基于深度学习的地表绿网苫盖提取方法与流程
1.本发明涉及一种地表绿网苫盖提取方法,尤其涉及一种基于深度学习的地表绿网苫盖提取方法。
背景技术:
2.城市发展带动了整个社会经济发展,城市建设成为现代化建设的重要引擎,也带来了大量的施工建设工地。然而施工建设过程会对周边环境造成污染,所以在实际建设过程中,相关管理部门和施工企业需要采取有效的应对措施最大程度的减少施工现场各类污染,保护建设区域的周边环境。施工过程中使用绿网覆盖裸露的土地,可以有效的治理扬尘,这是治理扬尘的有效措施,因此绿网苫盖作为建筑工地抑尘的主要措施而被广泛使用。快速获取地表绿网苫盖的空间分布与数量信息,对防尘抑尘、生态环境保护措施的制定具有重要的指导意义。
3.目前对于绿网苫盖的提取研究较少,尚未有系统性的方法技术提出,现主要依靠施工建设台账数据进行估算统计。现有的方法主要存在两个弊端:(1)缺乏精确性,从现有数据仅能得到施工建设的位置,无法得到具体的绿网苫盖分布和数量;(2)缺乏直观性,无法从图像的角度直观展示绿网苫盖的覆盖状况。而地理信息科学(gis)技术的研究对象之一是地表要素的空间信息与属性信息,而绿网苫盖也是一种地表覆盖要素,因此可借助于gis的方法进行绿网苫盖提取。而gis方法的实现需要两方面的支撑,一是数据支撑,二是方法支撑。
4.在数据来源方面,遥感影像可为地表要素覆盖的提取提供可靠的数据来源。遥感作为一种重要的对地观测技术,通过人造卫星或者无人机向地面发送和接收电磁波信号的方式完成对地面物体的监测与分析。遥感影像具有全天候、覆盖广、更新快的优势,而且遥感影像具有地物种类多样化、地物特征复杂度高、地物信息丰富等特点,为地物要素提取提供了重要的信息来源。近年来我国测绘遥感卫星取得长足进步,快捷高效的获取海量高分辨率遥感数据已成为现实。
5.在技术方法方面,可对高分辨率遥感影像进行解译,提取目标地物要素。而地物要素的提取问题,本质上属于语义分割问题。图像语义分割是根据图像本身的纹理,颜色以及场景等信息,来得出图像中每个像素所属的类别信息。在语义分割任务中,需要准确的把图像中的每一个像素分类到一个特定的类别,图像语义分割可以提供物体在图像中的类别信息,位置信息,姿态信息,以及环境信息等。遥感影像的语义分割方法可分为五类,分别是基于像素点的分割方法、基于边缘的分割方法、基于区域的分割方法、基于数学模型的分割方法、基于机器学习的分割方法。
6.近年来机器学习领域取得重大发展的是深度学习。深度学习方法是具有多个级别的表示学习方法,由多个简单但非线性的模块构成,每个模块将该层的特征信息转换为更高层次的抽象表示,这样经过足够多的转换,就可以学习到非常复杂的信息。近年来,深度卷积神经网络已经应用到许多像素级分类的图像语义分割任务中,并涌现出了一系列优秀
的网络,其中具有里程碑意义的工作是全卷积神经网络(fcn),它向人们展示了如何使用深度卷积神经网络对任意大小的输入图像进行端到端的逐像素语义分割。目前,基于fcn架构已演变出多种语义分割网络,如alexnet、vggnet、googlenet、u-net等。深度学习的出现使得语义分割任务能够高效精准完成。
7.综上可知,从数据和方法层面都可以支撑本发明中利用深度学习网络提取绿网苫盖的实现。
技术实现要素:
8.为了解决上述技术所存在的不足之处,本发明提供了一种基于深度学习的地表绿网苫盖提取方法,利用深度神经网络构建模型,从高分辨率遥感影像中提取绿网苫盖,既能够直观的反映绿网苫盖在城市中的分布,又能够提高绿网苫盖提取的精度。
9.为了解决以上技术问题,本发明采用的技术方案是:基于深度学习的地表绿网苫盖提取方法,包括以下步骤:
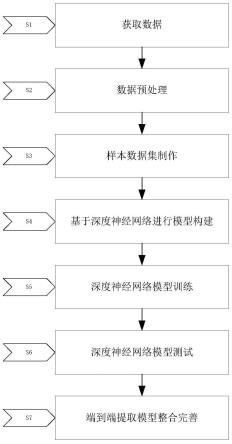
10.步骤s1、获取数据;
11.步骤s2、数据预处理;
12.步骤s3、样本数据集制作;
13.步骤s4、基于深度神经网络进行模型构建;
14.步骤s5、深度神经网络模型训练;
