一种基于草图的场景级细粒度视频检索方法及系统
1.本发明属于计算机视觉领域,具体涉及一种基于草图的场景级细粒度视频检索方法及系统。
背景技术:
2.草图作为一种手绘图像,通过简单的线条组合可以抽象性地展示物体的外观特征及位置信息,被广泛应用于基于草图的图像研究中,如图像补全、图像检索、图像生成等各项任务。草图可以跨越时序信息将不同时间段的物体及相应动作概括在一张草图内,在结合时序信息和空间位置上的优越性使其逐步被应用于视频相关任务上,基于草图的视频检索(sketch-based image retrieval,sbvr)任务取得了巨大的研究进展,它可被广泛应用于视觉、多媒体领域,如视频浏览、视频查询和编辑等工作中。但现有的大部分基于草图的视频检索工作采用传统方法,草图仅绘制简单的线条轮廓进行类别级别的视频检索;而采用深度学习方法的实例级别的视频检索仅针对单个物体,且不包含背景信息。
3.草图可以描述物体的外观特征及动作过程,结合空间位置和时序信息,可有效地提高视频检索效果。传统方法(参考文献:j.p.collomosse,g.mcneill,and y.qian,“storyboard sketches for content based video retrieval,”in 2009ieee 12th international conference on computer vision.ieee,2009,pp.245
–
252.)是先将视频帧分割为彩色区域,提取区域特征:面积、颜色、前景物体等,再通过帧间单映射代表相机运动,从而代表人的运动轨迹,然后由草图加草图符号来进行视频检索。peng xu(参考文献:p.xu,k.liu,t.xiang,t.m.hospedales,z.ma,j.guo,and y.-z.song,“fine-grained instance-level sketch-based video retrieval,”arxiv preprint arxiv:2002.09461,2020.)采用深度学习方法,利用三元组网络,特征提取分为外观特征流和动作特征流,最后将特征进行融合,利用三元组损失函数进行视频检索任务。场景级sbir(参考文献:f.liu,c.zou,x.deng,r.zuo,y.-k.lai,c.ma,y.-j.liu,and h.wang,“scenesketcher:fine-grained image retrieval with scene sketches,”2020.)实现的是场景草图检索图像,无法捕捉视频中的动作信息。
4.由上述可知,现有的基于草图的视频检索方法不能解决复杂场景下含有多个物体的细粒度视频检索问题。
技术实现要素:
5.本发明的目的在于提出一种基于草图的场景级细粒度视频检索方法(scene-level video retrieval with sketches)及系统,本发明进行场景级(即包含多个前景物体和背景信息)的基于草图的视频检索,通过将出现在不同时间段的物体压缩至同一张草图中,进行场景级的视频内容概括,检索出与草图背景元素、物体外观特征与动作类型均一致的视频。
6.为达到上述目的,本发明采用的技术方案如下:
7.一种基于草图的场景级细粒度视频检索方法,包括以下步骤:
8.对于绘制的场景草图,获取草图特征,包括整体外观特征,以及草图上实例的外观特征、类别特征和位置特征;根据这些草图特征构建草图空间结构图,该草图空间结构图包括草图外观结构图和草图类别结构图,该草图外观结构图是由表示实例的外观特征的实例节点、表示草图整体外观特征的一个场景节点和根据位置特征计算得到的表示距离的边共同构成,该草图类别结构图是由表示实例的类型特征的实例节点和根据位置特征计算得到的表示距离的边共同构成;
9.根据场景草图,采用自适应帧采样策略对视频进行采样,即先对视频帧进行稀疏采样得到候选视频帧,再对该候选视频帧利用训练好的草图-视频关联关系模型进行视频帧筛选,筛选出与场景草图最相关的视频帧并编码成视频;
