一种终端边缘联合资源优化配置的方法及系统
1.本发明主要涉及计算机技术领域,具体涉及一种终端边缘联合资源优化配置的方法及系统。
背景技术:
2.网络、云计算、边缘计算、人工智能等技术的发展,引发了人们对元宇宙的无限想象。为了使用户能够在现实世界和虚拟世界之间进行交互,增强现实(ar)技术起着至关重要的作用。同时,人工智能由于其学习和推理能力,在自动语音识别、自然语言处理、计算机视觉等领域发挥着重要的作用。在ai技术的辅助下,ar可以进行更深入的场景理解和更沉浸的交互。
3.然而,人工智能算法,尤其是深度神经网络(dnn)的计算复杂度通常非常高。在计算和能量容量有限的移动设备上,很难及时可靠地完成神经网络的推理。实验表明,即使在移动gpu的加速下,典型的单帧图像处理ai推理任务也需要大约600毫秒。此外,连续执行上述推理任务在商品设备上最多只能持续2.5小时。上述问题导致目前只有少数ar应用程序使用深度学。为了减少dnn的推理时间,一种方法是对神经网络进行网络剪枝。但是,如果修剪太多通道,可能会对模型造成破坏,并且可能无法通过微调来恢复令人满意的准确度。
4.移动边缘计算辅助ai是解决这些问题的另一种方法。移动边缘计算和ai技术的集成最近已成为支持计算密集型任务的有前途的范例。边缘计算将ai模型的推理和训练过程转移到靠近数据源的网络边缘。因此,它将减轻网络流量负载、延迟和隐私问题。但是对于边缘计算辅助ai应用的任务,仍然存在大量挑战,具体表现为:
5.(1)边缘的计算资源虽然远远强于终端用户,但也是有限的,一味依靠边缘设备的计算能力,无法很好地解决终端算力不足的问题;
6.(2)用户将ai推理任务卸载到边缘计算,虽然一定程度上会降低计算能力不足带来的影响,但同时也会引入通信延时;
7.(3)延时,能耗,准确率三者相互制约,一味提升其中一方的性能必然会导致另外两者性能下降。
技术实现要素:
8.本发明的目的在于克服现有技术的不足,本发明提供了一种终端边缘联合资源优化配置的方法及系统,基于该优化方法同时降低系统的平均推理延时和移动设备的平均能耗,并提高模型推理的准确率。
9.本发明提供了一种终端边缘联合资源优化配置的方法,所述方法包括:
10.基于边缘控制器记录不同帧数的视频输入到神经网络时,计算神经网络所需要的乘加数以及神经网络识别的准确率;在收到各个移动设备的视频识别请求时,根据移动设备的视频识别请求完成控制任务,所述控制任务包括:
11.确定每个移动设备视频采样的帧数,并基于每个移动设备视频采样的帧数给移动
设备所对应的视频采样管理模块发送采样帧数控制信息;
12.确定用户卸载决策,基于用户卸载决策确定用户的推理任务是在本地dnn推理模块完成还是在边缘dnn推理模块中完成;
13.基于各个移动视频设备通信资源的分配策略从而确定各个移动设备上行传输视频的时间比例;
14.确定边缘dnn推理模块的资源分配策略来决定每个卸载用户的cpu计算频率。
15.所述方法还包括:
16.所述边缘dnn推理模块从需要卸载的边缘设备中得到上传的视频,然后根据边缘控制器分配的计算资源完成推理,并将推理结果发送至各个移动设备上。
17.所述方法还包括:
18.所述视频采样管理模块获取边缘计算的采样帧数控制信息,基于采样帧控制信息控制所在移动设备的采样帧数,确定用于神经网络推理的输入视频的帧数。
19.所述方法还包括:
20.所述本地控制器从视频采样管理模块中获取视频,并根据从边缘控制器获取的用户卸载决策决定是否将视频传输至边缘服务器。
21.所述本地控制器从视频采样管理模块中获取视频,并根据从边缘控制器获取的用户卸载决策决定是否将视频传输至边缘服务器包括:
22.若用户卸载决策为1,则将视频传输至边缘服务器进行推理,同时传输的通信资源由基站进行配置;