15.步骤s6、深度神经网络模型测试;
16.步骤s7、端到端提取模型整合完善。
17.优选的,步骤s1的过程为:确定要提取的地理区域范围,获取对应区域的某一年或者近几年的高分辨率遥感影像;如果提取的区域需要多幅影像覆盖,则应选择时间接近的影像,并且影像应少云或者无云。
18.优选的,步骤s2中,将收集的遥感影像数据进行预处理,使用envi软件对影像进行校正、镶嵌,必要时对镶嵌影像进行匀色,减少影像色差对提取结果的影响。
19.优选的,步骤s3中,利用经过预处理的数据构建样本数据集,准备好训练数据集、验证数据集和测试数据集,以供之后的模型训练和测试,具体包括以下步骤:
20.s31、将预处理后的遥感影像导入arcgis软件中;
21.s32、创建训练集区域的掩模aoimask;
22.s33、利用aoimask裁剪得到训练图像数据;
23.s34、在原始遥感影像上选定验证集区域,使用s32、s33中的方法和工具剪裁得到验证图像数据boiimage.tif;
24.s35、在原始遥感影像上选定测试集区域,使用s32、s33中的方法和工具剪裁得到测试图像数据coiimage.tif;
25.s36、标注训练集区域的绿网苫盖要素;
26.s37、将矢量标签aoishp转换为栅格标签aoilabel;
27.s38、使用s36、s37中的方法和工具分别对验证集区域和测试集区域进行绿网苫盖的标注,得到栅格标签文件boilabel和coilabel;
28.s39、对训练集影像文件aoiimage和标签文件aoilabel进行裁剪;
29.s310、对裁剪后的训练样本进行“正样本”筛选;
30.s311、对筛选后的训练样本进行数据增强;
31.s312、使用s39中的方法对验证集影像文件boiimage和标签文件boilabel进行裁剪,并整理放入相应的文件夹,得到验证集数据;
32.s313、使用s39中的方法对测试集影像文件coiimage和标签文件coilabel进行裁剪,并整理放入相应的文件夹,得到测试集数据。
33.优选的,步骤s4中,以unet 3+网络为基础构建深度学习网络模型,用于提取绿网苫盖,具体包括以下步骤:
34.s41、搭建tensorflow深度学习环境;
35.s42、搭建模型核心架构:模型核心架构采用unet 3+网络,该网络包括一侧的收缩路径,用于特征提取的编码器结构,另一侧的扩张路径,用于恢复图像尺寸实现像素级预测的解码器结构;
36.s43、在tensorflow中构建模型功能模块,其包括数据读取模块,编码器解码器模块,精度评价模块;
37.其中,数据读取模块接收的是裁剪过后的影像和标签数据并对影像图片进行归一化处理;
38.编码器解码器模块即s42中的unet 3+网络,该网络有5个输出值,将经过4次上采样的输出值作为模型的最终输出,而侧边输出值用于深度监督;
39.精度评价模块将模型提取的绿网苫盖图斑与标签中的绿网苫盖真值进行对比,计算精确度、召回率、总体精度、kappa系数四个指标进行精度评价。
40.优选的,步骤s42中,模型的损失函数l采用focal loss和iou loss的混合损失函数,如下所示:
41.l=lfl+liou
42.其中,lfl表示focal loss,liou表示iou loss;
43.focal loss的计算公式如下所示:
44.l
fl
=-α
t
(1-p
t
)
γ
log(p
t
)
45.设y为地面真值,取值为0或1,p为模型预测的概率,p∈[0,1],那么α
t
与p
t
按下式计算:
[0046][0047][0048]
focal loss公式中α,γ为可调超参数,可设置初始值为α=0.25,γ=2,之后可根据模型训练效果进行调整;
[0049]
iou loss的计算公式如下:
[0050][0051]
其中,pi为第i个像素点的模型预测值,yi为第i个像素点的真值,n为总像素数。
[0052]
