基于Deeplabv3+网络的非结构化道路自适应注意力语义分割方法
基于deeplabv3+网络的非结构化道路自适应注意力语义分割方法
技术领域
1.本发明涉及机器视觉图像分割技术领域,特别涉及基于deeplabv3+网络的非 结构化道路自适应注意力语义分割方法。
背景技术:
2.无人驾驶车辆通过各种传感器对周围环境进行感知,根据道路信息作出相应 的决策规划。环境感知是无人驾驶研究的关键技术之一,主要通过视觉传感器获 取车辆周围局部环境的道路细节信息,采用语义分割、模式识别等技术,为智能 车辆局部自主决策及路径规划提供必要的可行驶区域信息,尤其是针对高速公 路、城市干道等结构化场景中,其道路分割已经取得了出色的表现能力以及初步 的商业化实际应用。
3.然而,我国建设环境多为非结构化道路,其环境具有复杂多变、结构多变等 特点,现有的结构化道路分割方法难以直接应用。为了进一步提高我国陆地智能 车辆的机动能力和整体作战能力,亟需对非结构化可行驶区域道路分割作进一步 深入研究。
4.基于深度学习的语义分割是当今计算机视觉领域研究的关键问题之一,其通 过对图片进行逐像素分类来实现若干个具有某种语义信息属性的像素级划分区 域,基于深度学习的语义分割网络模型有:fcn、segnet、u-net以及deeplab 系列等。fcn将传统卷积网络后面的全连接层替换为卷积层,实现了任意尺寸输 入,并使用了反卷积操作恢复空间分辨率。segnet及u-net采用编码-解码模块 结构,编码模块提取语义特征图片,解码模块恢复至原始分辨率。deeplab系列 网络模型是当前应用最广泛的语义分割算法之一,其中deeplabv3+网络较为成 熟,该网络采用aspp模块通过不同空洞尺寸的空洞卷积捕获多尺度上下文信息, 保证丰富感受野的同时维持了分辨率,但是在复杂多变的非结构化道路场景理解 中,其很难有效细化不同区域同类目标全局语义信息,导致语义分割不够精准、 网络模型泛化性弱、鲁棒性差。因此,如何解决这些问题对于非结构化可行驶区 域道路分割具有重要的研究意义和实际应用价值。
技术实现要素:
5.本发明的目的是提供一种非结构化道路可行驶区域复杂场景的基于 deeplabv3+网络的非结构化道路自适应注意力语义分割方法。
6.为此,本发明技术方案如下:
7.基于deeplabv3+网络的非结构化道路自适应注意力语义分割方法,步骤如 下:
8.s1、创建非结构化道路场景样本数据集,包括非结构化道路图片集和对应包 含有语义标注的图片集;
9.s2、基于deeplabv3+网络,在resnet-18网络的各block模块之后增加cbam 模块,构建形成基于deeplabv3+网络的非结构化道路自适应注意力语义分割算法 模型;
10.s3、利用步骤s1创建的非结构化道路场景样本数据集对非结构化道路自适 应注
意力语义分割算法模型进行迭代训练;其中,
11.(1)设置参数学习率lr=0.001,权重衰减weight_decay=0.0001;
12.(2)设置损失函数为交叉熵损失函数crossentropyloss,其公式为 式中,rn为采集第n帧图片 对应的语义标注png格式属性图片,为对应于rn预测后的图片。
13.进一步地,步骤s1的具体实施步骤为:
14.s101、获取由n帧非结构化道路图片构成的非结构化道路图片集m: m={m1,m2,m3,m4,m5,...,mn};
15.s102、利用语义标注工具labelimg对步骤s101中各图片中不同类别进行语 义标注,得到包含有语义标注的json图片集q:q={q1,q2,q3,q4,q5,...,qn};其 中,n为采集样本训练数据集的规模,mn为采集第n帧的图片,qn为包含有语 义标注的第n帧json图片;
16.2)将包含有语义标注的json图片集q中的图片统一转换为png图片,得 到png图片集r:r={r1,r2,r3,r4,r5,...,rn},其中,rn为png图片集中的第n 帧图片。
17.进一步地,对非结构化道路图片集m和png图片集r中的各图片进行相同 尺寸和分辨率的裁切处理。
