一种基于GAMHR-Net的多人姿态估计方法及系统
一种基于gamhr-net的多人姿态估计方法及系统
技术领域
1.本发明属于计算机视觉技术领域,具体涉及一种基于gamhr-net的多人姿态估计方法及系统。
背景技术:
2.人体姿态估计在很多方面都有着广泛的应用前景:虚拟现实、智能人机交互、智能监控、运动员辅助训练、病人监护等。人体姿态估计作为计算机视觉领域中一个极具挑战性的课题,是近年来计算机视觉领域中研究的一个热点。人体姿态估计所要解决的问题是判断给定图像中的人体在做什么或者说人的具体姿态是什么,它是图像理解、目标跟踪、人机交互、智能监控等研究领域的一个基础问题,在许多领域内都有着非常实际的应用意义,由此人体姿态估计是当前计算机视觉研究领域中一个备受关注的研究方向,并成为近几年科研领域中的研究热点。目前研究人体姿态估计的方法主要有传统的基于手工提取特征的方法和基于深度学习的方法。
3.基于手工提取特征的方法实际上就是对特定的视频图像采用传统的机器学习算法先提取其中的目标局部或者全局特征,然后对提取的特征采取编码以及规范化的形式,最后通过训练构建好的模型来得到预测结果。虽然基于手工提取特征的方法相对较为成功,但是该类方法是针对固定视频设计提取特征,无法满足输入视频的通用性,并且计算速度非常慢,很难满足现实世界中实时性的要求。
4.基于深度学习的人体姿态估计方法主要是先通过设计好的神经网络对输入视频进行自动特征提取并不断训练模型,之后将训练好的模型用于识别。目前基于深度学习的人体姿态估计算法主要通过三维卷积神经网络、双流网络、循环卷积神经网络和注意力网络进行构建。
5.相较于手工设计数据的特征,深度学习方法快捷、方便,并且时效性好,并且可以自动学习特征并由此对数据进行回归。随着深度卷积神经网络的应用和mscoco等大规模数据集的发布,人体姿态估计方法已经取得了较大的发展,它们大致可以分为自底向上(bottom-up)和自顶向下(top-down)的方法。自底向上的方法相较于自顶向下的方法来说,在精度上仍然有一定的差距,因此目前的研究热点仍然集中在自顶向下的方法上。
6.目前自顶向下的方法在精度方面也不算太高,一般来说还达不到图像分类任务或者目标检测任务的精度;同时由于训练样本太少或者数据集较为单一,很多模型只是在特殊的场景下才表现出较好的效果,鲁棒性比较差;另一方面由于人体姿态估计这个任务本身就是一个像素级的密集预测任务,因此要求在通过神经网络提取特征时需要保持高分辨率的空间维度。
技术实现要素:
7.发明目的:针对目前人体姿态估计鲁棒性差,过程复杂,准确率低的问题,本发明提出一种基于gamhr-net的多人姿态估计方法及系统,始终保持高分辨率的空间维度,可以
实现对多人的姿态估计和姿态跟踪,具有较高的准确率和召回率,同时使模型具有较强的鲁棒性。
8.技术方案:本发明提出一种基于gamhr-net的多人姿态估计方法,包括以下步骤:
9.(1)采用目标检测网络对输入图像或视频进行检测,获取人体位置信息;
10.(2)构建gamhr-net网络;所述gamhr-net网络包括一个stem-net模块、四个stage模块、四个transition模块以及三个gam block模块;所述stem-net模块包括主干网络和res-multiconv结构;
11.(3)将人体位置信息与对应的图像送入gamhr-net网络进行特征提取和特征融合;首先经stem-net模块初步提取底层特征;然后经stage模块和gam block模块进一步进行特征提取,并经transition模块进行特征融合;
12.(4)经过步骤(3)之后得到人体关节点并将关节点在原图像或原视频上展示出来。
13.进一步地,步骤(2)所述主干网络为一个步长为2,padding为1,输入通道为3,输出通道为64的3
×
3的卷积层,之后再经过batchnormalization层和relu激活层;然后,再接一个步长为2,padding为1,输入通道为64,输出通道为64的3
×
3的卷积层,之后再经过batch normalization层和relu激活层。
14.进一步地,所述步骤(3)所述stem-net模块初步提取底层特征实现过程如下:
15.res-multiconv结构将stem-net的主干网络分为两条支路;第一条支路首先经过一个步长为1,卷积核大小为1
×
1的depthwise卷积,再经过卷积核大小为1
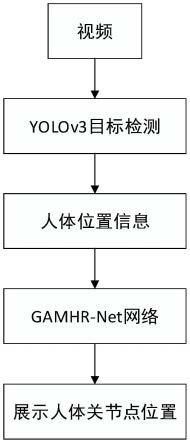
×
1的pointwise卷积,再进行batch normalization操作之后得到r11;接着,以r11作为输入,经过一个步长为1,卷积核大小为1
×
1的depthwise卷积,再经过卷积核大小为1
×
1的pointwise卷积,再进行batchnormalization和relu操作之后得到r12;然后,以r12作为输入,经过一个步长为1,卷积核大小为1
×
1的depthwise卷积,再经过卷积核大小为1
×
1的pointwise卷积,再进行batchnormalization操作之后得到r13;最后,将r11和r13进行矩阵和操作,再进行relu激活之后得到r1;
16.第二条支路首先经过一个步长为1,卷积核大小为3
×
3的depthwise卷积,再经过卷积核大小为1