优选的,步骤s43中,四个精度指标的计算方法如下:
[0053]
设tp表示类别为正类的像元点预测为正类的像元点的个数,即实际为绿网苫盖像元且提取结果也为绿网苫盖的像元数;
[0054]
tn表示类别为负类的像元点预测为负类的像元点的个数,即实际为非绿网苫盖像元且提取结果也为非绿网苫盖的像元数;
[0055]
fp表示类别为负类的像元点预测为正类像元点的个数,即实际为非绿网苫盖像元而提取结果为绿网苫盖的像元数;
[0056]
fn为类别为正类的像元点预测为负类的像元点的个数,即实际为绿网苫盖像元而提取结果为非绿网苫盖的像元数;
[0057]
精确度也叫查准率,是针对预测结果而言的,表示的是预测为正的样本中有多少是真正的正样本,按如下公式计算:
[0058][0059]
召回率也叫查全率,是针对原来的样本而言的,表示的是样本中的正例有多少被预测正确了,按如下公式计算:
[0060][0061]
总精度是所有的分类正确的样本数占总样本数的比例,按如下公式计算:
[0062][0063]
kappa系数是一个一致性检验的指标,检验模型预测结果和真实情况是否一致,其取值范围是[-1,1],实际应用中,一般是[0,1],这个系数的值越高,则代表模型实现的分类准确度越高,kappa系数的计算公式如下:
[0064][0065]
其中,
[0066][0067]
公式中n代表总样本个数。
[0068]
优选的,步骤s5中,对步骤s4的构建模型进行训练,使模型学习提取特征,具体步骤如下:
[0069]
s51、获取训练数据的图像和标签路径,获取验证数据的图像和标签路径,将相应路径填入模型的数据读取模块;
[0070]
s52、设定超参数的初始值;
[0071]
s53、模型读取训练数据,使用梯度下降方法更新模型参数进行模型训练,并在训练过程中对验证集数据测试模型的提取效果,达到指定epoch时结束训练,记录下训练集和验证集上的loss曲线,并计算相应的评价指标;
[0072]
s54、对模型超参数进行优化,首先根据上一步训练的loss曲线和精度指标确定超
参数的候选值,采用网格搜索法逐一测试不同超参数候选值对模型效果的影响,选取使模型提取效果达到最优的超参数,以达到模型优化的目的;
[0073]
s55、将训练好的模型保存到指定路径。
[0074]
优选的,步骤s6中,利用测试集数据进行模型测试,具体步骤如下:
[0075]
s61、读取步骤s313中处理好的测试集数据,输入步骤s55中训练好的模型,进行模型预测;
[0076]
s62、查看模型在测试集上运行的精度指标是否落在与验证集上的精度指标相近的区间;
[0077]
s63、将测试集数据多次输入模型运行,记录每次模型提取的精度指标,以测试模型的稳定性。
[0078]
优选的,步骤s7中,将经过测试的模型进行整合完善,具体过程如下:
[0079]
s71、整合模型功能模块,按流程确定以下功能模块,包括数据读取模块、影像裁剪模块、归一化处理模块、网络预测模块、影像拼接模块、结果可视化模块;
[0080]
s72、整合完善数据读取模块,使用gdal读取tiff格式的遥感影像,记录下影像行列数、栅格数据值、波段数、仿射矩阵、投影信息;
[0081]
s73、完善影像裁剪模块,采用网格移动方法裁剪输入的大尺寸图像,可设置裁剪尺寸和重叠率参数;
[0082]
s74、完善归一化处理模块,对裁剪后的图像进行归一化处理;
[0083]
s75、整合网络预测模块,将步骤s74处理后的图像输入经过步骤s5、s6训练和测试后的网络模型中,得出预测提取图像;
[0084]
s76、完善影像拼接模块,将上一步模型预测出的小尺寸图像进行拼接,还原为与原始图像尺寸相对应的提取结果;
[0085]
s77、完善结果可视化模块,使用matplotlib库将上一步得到的结果绘制出来,显示结果是一幅二值图像,白色为提取出的绿网苫盖要素,黑色为背景。
[0086]