10.对上述编码的视频,获取视频特征和时序信息,视频特征包括视频图像中整体外观特征、每个实例的外观特征、类型特征和位置特征;根据这些视频特征和时序信息构建视频时空结构图,该视频时空结构图包含视频空间结构图和视频时序结构图,该视频空间结构图包括视频外观结构图和视频类别结构图,该视频外观结构图是由表示实例的外观特征的实例节点、表示图像整体外观特征的一个场景节点和根据位置特征计算得到的表示距离的边共同构成,该视频类别结构图是由表示实例的类型特征的实例节点和根据位置特征计算得到的表示距离的边共同构成;该视频时序结构图根据所述时序信息、实例节点和场景节点构成;
11.将草图特征和视频特征输入到训练好的草图-视频检索模型中进行视频检索,该草图-视频检索模型包含外观分支和类别分支,该外观分支根据草图外观结构图和视频外观结构图生成视频检索结果,该类别分支根据草图类别结构图和视频类别结构图生成视频检索结果;将该两个检索结果进行外观特征和类别特征的融合,得到最终的视频检索结果。
12.进一步地,对于绘制的场景草图,采用预训练的googlenet inception-v3提取草图中的每个实例的外观特征,采用bert模型编码每个实例的类别特征,采用transformer中提到的相对位置处理方法并使用正弦和余弦函数获得位置特征,采用distance-iou根据位置特征计算实例之间的距离。
13.进一步地,采用两层的gcn网络进行草图特征更新,该gcn网络通过加入se模块对局部的实例节点进行特征融合。
14.进一步地,对上述编码的视频,采用resnet-152提取视频帧中的每个实例的外观特征,采用bert模型编码每个实例的类别特征,采用transformer中提到的相对位置处理方法并使用正弦和余弦函数获得位置特征,采用distance-iou根据位置特征计算实例之间的距离。
15.进一步地,采用两层的gcn网络结合se模块分别对视频空间结构图和视频时序结构图进行特征更新。
16.进一步地,草图-视频关联关系模型基于三元组网络构建,其训练方法为:利用训练集中草图和视频帧之间的匹配关系,由草图、视频帧正样本和视频帧负样本组成三元组匹配对,对草图-视频关联关系模型进行训练,通过训练学习草图和视频图像之间的语义和视觉关联关系。
17.进一步地,草图-视频检索模型基于三元组网络构建,其训练方法为:利用训练集
中待检索草图特征和视频特征,构建由草图特征、视频正样本特征和视频负样本特征组成的三元组匹配对,对草图-视频检索模型进行训练,计算最终的损失函数,通过调整模型参数使得损失降到最小,完成训练。
18.进一步地,所述最终的损失函数是由多个batch的损失函数进行平均得到,每个batch的损失函数为草图与视频正样本之间的距离和草图与负样本之间的距离的差值,再加上正负样本本身的间隔外,进行最大化。
19.进一步地,将草图-视频检索模型的两个分支的检索结果进行外观特征和类别特征的融合,是指对类别特征和外观特征分别得到的草图和视频之间的欧氏距离进行融合。
20.一种基于草图的场景级细粒度视频检索系统,包括:
21.草图检索视频的交互界面,包含用户输入界面和视频展示界面,该用户输入界面用于提供场景草图绘制工具以及绘制场景草图的面板,该视频展示界面用于展示检索出的视频;
22.草图特征获取模块,用于获取草图整体外观特征,以及草图上实例的外观特征、类别特征和位置特征;
23.草图特征更新模块,采用两层的gcn网络结合se模块对草图特征进行更新并对局部的实例节点进行特征融合;
24.视频特征获取模块,用于获取视频图像整体外观特征,以及图像上实例的外观特征、类别特征和位置特征,以及时序信息;
25.视频特征更新模块,用于采用两层的gcn网络结合se模块分别对视频空间结构图和时序结构图进行特征更新;
26.自适应帧采样模块,用于根据场景草图,采用自适应帧采样策略进行视频帧采样,即先通过稀疏采样得到候选视频帧,再通过基于三元组网络构建的草图-视频关联关系模型,并经训练实现对该候选视频帧进行筛选,筛选出与场景草图最相关的视频帧并编码成视频;
