一种MODIS地表温度数据产品重建方法
一种modis地表温度数据产品重建方法
技术领域
1.本发明涉及地表温度重塑技术领域,尤其涉及一种modis地表温度数据产品重建方法。
背景技术:
2.地表温度(landsurfacetemperature,lst)是研究地表能量平衡和陆面过程的重要参数,是城市气候变化、植被、生态监测的关键因子,对全球气候变化研究具有重要意义,因modis(moderate-resolutionimagingspectroradiometer)数据具有覆盖范围广、观测周期长等特点,逐渐成为获取lst的重要手段,然而,云和云阴影的存在导致modislst数据产品的时空连续性受到强烈破坏,研究发现,在任何时候都存在大约65%的全球表面被云层覆盖,直接导致热红外遥感影像中存在大面积的缺值,且缺值区各地不等,严重影响了modis地表温度产品的广泛应用,其中我国大陆地区的地表温度年均缺值率最高可达20%,特别是我国西南地区缺值最为严重,导致该区域的modis地表温度数据的可用性降低,因此,modis地表温度数据重建工作具有相当重要的意义。
3.国内外针对modis地表温度重建方法的研究,最初主要包括单一的基于空间信息的重建方法和基于时间信息的重建方法,该类方法主要是利用缺失像元与其相邻晴空像元之间的相关性实现插值,虽然此类方法易于实现,操作简单,但重建过程需要充足的有效像元,对数据质量要求较高,后来逐渐发展了综合时空信息的重建方法,其一般做法是先在时间域上进行补值,然后再在空间域上补值,从而实现数据重建,虽然综合时空信息的方法重建精度高,但该类方法受高时空异质性的影响较大,并且其重建结果受人为干预因素的影响较大,而随着深度学习的出现和发展,基于神经网络的地表温度重建方法也相继被提出,虽然该类方法充分考虑了地表温度的时空异质性,且具有较强的学习能力和鲁棒性,但现有基于深度学习的重建方法大多是根据地表温度与环境变量之间的关系实现模型构建,导致重建模型的精度受训练样本的数量和数值分布的影响较大,模型重建结果的精度得不到保证,因此,本发明提出一种modis地表温度数据产品重建方法以解决现有技术中存在的问题。
技术实现要素:
4.针对上述问题,本发明的目的在于提出一种modis地表温度数据产品重建方法,解决现有modis地表温度重建方法因重建模型的精度受训练样本的数量和数值分布的影响较大而导致模型重建结果的精度得不到保证的问题。
5.为了实现本发明的目的,本发明通过以下技术方案实现:一种modis地表温度数据产品重建方法,包括以下步骤:
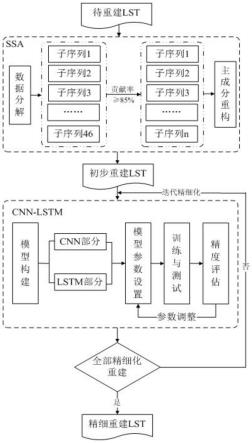
6.步骤一:先利用ssa模型提取地表温度时间序列的主要变化特征,并将提取的主要特征作为补值数据,进行地表温度的初步重建;
7.步骤二:先将地表温度数据的初步重建结果输入cnn-lstm模型,然后cnn部分的卷
积层遍历输入的地表温度信息,通过卷积内核权重与地表温度信息局部序列段进行卷积运算,得到一个特征表达能力强于原始时间序列的初步特征序列,卷积计算之后,平均池化层把最后一个卷积层计算得到的特征序列作为输入,用池化窗口在该序列上滑动,每滑动一次取窗口的平均值进行池化,输出更具表现力的特征序列,最后再用堆叠的lstm模型实现缺值像元的精细重建;
8.步骤三:按照缺值像元的时间先后顺序,利用步骤二中的精细化重建方法对地表温度数据的缺值像元逐一进行精细化重建,同时在重建过程中将上一缺值像元的新值替换初步重建数据,实现数据的更新,再将更新后的数据重新输入cnn-lstm模型中对下一缺值点的地表温度进行精细重建,并不断迭代至完成时间序列中所有缺值像元的重建,得到重建后的地表温度数据。
9.进一步改进在于:所述步骤一中,地表温度的初步重建的具体步骤为:先利用ssa模型对缺值像元的地表温度数据的时间序列进行分解,得到包含不同特征的子序列数据,接着计算分解后各子序列数据的贡献率,并按照从大到小的顺序选择前r个子序列,使选择的子序列的贡献率之和大于等于85%,然后将所选子序列相加组成重构数据,并代替缺值像元的值完成时间序列的更新,实现地表温度时间序列的初步重建。
