一种基于程序上下文的移动应用敏感行为描述生成方法
1.本发明涉及一种移动应用敏感行为描述生成方法,具体是一种基于程序上下文和应用文档的移动应用敏感行为描述生成方法,属于软件分析领域以及自然语言生成领域。
背景技术:
2.当前,智能手机蓬勃发展,移动应用凭借其便捷性和多元化逐渐渗透到生活的衣食住行方方面面,极大地满足人民需求,推动社会发展。为了更好地服务用户,应用会申请获取用户的某些敏感数据来提供支持,例如本地生活类应用会申请获取用户的位置信息为用户推荐附近的美食或者景点,音乐类应用会申请用户的联络人信息为不同的联络人设置不同的铃声。但是,恶意应用泛滥于市场,他们以非法方式收集用户的敏感数据,导致用户隐私的泄露与滥用,造成严重后果。保障用户合法权益、保护用户隐私数据势在必行。
3.目前,智能手机操作系统市场占有率最高的安卓采用权限机制来保护用户的隐私:在安卓6.0之前,移动应用列出它需要的所有权限,用户只能同意授予全部权限才能安装;安卓 6.0及以后,移动应用需要动态申请权限,移动应用在第一次需要使用权限的时候申请。但由于恶意应用滥用隐私行为的存在,用户在面对权限申请时存在应用为何申请这个权限以及应用得到这个权限后会否泄露个人隐私的顾虑,难以决断。
4.用户可以通过阅读隐私权政策文档来了解应用申请权限以及操作用户隐私数据的敏感行为。隐私权政策是谷歌商店要求每个应用都应该上传的一份完整说明应用如何收集、使用和分享用户数据的文档,见于谷歌商店应用详情面、移动应用登录界面等地方。目前,用户向隐私权政策文档了解应用敏感行为存在隔阂,有以下两个问题:
5.(1)隐私权政策文档过长,包含法律条款、联系方式等信息,阅读起来耗时费力;
6.(2)隐私权政策文档中缺乏应用敏感行为相关描述,敏感权限的平均描述率只有 10.5%;
技术实现要素:
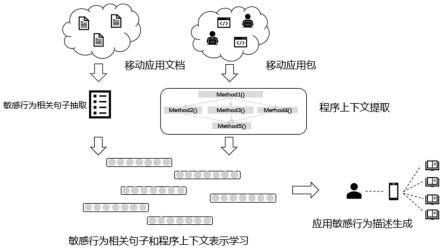
7.发明目的:现有的移动应用敏感行为描述生成方法集中于用传统自然语言处理方法来抽取应用描述中关于申请权限的解释,或者加入隐私权政策和代码分析作为辅助手段,利用语法来生成相应描述。由于应用文档中应用敏感行为描述的普遍缺失,现有方法只能处理小部分敏感行为。本发明针对现有移动应用敏感行为描述生成方法中的不足,提出了一种基于程序上下文的移动应用敏感行为描述生成方法,通过抽取应用程序中的程序调用图、图形界面中的文字作为应用程序的上下文,结合机器阅读理解和关键词抽取应用文档中的应用敏感行为相关句子,对于应用文档中缺失的应用敏感行为描述,根据其程序上下文相似度为其分配在现有数据中匹配度最高的应用敏感行为描述作为补全,并通过基于提示学习微调gpt3模型,大幅度提升移动应用敏感行为描述生成的效果。
8.技术方案:一种基于程序上下文的移动应用敏感行为描述生成方法,利用移动应用的程序上下文信息和应用文档,通过提示学习微调gpt3自然语言生成模型,生成精准的
移动应用敏感行为描述,用户可以在充分了解应用敏感行为后做出合适的决定,包括以下内容:
9.(1)移动应用程序上下文提取
10.对移动应用包进行静态分析,结合移动系统如安卓特有的组件间通信构造合理全面的程序调用图,分析应用图形界面和调用图中方法的映射关系,提取布局文件中相应的信息,对于移动应用的上下文提取,主要分为两个部分:
11.1.1应用程序代码上下文提取,由于应用代码中的方法名能直观地反映程序的意图,所以在敏感权限对应的敏感调用方法的调用过程中,方法名的文本序列能够提供应用敏感行为的上下文;
12.1.2应用图形界面上下文提取,应用的图形界面作为与用户交互的窗口,其中有着很多图标与文字,这些元素包含着和应用使用敏感权限的意图,例如图形界面上的“gps定位”文本暗示着应用将使用位置权限给用户提供gps导航等服务,所以需要提取图形界面所对应的布局文件中的文字和资源名。
13.(2)移动应用文档中敏感行为相关句子抽取与补充
14.从安卓移动应用的隐私权政策文档中提取和补充应用敏感行为相关句子。包括根据关键词、结合机器阅读理解问答抽取敏感行为相关句子以及根据词频-逆文档频率相似度为部分安卓移动应用补充敏感行为相关句子。