27.草图-视频检索模型,基于三元组网络构建并通过训练完成,包含外观分支和类别分支,用于根据输入的草图特征和视频特征进行细粒度视频检索,其中,外观分支根据草图外观结构图和视频外观结构图生成视频检索结果,类别分支根据草图类别结构图和视频类别结构图生成视频检索结果,将该两个检索结果进行外观特征和类别特征的融合,得到最终的视频检索结果。
28.本发明支持单张场景草图输入模式,在输入对应形式的草图后,检索出与草图中物体外形、类别、动作以及背景元素均一致的视频片段。本发明基于场景草图的细粒度视频检索,支持两种场景细粒度变化:一是前景物体变化,二是背景元素变化。采用图卷积神经网络与三元组网络结合的方式实现基于场景草图的细粒度视频检索。其中,对草图和视频通过构建图网络结构进行特征更新,将跨模态的特征映射到同一公共子空间,再构建三元组网络计算草图、视频之间的特征距离,实现检索功能。
29.与现有技术相比,本发明的有益效果是:
30.1.本发明方法与单物体、无背景的sbvr相比,场景级的视频检索更符合常见的视频类型,扩大了草图检索的实际应用场景。
31.2.本发明提出自适应视频帧采样策略,通过预学习场景级草图-图像对应关系,从
冗余的视频内容中高效地筛选与查询端草图最相似的多张视频帧,并将它们进行特征更新代表视频整体内容。该策略实现视频和草图的内容对齐,并可进一步提高视频特征提取的效率,减轻模型计算量。
32.3.本发明为实现细粒度的基于场景草图的视频检索,通过构建分支模型从类别分支和外观分支对草图和视频分别进行特征更新,从语义和视觉层面学习草图和视频之间的匹配关系。每个分支都包含场景草图的空间结构图和视频的时空结构图,并分别采用图卷积神经网络和时空图卷积神经网络进行特征更新。对两个分支进行单独训练,并在检索阶段将两个分支的检索结果进行结合。该方法有效地实现了视频的场景级细粒度检索,拓宽了草图检索视频领域的应用范围。
附图说明
33.图1是本发明实施例的基于草图的场景级细粒度视频检索网络结构图;
34.图2是本发明实施例的自适应视频帧采样策略图;
35.图3是本发明实施例的基于草图的场景级细粒度视频检索结果图示;
36.图4.本发明实施例的草图检索视频的交互界面图(包含用户输入界面及系统展示界面)。
具体实施方式
37.为了使本技术领域的人员更好的理解本发明,以下结合附图进一步详细描述本发明的技术方案,但不构成对本发明的限制。
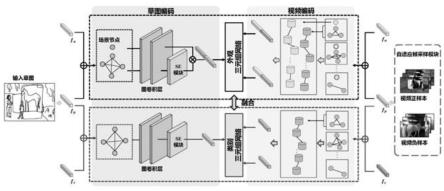
38.本实施例提出一种基于草图的场景级细粒度视频检索方法,提出建立自适应帧采样策略实现草图和视频内容之间的高效对齐;提出分支模型从类别和外观层面对草图、视频建立图结构;基于图卷积神经网络(graph convolution network,gcn)和时空图卷积神经网络(spatial-temporal graph convolution network,st-gcn,即gcn在空间和时序上进行特征更新)分别对草图和视频进行图特征更新;建立草图与视频特征匹配的三元组网络模型。主要内容模块分为草图特征编码、视频特征编码和草图、视频特征匹配三个模块,图1展示了基于草图的场景级细粒度视频检索框架图。
39.1.草图特征编码
40.1)草图空间结构图构建
41.对于场景草图s,建立草图空间结构图:草图类别结构图g
s,c
和草图外观结构图g
s,a
,每个图结构中包含n个实例节点代表实例级的信息,草图中的每个具有运动特征的物体代表一个实例。采用distance-iou的方式计算实例之间的距离作为实例的连接边。除此之外,草图外观结构图还包含着一个独立的场景节点将草图整体作为一个节点,不与其他实例节点连接,代表整体的外观特征。
42.其中,草图类别结构图中每个节点的特征为类别特征与位置特征相结合,草图外观结构图中每个节点的特征为外观特征和位置特征相结合。其中,采用预训练的googlenet inception-v3提取草图中每个实例的外观特征,特征维度为2048维;采用bert模型编码每个实例的类别特征,特征维度为768维;采用transformer中提到的相对位置处理方法,使用
