一种基于深度学习的供水管网漏损识别方法
1.本发明涉及供水管网漏损检测技术领域,尤其涉及一种基于深度学习的供水管网漏损识别方法。
背景技术:
2.供水管道声学检漏方法,是根据管道泄漏产生的声发射信号或管道振动信号来判断漏损发生和漏点位置,在业界早已得到应用。例如水司检漏人员使用的听漏棒、电子听音设备等。近年来,在供水管网大量部署噪音计,利用物联网技术采集、上传现场信号,实现对管网漏损的监测。
3.无论是人工听漏,还是噪音计监测,由于声信号极易受到环境噪音干扰,一般采用夜间最小噪音法判断。夜间最小噪音法,是为了将外界干扰降到最低,选取夜间某一时段作为最佳采样时段,将此时采样的信号作为最可信数据进行处理的一种方法,该方法能够克服一些环境噪音干扰。但是,监测点夜间还是会受到小区/单位水箱进水干扰。面对干扰,一般通过小波降噪、模态分解、提取时频域特征、识别等常规信号处理方法
[1-3]
,提高检漏准确性。此类方法在实际应用中存在阈值难选取、泄漏特征难提取、参数敏感等问题,而影响检漏。
[0004]
文献[4]是一种供水管网漏损噪声数据库的构建及应用方法,利用模拟实验获得各种管径、材质、漏损孔径等泄漏时泄漏声,虽然便捷但不能完全符合实际情况;同时,该方法仍然以人为抽取特征为主,频域特性数据(平均频率、谱宽系数以及半功率带)、统计分布特性数据(噪声分布的偏度和峭度)、传播特性数据(噪声的声速以及不同频带内噪声强度的衰减系数),这些特征数据在不同泄漏情况下表现并非一致,而且有些参数不可能获得(譬如,衰减系数)。由此,该发明方法在解决样本少、识别难问题上仍存在不足。
[0005]
文献[5]尽管采用了一维卷积神经网络,但对原始声音振动信号的处理,仍然沿用了“通过滤波器对原始信号进行预处理,将时域信号转换为频域信号”的传统方法,因此,漏失原始信号中的时频联合特性,将直接影响其渗漏事故诊断准确性。
[0006]
参考文献:
[0007]
[1]张鑫.城市供水管网声波检漏及定位技术研究[d].太原理工大学,2015.
[0008]
[2]谭建勇.供水管道泄漏检测与定位系统的设计与实现[d].南京邮电大学,2018.
[0009]
[3]宿建波.小波变换在管道泄漏检测中的应用研究[d].山东:中国石油大学(华东),2007.doi:10.7666/d.y1214582.
[0010]
[4]宁波水表(集团)股份有限公司.一种供水管网漏损噪声数据库的构建及应用方法:cn202110833664.6[p].2021-10-29.
[0011]
[5]大连理工大学.基于一维卷积神经网络的给水管网渗漏事故诊断方法:cn202111185247.1[p].2022-01-11.
