基于重组对抗的统一机器阅读理解方法
1.本发明属于自然语言处理技术领域,尤其涉及基于重组对抗的统一机器阅读理解方法。
背景技术:
2.机器进行阅读理解的能力是衡量其智能水平的重要标准。其中选择式机器阅读理解,因其候选项多是对参考文本内容的同义改写,故而对机器理解文本的语义提出更高要求。当前最先进的解决选择式机器阅读理解的方法,主要在单一问题类型场景下定制化设计模型结构。然而,在现实阅读理解场景中,对同一篇文章往往会从不同的角度进行考察,导致问题可能存在多种类型,且对应候选项的数目不特定。鉴于此,不难发现以往定制化模型因过度考虑了单一问题场景的特征,无法拓展覆盖真实场景需求。
3.机器阅读理解(machine reading comprehension,mrc)是自然语言处理中的一个重要的基础任务,有助于进一步提高机器的智能水平。在该任务中,机器需要在充分理解提供的参考文本(句子、段落或者文章)的基础上解答特定问题。根据答案是否出现在相关文档中,可进一步将mrc分为抽取式阅读理解(extractive machine reading comprehension,emrc)和选择式阅读理解 (multi-choice machine reading comprehension,mcmrc)两个类型。emrc 需要从原文中抽取出能够回答问题的文本片段作为预测答案,部分任务会额外提供候选项。不同于前者,mcmrc中候选项内容大都是对原文内容的同义改写或总结归纳,因此在进行阅读理解时对机器的理解能力提出了更严苛的要求。
4.现有对mcmrc的研究工作,大致可分为三类:第一类方法通过设计注意力机制以实现文本、问题以及候选项之间的交互,进而促进信息的发现与融合使得模型更精准地预测结果。第二类方法基于预训练语言模型,第一阶段在预训练语料上进行预训练,第二阶段在下游具体的mcmrc任务中进行 fine-tuning。除了前述两类方法外,认知科学、证据句筛选以及图神经网络等技术手段也被引入mcmrc以期实现更好的效果。
5.具体而言,代表性方法albert(非专利文献:a lite bert forself-supervised learning of language representations)首先通过自监督任务在通用语料上进行预训练;其次根据下游任务的特征设计分类器,例如在四选一单选型数据集race(非专利文献race:large-scale reading comprehensiondataset from examinations)与dream(非专利文献dream:a challengedataset and models for dialogue-based reading comprehension)上的四分类器或三选一数据集reclo(非专利文献reclor:a reading comprehension datasetrequiring logical reasoning)上的三分类器等;最后利用分类器预测结果并 fine_tuning预训练模型。albert通过针对特定类型数据集定制分类器等结构,成功在各个任务上取得了sota结果。
6.值得注意的是,在现实阅读理解场景中,对同一篇文章会从不同的角度进行考察,这也就导致了问题可能存在多种类型混杂,例如选择题、判断题与匹配题等。伴随问题类型
多样化出现的是候选项数目的不特定性,可能存在正误判断的两个候选项、传统四选一的四个候选项以及匹配题中不定数量候选项等。例如,源自中学生科学课本上的阅读理解数据集tqa,包含1,076 篇参考文本与26,260个问题,平均每篇文章中有24个问题。为充分考察学生对课文的掌握程度,课后题类型涉及判断题、选择题与匹配题等多个维度,且题型穿插考察、分布无明显分块。
7.因此,如何让模型自适应地对混型阅读理解任务进行求解仍是一个挑战的问题。现有方法在编码时需要基于问题类型设计文本、问题与候选项的组合输入模式,例如选择题需要串联文本、问题以及候选项作为输入,而判断题则仅需匹配文本和问题,无需考虑候选项。此外,在进行最终概率预测时需要根据候选项数量设计分类器的输出形式,即二分类、四分类还是其它。尽管通过设计额外的类型判别器对问题类型进行判定,再分类处理的方法可以一定程度上缓解这些问题,但这种设计下的模型框架需要根据问题类型以及候选项数量的变化而定制化构建,无法应对动态变化的现实场景。因此,真实场景驱动的混型阅读理解任务还亟待专门的进一步研究。