本发明提供了一种从高分辨率遥感影像中提取地表绿网苫盖要素的方法,弥补了此处技术方法的空缺,可以提高绿网苫盖提取的精度,直观反映绿网苫盖在城市中的分布。本方法具有可推广性,按照本方法各地可建立本地的样本数据集进行网络训练,构建适合本地区域的模型进行绿网苫盖的提取,可实现城市绿网苫盖的自动化提取,极大减轻人工负担,可为当地生态环境建设、规划建设和精细管理提供数据和技术支持,为城市规划、管理和决策提供参考。
附图说明
[0087]
图1为本发明的整体流程框架图。
[0088]
图2为本发明unet 3+网络结构示意图。
具体实施方式
[0089]
下面结合附图和具体实施方式对本发明作进一步详细的说明。
[0090]
如图1所示的基于深度学习的地表绿网苫盖提取方法,主要利用深度神经网络构建模型从高分辨率遥感影像中提取绿网苫盖图斑,来获取绿网苫盖在城市中的分布和数
量,提高绿网苫盖提取的精度,提升城市管理的自动化、智能化水平,可为城市规划、生态环境建设和城市精细管理提供支持,对城市扩张模式的研究与城市建设管理提供辅助,具体包括以下步骤:
[0091]
步骤s1、获取数据:确定要提取的地理区域范围,获取对应区域的某一年或者近几年的高分辨率遥感影像,例如北京地区的可采用北京二号卫星的0.8米分辨率的遥感影像。如果提取的区域需要多幅影像覆盖,则应选择时间接近的影像,并且影像应少云或者无云。此外可根据实际需要搜集相关辅助数据,如行政边界矢量数据、外业实地调绘数据等。
[0092]
步骤s2、数据预处理:将收集的遥感影像数据进行预处理,使用envi(the environment for visualizing images是一个完整的遥感图像处理平台)软件对影像进行校正、镶嵌,必要时对镶嵌影像进行匀色,减少影像色差对提取结果的影响。
[0093]
步骤s3、样本数据集制作:利用经过预处理的数据构建样本数据集,准备好训练数据集、验证数据集和测试数据集,以供之后的模型训练和测试,具体包括以下步骤:
[0094]
s31、将预处理后的遥感影像导入arcgis(arcgis产品线为用户提供一个可伸缩的,全面的gis平台)软件中;
[0095]
s32、创建训练集区域的掩模aoimask。选取训练集区域,创建一个训练集区域的掩模aoimask.shp,这个矢量用于裁剪训练集区域。元素类型为面要素,空间参考要和遥感影像保持一致;
[0096]
s33、利用aoimask裁剪得到训练图像数据。利用arcgis工具箱里的【spatial analyst tools】-》【extraction】-》【extract by mask】工具裁剪原遥感影像得到训练图像数据aoiimage.tif;
[0097]
s34、在原始遥感影像上选定验证集区域,使用s32、s33中的方法和工具剪裁得到验证图像数据boiimage.tif;
[0098]
s35、在原始遥感影像上选定测试集区域,使用s32、s33中的方法和工具剪裁得到测试图像数据coiimage.tif;
[0099]
s36、标注训练集区域的绿网苫盖要素。首先在arccatalog(地理数据的资源管理器)中创建训练集区域的矢量标签文件aoishp.shp,元素类型为面要素,添加一个名为id的属性字段,字段类型为短整型,空间参考要和遥感影像保持一致,然后编辑该文件,用polygon(绘制多边形函数)逐个标注勾画需要提取的绿网苫盖地物,并将属性赋值为1,保存编辑结果;
[0100]
s37、将矢量标签aoishp转换为栅格标签aoilabel。利用arcgis工具箱里的【conversion tools】-》【to raster】-》【feature to raster】工具将得到的矢量标签aoishp.shp转成栅格标签aoilabel.tif。字段field选择id,输出像元大小选择aoiimage.tif,另外需要在环境设置里的处理范围设置为与aoiimage.tif一致。该栅格标签中目标地物(绿网苫盖)的值为1,其他部分(视为背景)的值为0;