×
1的pointwise卷积,再进行batchnormalization操作之后得到r21;接着,以r21作为输入,经过一个步长为1,卷积核大小为1
×
1的depthwise卷积,再经过卷积核大小为1
×
1的pointwise卷积,再进行batch normalization和relu操作之后得到r22;然后,以r22作为输入,经过一个步长为1,卷积核大小为3
×
3的depthwise卷积,再经过卷积核大小为1
×
1的pointwise卷积,再进行batch normalization操作之后得到r23;最后,将r21和r23进行矩阵和操作,再进行relu激活之后得到r2;
17.将r1和r2进行矩阵和操作得到r,提取到更多的底层特征。
18.进一步地,步骤(3)所述stage模块和gam block模块进一步进行特征提取,并经transition模块进行特征融合实现过程如下:
19.每个stage模块中的每个branch都包含四个feature map;stage1有一个branch,为branch11,其输入为r,branch11通过下采样和多次残差连接提取特征,输入通道数为64,输出通道数为256;然后通过步长为1,大小为3
×
3的卷积保持该分支分辨率不变,为branch21,该分支的输出通道数为48;之后是transition1模块,通过步长为2,大小为3
×
3的卷积再产生一个分支branch22,该分支的输出通道数为96;
20.stage2有两个branch,分别为branch21和branch22,在branch22的开始处设置一个gam block模块,首先通过步长为2,大小为3
×
3的卷积对branch21的输出进行处理,产生的通道数为96,然后与branch22的输出进行融合之后进入branch32;然后通过步长为1,大小为1
×
1的卷积对branch22的输出进行上采样,该分支的输出通道数为48,然后与branch21的输出进行融合之后进入branch31;之后是transition2模块,通过步长为2,大小为3
×
3的卷积对branch22的输出进行处理产生一个通道数为192的分支branch33;
21.stage3有三个branch,分别为branch31、branch32和branch33,在branch33的开始处设置一个gam block模块;首先通过步长为2,大小为3
×
3的卷积对branch31的输出进行处理,输出通道数为48,记为t11;然后通过步长为1,大小为1
×
1的卷积对branch32的输出进行上采样,输出通道数为48,记为t12;再通过步长为1,大小为1
×
1的卷积对branch33的输出进行上采样,输出通道数为48,记为t13;再将t11、t12、t13进行融合得到t1;接着,通过步长为2,大小为3
×
3的卷积对branch31的输出进行处理,输出通道数为96,记为t21;然后通过步长为1,大小为1
×
1的卷积对branch33的输出进行上采样,输出通道数为96,记为t23;branch32的输出不变,记为t22,再将t21、t22、t23进行融合得到t2;之后,通过步长为2,大小为3
×
3的卷积对branch31的输出进行处理,输出通道数为192,记为t31;然后通过步长为2,大小为3
×
3的卷积对branch32的输出进行处理,输出通道数为192,记为t32,branch33的输出不变,记为t33,再将t31、t32、t33进行融合得到t3;stage3重复四次之后是transition3模块,通过步长为2,大小为3
×
3的卷积对branch33的输出进行处理,输出通道数为384,记为t4;
22.stage4有四个branch,分别为branch41、branch42、branch43和branch44,在branch44的开始处设置一个gam block模块;与stage3类似进行交叉融合,重复三次;之后是transition4模块,首先通过步长为1,大小为1
×
1的卷积分别对t1、t2、t3、t4的输出进行上采样,输出为分别为f11、f12、f13、f14,然后将f11、f12、f13、f14进行融合得到f,然后再通过步长为1,大小为1
×
1的卷积对f进行处理,输入通道数为48,输出通道数为17。
23.进一步地,所述depthwise卷积和pointwise卷积的输入输出通道数均为64。
24.基于相同的发明构思,本发明还提出一种基于gamhr-net的多人姿态估计系统,包括:
25.目标检测模块,用于对输入的图像或视频进行检测,得出当前输入中的所有人体位置信息;姿态估计模块,用于将目标检测网络得到的人体位置坐标及对应的图像送入gamhr-net网络进行特征提取和特征融合,得到人体关节点;所述gamhr-net网络包括一个stem-net模块、四个stage模块、四个transition模块以及三个gam block模块;首先经stem-net模块初步提取底层特征;然后经stage模块和gam block模块进一步进行特征提取,并经transition模块进行特征融合;显示模块,人体关节点显示在原输入图像或视频上,实现可视化。