15.移动应用中的敏感行为可以从两种移动应用文档中找到,一是应用隐私权政策,它是谷歌商店要求开发者提供的完整说明应用如何收集、使用和分享用户数据的文档,二是应用描述,作为吸引用户下载的文案,其中有应用的功能和特性的概括性描述,其中也有对应用敏感行为的描述。在谷歌商店应用详情页爬取移动应用的隐私权政策和应用描述文档并分句,进行敏感行为相关句子抽取与补充,主要分为两个部分:
16.2.1敏感行为相关句子抽取,结合关键词和机器阅读理解抽取相应的敏感行为相关句子。根据官方的权限文档分析出每个权限对应的关键词,并将包含关键词的分句加入相应权限的敏感行为相关句子备选数据库。使用基于bert微调的问答系统在应用文档中抽取出关于为什么要使用相应权限的回答,并加入敏感行为相关句子备选数据库。
17.2.2敏感行为相关句子补充,对于从隐私权政策文档中能使用关键词和机器阅读理解方法抽取敏感行为相关句子的应用,使用关键词和机器阅读理解方法抽取的敏感行为相关句子即为该应用的隐私权政策相关输入,对于无法使用关键词和机器阅读理解方法抽取敏感行为相关句子的应用,需要根据提取的应用程序上下文从描述备选数据库寻找相似度最高的敏感行为相关句子,作为该应用的隐私权政策相关输入。
18.(3)移动应用文档中敏感行为描述生成
19.使用前面操作提取的程序上下文和抽取与补充的隐私权政策中相关的敏感行为相关句子,基于提示学习方法,设计提示,并使用gpt3模型进行微调训练,最终生成结合程序上下文的应用敏感行为描述。
20.结合安卓移动应用特点构造程序调用图,提取程序代码上下文和图形界面上下文作为应用敏感行为信息;
21.安卓程序是由组件构成,将组件间通信、生命周期事件、界面交互、多线程的调用关系纳入应用调用图构造。使用soot构造应用调用图,提取应用程序中所有类和所有方法,
使用宽度优先搜索进行程序方法节点的扫描与拓展。如果扫描到的程序方法中的语句是关于生命周期事件、界面交互或多线程语句,则也执行加边操作。使用ic3工具分析安卓应用组件间通信过程,在获取组件通信的双方后,在调用图中进一步加入节点和有向调用边。
22.提取程序代码上下文。使用pscout提供的映射表在应用调用图中找到敏感权限调用方法,并用宽度优先搜索方法构造敏感权限调用方法子图。在敏感权限调用方法子图中,采用节点中方法签名里的方法名称作为程序代码上下文,根据驼峰命名法或下划线命名法分割方法名。
23.提取图形界面上下文。使用soot遍历应用程序中的方法体提取activity绑定的布局文件id。根据敏感权限调用方法子图确定应用程序中使用了敏感权限的activity,提取使用敏感权限的activity与布局文件id的映射关系。解包移动应用包获取应用中布局文件名字和布局的映射关系,匹配出使用敏感权限的activity与布局文件名称的绑定关系,提取资源中的文本属性和资源名作为图形界面上下文。
24.根据关键词、结合机器阅读理解问答抽取与根据词频-逆文档频率相似度补充敏感行为相关句子,解决传统抽取式生成方法中应用文档敏感行为描述普遍缺失问题。
25.首先,以在官方文档中出现频次高或敏感权限名和资源名为关键词,在分句后的文档中抽取相关句子。然后,使用基于bert的机器阅读理解问答模型在去除已抽取的相关句子后的文档中多次循环抽取文档中敏感行为相应句子。
26.对于应用文档敏感行为相关句子抽取结果为空应用,根据其提取的程序上下文,在已抽取的其他应用的备选数据中按照敏感权限和应用程序上下文补充隐私权政策文档敏感行为相关句子。基于词频-逆文档频率(tf-idf)计算两个应用程序上下文的相似度:
[0027][0028][0029]
tf-idfw=tfw*idfw[0030]
其中nw是在某一应用程序上下文文本中词条w出现的次数,n是该文本总词条数,y是相同敏感权限中敏感行为描述备选数据库中的文档总数,yw是包含词条w的文档数。
[0031]
对于某一缺少隐私权政策文档敏感行为相关句子的应用,计算程序上下文中每个词条的 tf-idf,形成词频-逆文档频率矩阵,分别计算相同敏感权限中其他应用的程序上下文的词频-逆文档频率矩阵,计算余弦相似度:
[0032][0033]
其中,a、b分别为待补充应用和备选数据库中相同敏感权限的其他应用的程序上下文的词频-逆文档频率矩阵。从备选数据库中选取余弦相似度最高的应用,将其隐私权政策文档敏感行为相关句子作为该待补充的应用的隐私权政策文档敏感行为相关句子。
[0034]
能在数据数量不大的情况下表现出色的基于提示学习微调gpt-3的移动应用敏感行为生成方法。
[0035]
基于提示学习,增加程序上下文等专家知识,改造敏感行为描述的下游任务,使该任务输入和输出更贴近原始gpt-3语言模型。通过为输入文本增加拼接任务提示语言,把敏
感行为描述生成任务转换为询问gpt3这篇文档“当前应用使用相机权限去”的文章续写题。设计提示为:“user interface:user interface texts;call graph:call graph texts;privacy policy: referenced privacy policy;this application uses permission permission to”,使任务的输入更贴近原始训练语料,其中,permission为应用用到的敏感权限,call graph texts为程序代码上下文,user interface texts为程序图形界面上下文,referenced privacy policy为隐私权政策文档中敏感行为相关句子。在训练过程中,使用部分数据样例对gpt3进行微调,对于用于训练的数据,将其应用描述文档中敏感行为描述文本 extracted application description改写为“this application uses permission permissionto extracted application description”并加以修改调整,最后加入提示中进行训练。
[0036]
有益效果:与现有技术相比,本发明提供的基于程序上下文的移动应用敏感行为描述生成方法,优势如下:
[0037]
(1)考虑应用程序上下文,对不同类型的应用程序上下文分别处理,丰富了应用操作敏感权限的来源,提升了在敏感行为生成中的准确性;
[0038]
(2)本发明采用了多种文档抽取方法,在应用隐私权政策文档抽取过程中同时用关键词抽取和机器阅读理解问答抽取相应权限的敏感行为相关句子,提升了抽取行为的召回率,最终提高了敏感行为描述生成的效果;
[0039]
(3)综合考虑程序上下文中程序调用图和应用图形界面文本信息,对于未能在隐私权政策文档中抽取出相应敏感行为相关句子的应用,能根据程序上下文从描述备选数据库中匹配出最相似的敏感行为相关句子作为该应用的隐私权政策文档的输入,解决了隐私权文档中应用敏感行为相关描述普遍缺失的问题;
[0040]
(4)本发明采用基于提示学习的方法设计提示,使生成任务更贴近gpt3原始训练过程,更能激发出gpt3潜在的推理能力,在小样本数据训练中达到良好的生成效果。
附图说明
[0041]
图1为本发明实施例的整体流程示意图;
[0042]
图2为本发明实施例的应用程序上下文提取流程示意图;
[0043]
图3为本发明实施例的应用隐私权政策文档敏感行为相关句子抽取流程示意图。
具体实施方式
[0044]
下面结合具体实施例,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本技术所附权利要求所限定的范围。
[0045]
基于程序上下文的移动应用敏感行为描述生成方法,包括以下内容和步骤:
[0046]
(1)移动应用程序上下文提取
[0047]
根据移动应用包,获得移动应用程序上下文的步骤包括:
[0048]
步骤1.1,兼顾安卓特点的应用调用图构造,不同于常规的java程序,安卓应用程序拥有独特的组件间通信和生命周期方法,在构造调用图时,除了显式的调用关系,由组件间通信、生命周期方法和多进程通信引起的隐式调用也需要考虑;
[0049]