[0101]
s38、使用s36、s37中的方法和工具分别对验证集区域和测试集区域进行绿网苫盖的标注,得到栅格标签文件boilabel和coilabel;
[0102]
s39、对训练集影像文件aoiimage和标签文件aoilabel进行裁剪。分别使用滑动窗口方法进行裁剪,两者采用相同的裁剪参数,保持相同的滑动窗口大小和窗口重叠度,得到一系列尺寸相同的小栅格图片,分别放入影像和标签两个文件夹。裁剪后的影像文件和对
应的标签文件采用相同的命名,并分别放入相应的文件夹,作为初步的训练样本;
[0103]
s310、对裁剪后的训练样本进行“正样本”筛选,所谓正样本指的是包含目标地物的图片,不含目标地物的图片称为负样本。具体方法是将训练集标签文件夹中值不全为0的标签图片(正样本)挑选出来,同时根据文件名把相对应的影像图片挑选出来,得到筛选后的训练样本;
[0104]
s311、对筛选后的训练样本进行数据增强。数据增强方式包括平移、旋转、裁剪、翻转、缩放等,对影像图片和标签图片采用同样的数据增强操作,产生的新影像图片和相应的标签图片采用相同的名字命名并分别放入相应的文件夹,得到数据增强后的训练样本;
[0105]
s312、使用s39中的方法对验证集影像文件boiimage和标签文件boilabel进行裁剪,并整理放入相应的文件夹,得到验证集数据;
[0106]
s313、使用s39中的方法对测试集影像文件coiimage和标签文件coilabel进行裁剪,并整理放入相应的文件夹,得到测试集数据。
[0107]
最终的训练集、验证集、测试集数据组织形式如下所示:
[0108]
——训练集
[0109]
——影像
[0110]
——标签
[0111]
——验证集
[0112]
——影像
[0113]
——标签
[0114]
——测试集
[0115]
——影像
[0116]
——标签
[0117]
步骤s4、基于深度神经网络进行模型构建:以unet 3+网络为基础构建深度学习网络模型,用于提取绿网苫盖,具体包括以下步骤:
[0118]
s41、搭建tensorflow深度学习环境。
[0119]
tensorflow是一个端到端的开源机器学习平台,tensorflow的安装分为cpu(中央处理器)版本和gpu(图形处理器)版本,cpu版本适用性较广,但是运算速度较慢,gpu版本运行速度更快,但是要求机器的显卡必须是nvidia的显卡,因为只有nvidia显卡才能开启cuda(compute unified device architecture,是显卡厂商nvidia推出的运算平台)加速。tensorflow-gpu深度学习环境的搭建需要以下几步:
[0120]
①
根据tensorflow官网的相容性列表(https://tensorflow.google.cn/install/source_windows?hl=en#gpu)确定相对应的tensorflow、python(计算机编程语言)、cuda、cudnn(深度神经网络库(cudnn)是gpu加速的用于深度神经网络的原语库)相容版本,如表1所示;
[0121]
表1 tensorflow版本兼容表
[0122][0123][0124]
②
安装anaconda(开源的python发行版本);
[0125]
③
从nvidia官网(https://developer.nvidia.com/cuda-downloads)下载cuda并安装;
[0126]
④
从官网下载cudnn,cudnn下载完成之后是一个压缩文件,需解压缩然后将解压后的文件复制到cuda安装路径下的cudnn文件夹,完成cudnn的安装;
[0127]
⑤
安装选定版本的tensorflow-gpu。
[0128]
s42、搭建模型核心架构。
[0129]
模型核心架构采用unet 3+网络,如图2所示。该网络左侧是收缩路径(编码器结