正弦和余弦函数获得绝对位置特征。
43.2)草图特征更新
44.在建立草图空间结构图后,采用两层的gcn进行特征更新,草图类别结构图g
s,c
和草图外观结构图g
s,a
中的特征更新公式均为:
45.f
sl+1
=relu(aw
lfsl
)
46.其中a为邻接矩阵,w
l
是第l层的训练参数,relu为使用的激活函数。
47.其中,在通过gcn进行特征更新后,加入se模块(参考文献:j.hu,l.shen,and g.sun,“squeeze-and-excitation networks,”in proceedings of the ieee conference on computer vision and pattern recognition,2018,pp.7132
–
7141.)作为注意力机制,对局部的实例节点进行特征融合:
[0048][0049]
其中σ为sigmoid激活函数,w
se
为se模块的权重向量,f
si
为实例节点的特征。
[0050]
其中,对于草图外观结构图,在得到局部的实例节点特征后,与场景节点的特征进行特征拼接得到最终的草图外观特征f
s,a
:
[0051][0052]
2.视频特征编码
[0053]
1)自适应帧采样策略
[0054]
在视频特征编码过程中,最大的问题是由于视频的时序冗余性,它的关键内容隐藏在视频中。为了降低逐帧处理视频带来的巨大计算损耗并且进行草图和视频上的内容对齐,提出自适应视频帧采样策略采样与输入草图最相似的多张视频帧,图2展示了自适应帧采样策略的流程图。
[0055]
利用数据集中草图和视频帧之间的匹配关系,即草图、视频帧正样本和视频帧负样本组成三元组匹配对,构建基于三元组网络的草图-视频关联关系模型,通过训练来学习草图和视频图像之间的语义和视觉关联关系。
[0056]
在检索过程中,首先对视频进行稀疏采样作为候选视频帧,然后应用草图-图像关联关系模型去进一步地筛选与输入草图最相关的k张视频帧代表视频进行视频编码,该方法快速地筛选出与草图相关度最高的视频。
[0057]
2)视频时空结构图构建
[0058]
给定筛选出的k张视频帧,建立视频时空结构图,从空间和时序的角度提取视频帧的特征,视频时空结构图包含视频空间结构图和视频时序结构图。其中视频空间结构图中的每张视频帧的空间结构图,为与草图一致的空间结构图。
[0059]
视频帧中每个实例的外观特征通过resnet-152提取,类别特征和位置特征的提取方式与草图保持一致,实例的连接边由distance-iou计算实例之间的距离得到。
[0060]
其中视频时空结构图包含两个分支,即视频外观结构图和视频类别结构图。对于视频外观结构图,当视频空间结构图中所有实例的节点特征在通过se模块后,输出作为时
序结构图中的一个实例节点。进一步地,建立两个时序结构图和分别包含了每张视频帧在经过空间结构图特征更新后的场景节点和实例节点。
[0061]
对于视频类别结构图,由于图中仅包含实例节点,不包含全局的场景节点,因此仅建立一个包含时序实例节点的时序结构图。
[0062]
3)视频特征更新
[0063]
采用与草图特征更新相同的方式对视频空间结构图进行特征更新,并且再次采用两层的gcn结合se模块对视频时序结构图进行特征更新。最终从类别层面和外观层面分别获得视频特征f
v,c
和f
v,a
。
[0064]
3.草图-视频特征匹配
[0065]
在获得草图特征fs和视频特征fv之后,构建待检索草图特征视频正样本特征和视频负样本特征组成的三元组匹配对,并映射到同一公共子空间,输入到一个基于三元组网络的草图-视频检索模型中,其中视频正样本是数据集中与草图内容描述一致的正确视频,视频负样本通过遍历所有的视频计算出与正样本距离最远的视频得到,即:
[0066][0067]
其中argmin表示使目标函数取最小值时的变量值,i表示的是视频正样本的序号,j表示的是视频负样本的序号。
[0068]