技术实现要素:
[0012]
针对上述常规信号处理方法存在的问题,本发明通过处理噪音计音频文件得到热力图基础上,采用深度学习方法,利用大量实际样本训练建立ai检漏模型,提高噪音计检漏准确性。
[0013]
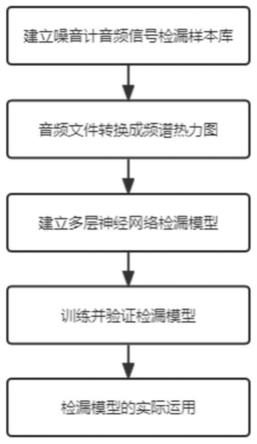
本发明提供了一种基于深度学习的供水管网漏损识别方法,包括以下步骤:
[0014]
步骤1建立噪音计音频信号检漏样本库
[0015]
步骤1-1收集供水管网各噪音计监测点的音频信号;
[0016]
步骤1-2对收集的音频信号按漏损与正常两种标签进行标识,建立噪音计音频信号检漏样本库。
[0017]
步骤2音频信号转换成频谱热力图
[0018]
步骤2-1根据式(1),对音频信号进行预加重处理:
[0019]
y[n]=x[n]-a*x[n-1]
ꢀꢀꢀ
(1)
[0020]
式(1)中,x[n]为原始信号,y[n]为预加重后信号,a为接近1的参数;
[0021]
步骤2-2对预加重处理后的信号进行分帧处理:将信号按固定时间段分为若干帧;
[0022]
按一定比例设置帧移和帧长;
[0023]
步骤2-3对分帧之后的信号进行加窗操作;
[0024]
步骤2-4对分帧、加窗处理后的信号进行快速傅里叶变换fft,得到频谱信息;
[0025]
步骤2-5将时间帧的序号作为横坐标、频率值作为纵坐标、频谱幅值的大小以颜色表示,得到频谱热力图;
[0026]
步骤3建立多层神经网络检漏模型
[0027]
以频谱热力图为输入,以分类结果为输出,建立由多层卷积神经网络组成的神经网络检漏模型
[0028]
步骤4训练并验证多层神经网络检漏模型
[0029]
步骤4-1将样本库中两类样本均以一定比例进行划分,形成训练集和测试集,进行多层神经网络检漏模型的训练;
[0030]
步骤4-2测试多层神经网络检漏模型在测试集样本上的预测结果,并计算其准确率accuracy和接受者操作特征roc曲线下方的面积auc指标;其中,模型预测结果指的是:预测结果为漏损的可能性,数值越大表示越有可能漏损;
[0031]
步骤4-3根据多层神经网络检漏模型预测结果和步骤1中标识的标签,计算得到混淆矩阵;
[0032]
步骤4-4通过auc曲线寻找最佳阈值th,所述auc曲线的横坐标为:fp,纵坐标为:tp,根据auc曲线上最靠近坐标(0,1)的点,所对应的概率值确定为最佳阈值th;
[0033]
步骤4-5得到最佳阈值th后,将概率与阈值进行对比,得到二分类预测标签;
[0034]
步骤4-6利用二分类预测标签进行混淆矩阵tp/fp/fn/tn、准确率accuracy、灵敏度precision、特异度specificity参数的计算,以进一步对多层神经网络检漏模型进行验证;
[0035]
其中,准确率accuracy按式(2)计算:
[0036]
accuracy=(tp+tn)/(tp+tn+fp+fn)
ꢀꢀꢀ
(2)
[0037]
灵敏度precision(阳性预测率)按式(3)计算:
[0038]
precision=tp/(tp+tn+fp+fn)
ꢀꢀꢀ
(3)
[0039]
特异度specificity(阴性预测率)按式(4)计算:
[0040]
specificity=tn/(tp+tn+fp+fn)
ꢀꢀꢀ
(4)
[0041]
三者的数值越接近1,表示多层神经网络检漏模型分类的性能越好;
[0042]
步骤4-7如多层神经网络检漏模型通过验证,则进入步骤5实际应用;否则,重新挑选样本,重复步骤1-4。
[0043]
步骤5利用步骤1-4得到通过验证的多层神经网络检漏模型,进行实际判漏。
[0044]
步骤5-1获取实测得到的音频信号数据,
[0045]
步骤5-2按照步骤2计算方法,转换生成频谱热力图;
[0046]
步骤5-3将该频谱热力图作为输入,经多层神经网络检漏模型计算得到预测结果,再与最佳阈值th比较,输出最终二分类标签0或1,从而得到供水管网是否漏损的判断。
[0047]
作为优选,所述步骤3中,采用深度残差网络resnet-50模型为backbone,建立多层神经网络检漏模型。
[0048]
作为优选,所述步骤4-6中进一步对多层神经网络检漏模型进行验证,所述验证指标中,准确度accuracy、灵敏度precision、特异度specificity都要高于0.9。