8.现有的解决mcmrc相关任务的模型,根据设计思路的不同可将其分为基于注意力机制、基于预训练语言模型以及其他模型三类。传统模型通过收集和总结文章中与问题相关的证据(文本片段),随后进行证据与候选项的匹配选出最优答案。zhu haichao,wei furu,qin bing等人在非专利文献 hierarchical attention flow for multiple-choice reading comprehension提出这种简单的匹配检索模式没有充分利用文本中的信息,因此设计了基于神经网络的分层注意力流框架,以充分利用候选项来建模参考文本、问题和候选项之间的词级和句子级交互。wang shuohang,yu mo,jiang jing等人在非专利文献a co-matching model for multi-choice reading comprehension中将问题和候选项视为两个序列,对于参考文本中的每个字符计算来自问题与候选项的两个注意力加权向量,然后,将问题的位置信息和与参考文本特定上下文相匹配的候选答案进行编码并将它们与给定的文本联合匹配,实现信息从词级聚合到句子级,然后从句子级聚合到文档级。chen zhipeng,cui yiming,mawentao等人在非专利文献convolutional spatial attention model for readingcomprehension with multiple-choice questions中首先将参考文本、问题和候选项编码为通过附加pos标签和匹配特征增强的词表示。然后通过结合参考文本、问题信息来丰富候选项的表示,并使用卷积神经网络来动态地提取不同窗口大小下相邻区域间的空间相关信息,形成空间注意力。duan liguo,gaojianyig,li aiping等人在非专利文献a study on solution strategy ofoption-problems in machine reading comprehension中获取文章和问题的综合语义时,在拼接、双线性、点乘和差集4种常用注意力的基础上,融合 query2context和context2query两个方向的注意力,强化文章和问题的关键信息,弱化无关信息。
9.随着bert的出现,预训练语言模型被证明了在机器语言理解上具备强大性能。因此,研究者们考虑将其作为模型的编码层以设计与注意力机制相结合的结构。ran qiu,li peng,hu weiwei等人在非专利文献option comparisonnetwork for multiple-choice reading comprehension中提出了在字符级别显示比较候选项的比较网络,首先使用bert将候选项编码为向量序列作为其特征。然后,对于每个候选项使用向量空间中基于注意力的机制在词级将其与其他候选项进行一一比较,以识别它们的相关性。zhang shuailiang,
zhao hai, wu yuwei等人在非专利文献dcmn+:dual co-matching network formulti-choice reading comprehension中同样以bert为编码器提出了双协匹配网络,它双向合并了《参考文本,问题,候选项》三元组之间的所有成对关系,利用门控机制来融合来自两个方向的表示。此外,整合了人类通常使用的两种阅读策略。一种是文本句子选择,帮助从参考文本中提取证据,然后将证据与候选项相匹配。另一种是候选项交互,将比较信息编码到每个候选项中。这类方法着眼于设计注意力机制以发掘参考文本、问题以及候选项之间的关联关系。然而不同类型的问题具有不同特征需要有针对性的设计,例如在判断题中不必要设计候选项(“对”或“错”)与参考文本、问题的交互。
10.如上文提及,以bert的出现为标志,自然语言处理领域迈入预训练语言模型时代。预训练语言模型除了作为整体模型的编码模块外,也可直接对向量表示进行fine-tuning应用于mcmrc的下游任务。devlin j,chang ming-wei, lee k等人在非专利文献a co-matching model for multi-choice readingcomprehension提出了自编码语言模型bert,整体框架基于12层transformer 编码器,设计了随机mask并预测对应位置字符与句子连续性预测两个自监督任务以在通用语料上对模型进行预训练。最后经过一个与候选项数目相同的分类器预测每个候选项的概率。yang zhilin,dai zihang,yang yiming等人在非专利文献xlnet:generalized autoregressive pretraining for languageunderstanding中认为bert中的mask机制会导致训练和fine-tuning两阶段数据输入不统一,因此提出了xlnet。抛弃了mask机制,提出了双流自注意力机制。在transformer内部,从选定单词的上文和下文单词中,随机选择n-1 个,放到该单词的上文位置中,把其它单词的输入通过注意力掩码隐藏掉,以此结合自编码和自回归两种模型的特长。liu yinhan,ott m,goyal n等人在非专利文献roberta:a robustly optimized bert pretraining approach设计了 roberta,主要在三个方面对bert进行了改进:1)经实验验证后删除了句子连续性预测任务;2)提出了动态mask方案,在句子输入模型之后再进行随机mask;3)扩大了每轮训练的batch-size的尺寸。lan zhenzhong,chenmingda,goodman s等人在非专利文献albert:a lite bert forself-supervised learning of language representations出于让模型更轻、训练更快、效果更好的初衷提出了albert,采用了矩阵分解的方式先把词one-hot 向量映射到低维空间之后,再映射到隐藏层,其次所有编码层共享参数,最后设计了基于主题的关联去预测是否两个句子调换了顺序的自监督任务。