10.进一步改进在于:所述子序列贡献率计算过程如下:
[0011][0012]
式中,cj表示前j项子序列的贡献率,λr表示特征值。
[0013]
进一步改进在于:所述步骤二中,cnn部分的卷积层提取地表温度数据潜在的特征时,用固定大小的卷积核扫描整个地表温度数据,不同权值的多个卷积核通过卷积运算提取地表温度数据不同方面的不同特征。
[0014]
进一步改进在于:所述步骤二中,卷积核的运算过程如下式所示:
[0015][0016]
式中,为第l层第i个卷积核权重矩阵,x
l-1
为第l-1层输出,为第l层输出的第i个特征,*为卷积运算符,为偏置项。
[0017]
进一步改进在于:所述步骤二中,所述cnn-lstm模型由cnn和lstm网络结构组成,所述cnn网络结构由五个卷积层和一个平均池化层组成,所述lstm网络结构由三个堆叠的lstm网络组成。
[0018]
进一步改进在于:利用cnn-lstm模型中cnn部分的卷积层遍历输入的地表温度信息,用卷积内核权重与地表温度信息局部序列段进行卷积运算,得到一个特征表达能力强于原始时间序列的初步特征序列。
[0019]
进一步改进在于:得到初步特征序列后利用平均池化层将最后一个卷积层计算得到的特征序列作为输入,用池化窗口在该序列上滑动,每滑动一次取窗口的平均值进行池化,输出更具表现力的特征序列,实现对地表温度时间序列的显著时序特征提炼。
[0020]
本发明的有益效果为:本发明基于ssa-cnn-lstm模型重建地表温度数据,不仅能
够排除地表温度高时空异质性的影响,且对有效像元的数量要求不高,通过引入ssa(奇异谱分析)数据分解算法能挖掘出更多的潜在信息,所提取的数据特征也更加丰富,从而为后续地表温度的精细重建奠定数据基础,在原有lstm(长短时记忆网络)的基础上加入了cnn(卷积神经网络),可以实现对地表温度时间序列数据的快速特征提取,挖掘潜在的隐藏信息并去除冗余信息,从而提高lstm模型的预测精度,可以将cnn对特征信息的提取能力与lstm对长期依赖信息的学习能力相互结合,从而进一步提高地表温度的重建精度。
附图说明
[0021]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
[0022]
图1是本发明实施例一的方法流程示意图;
[0023]
图2是本发明实施例二的第一个差值分析对比示意图;
[0024]
图3是本发明实施例二的第一个重建后图像与原始数据的对比示意图;
[0025]
图4是本发明实施例二的第二个差值分析对比示意图;
[0026]
图5是本发明实施例二的第二个重建后图像与原始数据的对比示意图;
[0027]
图6是本发明实施例二的第一个重建前后对比效果示意图;
[0028]
图7是本发明实施例二的第二个重建前后对比效果示意图。
具体实施方式
[0029]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0030]
实施例一
[0031]
参见图1,本实施例提供了一种modis地表温度数据产品重建方法,包括以下步骤:
[0032]
步骤一:先利用ssa模型提取地表温度时间序列的主要变化特征,并将提取的主要特征作为补值数据,进行地表温度的初步重建,地表温度的初步重建的具体步骤为:先利用ssa模型对缺值像元的地表温度数据的时间序列进行分解,得到包含不同特征的子序列数据,接着计算分解后各子序列数据的贡献率,并按照从大到小的顺序选择前r个子序列,使选择的子序列的贡献率之和大于等于85%,然后将所选子序列相加组成重构数据,并代替缺值像元的值完成时间序列的更新,实现地表温度时间序列的初步重建,子序列贡献率计算过程如下:
[0033][0034]
式中,cj表示前h项子序列的贡献率,λr表示特征值;
[0035]
步骤二:先将modis地表温度产品提供的地表温度数据输入cnn-lstm模型,由一维