23.若用户卸载决策为0,那么允许视频在本地完成推理,并根据本地设备信息分配本地的cpu计算资源。
24.当移动设备需要在本地完成dnn推理时,本地dnn推理模块获取视频,并使用分配的本地计算资源完成dnn推理。
25.相应的,本发明还提供了一种边端协同的视频ai推理系统,所述系统包括:
26.边缘控制器,用于记录着当不同帧数的视频输入到神经网络时,计算神经网络所需要的乘加数以及神经网络识别的准确率;在收到各个移动设备的视频识别请求时,根据移动设备的视频识别请求完成控制任务;
27.边缘dnn推理模块,用于从需要卸载的边缘设备中得到上传的视频,然后根据边缘控制器分配的计算资源完成推理,并将推理结果发送至各个移动设备上;
28.视频采样管理模块,用于获取边缘计算的采样帧数控制信息,基于采样帧控制信息控制所在移动设备的采样帧数,确定用于神经网络推理的输入视频的帧数;
29.本地控制器,用于从视频采样管理模块中获取视频,并根据从边缘控制器获取的用户卸载决策决定是否将视频传输至边缘服务器;
30.本地dnn推理模块,用于当移动设备需要在本地完成dnn推理时,获取视频,并使用分配的本地计算资源完成dnn推理。
31.所述根据移动设备的视频识别请求完成控制任务包括:
32.确定每个移动设备视频采样的帧数,并基于每个移动设备视频采样的帧数给移动设备所对应的视频采样管理模块发送采样帧数控制信息;
33.确定用户卸载决策,基于用户卸载决策确定用户的推理任务是在本地dnn推理模
块完成还是在边缘dnn推理模块中完成;
34.基于各个移动视频设备通信资源的分配策略从而确定各个移动设备上行传输视频的时间比例;
35.确定边缘dnn推理模块的资源分配策略来决定每个卸载用户的cpu计算频率。
36.所述本地控制器在若用户卸载决策为1时,则将视频传输至边缘服务器进行推理,同时传输的通信资源由基站进行配置。
37.所述本地控制器在若用户卸载决策为0时,那么允许视频在本地完成推理,并根据本地设备信息分配本地的cpu计算资源。
38.本发明实施例具有的有益效果如下:
39.(1)本发明基于边端协同的ai推理算法卸载架构提供了一个边端协同的视频ai推理系统的架构,边缘服务器可以根据请求用户的数量,确定用户用于检测的视频帧数,并给出用户的卸载策略和用户的通信计算资源分配方案。
40.(2)多维度的性能优化。在给出的系统架构下,联合考虑推理延时,终端能耗和识别准确率,提出了一种有效的算法,在降低延时和能耗的同时,提升神经网络的识别准确率。
41.(3)性能权衡分析。该发明给出了推理延时,终端能耗和识别准确率三者之间的权衡关系,利用该关系,可以进行针对性的系统优化,不同应用下ai推理的系统性能。
附图说明
42.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见的,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它的附图。
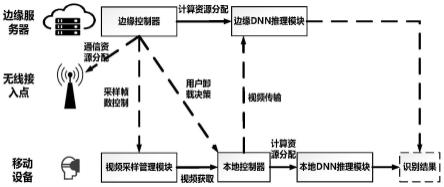
43.图1是本发明实施例中的边端协同的视频ai推理系统结构示意图;
44.图2是本发明实施例中的不同卸载策略的性能比较示意图;
45.图3是本发明实施例中的延时、能耗、识别准确率权衡关系示意图。
具体实施方式
46.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
47.本发明主要解决的技术问题是针对基于深度学习的视频识别任务,提出一种边端协同的视频ai推理系统的架构,并且根据该架构,提出了一种同时优化执行深度学习推理任务的延时,能耗以及准确率的方法。同时,本发明给出了延时,能耗以及准确率的权衡关系,该关系可以作为系统设计的参考。