11.尽管该类方法在mcmrc各大榜单上取得了很好的成绩,但由于 fine-tuning时需要根据下游的具体任务设计特定的输入、输出形式,这一特点使得预训练语言模型无法直接使用在选项类型不固定的场景中。
12.除了上述两类主要研究路径之外,研究者们还在其他方向上探索了如何解决mcmrc。sun kai,yu dian,yu dong等人在非专利文献improving machinereading comprehension with general reading strategies受在认知科学研究中已被证明可有效提高人类读者的理解水平的阅读策略的启发,提出了三种相对独立的阅读策略来提升mcmrc:1)重复阅读,综合考虑输入序列的正序和反序;2)突出显示,将可训练的词向量表示添加到与问题和候选项相关的标记的文本表示中;3)自我评估,以无监督的方式直接从文本中生成问题和选项对模型效果进行评估。wang hai,yu dian,sun kai等人在非专利文献 evidence sentence extraction for machine reading comprehension致力于发现文本
中的证据句。由于大多数情况下缺乏真实的证据句子标签,因此采用了远程监督来生成不精确的标签,然后使用它们来训练证据句子提取器。随后利用深度概率逻辑学习框架对嘈杂的标签进行清洗以提升质量,再将句子级和跨句级语言指标结合起来进行半监督训练。huang yinya,fang meng,cao yu 等人在非专利文献dagn:discourse-aware graph network for logicalreasoning提出了一种基于文本的话语结构进行推理的话语感知图网络。该模型首先将话语信息编码为一个逻辑图,其中基本话语单元是节点,话语关系是边。其次利用图神经网络学习高级话语特征来表示文本,最后将话语特征与来自预训练语言模型的上下文标记特征相结合。
13.虽然这些模型在不同mcmrc任务上获得了不错的表现,但由于这些任务本身的局限性导致了它们无法在统一框架下直接迁移至问题多类型、候选项数量不特定的应用场景。
技术实现要素:
14.本发明提出的基于重组对抗的统一机器阅读理解方法,对于mcmrc的相关问题,将所有类型的问题都转化为逐个选项的正误判断,能够较好地解决上述问题。本发明提出了基于重组对抗的统一机器阅读理解框架,用一个统一的框架解决混型阅读理解问题。首先,通过重组层对候选项进行重新组合,以将所有类型问题整合为一种形式;其次,通过编码层和融合层充分实现参考文本与重组候选项间的交互,以使得重组候选项的向量表示中包含更多的支撑文本信息;最后,通过对抗学习增加训练过程中的随机扰动,以避免向量趋同问题,进而获得重组候选项的差异性表示。在源自中学生科学课本的阅读理解数据集上的实验结果表明,设计的方法能够较好地解决问题类型多样化、候选项数目不特定的问题。
15.为此,本发明研究了一种面向混型机器阅读理解的统一模型框架——提出了重组对抗模型(recombination adversarial model,ram),通过设计一个模型框架以应对问题多类型、候选项数量不特定的阅读理解场景。针对现有方法无法适用新问题的痛点,ram构建了一个新的阅读理解框架,将所有问题统一转化为单选判定形式,通过对每一个选项进行正误判定,解决了上述两个问题。具体而言,ram首先将候选项拆分,逐个与问题进行组合,形成设问句。随后,组合参考文本与新产生的候选项,从而将不同类型的问题转化成在参考文本的支撑下,对每个新的候选项预测其成立概率的判断题。这种变换克服了现有研究中无法统一进行多类型问题阅读理解的难题。为进一步丰富候选项中的信息容量,ram在完成编码后,设计了在候选项向量表示中融入参考文本与候选项的注意力交互结果,使得成立概率的判断愈加可靠。此外,在此框架下,由于同一问题下的新候选项中包含相同的组成部分(问题),可能使得原候选项中的内容在向量编码时被平滑,进而导致新候选项的向量表示趋于一致的问题。为此,提出在训练阶段采用对抗学习的方法,通过对向量表示进行随机扰动,迫使其在学习过程中更多地关注新候选项中的不同部分,扩大新候选项向量表示的差异性。最终,基于ram实现的模型在公开数据集上取得了优越的测试性能。
16.具体的,本发明公开的基于重组对抗的统一机器阅读理解方法,包括以下步骤:
17.获取类型多样化、候选项数目不特定的问题;
18.重组问题和候选项形成组合候选项,并依据参考文本对新候选项进行成立与否的判断,将实际阅读理解场景中的判断题、选择题以及匹配题统一转化成单选判定问题;
19.对重组获得的组合候选项与参考文本的共同编码,获得与参考文本及其他重组候选项交互后的重组候选项向量表示;