cnn网络模型中的卷积层通过输入数据与卷积核的运算来提取地表温度数据潜在的特征,并通过卷积核在地表温度时间方向上的滑动进行局部时间段的特征提取,得到一个特征表达能力强于原始时间序列的初步特征序列,提取地表温度数据潜在的特征时,用固定大小的卷积核扫描整个地表温度数据,不同权值的多个卷积核通过卷积运算提取地表温度数据不同方面的不同特征,卷积核的运算过程如下式所示:
[0036][0037]
式中,为第l层第i个卷积核权重矩阵,x
l-1
为第l-1层输出,为第l层输出的第i个特征,*为卷积运算符,为偏置项;
[0038]
在特征提取过程中,第一个卷积层的输出作为第二个卷积层的输入,以此类推,直至完成所有卷积层的运算,卷积计算之后,平均池化层把最后一个卷积层计算得到的特征序列作为输入,用池化窗口在该序列上滑动,每滑动一次取窗口的平均值进行池化,输出更具表现力的特征序列,之后将cnn部分提炼的时序特征作为堆叠lstm部分的输入对缺值像元进行预测,在预测过程中第一层的输出作为第二层的输入,以此类推,从而实现缺值像元的精细化重建;
[0039]
步骤三:按照缺值像元的时间先后顺序,利用步骤二中的精细化重建方法对地表温度数据的缺值像元逐一进行精细化重建,同时在重建过程中将上一缺值像元的新值替换初步重建数据,实现数据的更新,再将更新后的数据重新输入cnn-lstm模型中对下一缺值点的地表温度进行精细重建,并不断迭代至完成所有时间序列中缺值像元的重建,得到重建后的地表温度数据,实现基于ssa-cnn-lstm模型的modis地表温度产品重建。
[0040]
实施例二
[0041]
以2008年新疆和田地区和2020年四川汶川地区为例,采用“去除-重建-对比”的方法分别从时间和空间两个角度对实施例一方法和两种对比方法的重建效果进行对比分析,所用对比方法分别为基于ssa-lstm的地表温度重建方法和基于ssa-bilstm的地表温度重建方法,其次,对实施例一方法的区域适用性以及实际应用效果进行验证。
[0042]
不同重建方法对比:使用“去除-重建-对比”的方法分别对实施例一方法和两种对比方法的重建精度进行分析。首先以新疆和田为研究区,分别对2008年第29期和35期数据在空间上做了抠值处理,其中第29期图像的扣除范围为21
×
21,总计441个像元,第35期图像的扣除范围为26
×
26,总计676个像元。然后使用三种方法分别对两个区域进行重建,并分别从定量和定性两个角度对各种方法的重建效果进行分析(图中的sclstm代表本专利方法ssa-cnn-lstm);
[0043]
(1)定性分析。三种方法重建后的图像与原始数据的对比如图3所示,从图中可以看出实施例一方法对两个区域的重建精度均优于其它两种方法。对于第35期,基于ssa-bilstm的重建结果要稍差一些,重建后图像中存在部分值偏低的现象,实施例一方法和ssa-lstm方法重建后的图像与原始数据的一致性更好。
[0044]
(2)定量分析。为了更加清晰地展现各种方法的重建效果,分别对三种方法在两个子区域上的重建结果与原始数据进行了差值分析,结果如图2所示。首先,对两个子区域缺值像元的重建后结果与原始数据进行了误差统计(见图2(a)和2(b))。从图2(a)中可以看出实施例一方法的重建误差整体较为稳定,其误差基本分布在0~2k之间,没有出现极大值的
情况。而两种对比方法的重建误差波动较大,且最大误差达到了4k以上,极大值点较多。在此基础上,对两个子区域的重建误差的分布区间进行了统计(见图2(b))。从图中可以清楚地看到三种方法的重建误差基本分布在2k以下,而相比之下实施例一方法更优,且实施例一方法重建后误差大于2k的像元数量要少于其余两种方法。此外,使用精度评定指标rmse对三种方法的重建精度进行了对比分析(见图2(c)),从结果中可以看出实施例一方法的重建精度要优于两种对比方法,其rmse最小为0.916k。最后,分别对各种方法的重建效率进行了统计分析(见图2(d)),基于ssa-lstm的重建方法所用时间最少,实施例一方法次之,基于ssa-bilstm的重建方法所用时间最多。总之,对于新疆和田地区,实施例一方法花费的重建时间虽然相比ssa-lstm较多,但是在重建精度上实施例一方法更优。