[0049]
作为优选,所述步骤5还包括以下步骤:
[0050]
步骤5-4如发现检漏模型判断准确性降低,可审查样本库,重复步骤1-4,重建检漏模型。
[0051]
作为优选,所述步骤1中的音频信号为固定采样频率采集的2-3秒音频信号数据,所述步骤1中的样本库包括不同管径、材质、漏况的实际样本;所述样本库样本量不少于5000例。
[0052]
作为优选,所述步骤2-1中,
[0053]
参数a的值设置为通常设置为0.97或0.95。
[0054]
作为优选,所述步骤2-2中,所述若干帧的每一帧的时间段长度为20-40ms;
[0055]
设置帧移和帧长的比例为1:4或1:5。
[0056]
作为优选,所述步骤2-5中,所述频谱幅值的大小通过以下方式转换成颜色表示:
[0057]
频谱幅值的大小以颜色表示,是通过标准的颜色映射表colormap将数值转换成颜色,最小值0为深蓝色,由小到大为浅蓝、浅绿、黄色、橘色、红色,最大值255为深红。
[0058]
本发明专利的有益效果:
[0059]
相比于音频文件常规处理方法,本发明方法中的频谱热力图包含信息量更大,不仅包含频率和频谱幅度,还包含了时域信息,更有利于检测识别。相比于传统的特征提取、模式识别方式,深度学习方法主要是数据驱动进行特征提取,根据大量样本的学习得到深层的、数据集特定的特征表示,其对数据集的表达更高效和准确,所提取的抽象特征鲁棒性更强,泛化能力更好。
[0060]
本发明方法利用既有的大量实际样本,通过cnn模型自学习能力自行抽取特征进行识别,突破人为经验限制,在高质量、海量样本的监督学习下,得到更精准的检漏能力。
附图说明
[0061]
为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体
实施方式或现有技术描述中所需要使用的附图作简单介绍,后文将参照附图以示例性而非限制性的方式详细描述本发明的一些具体实施例。本领域技术人员应该理解,这些附图未必是按比例绘制的。附图中:
[0062]
图1为本发明方法总体流程图
[0063]
图2为音频转频谱热力图流程图
[0064]
图3为不同状态下音频的频谱热力图,其中左侧部分为漏损情况,右侧部分为正常情况
[0065]
图4为模型评估auc曲线
具体实施方式
[0066]
为了使本技术的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本技术进行进一步详细说明。应当理解,此处描述的具体实施例仅用以解释本技术,并不用于限定本技术。
[0067]
本发明方法具体步骤如下:
[0068]
步骤1建立噪音计音频信号检漏样本库
[0069]
噪音计物联网平台在长期的监测过程中,收集、存储供水管网各监测点的音频文件,并根据传统方法进行了标识(正常、疑似、漏损)。这里,结合抢修数据,对证实的漏损点抢修前后、附近监测点音频文件按漏损与正常两种标签进行精准标注,建立噪音计音频信号检漏样本库。
[0070]
所述的音频文件,一般为固定采样频率采集的2-3秒音频信号数据。样本库尽量多地收集各种管径、材质、漏况的实际样本。优选地,样本量不少于5000例。
[0071]
步骤2音频文件转换成频谱热力图
[0072]
在通常情况下,由于音频的高频分量强度较小、音频的低频分量强度较大,需要将信号的高低频分量得到平衡,故对信号进行预加重处理,如式(1):
[0073]
y[n]=x[n]-a*x[n-1]
ꢀꢀꢀ
(1)
[0074]
式(1)中,x[n]为原始信号,y[n]为预加重后信号,a为接近1的参数,通常设置为0.97或0.95。
[0075]
对预加重处理后的信号进行分帧处理:将信号按固定时间段分为若干块,一块即为一帧。其中,每一帧的时间段长度叫帧长,一般取20-40ms。为确保音频特征参数的平滑性,一般采用重叠取帧的方式,即相邻帧之间存在重叠部分,该重叠部分叫作帧移。一般来说,帧移和帧长的比例为1:4或1:5。
[0076]
分帧相当于对音频信号加矩形窗,矩形窗在时域上对信号进行截断,在边界处存在多个旁瓣,会发生频谱泄露。为了减少频谱泄露,通常对分帧之后的信号进行其它形式的加窗操作。常用的窗函数有:汉明(hamming)窗、汉宁(hanning)窗和布莱克曼(blackman)窗等。
[0077]