20.在所述重组候选项向量表示中融入与其相关的参考文本信息,以丰富所述重组候选项向量表示中蕴含的信息;
21.将每一个候选项向量视为一个单独的样本,对其成立与否进行概率判定,输出结果。
22.进一步的,所述将实际阅读理解场景中的判断题、选择题以及匹配题统一转化成单选判定问题包括:
23.将候选项拆分,逐个与问题进行组合,形成设问句;
24.组合参考文本与新产生的候选项,从而将不同类型的问题转化成在参考文本的支撑下,对每个新的候选项预测其成立概率的判断题。
25.进一步的,所述判断题的数学形式为:《p,q,a》三元组,
26.其中p表示参考文本,形式上是句子、段落或整篇文章;q表示自然语言形式的问题,a={a1,a2,...,an}表示与特定问题对应的候选项集合,n表示候选项的数量,当中有且只有一个正确答案。
27.进一步的,对于任一输入问题,将候选项拆分串联至问题后,组成与原候选项数量相同的新候选项,具体表示为:
28.c={c1,c2,...,cn}={q+a1,q+a2,...,q+an}
29.其中,c表示重组后的候选项集合;
30.将参考文本p作为背景知识与候选项结合以供机器判断候选项中的事实陈述是否成立,具体组合形式如下:
31.p,c1,c2,...,cn32.上式将所有候选项串联,考虑参考文本p中包含的信息,同时关注其他候选项中的关键信息,以发现不同候选项之间的关联关系。
33.进一步的,所述对重组获得的组合候选项与参考文本的共同编码,包括:
34.采用预训练语言模型roberta作为分词器进行文本的分词和词表映射,得到文本与候选项的编码,具体输入形式如下:
35.[cls]p[sep]c1[sep]c2[sep]...[sep]cn[sep]
[0036]
其中,[cls]表示roberta中标记输入文本起始位置的特殊字符,[sep]表示roberta中不同文本之间的间隔字符,n为文本的数量;
[0037]
获得参考文本和候选项的词向量表示:
[0038]
e=(e1,e2,...,em)∈rm×d[0039]
其中,e表示输入文本序列的词向量编码,em表示序列中第m个字符的词向量,r表示实数空间,m表示文本长度,d表示维度大小。
[0040]
进一步的,对于文本和候选项串联后长度超过512的数据,采用 longformer的滑窗机制、扩大的滑窗机制、融合全局信息的滑窗机制拓展输入上限到4096;
[0041]
或使用bigbird的随机注意力、窗口注意力以及全局注意力方法,将bert 中的复杂度降至线性,进而拓展输入上限到4096。
[0042]
进一步的,所述在所述重组候选项向量表示中融入与其相关的参考文本信息,包
括:
[0043]
设计文本与候选项之间的注意力机制:
[0044][0045]
s=softmax(a)
[0046][0047]
其中,tanh表示非线性激活函数以实现非线性映射,w
pc
表示可学习的权重矩阵,e
p
为参考文本向量表示,为候选项向量表示,b
pc
表示偏置项,j 为候选项的编号,softmax实现矩阵内数值在[0,1]上归一化,最终获得候选项cj关于参考文本的注意力向量表示
[0048]
采用mean_pooling获取每个候选项的平均向量表示,即:
[0049][0050]
其中,|
·
|表示特定对象的数量,sum表示线性加和,候选项平均向量表示 cj∈rd将被用于信息融合以及最终的概率预测;
[0051]
在获得注意力向量表示之后,使用高速路网络机制实现信息的融合,具体如下:
[0052][0053][0054][0055]
其中,wr和wg表示可学习的权重矩阵,[;]表示串联输入的向量,表示两个矩阵对应位置元素相乘,relu表示非线性激活函数,oj表示输入向量与中间向量的线性插值,g表示门控阈值以控制调整线性插值中各部分所占比重,是参考文本的平均向量表示;
[0056]
通过线性拼接得到经过融合层之后获得的候选项最终表示mj∈r
2d
:
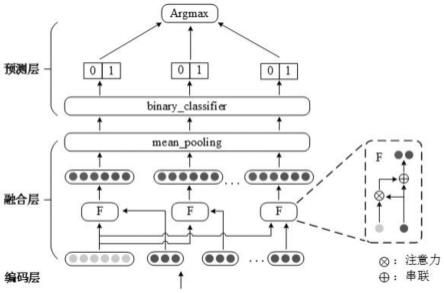
[0057][0058]
进一步的,所述将每一个候选项向量视为一个单独的样本,对其成立与否进行概率判定包括:
[0059]
通过一个二分类器对候选项向量进行[0,1]之间的概率预测:
[0060]
p=sigmoid(f
p
(m))
[0061]
其中,p表示候选项的概率输出,sigmoid用以平滑神经网络输出至[0,1] 之间,f
p
表示输出维度为1的二分类全连接预测网络;
[0062]
在训练时,对每一个候选项进行概率预测并逐一计算损失值,数学公式为:
[0063][0064]
其中,bce为二值交叉熵损失函数,l
p
表示计算得出的损失值,l表示真实标签的集
合,k表示第k个候选项,n表示当前batch_size中所有候选项的集合,|
·
|表示特定对象的数量,p表示模型的预测概率,l表示样本的真实标签。
[0065]
进一步的,引入对抗学习机制,在候选项向量表示中加入随机干扰,迫使模型关注有规律的关键语义分布,实现候选项向量的差异性表示。