[0045]
其次,以四川汶川为研究区,分别对2020年第8期和42期数据在空间上做了抠值重建处理,其中第8期扣除范围为21
×
21,总计441个像元,第42期扣除范围为26
×
26,总计676个像元。然后使用三种方法分别对两个区域进行重建,并分别从定量和定性两个角度对各种方法的重建效果进行分析。
[0046]
(1)定性分析。三种方法重建后的图像与原始数据的对比如图5所示,可以看出实施例一方法结果更优。对于2020年第8期的重建结果,实施例一方法重建后的图像与原始数据的纹理信息更一致,基于ssa-bilstm的重建结果存在部分像元偏高或者偏低的现象,基于ssa-lstm方法的重建效果最差,其重建结果整体偏高。对于第42期的重建结果,实施例一方法和ssa-bilstm的重建结果中大部分数值偏低,这可能是由该区域天气突变或者植被覆盖不同所导致的地表温度的不规则变化造成的,而基于ssa-lstm的重建结果整体偏高。
[0047]
(2)定量分析。三种方法在两个子区域上的重建结果与原始数据的差值分析如图4所示。从图4(a)中可以看出实施例一方法的重建误差整体较为稳定,其误差基本分布在0~2k之间。而两种对比方法的重建误差波动较大,其中基于ssa-bilstm的重建误差最大达到了5k以上。通过重建误差分布区间统计图(见图4(b))可以清楚地看到,对于第8期数据三种方法的重建误差基本分布在2k以下,但实施例一方法更优,且实施例一方法重建后误差大于2k的像元数量几乎为0。而对于第42期图像,虽然三种方法的重建误差均普遍增大,但是实施例一方法的重建结果要优于其余两种方法。此外,使用精度评定指标rmse对三种方法的重建精度进行了对比分析(见图4(c)),从结果中可以看出实施例一方法的重建精度要优于两种对比方法,其rmse最小达到了0.7241k。最后,分别对各种方法的重建效率进行了统计分析(见图4(d)),基于ssa-lstm的重建方法所用时间最少,实施例一方法次之,基于ssa-bilstm的重建方法所用时间最多。总之,对于四川汶川地区,由于该区域天气突变或者地表覆盖类型多变会影响数据重建效果,但是通过不同方法之间的对比可以看出实施例一方法的重建效果更优,重建结果的稳定性更好。因此,通过四川汶川地区的模拟重建实验也证明了实施例一方法的区域适用性。
[0048]
基于实施例一方法对2008年新疆和田100*100像元范围内的地表温度进行重建,得到完整的地表温度数据,重建前后对比效果如图6所示,可以看出,实施例一方法可以较好地实现大面积缺值区域地填补,并且重建后效果与实际情况较为一致。此外实施例一方法重建后的地表温度数据并没有出现数值过高或者过低的现象,可见实施例一方法对地表温度数据的整体和细节变化的把握均较好,重建后数据能够表现数据本身的变化特征;
[0049]
基于实施例一方法对2020年四川汶川100*100范围的地表温度进行重建,重建后
效果如图7所示,可以看出实施例一方法在时间和空间上数据缺失量较大的区域均能实现完整的重建,且重建后能够符合实际地表温度的变化情况。
[0050]
通过对实施例一提出的modis地表温度数据产品重建方法进行实例应用,可以得出以下三点结论:
[0051]
在原有lstm的基础上加入cnn所提取的地表温度时间序列的有用信息更多,冗余信息更少,可以实现更准确的预测;
[0052]
实施例一所提方法重建后误差更小,大部分误差分布在2k以下,其rmse最小为0.7241k,且对于不同地区而言,实施例一方法的重建精度稳定性更好,即使是在空间上大面积缺值的缺值区域也能实现地表温度的完整重建;
[0053]
通过实施例一方法在干旱少雨的新疆和田地区和湿润多雨的四川汶川地区的实际应用,证明了实施例一方法的区域适用性。
[0054]
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1