公式构建散列中的域字段field和域字段值value的集合nvali,再结合ki通过公式dm=build(ki,nvali)构建数据转换对象dm。
21、所述基于属性的行式存储模块arb-kvm中的关系转换算法包括:
22、输入数据库对象db,初始化全局map类型表对象tabobjmap,以表名称为键,以表对象为值;
23、输入全局表对象tabobjmap,输出db中的所有表的自增主键tpk,设置ti(i<tcount)中的主键为pki,若主键存在,则通过公式获取到表中的主键pki,否则为主键值为默认值dpk;
24、针对每一个数据库表,输入数据库名称db,表名ti和主键pki以及主键值pkvali,根据公式ki=m(db,ti,pki,pkvali)拼接为字符串对象ki;
25、针对数据集djsonarr,设置行对象rowi,行对象中的属性列长度为tcolcount,colk(k<tcolcount)和colvalk(k<tcolcount)分别为rowi中的每个列字段和列值,根据公式构建散列中的的域字段field和域字段值value的集合nvali,再结合ki通过公式dm=build(ki,nvali)构建数据转换对象dm。
26、所述分段列式键值交叉存储模式pcb-kvcm中的关系转换算法包括:
27、输入数据库对象db,初始化全局map类型表对象tabobjmap,以表名称为键,以表对象为值;
28、输入全局表对象tabobjmap,输出dm中的所有表的自增主键tpk,设置ti(i<tcount)中的主键为pki,若主键存在,则通过公式获取到表中的主键pki,否则为主键值为默认值dpk;
29、针对每一个数据库表,输入数据库名称db,表名ti和主键pki,针对每一个pk′i和分段s和e,根据公式拼接为对应redis中的key对象ki;
30、针对数据集djsonarr,设置行记录rt(t<trcount),属性字段ci(i<trcount),属性值为v(t,i),表示非主键列中当前行的主键值,vti表示ci列的所有数据集合,ci为redis中的域字段field,vti为域字段值value,根据当前列是主键或者非主键两种情况分别对vti进行构建,最后结合ki通过公式nvali=build(ci,vti)和dm=build(ki,nvali)构建数据转换对象dm。
31、所述基于对象的行式存储模式orb-kvm、基于属性的行式存储模块arb-kvm和分段列式键值交叉存储模式pcb-kvcm中的关系转换算法包括:
32、根据全局表对象获取指定库中的所有外键信息,主要包括主表对象、从表对象和依赖的字段;
33、根据主表对象和从表对象以及依赖字段建立有向图模型,其中有向图模型中的顶点表示表对象,有向边表示被依赖关系,权重表示被依赖的字段,根据有向图的出度和入度判断依赖和被依赖对象,确定表中的外键个数;
34、深度遍历有向图,设置常量c标识外键,通过公式fk=m(ki,c)和fm=build(fk,cid,tc)按照遍历排序构建外键关系散列fm。
35、所述基于对象的行式存储模式orb-kvm、基于属性的行式存储模块arb-kvm和分段列式键值交叉存储模式pcb-kvcm中的约束转换算法包括主键约束、唯一约束、默认约束、外键约束和检查约束;所述主键约束、唯一约束、默认约束和检查约束分别采用单独的散列存储,内存化后对redis数据的操作,对约束条件进行判断合法后再进行数据操作。
36、所述sql操作中间件由三层组成,第一层为输入层包括标准sql和redis原生操作,第二层包括sql解析组件、操作预检查组件和sql适配组件,第三层为redis集群数据层;其对redis进行访问的步骤包括:
37、通过sql解析组件获取sql的详细信息,构建sql解析对象;
38、根据sql解析对象的内容通过操作预检查组件按照操作类型判断是是否符合已有约束和表数据之间的关系;
39、通过sql适配组件根据sql解析对象中的内容调用redis原生接口完成对sql表达的数据操作的内容一致性操作。
40、所述通过sql解析组件获取sql的详细信息,构建sql解析对象包括:
41、对接收到的标准sql语句首先按照操作类型进行分类,再按照标准的语法格式对sql进行解析,对sql语句的字符流进行处理;
42、然后将字符流划分为相应的单词流进行词法分析,构造出包括操作类型、字段列、表名和条件的sql解析对象;
43、所述操作预检查组件按照操作类型判断是是否符合已有约束和表数据之间的关系包括:
44、解析所述sql解析组件构建的sql解析对象,识别此次sql的操作类型,如果是select,则直接略过,否则将进入操作预检查组件进行预检查;
45、如果是insert,则对多种约束组件进行判断,当全部约束组件都通过时,最终通过状态才会被标记为通过,否则标记为未通过;
46、如果是delete,则对外键约束组件进行判断,当满足外键关系删除时,最终通过状态才会被标记为通过,否则标记为未通过;
47、如果是update,则对多种约束组件进行判断,当全部约束组件都通过时,最终通过状态才会被标记为通过,否则标记为未通过。
48、所述数据备份架构包括rdb解析组件、json数据sql化组件和批量sql任务组件;所述rdb解析组件用于按照rdb文件的格式过滤文件中的非数据字符,批量将二进制数据文件转化为对应的json对象文件;所述json数据sql化组件用于分析json文件的数据内容,按存储模式的逆过程将json对象解析为sql语句;所述批量sql任务组件用于使用队列存放sql对象,当json数据sql化组件生成的sql对象被push到队列中,到达指定时间后,组件按照先进先出的顺序从队列中取出预设阈值个数的sql对象,然后调用mysql的驱动程序,执行对应的批量操作api批量执行sql存入到mysql中。
49、本发明具有以下优点:一种基于redis的关系型数据库全量内存化的方法,构建出三种不同的存储转换模式(orb-kvm、arb-kvm和pcb-kvcm)实现关系模型到键值模型的转换,存储转换模式中包括对数据、关系和约束的转换。并结合数据分页、多线程和redis批量命令技术实现数据库快速批量迁移;针对内存化到redis中的数据设计了标准sql访问中间件,利用java stream流技术和redis的数据结构特性对redis原生接口进行扩展与封装。同时实现了基于数据日志文件将redis中的数据备份到mysql;
- 还没有人留言评论。精彩留言会获得点赞!