构),用于特征提取,右侧是扩张路径(解码器结构),用于恢复图像尺寸实现像素级预测。在收缩路径中,网络重复使用3
×
3卷积和最大池化运算来进行下采样。在扩展路径中,采用全尺度跳跃链接进行上采样,unet 3+中的每一个解码器层都融合了来自编码器中的大尺寸、同尺寸的特征图以及来自解码器的小尺寸的特征图,这些特征图捕获了全尺度下的细粒度语义和粗粒度语义。unet 3+还采用了全尺度深度监督,对每个解码器阶段的侧边输出利用地面真实值进行监督。
[0130]
模型的损失函数l采用focal loss和iou loss的混合损失函数,如下所示:
[0131]
l=lfl+liou
[0132]
其中,lfl表示focal loss,liou表示iou loss;
[0133]
focal loss的计算公式如下所示:
[0134]
l
fl
=-α
t
(1-p
t
)
γ
log(p
t
)
[0135]
设y为地面真值,取值为0或1,p为模型预测的概率,p∈[0,1],那么α
t
与p
t
按下式计算:
[0136][0137][0138]
focal loss公式中α,γ为可调超参数,可设置初始值为α=0.25,γ=2,之后可根据模型训练效果进行调整;
[0139]
iou loss的计算公式如下:
[0140][0141]
其中,pi为第i个像素点的模型预测值,yi为第i个像素点的真值,n为总像素数。
[0142]
s43、在tensorflow中构建模型功能模块,其包括数据读取模块,编码器解码器模块,精度评价模块。
[0143]
数据读取模块接收的是裁剪过后的影像和标签数据并对影像图片进行归一化处理;
[0144]
编码器解码器模块即s42中的unet 3+网络,该网络有5个输出值,将经过4次上采样的输出值作为模型的最终输出,而侧边输出值用于深度监督;
[0145]
精度评价模块将模型提取的绿网苫盖图斑与标签中的绿网苫盖真值进行对比,计算精确度、召回率、总体精度、kappa系数四个指标进行精度评价。
[0146]
下面对这四个精度指标的计算方法进行说明。
[0147]
设tp(true positive)表示类别为正类的像元点预测为正类的像元点的个数,即实际为绿网苫盖像元且提取结果也为绿网苫盖的像元数;
[0148]
tn(true negative)表示类别为负类的像元点预测为负类的像元点的个数,即实际为非绿网苫盖像元且提取结果也为非绿网苫盖的像元数;
[0149]
fp(false positive)表示类别为负类的像元点预测为正类像元点的个数,即实际为非绿网苫盖像元而提取结果为绿网苫盖的像元数;
[0150]
fn(false negative)为类别为正类的像元点预测为负类的像元点的个数,即实际为绿网苫盖像元而提取结果为非绿网苫盖的像元数,如下表所示。
[0151]
类别提取为绿网苫盖提取为非绿网苫盖实际为绿网苫盖tpfn实际非绿网苫盖fptn
[0152]
精确度(precision)也叫查准率,是针对预测结果而言的,表示的是预测为正的样本中有多少是真正的正样本,按如下公式计算:
[0153][0154]
召回率(recall)也叫查全率,是针对原来的样本而言的,表示的是样本中的正例有多少被预测正确了,按如下公式计算:
[0155][0156]
总精度(overall accuracy)是所有的分类正确的样本数(正类预测为正类、反类预测为反类)占总样本数的比例,按如下公式计算:
[0157][0158]
kappa系数一个一致性检验的指标,检验模型预测结果和真实情况是否一致。这个系数的取值范围是[-1,1],实际应用中,一般是[0,1],这个系数的值越高,则代表模型实现的分类准确度越高。kappa系数的计算公式如下:
[0159][0160]
其中,
[0161][0162]
公式中n代表总样本个数。
[0163]
步骤s5、深度神经网络模型训练:对构建模型进行训练,使模型学习提取特征,具体的方法如下:
[0164]
s51、获取训练数据的图像和标签路径,获取验证数据的图像和标签路径,将相应路径填入模型的数据读取模块;
[0165]
s52、设定超参数的初始值,例如batch size设为2,epoch设置为100,初始学习率learning rate设为e-4
;(batch size为每批数据量的大小;一个epoch表示:所有的数据送入网络中,完成了一次前向计算+反向传播的过程)。
[0166]
s53、模型读取训练数据,使用梯度下降方法更新模型参数进行模型训练,并在训练过程中对验证集数据测试模型的提取效果,达到指定epoch时结束训练,记录下训练集和验证集上的loss曲线,并计算相应的精确度、召回率等评价指标;
[0167]
s54、对模型超参数进行优化,首先根据上一步训练的loss曲线和精度指标确定batch size,epoch、调整参数初始化方法(如xavier初始化和he初始化)、梯度下降方法(如
adam、rmsprop等)等超参数的候选值,采用网格搜索法逐一测试不同超参数候选值对模型效果的影响,选取使模型提取效果达到最优的超参数,以达到模型优化的目的;
[0168]
s55、将训练好的模型保存到指定路径。
[0169]
步骤s6、深度神经网络模型测试:利用测试集数据进行模型测试,具体步骤如下:
[0170]
s61、读取步骤s313中处理好的测试集数据,输入步骤s55中训练好的模型,进行模型预测;
[0171]
s62、查看模型在测试集上运行的精度指标是否落在与验证集上的精度指标相近的区间;
[0172]
s63、将测试集数据多次输入模型运行,记录每次模型提取的精度指标,以测试模型的稳定性。
[0173]
步骤s7、端到端提取模型整合完善。
[0174]
将经过测试的模型进行整合完善。上述步骤中模型的输入是裁剪过后的小尺寸图像和标签,输出的也是与输入图像相对应的绿网苫盖提取结果,该提取结果以小尺寸的栅格图片形式呈现,呈现方式较为细碎不利于提取内容的直观展现,如果得到相对完整的大尺寸提取结果,需要对模型进行整合完善,以达到端对端的效果,即输入大尺寸的遥感影像,经过模型得到的是相对应的大尺寸的绿网苫盖提取图像,具体步骤如下:
[0175]
s71、整合模型功能模块,按流程确定以下功能模块,包括数据读取模块、影像裁剪模块、归一化处理模块、网络预测模块、影像拼接模块、结果可视化模块。
[0176]
s72、整合完善数据读取模块,使用gdal(开源栅格空间数据转换库)读取tiff(tag image file format,标签图像文件格式)格式的遥感影像,记录下影像行列数、栅格数据值、波段数、仿射矩阵、投影等信息;
[0177]
s73、完善影像裁剪模块,采用网格移动方法裁剪输入的大尺寸图像,可设置裁剪尺寸和重叠率参数;
[0178]
s74、完善归一化处理模块,对裁剪后的图像进行归一化处理;
[0179]
s75、整合网络预测模块,将s74处理后的图像输入经过步骤s5、s6训练和测试后的网络模型中,得出预测提取图像;
[0180]
s76、完善影像拼接模块,将上一步模型预测出的小尺寸图像进行拼接,还原为与原始图像尺寸相对应的提取结果;
[0181]
s77、完善结果可视化模块,使用matplotlib库(matplotlib是一个python的2d绘图库)将上一步得到的结果绘制出来,显示结果是一幅二值图像,白色为提取出的绿网苫盖要素,黑色为背景。
[0182]
利用本发明方法对地表绿网苫盖进行动态监测与管理,可为城市规划、生态环境建设和城市精细管理提供数据和技术支持,对城市扩张模式的研究与城市建设管理具有重要意义。
[0183]
上述实施方式并非是对本发明的限制,本发明也并不仅限于上述举例,本技术领域的技术人员在本发明的技术方案范围内所做出的变化、改型、添加或替换,也均属于本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1