步骤1.2,敏感权限调用方法子图构造,在步骤1.1构造的应用调用图中找到敏感权限调用方法,并用宽度优先搜索方法构造敏感权限调用方法子图;
[0050]
步骤1.3,敏感权限调用方法子图文本提取,在提取敏感权限调用子图后,提取子图节点所代表的程序方法名,并用根据驼峰命名法或下划线命名法对方法名进行剥离;
[0051]
步骤1.4,应用图形界面布局文件id获取,在程序静态分析过程中,根据步骤1.2构造的敏感权限调用方法子图确定应用程序中使用了敏感权限的应用组件activity,并对每个程序方法的方法体进行遍历,搜索其中与为应用组件activity设置布局文件相关的程序语句,提取出activity与布局文件id的映射关系;
[0052]
步骤1.5,应用图形界面布局文件文本提取,将移动应用包解码,在资源文件夹中获取应用中布局文件名字和id的映射关系,后匹配出应用组件activity与布局文件名称的绑定关系,最终根据布局文件名称在资源文件夹中提取文本属性和资源名。
[0053]
在本实施实例中,如图2所示,其中静态分析需要充分考虑安卓程序特点,所以图2中我们将安卓程序特有的进程间通信、生命周期方法等整合于程序调用图,以提升其准确度。在每一个应用的程序上下文提取中,执行的步骤详细过程如下:
[0054]
步骤1.1中,兼顾安卓特点的应用调用图构造,安卓程序是由组件构成,组件之间会相互通信;安卓程序由事件驱动,用户在安卓程序中浏览的时候,安卓框架会启动一系列生命周期事件(如oncreate和onresume);用户在和安卓程序图形界面中与程序交互时,会触发安卓程序中的交互事件(如调用onclick这样的callback方法);多线程将程序的执行剥离开来,在前端和后台一起执行。不管是组件间通信、生命周期事件、界面交互还是多线程都会唤起其他方法的执行,而在常规的java程序调用图中,这些隐式的调用都不会被构造。本发明考虑到安卓应用特点,将组件间通信、生命周期事件、界面交互、多线程的调用关系也纳入应用调用图构造。
[0055]
本发明使用soot构造应用调用图,提取应用程序中所有类和所有方法,并使用宽度优先搜索进行程序方法节点的扫描与拓展。在程序方法节点的扫描过程中,按序遍历程序方法中的语句,通过句中的调用关系构造有向边,并将被调用的方法加入待扫描的队列。如果扫描到的语句是关于生命周期事件、界面交互或多线程语句,加入待加边集合,最后执行加边操作。本发明中加入的隐形调用关系如表1所示:
[0056]
表1加入的隐形调用关系
[0057][0058]
本实施例使用ic3工具分析安卓应用组件间通信过程,努力准确推测组件间通信数据传递过程中中间载体intent复合变量值,并基于此匹配intent和其可能的目标组件,减少组件间通信的错误推断(false positives)数量。在获取组件通信的双方后,在上一步所得的调用图中进一步加入节点和有向调用边。
[0059]
步骤1.2中,敏感权限调用方法子图构造,基于应用调用图构造的结果,在应用调用图中找到敏感权限调用方法。安卓程序需要调用敏感权限调用方法来使用敏感权限,同一个敏感权限也有很多不同的敏感权限调用方法。本实施例使用pscout提供的敏感权限和敏感权限调用方法映射表来获取所需的敏感权限对应的敏感权限调用方法。遍历应用调用图构造的每个方法节点,如果它是敏感权限调用方法,则用宽度优先搜索方法构造敏感权限调用方法子图。对于一个安卓应用,会有多张敏感权限调用方法子图,因为一个应用会调用不同的敏感权限,同一个敏感权限会使用不同的敏感权限调用方法。根据谷歌官方划定的危险权限组将同一个危险权限组的敏感权限调用方法子图划为同一个集合。
[0060]
步骤1.3中,敏感权限调用方法子图文本提取,在敏感权限调用方法子图中,每个节点为方法签名,包括方法所在类、返回值、名称和参数信息,由于方法所在类、返回值、名称和参数在同一个应用程序内多次出现造成大量的重复,所以本方法仅采用方法签名中的方法名称作为程序上下文。在java语言中,变量命名习惯为驼峰命名法,本实施例根据驼峰命名法或下划线命名法对敏感权限调用方法子图中的方法名进行分离,例如将createcamerascreennail剥离为create,camera,screen,nail序列。在提取方法名的过程中,如果遇到因代码混淆而代码名长度非常短的情况,例如方法名为a或者b,则略去这样的方法名。敏感权限调用方法子图中提取的文本是应用程序上下文的一部分。