[0066]
进一步的,在所述对抗训练中,用e表示输入,θ表示模型的参数,对抗训练在所述二分类器的损失函数上加入如下损失:
[0067][0068]
其中,r
adv
表示最终输入的随机扰动,r表示随机扰动,||
·
||表示二范数,ε表示超参数,l表示损失函数;
[0069]
采用下式实现上式在神经网络中的运算,具体的过程如下:
[0070]radv
=-εg/||g||
[0071][0072]
其中,g表示损失函数l对输入词向量表示e的梯度,表示梯度运算,f表示模型运算,y表示样本标签。
[0073]
本发明的有益效果为:
[0074]
发现了传统mcmrc任务设定中的不足,依据真实阅读理解场景提出了问题多类型、候选项数量不特定的阅读理解新任务,将多选问题转化为逐个候选项的正误判断。
[0075]
提出了统一解决上述问题的模型,包括统一不同类型问题的候选项重组层、实现长文本语义表示的编码层、丰富候选项信息的注意力融合层、扩大语义表示差异性的对抗训练模块以及预测层;
[0076]
为提高对不同候选项的区分能力,提出了融合层和对抗学习两个机制,实验证明了ram通过统一框架解决上述问题的有效性,以及不同组件设计的合理性。
附图说明
[0077]
图1本发明的模型框架图。
具体实施方式
[0078]
下面结合附图对本发明作进一步的说明,但不以任何方式对本发明加以限制,基于本发明教导所作的任何变换或替换,均属于本发明的保护范围。
[0079]
定义1(混型选择式阅读理解):mcmrc任务可以表示为提供《p,q,a》三元组,其中p表示参考文本,形式上可以是句子、段落或者整篇文章;q表示自然语言形式的问题,同一个参考文本下可能存在多个问题,问题的类型存在多样性;a={a1,a2,...,an}表示与特定问题对应的候选项集合,n表示候选项的数量,当中有且只有一个正确答案。要求机器依据参考文本对问题进行阅读理解,并最终从候选项中预测出正确结果。
[0080]
本发明的模型包括重组层、编码层、融合层、对抗训练模块以及预测层,其框架如图1所示。
[0081]
为解决问题多样性与候选项数量不确定的问题,本发明通过重组层重组问题和候选项形成组合候选项,并依据参考文本对新候选项进行成立与否的判断,实现了将实际阅
long-document transformer)作为编码机制。longformer改进了传统的自注意力机制,每一个字符只对固定窗口大小附近的其他字符进行局部注意力运算(local attention);并结合具体任务,对特定的字符片段计算全局注意力 (global attention)。具体来说,longformer共提出了三种新的注意力模式,分别是滑窗机制、扩大的滑窗机制、融合全局信息的滑窗机制。
[0098]
在滑窗机制中,对于每一个字符只计算其与附近w个字符的注意力,这也就使得计算复杂度降到了o(w
×
m)。在滑窗机制的基础上,longformer借鉴了空洞卷积的思想设计出了扩大的滑窗机制,在不增加计算负荷的前提下,在滑动窗口中涉及到的相邻字符间插入大小为d的空隙,从而将注意力的“视野”由w的上下文拓展到了w
×
d。此外,为根据服务于具体任务,longformer引入了global attention,允许在少量特定字符或者片段上进行与roberta相同的全局注意力计算。通过这些特定机制的提出,longformer将编码文本长度的上限提升到了4096,能够基本满足对长文本进行编码分析的需求。
[0099]
除此之外,bigbird(big bird:transformers for longer sequences)通过设计并结合随机注意力(random attention)、窗口注意力(window attention)以及全局注意力(global attention),也实现了将bert中的复杂度降至线性,进而拓展输入上限到4096。
[0100]
此时,可获得参考文本和候选项的词向量表示:
[0101]
e=(e1,e2,...,em)∈rm×d[0102]
其中,e表示输入文本序列的词向量编码,em表示序列中第m个字符的词向量,r表示实数空间,m表示文本长度,d表示维度大小。
[0103]
经过编码层,可获得参考文本向量表示e
p
∈r
x
×d、候选项向量表示其中x表示参考文本的长度,yj表示第j个候选项的长度。
[0104]
为进一步捕捉候选项与参考文本的关联关系,丰富候选项表示中包含的信息,本发明设计了文本与候选项之间的注意力机制:
[0105][0106]
s=softmax(a)
ꢀꢀꢀ
(3)
[0107][0108]
其中,tanh表示非线性激活函数以实现非线性映射,w
pc
表示可学习的权重矩阵,b
pc
表示偏置项,softmax实现矩阵内数值在[0,1]上归一化。最终获得候选项cj关于参考文本的注意力向量表示
[0109]
随后,本发明采用mean_pooling获取每个候选项的平均向量表示,即:
[0110][0111]
其中,|
·
|表示特定对象的数量,sum表示线性加和。候选项平均向量表示 cj∈rd将被用于信息融合以及最终的概率预测。