26.有益效果:与现有技术相比,本发明的有益效果:1、gamhr-net模型始终保持高分辨率,并且主干网络通过对不同尺度的特征进行融合,充分利用现有特征的同时,再结合全局的语义信息,实现了更加准确和鲁棒的姿态预测;2、通过stem-net结构,利用并行可分离卷积的思想来减少初步特征提取阶段时底层信息的损失;3、通过gam block模块加强全局空间通道的交互以减少信息的损失,实现了较高的关节点定位精度和召回率。
附图说明
27.图1为本发明实施例的方法流程图;
28.图2为本发明实施例的gamhr-net主干结构图;
29.图3为本发明实施例的stem-net结构图;
30.图4为本发明实施例的res-multiconv结构图;
31.图5为本发明实施例的gam block结构图;
32.图6为本发明实施例的人体姿态检测效果图。
具体实施方式
33.下面结合附图对本发明作进一步详细说明。
34.本实施方式中涉及大量变量,现将各变量作如下说明,如表1所示。
35.表1变量说明表
36.[0037][0038]
[0039]
本发明提出一种基于gamhr-net的多人姿态估计方法,该方法通过yolov3目标检测网络检测输入图像或视频中的人体,得到一组或多组人体位置信息;然后将人体位置坐标及对应图像送入gamhr-net网络进行特征提取和特征融合,最后得到一组或多组人体关节点并将之在原图像或原视频上展示出来。如图1所示,具体包括以下步骤:
[0040]
步骤1:用目标检测网络对输入图像或视频进行检测,获取人体位置信息。
[0041]
采用的的目标检测网络为yolov3,通过coco 2017数据集对yolov3目标检测网络进行训练,输入的图像经过yolov3目标检测网络处理之后提取出特征图,然后,根据得到的特征图定位出一个或多个人体(一个还是多个人体取决于输入图像中的总人数)在原输入图像像素坐标系下的具体位置,最后,再根据人体框提取出人体图像。
[0042]
步骤2:如图2所示,构建gamhr-net网络,包括一个stem-net模块、四个stage模块、四个transition模块以及三个gam block模块;将人体位置信息与对应的图像送入gamhr-net网络进行特征提取和特征融合;首先经stem-net模块初步提取底层特征;然后经stage模块和gam block模块进一步进行特征提取,并经transition模块进行特征融合。
[0043]
四个stage模块进行特征的进一步提取及多尺度的特征融合和交互,四个transition模块来提取多通道信息以及三个gam block模块来加强全局空间通道的交互以减少信息的损失。
[0044]
如图3所示,stem-net模块包括主干网络和res-multiconv结构;stem-net模块的主干首先是一个步长为2,padding为1,输入通道为3,输出通道为64的3
×
3的卷积层,之后再经过batch normalization层和relu激活层;然后,再接一个步长为2,padding为1,输入通道为64,输出通道为64的3
×
3的卷积层,之后再经过batch normalization层和relu激活层;主干网络之后是res-multiconv结构。
[0045]
如图4所示,res-multiconv结构将stem-net模块主干网络分为两条支路。第一条支路首先经过一个步长为1,卷积核大小为1
×
1的depthwise卷积,再经过卷积核大小为1
×
1的pointwise卷积,再进行batchnormalization操作之后得到r11;接着,以r11作为输入,经过一个步长为1,卷积核大小为1
×
1的depthwise卷积,再经过卷积核大小为1
×
1的pointwise卷积,再进行batch normalization和relu操作之后得到r12;然后,以r12作为输入,经过一个步长为1,卷积核大小为1
×
1的depthwise卷积,再经过卷积核大小为1
×
1的pointwise卷积,再进行batch normalization操作之后得到r13;最后,将r11和r13进行矩阵和操作,再进行relu激活之后得到r1。
[0046]
第二条支路首先经过一个步长为1,卷积核大小为3
×
3的depthwise卷积,再经过卷积核大小为1
×
1的pointwise卷积,再进行batchnormalization操作之后得到r21;接着,以r21作为输入,经过一个步长为1,卷积核大小为1
×
1的depthwise卷积,再经过卷积核大小为1
×
1的pointwise卷积,再进行batch normalization和relu操作之后得到r22;然后,以r22作为输入,经过一个步长为1,卷积核大小为3
×
3的depthwise卷积,再经过卷积核大小为1
×
1的pointwise卷积,再进行batch normalization操作之后得到r23;最后,将r21和r23进行矩阵和操作,再进行relu激活之后得到r2。然后再将r1和r2进行矩阵和操作得到r,使其能够提取到更多的底层特征,r为stem-net结构的输出。在此过程中depthwise卷积和pointwise卷积的输入输出通道数均为64。
[0047]
如图5所示,gam block模块包括一个通道注意力子模块和一个空间注意力子模