[0061]
步骤1.4中,应用图形界面布局文件id获取,在安卓程序中,应用组件activity代表着用户界面,担任与用户交互的任务,加载与展示布局文件。在安卓应用程序中,布局文件既可以在activity一开始调用setcontentview方法时被加载,也可以在activity运行过程中调用 inflate方法来加载。本实施例在使用soot进行程序静态分析时,通过遍历应用程序中的方法体,搜索setcontentview与inflate语句,并从语句中提取出该activity此时绑定的布局文件的id。根据步骤1.2构造的敏感权限调用方法子图确定应用程序中使用了敏感权限的 activity,最终提取使用了敏感权限的activity与布局文件id的映射关系。
[0062]
步骤1.5,应用图形界面布局文件文本提取,本实施例使用apktool工具解包移动应用包,在解包后的/res/values/public.xml文件中获取应用中布局文件名字和布局的映射关系,然后结合步骤1.4的使用敏感权限的activity与布局文件id的映射关系匹配出使用敏感权限的 activity与布局文件名称的绑定关系。最后根据布局文件名称在应用解包后的资源文件夹中提取文本属性和资源名,这些文本属性与资源名是应用程序上下文的另一部分。
[0063]
(2)移动应用文档中敏感行为相关句子抽取与补充
[0064]
移动应用文档中的敏感行为描述是生成移动应用敏感行为描述的重要参考和来源。在谷歌商店应用详情页面爬取移动应用的隐私权政策和应用描述文档后,根据句号、问号、感叹号等符号进行分句操作,再进行敏感行为相关句子抽取与补充。
[0065]
在敏感行为相关句子抽取步骤中,首先按照关键词在文档中抽取出相关语句。关键词的来源有二:一是根据pscout提供的敏感权限和敏感权限调用方法映射表爬取安卓开发者官方文档的方法接口说明,分词后按照敏感权限为单位成为集合,并选择其中出现频次高的词语做关键词;二是根据移动应用文档中常见的使用意图设定关键词,如申请相机权限的总是用来拍照,则“take pictures”是相机权限的关键词之一。
[0066]
关键词方法使抽取答案集中于个别词组,不利于文档抽取的完整性,因此,本实施
例还使用基于bert的机器阅读理解问答模型抽取文档中相应句子。具体的做法是:将应用的文档作为文本,将“why does this application use calendar permission?”,其中calendar指的是该移动应用使用的日历敏感权限。由于文档中会多次出现关于单个敏感权限的敏感行为相关句子,本实施例将会从文档中抽取多次,并将上一次抽取的句子从文档中移除,且只抽取置信度高于0.3的句子。
[0067]
对于单个应用,对基于关键词和机器阅读理解抽取的敏感行为相关句子进行区间去重与融合,如果该应用文档的敏感行为相关句子抽取结果不为空,则经过区间去重与融合的敏感行为相关句子抽取结果即为该应用的隐私权政策文档敏感行为描述参考文本,并将结果以(敏感权限,应用程序上下文,应用隐私权政策文档敏感行为描述参考文本)形式放入敏感行为相关句子备选数据库。对于应用文档敏感行为相关句子抽取结果为空应用,根据其提取的程序上下文提取,在备选数据库中按照敏感权限和应用程序上下文补充隐私权政策文档敏感行为相关句子参考文本。本实施例基于词频-逆文档频率(tf-idf)计算两个应用程序上下文的相似度,计算公式如下:
[0068][0069][0070]
tf-idfw=tfw*idfw[0071]
其中nw是在某一应用程序上下文文本中词条w出现的次数,n是某一应用程序文本总词条数,y是相同敏感权限中敏感行为相关句子备选数据库中的文档总数,yw是包含词条w的文档数。