对分帧、加窗处理后的信息进行快速傅里叶变换(fft)得到频谱信息,将时间帧的序号作为横坐标、频率值作为纵坐标、频谱幅值的大小以颜色表示,即得到频谱热力图。
[0078]
这里,频谱幅值的大小以颜色表示,是通过标准的颜色映射表(colormap)将数值转换成颜色。
[0079]
步骤3建立多层神经网络检漏模型
[0080]
利用卷积神经网络cnn在图像识别领域的优势,以频谱热力图为输入,以分类结果为输出,建立多层神经网络检漏模型。
[0081]
优选地,采用深度残差网络resnet-50模型为backbone,建立多层神经网络。resnet在2015年被提出,在图像检测、分割、识别等领域里已得到广泛应用。
[0082]
步骤4训练并验证检漏模型
[0083]
样本库中两类样本均以7:3的比例进行划分,构成占总数据集7成的训练集和占总数据集3成的测试集,将音频文件转换成频谱热力图,进行多层神经网络检漏模型的训练。
[0084]
训练结束后,测试检漏模型在测试集样本上的预测结果,并计算其准确率(accuracy)和auc(area under curve,接受者操作特征roc曲线下方的面积)指标。其中,模型预测结果指的是:预测结果为漏损的可能性,数值越大表示越有可能漏损。
[0085]
根据模型预测结果和样本的真实标签,计算得到混淆矩阵(如表1),得到真阳性(tp:true positive)、假阳性(fp:false positive)、真阴性(tp:true negatives)和假阴性(fn:false negatives)。
[0086]
表1混淆矩阵
[0087][0088]
本发明通过auc曲线寻找最佳阈值th。这里,auc(area under curve):接受者操作特征roc曲线下的面积,介于0.1和1之间,auc作为数值可以直观的评价分类器的好坏,值越大越好。auc曲线的横坐标为:fp,纵坐标为:tp,图片上越靠近点(0,1)的坐标,所对应的概率值,所能分类的效果就越好。
[0089]
得到最佳阈值th后,将概率与阈值进行对比,得到二分类预测标签。利用预测标签进行混淆矩阵tp/fp/fn/tn、准确率accuracy、灵敏度precision、特异度specificity等参数的计算,以进一步对模型进行验证。
[0090]
其中,准确率accuracy按式(2)计算:
[0091]
accuracy=(tp+tn)/(tp+tn+fp+fn)
ꢀꢀꢀ
(2)
[0092]
灵敏度precision(阳性预测率)按式(3)计算:
[0093]
precision=tp/(tp+tn+fp+fn)
ꢀꢀꢀ
(3)
[0094]
特异度specificity(阴性预测率)按式(4)计算:
[0095]
specificity=tn/(tp+tn+fp+fn)
ꢀꢀꢀ
(4)
[0096]
三者的数值越接近1,表示模型分类的性能越好。优选地,验证指标为:准确度accuracy、灵敏度precision、特异度specificity都要高于0.9。如模型通过验证,则进入步骤5实际应用;否则,重新挑选样本,重复步骤1-4。
[0097]
步骤5检漏模型的实际运用
[0098]
利用步骤1-4得到通过验证的检漏模型,进行实际判漏。
[0099]
针对噪音计实测得到的音频文件数据,首先按照步骤2计算方法,转换生成频谱热力图;其次,将该频谱热力图作为输入,经检漏模型计算得到预测结果,再与最佳阈值th比较,输出最终二分类标签0或1,从而得到供水管网是否漏损的判断。
[0100]
实际运用中,如发现检漏模型判断准确性降低,可审查样本库,重复步骤1-4,重建检漏模型,以适应实际工况变化。
[0101]
以某市安置在cb片区的10个噪音计2022年1月1日至3月1日两个月的音频数据为例(采样频率8192hz),进行本发明实施例的具体实施方式说明。
[0102]
本发明方法流程图,如图1所示,具体步骤如下:
[0103]
步骤1建立噪音计音频信号检漏样本库
[0104]
2022年01月01日至02月28日,某市cb片区安置了10个噪音计,在噪音计物联网平台2个月的监测过程中,收集、存储供水管网各监测点的音频文件7000多例,并根据传统方法进行了标识(正常、疑似、漏损)。
[0105]