块。通道注意子模块使用三维排列来在三个维度上保留信息,然后,用一个两层的mlp(多层感知器)来放大跨维通道-空间的依赖性。空间注意力子模块通过使用两个7
×
7卷积层进行空间信息融合来关注空间信息。
[0048]
每个stage中的每个branch都包含四个feature map,stage1有一个branch,为branch11,其输入为步骤(2.3)中的r,该branch11通过下采样和多次残差连接提取特征,输入通道数为64,输出通道数为256;然后通过步长为1,大小为3
×
3的卷积保持该分支分辨率不变,为branch21,该分支的输出通道数为48。之后是transition1模块,通过步长为2,大小为3
×
3的卷积再产生一个分支branch22,该分支的输出通道数为96。stage2有两个branch,分别为branch21和branch22,在branch22的开始处设置一个gam block模块,进行全局空间通道的交互来减少信息的损失。首先通过步长为2,大小为3
×
3的卷积对branch21的输出进行处理,产生的通道数为96,然后与branch22的输出进行融合之后进入branch32;然后通过步长为1,大小为1
×
1的卷积对branch22的输出进行上采样,该分支的输出通道数为48,然后与branch21的输出进行融合之后进入branch31。之后是transition2模块,通过步长为2,大小为3
×
3的卷积对branch22的输出进行处理产生一个通道数为192的分支branch33。stage3有三个branch,分别为branch31、branch32和branch33,在branch33的开始处设置一个gam block模块,进行全局空间通道的交互来减少信息的损失。首先通过步长为2,大小为3
×
3的卷积对branch31的输出进行处理,输出通道数为48,记为t11;然后通过步长为1,大小为1
×
1的卷积对branch32的输出进行上采样,输出通道数为48,记为t12;再通过步长为1,大小为1
×
1的卷积对branch33的输出进行上采样,输出通道数为48,记为t13;再将t11、t12、t13进行融合得到t1。接着,通过步长为2,大小为3
×
3的卷积对branch31的输出进行处理,输出通道数为96,记为t21;然后通过步长为1,大小为1
×
1的卷积对branch33的输出进行上采样,输出通道数为96,记为t23;branch32的输出不变,记为t22,再将t21、t22、t23进行融合得到t2。之后,通过步长为2,大小为3
×
3的卷积对branch31的输出进行处理,输出通道数为192,记为t31;然后通过步长为2,大小为3
×
3的卷积对branch32的输出进行处理,输出通道数为192,记为t32,branch33的输出不变,记为t33,再将t31、t32、t33进行融合得到t3。stage3重复四次之后是transition3模块,通过步长为2,大小为3
×
3的卷积对branch33的输出进行处理,输出通道数为384,记为t4。stage4有四个branch,分别为branch41、branch42、branch43和branch44,在branch44的开始处设置一个gam block模块,进行全局空间通道的交互来减少信息的损失。与stage3类似进行交叉融合,重复三次。之后是transition4模块,首先通过步长为1,大小为1
×
1的卷积分别对t1、t2、t3、t4的输出进行上采样,输出为分别为f11、f12、f13、f14,然后将f11、f12、f13、f14进行融合得到f,然后再通过步长为1,大小为1
×
1的卷积对f进行处理,输入通道数为48,输出通道数为17。
[0049]
在本实施方式中,存放数据文件夹为datasets/coco,包括四个子文件夹,分别为annotations,test2017,train2017和val2017,其中annotations保存json格式的标注文件,test2017、train2017和val2017分别存放测试集、训练集和验证集的图像。将coco数据集输入gamhr-net网络进行训练,初始学习率为0.001,优化器采用adam,batch_size为4,epochs为210,开始进行模型训练,得到训练好的gamhr-net网络权重模型,最终在测试数据集上进行验证;预测效果如图6所示。
[0050]
基于相同的发明构思,本发明还提供一种采基于gamhr-net的多人姿态估计系统,
包括:
[0051]
目标检测模块,用于对输入的图像或视频进行检测,得出当前输入中的所有人体位置信息。
[0052]
姿态估计模块,用于将目标检测网络得到的人体位置坐标及对应的图像送入gamhr-net网络进行特征提取和特征融合,得到人体关节点;gamhr-net网络包括一个stem-net模块、四个stage模块、四个transition模块以及三个gam block模块;首先经stem-net模块初步提取底层特征;然后经stage模块和gam block模块进一步进行特征提取,并经transition模块进行特征融合。
[0053]
显示模块,人体关节点显示在原输入图像或视频上,实现可视化。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1