[0072]
对于某一缺少隐私权政策文档敏感行为描述参考文本的应用,计算程序上下文中每个词条的tf-idf,形成词频-逆文档频率矩阵,分别计算相同隐私权限中其他应用的程序上下文的词频-逆文档频率矩阵,计算余弦相似度,公式如下:
[0073][0074]
其中,a、b分别为待补充应用和备选数据库中相同敏感权限的其他应用的程序上下文的词频-逆文档频率矩阵。从备选数据库中选取余弦相似度最高的应用,将其隐私权政策文档敏感行为描述参考文本作为待补充的应用的隐私权政策文档敏感行为描述参考文本。
[0075]
(3)敏感行为描述生成
[0076]
清晰明了、详略得当的应用敏感行为描述是用户与应用敏感行为间的桥梁。除了充足的应用敏感行为信息,在基于深度学习的应用敏感行为描述生成过程中,还需要准确、合适的敏感行为描述目标来辅助训练过程。这样的敏感行为描述目标需要具备以下特质:一是正确反映该应用的敏感行为意图,二是语言需要简洁明了、通俗易懂。应用的描述文档就能担当这样的任务。应用的描述文档出现于应用在google play应用商店的应用详情页面,作为吸引用户下载的文案,它的语言相对来说简单生动,其中有应用的功能和特性的概括性描述,是较为理想的生成目标。本实施例将应用的描述文档中与应用敏感行为相关的句子抽取出来,作为训练时的目标。
[0077]
经过移动应用程序上下文提取和文档中敏感行为描述抽取与补充步骤后,我们仅将同时能在应用包中提取出程序上下文和能在应用描述文档中抽取出同一敏感权限相关的敏感行为描述的应用纳入本实施例的实验数据集,最终形成形式为(permission,call graph texts, user interface texts,referenced privacy policy,extracted application description) 的实验数据条目,其中,permission为应用用到的敏感权限,call graph texts为程序调用图文本,user interface texts为程序图形界面文本,referenced privacy policy为隐私权政策文档中敏感行为描述参考文本,extracted application description为应用描述文档中敏感行为描述文本。
[0078]
由于应用文档中敏感行为相关描述的普遍缺失和代码混淆的普遍存在,在对8580个应用包及其应用描述、隐私权政策文档进行分析后,共得到了1006条数据。如此少量的数据难以支撑自然语言生成的模型,因此,本实施例基于生成式预训练模型gpt3生成应用敏感行为描述。gpt3模型基于超过3000亿的文本符号训练而成,在需要即时推理或领域适应的任务中表现出色,在零样本、少样本的训练任务中有很好的表现。
[0079]
本实施例基于提示学习,通过改造敏感行为描述的下游任务、增加程序语言上下文等专家知识,使该任务输入和输出适合原始语言模型,在零样本或少样本的场景中获得良好的任务效果。本实施例通过为输入文本增加任务提示语言,将敏感行为描述生成任务转换为基于预训练语言模型的文章续写问题,也就是把敏感行为描述生成任务转换为询问gpt3这篇文档“当前应用使用相机权限去”的文章续写题。具体设计的提示为:“user interface: user interface texts;call graph:call graph texts;privacy policy: referenced privacy policy;this application uses permission permission to”,使任务的输入更贴近原始训练语料。在训练过程中,使用部分数据样例对gpt3进行微调,对于用于训练的数据,将其extracted application description改写为“this application uses permissionpermission to extracted application description”并加以修改调整,最后加入提示中进行训练。我们将以上方法命名为descriper。