48.本发明提出了一种边端协同的视频ai推理系统的架构,其功能是,在一个边缘服务器通过无线接入服务多个移动设备场景下,当这些设备都需要进行基于ai的视频识别任务时,通过合理调整进行识别的视频帧数以及联合配置无线与计算资源,达到降低神经网
络的推理延时和能耗,同时提高神经网络推理准确率的目的。
49.具体的,图1示出了本发明实施例中的边端协同的视频ai推理系统结构示意图,该系统包括:
50.边缘控制器,用于记录着当不同帧数的视频输入到神经网络时,计算神经网络所需要的乘加数以及神经网络识别的准确率;在收到各个移动设备的视频识别请求时,根据移动设备的视频识别请求完成控制任务;
51.边缘dnn推理模块,用于从需要卸载的边缘设备中得到上传的视频,然后根据边缘控制器分配的计算资源完成推理,并将推理结果发送至各个移动设备上;
52.视频采样管理模块,用于获取边缘计算的采样帧数控制信息,基于采样帧控制信息控制所在移动设备的采样帧数,确定用于神经网络推理的输入视频的帧数;
53.本地控制器,用于从视频采样管理模块中获取视频,并根据从边缘控制器获取的用户卸载决策决定是否将视频传输至边缘服务器;
54.本地dnn推理模块,用于当移动设备需要在本地完成dnn推理时,获取视频,并使用分配的本地计算资源完成dnn推理。
55.所述根据移动设备的视频识别请求完成控制任务包括:确定每个移动设备视频采样的帧数,并基于每个移动设备视频采样的帧数给移动设备所对应的视频采样管理模块发送采样帧数控制信息;确定用户卸载决策,基于用户卸载决策确定用户的推理任务是在本地dnn推理模块完成还是在边缘dnn推理模块中完成;基于各个移动视频设备通信资源的分配策略从而确定各个移动设备上行传输视频的时间比例;确定边缘dnn推理模块的资源分配策略来决定每个卸载用户的cpu计算频率。
56.所述本地控制器在若用户卸载决策为1时,则将视频传输至边缘服务器进行推理,同时传输的通信资源由基站进行配置;在若用户卸载决策为0时,那么允许视频在本地完成推理,并根据本地设备信息分配本地的cpu计算资源。
57.基于图1所示的系统结构,本发明实施例中的终端边缘联合资源优化配置的方法,所述方法包括:基于边缘控制器记录不同帧数的视频输入到神经网络时,计算神经网络所需要的乘加数以及神经网络识别的准确率;在收到各个移动设备的视频识别请求时,根据移动设备的视频识别请求完成控制任务,所述控制任务包括:确定每个移动设备视频采样的帧数,并基于每个移动设备视频采样的帧数给移动设备所对应的视频采样管理模块发送采样帧数控制信息;确定用户卸载决策,基于用户卸载决策确定用户的推理任务是在本地dnn推理模块完成还是在边缘dnn推理模块中完成;基于各个移动视频设备通信资源的分配策略从而确定各个移动设备上行传输视频的时间比例;确定边缘dnn推理模块的资源分配策略来决定每个卸载用户的cpu计算频率。
58.进一步的,所述边缘dnn推理模块从需要卸载的边缘设备中得到上传的视频,然后根据边缘控制器分配的计算资源完成推理,并将推理结果发送至各个移动设备上。
59.进一步的,所述视频采样管理模块获取边缘计算的采样帧数控制信息,基于采样帧控制信息控制所在移动设备的采样帧数,确定用于神经网络推理的输入视频的帧数。
60.进一步的,所述本地控制器从视频采样管理模块中获取视频,并根据从边缘控制器获取的用户卸载决策决定是否将视频传输至边缘服务器。
61.进一步的,所述本地控制器从视频采样管理模块中获取视频,并根据从边缘控制