这里,结合抢修数据,对证实的漏损点抢修前后、附近监测点音频文件进行精准标注。按漏损与正常两种类别进行分类,建立噪音计音频信号检漏样本库。
[0106]
所述的音频文件,为固定采样频率(8192hz)采集的2.5秒音频信号数据。优选地,5700例。
[0107]
其中,音频信号包含管网已探明确实存在漏损情况的信息,以及管网漏损修复后,正常(无漏损)情况下的信息。按漏损与正常两种类别进行分类,分别标记为1(漏损)和0(正常),漏损:4600例,正常:1100例。
[0108]
步骤2音频文件转换成频谱热力图
[0109]
音频转热力图流程图,如图2所示,具体步骤如下:
[0110]
利用步骤1建立好的噪音计音频信号检漏样本库,
[0111]
(1)将样本取出并附带标签信息,依次进行音频数据读取,得到时域信号x[n];
[0112]
(2)为平衡高低频分量,通过公式(1)对原始信号x[n]进行预加重处理,得到预加重后信号y[n],其中,加重系数a设置为:0.97;
[0113]
(3)对信号y[n]进行分帧处理,帧长设置为:25ms,帧移设置为:10ms;
[0114]
(4)加窗处理,窗函数选择:汉明(hamming)窗;
[0115]
(5)对加窗后的信号,进行快速傅里叶变换(fft)得到频谱信息;
[0116]
(6)将时间帧的序号作为横坐标、频率值作为纵坐标、频谱幅值的大小以颜色表示,得到频谱热力图。其中,频谱幅值的大小以颜色表示,是通过标准的jet格式颜色映射表(colormap)将数值转换成颜色,最小值0为深蓝色,由小到大为浅蓝、浅绿、黄色、橘色、红色,最大值255为深红;图片名称包含:设备号、音频采集时间信息。
[0117]
图3为音频的频谱热力图,包含漏损和正常两种情况。
[0118]
步骤3建立多层神经网络检漏模型
[0119]
利用卷积神经网络cnn在图像识别领域的优势,以频谱热力图为输入,以分类结果为输出,建立多层神经网络检漏模型。具体采用深度残差网络resnet-50模型为backbone。建立模型步骤:
[0120]
(1)数据预处理:读取音频的频谱热力图并将图片缩放到统一尺寸(224,224),随后依次进行数据增强、归一化、标准化操作。
[0121]
(2)设置batch_size=16、抽取数据的方式为随机,进行小批量迭代训练;
[0122]
(3)加载检漏模型并初始化学习率lr=1*10-4
,采用adam策略优化。
[0123]
(4)epoch设置为6(拟进行6轮训练),并保存每一轮模型权重、测试集预测结果、预测精确度(accuracy)、auc数值等参数。
[0124]
由此,建立多层神经网络检漏模型。
[0125]
步骤4训练并验证检漏模型
[0126]
将热力图作为多层神经网络检漏模型的输入,进行训练。
[0127]
用于训练的热力图是以文件夹进行区分。建立两个文件夹:训练集(文件名为:train)、测试集(文件名为:test),在文件夹中,分别再新建两个文件夹:漏损(文件名为:1)、正常(文件名为:0)。将每一类图片以7:3的比例放入训练集和测试集对应的文件夹中。
[0128]
训练后得到每一轮模型的一次权重、测试集预测结果、预测精确度(accuracy)、auc数值等参数。
[0129]
经比较,取最大的auc数值:0.978,利用auc曲线(如图4所示)找到最佳阈值th=6.3*10-4
,用该阈值再次分类得到模型预测结果,算出准确率约为0.98,灵敏度约为0.97,特异度约为0.99。结果均高于0.90,说明模型的分类达到验证指标,可以使用。
[0130]
步骤5检漏模型的实际运用
[0131]
在该市gs区某小区,存在漏损情况,布置了多个噪音计进行音频的采集,本次实际运用采用的是#211****001设备的音频。已知,该小区在12月08日08时至12月14日11时,存在漏损情况,该时段音频有143例;该地在12月04日02时至12月05日07时,无漏损情况,该时段音频有24例。
[0132]
利用步骤1-4得到的模型,对上述数据进行生成频谱热力图、模型预测结果、利用之前的最佳阈值th=6.3*10-4
进行分类,验证结果为:精确度=0.98。
[0133]
以上所述,仅为本发明的典型应用,但本发明的保护范围并不局限于此,任何熟悉本领域的人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1