[0112]
在获得注意力向量表示之后,本发明使用高速路网络机制实现信息的融合,具体如下:
[0113][0114][0115][0116]
其中,wr和wg表示可学习的权重矩阵,[;]表示串联输入的向量,表示两个矩阵对应位置元素相乘,relu表示非线性激活函数,oj表示输入向量与中间向量的线性插值,g表示门控阈值以控制调整线性插值中各部分所占比重,是参考文本的平均向量表示。
[0117]
通过线性拼接可得经过融合层之后获得的候选项最终表示mj∈r
2d
:
[0118][0119]
尽管注意力融合机制使得ram部分掌握了区分候选项中关键信息的能力,但从公式(1)中可以看出,问题在候选项的组成中占了很大一部分。这可能导致模型在学习候选项向量表示时因不同候选项之间相同的成分过多平滑了原候选项信息,最终学习得到的表示相似度较高,进而影响预测效果。
[0120]
对抗学习旨在提升模型识别原始样本和对抗样本能力。其中,对抗样本 (adversarial examples)是通过在输入的原始样本上增加微小的随机扰动生成的样本。对抗学习最早在图像分类中被提出,其目目的是为了对一张图像加入人类肉眼难以分辨但对机器而言干扰性极大的扰动,以改变模型对该图像类别的预测。不同于在图像分类中直接将扰动加在原始输入样本上,文本分类中的对抗扰动并不作用在自然语言的文本上,因为离散的符号输入无法满足扰动插入时对连续性的要求,因此是作用在连续的词向量表示中。
[0121]
因此,本发明在训练时主动在训练中引入随机扰动以增大模型训练过程中的数据波动性,从而迫使其关注不同候选项表示之间的差异性。在对抗训练中,用e表示输入,θ表示模型的参数,对抗训练在原始分类器的损失函数上加入如下损失:
[0122][0123]
其中,r
adv
表示最终输入的随机扰动,r表示随机扰动,||
·
||表示二范数,ε表示超参数,l表示损失函数。
[0124]
ram采用了非专利文献big bird:transformers for longer sequences中的线性近似以实现上式在神经网络中的运算,具体的过程如下:
[0125]radv
=-εg/||g||
ꢀꢀꢀ
(10)
[0126][0127]
其中,g表示损失函数l对输入词向量表示e的梯度,表示梯度运算, f表示模型运算,y表示样本标签。
[0128]
经过上述流程处理后,模型将每一个候选项向量视为一个单独的样本,对其成立与否进行概率判定。通过这一操作,ram实现了对不同类型问题、不同数量候选项的统一预测。具体来说,模型的最后通过一个二分类器对候选项向量进行[0,1]之间的概率预测:
[0129]
p=sigmoid(f
p
(m))
ꢀꢀꢀ
(12)
[0130]
其中,p表示候选项的概率输出,sigmoid用以平滑神经网络输出至[0,1] 之间,f
p
表示输出维度为1的二分类全连接预测网络。
[0131]
在训练时,不同于传统模型中的多分类交叉熵损失计算,ram对每一个候选项进行概率预测并逐一计算损失值,运算遵循二值交叉熵损失函数 (binary cross entropy,bce)。数学公示为:
[0132][0133]
其中,bce为二值交叉熵损失函数,l
p
表示计算得出的损失值,l表示真实标签的集合,k表示第k个候选项,n表示当前batch_size中所有候选项的集合,|
·
|表示特定对象的数量,p表示模型的预测概率,l表示样本的真实标签。
[0134]
与常规损失值计算过程类似,对抗学习的训练过程仅需在向量输入时加入随机扰动r
adv
,具体运算过程为:
[0135]
p
adv
=sigmoid(f
p
(c+r
adv
))
ꢀꢀꢀ
(14)
[0136][0137]
综合二者,ram训练的最终损失函数为:
[0138]
l=l
p
+l
adv
ꢀꢀꢀ
(16)
[0139]
在测试时,直接采用公式(12)中预测结果作为候选项的概率预测,同一问题下选择概率值最大的候选项作为最终预测答案。
[0140]
本部分将首先介绍实验中设计的数据集、模型、参数等实验设定细节,其次在ttqa上测试了ram的整体效果,分析了不同类型问题、不同数量候选项的结果,随后进行了消融实验并给出了案例分析。
[0141]
为反应真实阅读理解场景下问题多类型、候选项数量不特定的特点,实验采用了tqa文本问答数据集(下面简称tqa,tqa是一个多模态教科书问题数据集,包含13693个纯文本问答题和12567个图文问答题;为充分评价模型有效性,本发明使用了tqa的纯文本问答题部分作为实验数据集,简称ttqa。数据集链接:https://allenai.org/data/tqa),从中抽取出了仅涉及文本问答部分的相关数据,并剔除了文本中涉及到的图片以及噪声数据。最终获得了1073篇文档及与之相对应的13049个问题及候选项,数据特征的具体统计如表1所示,其中“#”表示数量,
“‑”
代表对应数据集不存在该类别的样例, t/f表示判断题。按照tqa中原本的训练集/验证集/测试集的数据划分,ttqa 中同样将663文档用于训练、200文档用于验证以及210文档用于测试。与传统mcmrc的数据集相比,ttqa中包括了判断题、选择题两种类型,存在三种数量(2、4、7)的候选项,且文本平均长度较长,问题平均长度与候选项平均长度的比率较高。