18.进一步地,在步骤s3中,基于由非结构化道路图片集m为原始图片,对应 png图片集r为标签图片构成n个图片组,将其按7:1:2的比例随机划分训练集、 验证集和测试集,并分别用于模型的训练、验证和测试中。
19.与现有技术相比,该基于deeplabv3+网络的非结构化道路自适应注意力语义 分割方法通过在deeplabv3+网络的骨干特征提取网络中引入自适应注意力 cbam,有效解决了复杂环境场景下非结构化道路可行驶区域语义分割精度不足 的问题,并通过增强卷积空间和通道维度特征自适应表达能力,实现有效细化不 同类别上下文信息,尤其在物体边缘处可以实现细粒度推理,提升复杂环境下非 结构化道路可行驶区域语义分割的鲁棒性以及算法网络模型的泛化性,满足智能 车辆对非结构化道路可行驶区域复杂场景的理解力要求。
附图说明
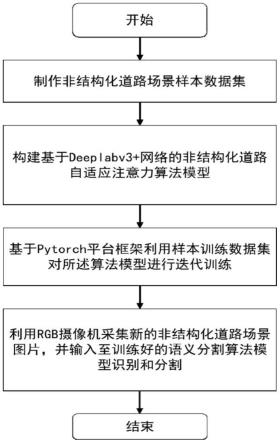
20.图1为本发明的基于deeplabv3+网络的非结构化道路自适应注意力语义分割 方法的流程图;
21.图2为本发明的基于deeplabv3+网络的非结构化道路自适应注意力语义分割 方法模型;
22.图3为采用本发明的基于deeplabv3+网络的非结构化道路自适应注意力语义 分割方法测试的图片、采用deeplabv3+网络测试的图片以及原始图片的对比图。
具体实施方式
23.下面结合附图及具体实施例对本发明做进一步的说明,但下述实施例绝非对 本发明有任何限制。
24.如图1所示,该基于deeplabv3+网络的非结构化道路自适应注意力语义分割 方法
的具体实施方式如下:
25.s1、创建非结构化道路场景样本数据集,包括非结构化道路图片集和对应包 含有语义标注的图片集;
26.该步骤s1的具体实施步骤如下:
27.s101、获取非结构化道路场景样本数据集:
28.从车辆原始行车记录仪视频中提取n帧非结构化道路图片构成的非结构化 道路图片集m:m={m1,m2,m3,m4,m5,...,mn};在本实施例中,n=5600;
29.s102、对原始图片集进行处理得到包含有语义标注的图片集:
30.1)利用语义标注工具labelimg对步骤s101得到的图片集m每张图片中道 路、石头、人、车辆、水坑、土坑和树枝进行语义标注,得到包含有语义标注的 json图片集q:q={q1,q2,q3,q4,q5,...,qn};其中,n为采集样本训练数据集的规 模,mn为采集第n帧的图片,qn为包含有语义标注的第n帧json图片;
31.2)将包含有语义标注的json图片集q中的图片统一转换为png图片,得 到png图片集r:r={r1,r2,r3,r4,r5,...,rn},其中,rn为png图片集中的第n 帧图片;
32.s103、语义分割:
33.将非结构化道路图片集m和png图片集r中的各图片一致处理为分辨率为 960*1920的图片。
34.s2、基于deeplabv3+网络,在resnet-18网络的各block模块之后增加cbam 模块,构建形成基于deeplabv3+网络的非结构化道路自适应注意力语义分割算法 模型;
35.如图2所示,deeplabv3+网络包括骨干特征提取网络、aspp模块和特征解 码模块;其中,骨干特征提取网络具体为resnet-18网络,本技术的改进在于, 在resnet-18网络的各block模块之后增加cbam模块,形成新的 resnet-18_cbam网络;具体地,在block1模块与block2模块之间增加cbam 模块,使block1模块的输出值经过cbam模块处理后再输入至block2模块中; 在block2模块与block3模块之间增加cbam模块,使block2模块的输出值经过 cbam模块处理后再输入至block3模块中;在block3模块与block4模块之间增 加cbam模块,使block3模块的输出值经过cbam模块处理后再输入至block4 模块中;在block4模块后增加cbam模块,使block4模块的输出值经过cbam 模块处理后输入至aspp模块中的各conv卷积中以及特征解码模块的conv 卷积中;
36.采用该基于deeplabv3+网络的非结构化道路自适应注意力语义分割算法模 型的图片数据处理过程具体如下:
37.a、骨干特征提取网络的处理过程:
38.1)对非结构化道路图片集m中的各图片mn(h,w)∈m
(h,w)
输入卷积conv
_7*7
生成 低层特征图即:
[0039][0040][0041]
其中,(h,w)为输入图片的高为h,宽为w;mn为第n帧采集图片;n
in
为 输入图片的尺
寸;k为卷积核的大小;p为填充;s为步长;conv
_r*r
为r*r的卷积 运算,即对应元素相乘求和,r=7;为输出特征 图大小,即输出特征图的高为输出特征图的宽为
[0042]
对进行批量归一化bn处理,以提高所述算法模型loss收敛速度; 而后,对bn处理后的特征图进行激活函数relu处理,以增强所述算 法网络模型非线性拟合能力,输出结果为特征图f0;
[0043]
2)对步骤1)的特征图f0利用式(1)连续进行2次conv
_3*3
运算及激活函数 relu处理,得到新特征图;进而对该新特征图利用式(1)连续进行2次进行conv
_3*3
运算及激活函数relu处理,得到特征图f1,即为block1的输出结果;
[0044]
3)将步骤2)的特征图f1输入至cbam模块中,得到特征图f2;
[0045]
4)对步骤3)的特征图f2利用式(1)进行downsample下采样操作及激活 函数relu处理,得到新特征图;进而对该新特征图利用式(1)进行conv
_3*3
运算 及激活函数relu处理,得到特征图f3,即为block2的输出结果;;
[0046]
5)将步骤4)的特征图f3输入至cbam模块中,得到特征图f4;
[0047]
6)对步骤5)的特征图f4利用式(1)进行downsample下采样操作及激活 函数relu处理,得到新特征图;进而对该新特征图利用式(1)进行conv
_3*3
运算 及激活函数relu处理,得到特征图f5,即为block3的输出结果;;
[0048]
7)将步骤6)的特征图f5输入至cbam模块中,得到特征图f6;
[0049]
8)对步骤7)特征图f6利用式(1)进行downsample下采样操作以及激活 函数relu处理,得到新特征图;进而对该新特征图利用式(1)进行conv
_3*3
运算 以及激活函数relu处理,得到特征图f7,即为block4的输出结果;;
[0050]
9)将步骤8)的特征图f7输入至cbam模块中,得到特征图f8;至此,骨 干特征提取网络中的图片语义信息特征提取完成;
[0051]
其中,在各cbam模块中对输入特征图的处理过程为:
[0052]
①
将初始特征图输入channel attention module中,以增大有效通道权重表 达,抑制无效通道权重表达;
[0053]
其中,channel attention module的计算公式为:
[0054][0055]
②
将经过上述步骤
①
输出的特征图与步骤
①
中的初始特征图进行特征求和 融合操作,得到新的特征图;
[0056]
③
将经过步骤
②
得到的新特征图输入spatial attention module中,以加强图 片像素点之间的相关性,保持全局空间一致性;
[0057]
其中,spatial attention module计算公式为:
[0058][0059]
式中,f为输入特征图,为经过global average pooling计算后的特征图,为经过global max pooling计算后的特征图,w0和w1为多层感知机模型中的 两层参数,δ为sigmoid激活函数;
[0060]
在该过程中,通过赋予channel及spatial新的权重来实现图片中重要特征信 息的识别,丰富所述算法网络模型全局语义信息,满足自适应注意力对复杂环境 场景下非结构化道路可行驶区域理解的表达能力。
[0061]
b、aspp模块的处理过程:
[0062]
1)对过程a中的步骤1)输出的特征图f8输入至aspp中,以捕获不同尺 度的感受野信息及不同尺度的特征信息;其中,aspp公式如下:
[0063][0064]
式中,i代表输入空洞卷积的大小,s代表步长,k代表原来卷积核的大小, d为填充空格数,o代表空洞卷积后特征图的大小;
[0065]