器获取的用户卸载决策决定是否将视频传输至边缘服务器包括:若用户卸载决策为1,则将视频传输至边缘服务器进行推理,同时传输的通信资源由基站进行配置;若用户卸载决策为0,那么允许视频在本地完成推理,并根据本地设备信息分配本地的cpu计算资源。
62.进一步的,当移动设备需要在本地完成dnn推理时,本地dnn推理模块获取视频,并使用分配的本地计算资源完成dnn推理。
63.需要说明的是,根据上述系统架构,本发明提出了对应的优化方案,同时降低系统的平均推理延时和移动设备的平均能耗,并提高模型推理的准确率,具体算法如下:
64.首先,利用神经网络的乘加数模型得到完成神经网络模型推理需要的乘加数c(mn),考虑到对于每一层神经网络,完成推理需要的乘加数和输入大小成正比,因此经过推导,总的计算乘加数可以粗略地由输入视频帧数的线性函数表示,记为:
65.c(mn)=m
c,0mn
+m
c,1
66.其中m
c,0
和m
c,1
是通过拟合得到的参数,由模型的架构决定,mn为采样帧数控制信息,然后根据乘加数给出神经网络的计算延时dn和能耗en的表达式:
[0067][0068][0069]
其中ρ表示每一个乘加运算需要的cpu转数,d表示每一帧视频的大小,rn表示第n个移动设备的通信速率,tn代表第n个移动设备的通信时间比例(即通信资源分配比例),κ表示能耗系数,pn表示移动设备的发射功率,xn表示用户卸载决策,表示分配给本地的cpu计算资源,表示根据边缘控制器分配的计算资源,xn代表是否卸载到边缘计算(如果xn=1则代表卸载,否则就在本地计算)。
[0070]
对于准确率,输入视频的帧数越多,模型预测的准确率越高。而随着视频输入帧数的增加,模型预测准确率的增益会逐渐下降。因此,准确率φ(mn)可以表示成如下函数:
[0071][0072]
其中m
a,0
,m
a,1
以及m
a,2
是通过拟合得到的参数,数值由神经网络的模型和任务决定。
[0073]
综上所述,优化的目标函数为:
[0074][0075][0076][0077][0078][0079][0080][0081]
其中:β1,β2,β3分别为权重系数,优化目标是降低总延时dn和总能耗en,并提高用户
识别准确率φ(mn),约束条件为
①
用户帧数符合给定的范围,
②
参与卸载的设备其通信时间比例之和小于1,
③
边缘设备的分配计算频率之和小于其上限,
④
分配的通信时间以及边缘计算频率需要大于0,
⑤
移动设备的计算频率分配为大于0小于的值,
⑥
xn为卸载或者不卸载。
[0082]
为了求解该优化问题,设定卸载策略xn是给定的,然后把问题分解为2个子问题,分别是在本地完成推理的移动设备的资源优化问题和在边缘完成推理的移动设备的资源优化问题。设在本地完成推理的用户集合为n0,在边缘完成推理的用户集合为n1,因此该优化问题转化为两个子优化问题。
[0083]
对于n0的资源优化问题,其问题表述为:
[0084][0085][0086][0087]
其中勾在本地计算时的代价函数。需要满足的约束条件为
①
用户帧数符合给定的范围,
②
移动设备的计算频率分配为大于0小于的值
[0088]
通过推导,可以得到求解该子问题的闭式表达式:
[0089][0090][0091]
对于n1的资源优化问题,其问题表述为:
[0092][0093][0094][0095][0096][0097]
其中勾卸载到边缘计算时的代价函数。需要满足的约束条件为
①
用户帧数符合给定的范围,
②
参与卸载的设备其通信时间比例之和小于1,
③
边缘设备的分配计算频率之和小于其上限,
④
分配的通信时间以及边缘计算频率需要大于0。
[0098]
通过推导,可以得到tn,与mn的关系表达式为:
[0099]
[0100][0101]