[0142]
表1 mcmrc数据集统计信息
[0143][0144]
由于该类型任务系本发明首次提出,现有方法难以用统一的模型解决 ttqa中的相关问题,因此本发明设计了随机选择作为基线模型,3种不同设定下的ram进行实验分析。
[0145]
·
随机选择(random)。利用随机函数随机产生针对不同问题的结果预测;
·
ram(bi-lstm)。利用bi-lstm替换掉模型中的编码层,其余部分按照模型运行;
[0146]
·
ram(bigbird)。在编码层中使用big bird作为词向量编码器,其余部分按照模型运行;
[0147]
·
ram(longformer)。在编码层中使用longformer作为词向量编码器,其余部分按照模型运行。
[0148]
本发明中使用的roberta、bigbird与longformer均采用huggingface官方开源的transformers包中封装的版本。在bi-lstm、bigbird以及longformer 中,文本最大长度均设置为2500。bi-lstm中batch_size=64,hidden_dim=100,使用golve(glove:global vectors for word representation)。作为初始化词向量。bigbird及longformer中batch_size=9,词向量维度d=768。bigbird中注意力块尺寸block_size=64,随机注意力块数量num_random_blocks=3。 longformer中注意力窗口尺寸为attention_window=256,同时将候选项文本序列选作全局注意力对象。对抗学习中的超参数ε=1。模型测试环境为3*teslav100 32g显存服务器。实验采用精确度(precision)作为评价指标,即答对的题目数量在所有题目中所占比例。
[0149]
表2 整体实用结果
[0150][0151]
表2展示了实验结果,all为ttqa中所有问题的总结果。总体来说ram 的结果差强人意,最好的设定中(longformer)做对了69.56%的题目,相较人类中的优等生而言还有较大提升空间。此外,从表中可看出编码结构的不同对结果的影响较大,其中bi-lstm在长文本中因难以捕捉到长序列中的上下文信息,导致效果较差。longformer的效果超过big bird17.72%的原因可能在于滑动窗口的设定拓展了注意力的边界,使得ram在训练时学习到了更多的语义关联;同时,将候选项设置为全局注意力的对象更有助于建模候选项与参考文本的交互。为考察ram在解决多类型问题、不同数量候选项上的表现,本发明还将数据集进行了细化拆分,分别在不同设定上进行了实验,具体分析将在下文给出。
[0152]
ttqa中包含判断题(true or false,t/f)、多选题(multiple choice,mc)以及匹配题(matching),由于匹配题也是从多个选项中选出正确的一个,因此本发明将其纳入多
选题中统一进行分析,最终结果如表3所示。
[0153]
表3 多类型问题结果
[0154][0155]
总体来说,判断题的准确率要高于多选题。不过,相较随机选择中判断题的正确率是多选题的2倍,ram中双方的差距明显缩小,这证明本发明提出的结构在处理多类型问题上是有效的。此外,判断题效果好于多选题除了候选项数量的不同之外,另一个可能原因在于ram的框架本质上是一个将 mcmrc转化为单选正误判定的结构,因此,天然适合解决判断题问题。
[0156]
不同数量候选项分析:由于ttqa的选择题中没有双选题,因此选项数量为2的结果引用自判断题列,结果如表4所示。
[0157]
表4 不同数量候选项结果
[0158][0159]
从表中可以看出,随着候选项数量的增加,模型预测的准确率相应下降,这一现象符合人类在进行阅读理解测验时的真实情况,选项数量的增加往往意味着干扰项的增加,将进一步影响人的判断。不过对ram而言,候选项数量的增多意味着模型在学习不同候选项表示之间的差异性时难度增加。具体来说,模型在学习时倾向于在向量空间内区分正负样本的位置,ttqa中候选项长度(2.6)相较问题的平均长度(9.8)而言较短,容易导致等式(1) 产生的结果的重合部分过大。此时,候选项数量的增加意味着训练的负样本数量增多,而这些具有相同标签的负样本之间的重合度又较高,使得其在向量空间里的位置较接近,这将导致对不同候选项的表示的趋同,进一步增加模型区分不同候选项中关键信息的难度。本发明设计的注意力融合和对抗学习两个模块,解决了这一问题。
[0160]
为进一步分析ram中各部分在模型整体中发挥的作用以及对最终结果的影响,本节进行了消融实验,以ram(longformer)为分析模型,逐一对框架中不同组件进行调整。最终结果如表5所示,其中,enc表示编码层,fus 表示融合层,adv表示对抗学习。因bi-lstm可认为是ram删除编码层的结果,故在w/oenc中采用bi-lstm作为词向量编码测试该条目结果。