2)对过程b中的步骤1)中不同尺度空洞卷积feature进行通道叠加,并通 过输出层conv-》bn-》relu-》dropout降维至给定通道数,获取最终high_levelfeatures。
[0066]
c、特征解码模块的处理过程:
[0067]
1)对过程a中的步骤1)输出的特征图f8进行1*1conv操作获得low_level features;
[0068]
2)对过程b中的步骤2)输出的high_level features通过双线性插值法进 行4倍上采样;
[0069]
3)对过程c中的步骤1)输出的low_level features与过程c中的步骤2) 中经过双线性插值4倍上采样后的high_level features进行concat特征拼接;
[0070]
4)对过程c中的步骤3)中经过特征拼接后的特征图进行3*3conv操作, 并对其进行双线性插值4倍上采样,从而获得预测特征图predict。
[0071]
s3、利用步骤s1创建的非结构化道路场景样本数据集对非结构化道路自适 应注意力语义分割算法模型进行迭代训练。
[0072]
该步骤s3的具体实施步骤为:
[0073]
s301、对步骤s1创建的非结构化道路场景样本数据集,基于由非结构化道 路图片集m为原始图片,对应png图片集r为标签图片构成n个图片组,将其 按7:1:2的比例随机划分训练集、验证集和测试集;
[0074]
s302、设置对迭代训练过程中的必要参数:
[0075]
(1)设置参数学习率lr=0.001,权重衰减weight_decay=0.0001;
[0076]
(2)设置损失函数为交叉熵损失函数crossentropyloss,其公式为:
[0077][0078]
式中,rn为采集第n帧图片对应的语义标注png格式属性图片,为对 应于rn预测
后的图片。
[0079]
s303、将步骤s301划分出的训练集代入步骤s2创建的模型中进行训练,并 利用验证集验证经过训练的模型,其次利用该算法网络对测试集进行测试。
[0080]
为了评价算法模型语义分割的精度,分别采用mpa和miou作为评价指标, 对本技术的非结构化道路语义分割模型算法进行评价,相应地,作为对比模型, 将deeplabv3+网络作为步骤s2中构建的模型进行相同方式处理,并对二者的处 理结果进行比较;其中,
[0081]
mpa评价指标的计算公式为:
[0082][0083]
miou评价指标的计算公式为:
[0084][0085]
式中,pij为真实值为i,j为被预测的数量,k+1是类别个数(包含背景类), pii是真正的数量,pij、pji则分别为假正和假负。
[0086]
采用rgb摄像机采集多张不同场景的非结构化道路图片,并利用本实施例 训练好的模型以及训练好的对比模型对上述多张图片进行处理。如图3所示为基 于同一张原始非结构化道路图片经过本技术模型和对比模型处理后对比图。从图 3中可以明显看出:在图片2和图片4中,对比模型在b、d两处很明显具有若 干语义噪声,而本技术模型取得良好的测试效果,其次,在图片1、图片3以及 图片5中,本技术模型较对比模型在a、c、e三处可以实现良好的边缘细粒度 化推理,解决非结构化道路场景下边缘特征语义分割效果差的问题;可见,本申 请的方法针对非结构化道路边缘以及图片噪声干扰方面取得一定的提升效果。
[0087]
另外,基于mpa和miou这两个评价指标,较现有技术deeplabv3+网络处 理方法的miou为72%,本技术处理方法的miou提升了3%,达到75%;较现有 技术deeplabv3+网络处理方法的mpa为82%,本技术处理方法的mpa提升了 3%,达到85%。
[0088]
本技术模型适用于图3中水泥材质道路、土质道路、山地道路以及碎石道路 等多种复杂非结构化道路场景,具有出色的场景适用泛化性,同时,提升了非结 构化道路语义分割精度,具有良好的鲁棒性。图3中所示复杂非结构化道路场景 绝非对发明有任何场景限制。
[0089]
综上所述,本技术的非结构化道路语义分割模型算法有效提高了非结构化道 路场景语义分割的准确性,鲁棒性以及算法网络模型的泛化性。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1