对上述草图-视频检索模型进行训练,具体地,该草图-视频检索模型包含两个分支,即外观分支和类别分支;该外观分支用于根据草图空间结构图中的草图外观结构图,检索视频时空结构图中的视频外观结构图;该类别分支用于根据草图空间结构图中的草图类别结构图,检索视频时空结构图中的视频类别结构图;通过对这两个分支分别进行训练,实现单张草图的细粒度视频检索。具体损失函数的定义为将草图与视频正样本之间距离和草图与负样本之间距离的差值,再加上正负样本本身的间隔外,进行最大化:
[0069][0070]
其中d为欧式距离,δ为正样本和负样本之间的间隔,0代表的值为正,最小为0。
[0071]
将多个batch的结果进行平均,得到最终的损失函数:
[0072][0073]
b为batch大小,每个batch包含一批草图及对应的视频匹配对。
[0074]
通过调整模型参数使得上述损失降到最小,得到训练好的草图-视频检索模型。
[0075]
在正常使用阶段(含测试阶段),利用训练好的草图-视频关联关系模型和草图-视频检索模型进行视频检索,具体步骤如下:
[0076]
1.用户进入草图检索视频系统,在画布上形成自己的场景草图。系统提供草图绘制和草图素材拼接两种场景草图的生成方式。本示例中用户使用画笔在画布上绘制当前场景的背景元素,并进一步地指定素材栏中前景物体的类别,通过滑动素材栏,将想要的物体
拖拽至画布中输入场景草图,采用放缩、移动的操作调整物体朝向、比例,构成输入的场景草图(如图4左边列所示)。
[0077]
2.利用预训练的googlenet inception-v3提取草图中每个实例的外观特征,采用bert模型编码每个实例的类别特征,采用transformer中提到的相对位置处理方法使用正弦和余弦函数获得绝对位置特征,采用distance-iou的方式计算实例之间的距离作为实例的连接边。由外观特征和位置特征构成草图外观结构图,由类别特征和位置特征构成草图类别结构图,建立草图空间结构图。然后利用两层的gcn网络对上述特征进行更新。
[0078]
3.对数据库中的待检索视频通过自适应帧采样策略进行采样,首先进行稀疏采样,采样得到候选视频帧,然后利用训练好的草图-视频关联关系模型对候选视频帧进一步筛选,得到与草图相关度最高的视频。
[0079]
4.对于筛选出的视频帧,构建视频时空结构图,该视频时空结构图包含视频空间结构图和视频时序结构图。通过resnet-152提取视频帧中的实例的外观特征,采用bert模型编码每个实例的类别特征,采用transformer中提到的相对位置处理方法使用正弦和余弦函数获得绝对位置特征,采用distance-iou的方式计算实例之间的距离作为实例的连接边。由外观特征和位置特征构成视频外观结构图,由类别特征和位置特征构成视频类别结构图,得到视频空间结构图。然后利用两层的gcn网络对上述特征进行更新。
[0080]
利用训练好的草图-视频检索模型对视频进行检索,通过外观分支和类型分支分别输出结果,对两结果中的类别特征和外观特征分别得到的草图和视频之间的欧氏距离dc和da进行融合,融合公式如下:
[0081]
d=αdc+(1-α)da[0082]
其中α在实验过程中确定具体的值。
[0083]
在将从类别层面和外观特征层面得到的草图-视频距离进行融合之后,对待检索视频进行排序,得到最终的草图检索视频结果。草图检索视频的结果示意如图3所示,验证了检索方法的有效性。
[0084]
5.模型输出检索出的与输入草图相似性最高的前10个视频,并显示在检索结果栏里,用户可以在检索结果那一栏进行滑动,点击放大并播放检索出的视频,如图4右列所示。
[0085]
以上对本发明所述的:一种基于草图的场景级细粒度视频检索方法和装置进行了详细的说明,但显然本发明的具体实现形式并不局限于此。对于本技术领域的一般技术人员来说,在不背离本发明所述方法的精神和权利要求范围的情况下对它进行的各种显而易见的改变都在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1