然后通过凸优化的方法可以求解该问题。
[0102]
对于卸载策略xn的求解问题,本发明实施例基于贪婪的迭代算法来实现。可以观察到在本地执行推理时,成本函数和优化变量mn,只依赖于设备自身的参数,不受其他设备参数的影响。但是,对于边集代价函数与集合中的设备数量和参数有关。下面介绍基于算法的原理。首先,计算每个设备的任务在本地执行时集合的成本函数其次,舍得所有设备都卸载到边缘服务器进行推理并且在每次迭代中,得到的每个设备对应的代价函数比较成本函数和代价函数在集合中的设备,可以得到和之间的差值,并选择差值最大的设备记为设备y。尝试将集合中的设备y放入集合并计算新集合的成本。如果新集合的总成本降低,则继续下一次迭代。否则,将设备y放回集合算法结束。
[0103]
将下行带宽设置为5mhz,路径损耗建模为pl=128.1+37.6log
10
(d),其中d是设备与无线接入点之间的距离,单位为公里。设备随机分布在[500m 500m]范围内。mec服务器和设备的计算资源分别设置为1.8ghz和22ghz。识别精度要求和最大输入视频帧数设置为系数κ=10
28
,由对应的设备确定。输入视频的大小为112*112*mn。此外,计算复杂度系数设置为ρ=12这是在通过多次实验获得的。权重β1,β2,β3分别设置为0.2,0.2,0.6。
[0104]
将提出的卸载方案与本地推理方案(local)、边缘推理方案(edge)、随机卸载方案(random)进行比较,实验结果如图2所示。当设备数量小于10时,仅在边缘执行任务的方案的成本几乎等于提出卸载方案的成本。这是因为当设备数量较少时,所有设备都可以从边缘服务器上执行推理中受益。如果推理任务只在本地执行,设备的平均成本不会改变,因为设备之间的本地资源互不影响。edge方案的曲线是线性的,因为实验中所有用户的ai模型都是相同的。
[0105]
本实验使用不同的权重β1,β2,β3来分析平均延迟、能耗和准确率之间的权衡关系。权衡曲面的性能是通过提出的卸载和分配方案获得的,约束是β1+β2+β3=1。如图3所示,延迟、能耗和准确性是相互限制,三者相互权衡。当延迟恒定时,更高的识别精度需要更高的能耗。从另一个角度来说,为了提高准确率,需要牺牲延迟和能耗的性能。此外,具有相同的精度时,更高的能耗会使设备更倾向于在本地执行推理任务,从而使得延迟降低。
[0106]
本发明实施例具有的有益效果如下:
[0107]
(1)本发明基于边端协同的ai推理算法卸载架构提供了一个边端协同的视频ai推理系统的架构,边缘服务器可以根据请求用户的数量,确定用户用于检测的视频帧数,并给出用户的卸载策略和用户的通信计算资源分配方案。
[0108]
(2)多维度的性能优化。在给出的系统架构下,联合考虑推理延时,终端能耗和识
别准确率,提出了一种有效的算法,在降低延时和能耗的同时,提升神经网络的识别准确率。
[0109]
(3)性能权衡分析。该发明给出了推理延时,终端能耗和识别准确率三者之间的权衡关系,利用该关系,可以进行针对性的系统优化,提升不同应用下ai推理的系统性能。
[0110]
本领域普通技术人员可以理解上述实施例的各种方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,该程序可以存储于一计算机可读存储介质中,存储介质可以包括:只读存储器(rom,readonly memory)、随机存取存储器(ram,random access memory)、磁盘或光盘等。
[0111]
另外,以上对本发明实施例进行了详细介绍,本文中应采用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1