[0080]
实验数据:在对8580个应用包及其应用描述、隐私权政策文档进行分析后,共得到了 1006条数据,每条的形式为(permission,call graph texts,user interface texts, referenced privacy policy,extracted application description),本实施例将实验数据划分为训练集和测试集,其中,训练集有274条数据,测试集有732条数据,其关于权限的分布如表2所示:
[0081]
表2实验数据权限分布
[0082]
敏感权限训练集条目数量测试集条目数量总条目数量日历61622相机55134189联系人266389位置50163213麦克风6792159短信41418存储66250316总计2747321006
[0083]
实验参数:本实验基于gpt-3中的davinci预训练模型微调,批次大小为2,学习率为 0.05,训练轮次为4。
[0084]
评价指标:本实施例将生成的句子与目标生成句子的相似度作为生成效果的依据,选用双语替换评测(bilingual evaluation understudy,bleu)和排序明确翻译评估指标(metric forevaluation of translation with explicit ordering,meteor)作为生成效果评价指标。
[0085]
比较方法:根据抽取式等传统方法的单一输入源,本实施例选取了一下三种方法来与本发明的方法比较:
[0086]
descriper_ui,缺少图形界面上下文信息的方法,即只将程序代码上下文和隐私权政策中敏感行为相关句子作为敏感行为信息源的方法;
[0087]
descriper_cg,缺少程序代码上下文信息的方法,即只将图形界面上下文和隐私权政策中敏感行为相关句子作为敏感行为信息源的方法;
[0088]
descriper_pp,缺少隐私权政策中敏感行为相关句子信息的方法,即只将图形界面上下文和程序代码上下文作为敏感行为信息源的方法;
[0089]
实验结果:
[0090]
我们首先将使用了descriper模型的方法直接与这些比较方法进行比较,表3展示了 bleu与meteor的实验结果。我们的方法相比于这些比较方法在两个指标下均有提升。例如相比于实验结果最好的比较方法descriper_pp,在bleu与meteor的值上分别提升了 3.23%-39.17%与1.36%-18.66%。提升主要的原因是应用敏感行为信息源的拓宽与敏感行为信息的丰富,表4列举了一些descriper生成的结果,其中,descriper生成结果列中加粗的单词是指和程序上下文、隐私权政策相关句子中重合的部分。descriper可以充分捕捉和利用多个敏感行为信息源中跟应用敏感行为相关的句子,如对应用il.talent.androminder使用麦克风敏感权限生成的敏感行为描述中的单词分别来自于对程序代码上下文、隐私权政策中敏感行为相关句子和图形界面上下文。
[0091]
此外,我们还尝试对敏感行为的生成目标,即从该移动应用文档中抽取出的敏感行为相关句子和我们生成的描述对比优劣,部分如表5所示。部分生成目标只指出该应用需要申请哪个危险权限组,而我们生成的敏感行为描述在指出权限之外还说明了该用户为什么需要该权限,这也说明了本发明的必要和有效性。
[0092]
表3实验结果
[0093]
[0094]
表4生成结果
[0095][0096]
表5生成目标和生成结果的对比
[0097][0098]
综上所述,使用本发明提供的方法,能够有效生成应用敏感行为描述,帮助弥补用户与应用敏感行为信息间的隔阂。本发明区分考虑了不同的应用程序上下文并同时将与程序上下文与应用敏感行为的联系纳入考虑,解决了应用文档中敏感行为描述普遍缺失的问题,相比现有方法能够极大提升移动应用敏感行为描述的合理性与准确性。有较高的应用价值。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1