[0161]
表5 消融实验结果
[0162][0163]
删除编码层后效果的大幅下降(27.26%)是可以预测的,因为bi-lstm 无法克服长距离依赖问题,即存在传递过程中过度关注新加入文本,导致远距离信息在传递过程中的缺失。尽管其通过维护一个全局的向量信息来做信息融合,但仍会使得一些重要信息在融合过程中丢失。roberta通过 transformer的自编码器对序列进行注意力编码的过程极大缓解了这一问题,且在longformer中针对长文本的滑窗注意力、全局注意力等结构设计同样是极有效的。
[0164]
融合层的加入使得效果上升了1.56%,并且在各不同数量候选项的切分集上均有提升,证明了该模块的设计能够一定程度上帮助模型克服结构导致的候选项数量增加导致的表示趋同化问题。该现象也说明,尽管ram通过 longformer中的滑窗注意力以及全局注意力等机制设定,实现了候选项与参考文本向量表示之间的交互,但提取出不同粒度的信息进行注意力计算,仍能提升模型效果。
[0165]
对抗学习贡献了1.60%的效果增加,意味着其在解决趋同化问题时同样有效。这可能是因为随机扰动增大了候选项之间的差异性,增强了ram判定不同候选项的能力。具体来说,有大量重合部分(问题)的候选项在进入模型之后,因随机扰动的加入使得其在向量空间中的位置分布的差异性变大。模型在学习过程中尽管对负样本的处理仍然遵循拉近其距离的原则,但由于这些负样本中包含了随机扰动,致使模型不得不更多地关注规律性存在的文本特征。因而能够学习到不同候选项中的关键信息。
[0166]
本部分给出了不同数量候选项问题中的错误典例以形象展示ttqa的数据特性及ram的失误判断,结果如表6所示。
[0167]
表6 错误预测结果的案例分析
[0168][0169]
从表中不难看出,ttqa中的判断题不能抛开参考文本单纯通过外部知识进行预测,例如“被子植物是最成功的植物吗?”,需考虑被子植物对比的对象以及时间限定等要素。同一个问题在不同的文本环境中可能得出不同的答案。因此,本发明致力于通过编码层、融合层等设计增强ram对文本信息的捕捉能力。相较之下,选择题当中部分可依赖常识进行回答。
[0170]
本发明的有益效果为:
[0171]
发现了传统mcmrc任务设定中的不足,依据真实阅读理解场景提出了问题多类型、候选项数量不特定的阅读理解新任务,将多选问题转化为逐个候选项的正误判断。
[0172]
提出了统一解决上述问题的模型,包括统一不同类型问题的候选项重组层、实现长文本语义表示的编码层、丰富候选项信息的注意力融合层、扩大语义表示差异性的对抗训练模块以及预测层;
[0173]
为提高对不同候选项的区分能力,提出了融合层和对抗学习两个机制,实验证明了ram通过统一框架解决上述问题的有效性,以及不同组件设计的合理性。
[0174]
本发明所使用的词语“优选的”意指用作实例、示例或例证。本发明描述为“优选的”任意方面或设计不必被解释为比其他方面或设计更有利。相反,词语“优选的”的使用旨在以具体方式提出概念。如本技术中所使用的术语“或”旨在意指包含的“或”而非排除的“或”。即,除非另外指定或从上下文中清楚,“x 使用a或b”意指自然包括排列的任意一个。即,如果x使用a;x使用b;或x使用a和b二者,则“x使用a或b”在前述任一示例中得到满足。
[0175]
而且,尽管已经相对于一个或实现方式示出并描述了本公开,但是本领域技术人员基于对本说明书和附图的阅读和理解将会想到等价变型和修改。本公开包括所有这样的修改和变型,并且仅由所附权利要求的范围限制。特别地关于由上述组件(例如元件等)执行的各种功能,用于描述这样的组件的术语旨在对应于执行所述组件的指定功能(例如其在功能上是等价的)的任意组件(除非另外指示),即使在结构上与执行本发明所示的本公开的示范性实现方式中的功能的公开结构不等同。此外,尽管本公开的特定特征已经相对于若干实现方式中的仅一个被公开,但是这种特征可以与如可以对给定或特定应用而言是期望和有利的其他实现方式的一个或其他特征组合。而且,就术语“包括”、“具有”、“含有”或其变形被用在具体实施方式或权利要求中而言,这样的术语旨在以与术语“包含”相似的方式包括。
[0176]
本发明实施例中的各功能单元可以集成在一个处理模块中,也可以是各个单元单独物理存在,也可以多个或多个以上单元集成在一个模块中。上述集成的模块既可以采用硬件的形式实现,也可以采用软件功能模块的形式实现。所述集成的模块如果以软件功能模块的形式实现并作为独立的产品销售或使用时,也可以存储在一个计算机可读取存储介质中。上述提到的存储介质可以是只读存储器,磁盘或光盘等。上述的各装置或系统,可以执行相应方法实施例中的存储方法。
[0177]
综上所述,上述实施例为本发明的一种实施方式,但本发明的实施方式并不受所述实施例的限制,其他的任何背离本发明的精神实质与原理下所做的改变、修饰、代替、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1