一种基于LSTM算法预测土仓压力的方法
一种基于lstm算法预测土仓压力的方法
技术领域
1.本发明涉及工程掘进技术领域,尤其涉及一种基于lstm算法预测土仓压力的方法。
背景技术:
2.随着我国这些年社会经济的飞快发展,土压平衡盾构机已经成为建设地铁、隧道的最主要施工设备之一。合理的设定土仓压力基准值是施工安全的重要保障。因此,针对预测未来的土仓压力变化显得极为重要,对提高盾构机施工安全、效率具有重要意义。
3.现有采用神经网络算法对土仓压力进行预测的技术,为了追求对预测结果的精准,往往会增大隐含层的层数、神经元的数量,从而导致神经网络预测模型的复杂程度过高,从而出现过拟合问题。同时,由于土压平衡盾构机在掘进过程中,掘进因素众多,存在明显的关联性,上一时刻的参数数据会影响下一时刻的参数,即盾构机掘进数据存在时间序列问题。
4.现有技术中,申请号为cn202011296026.7的一种基于xgboost算法预测盾构机土仓压力的方法,该专利提出了一种基于xgboost算法预测盾构机土仓压力的方法,通过xgboost算法筛掉与土仓压力变化相关性数值小的特征变量,选取与土仓压力变化关联的相关变量作为特征向量;将传感器采集的原始数据经特征提取并进行移位变换分成训练集和验证集;投喂训练集获得初始xgboost回归模型,通过网格搜索方式得到最优模型参数;将验证集中的数据样本输入经参数优化后的xgboost回归模型,得到最优的xgboost土压回归模型;使用xgboost土压回归模型计算出未来时段的土压值。该专利实现了预知盾构掘进施工中土仓压力的变化情况,为预警盾构施工中存在的土压异常及化解潜在的施工安全隐患提供了技术支持,提升盾构掘进施工的安全性。但是,xgboost算法参数过多,调参复杂,且在该算法中训练集必须包括总体,一旦在测试集中出现训练集中从未出现过的特征,模型效果会变差,预测精度降低。
技术实现要素:
5.本发明的目的在于提供一种基于lstm算法预测土仓压力的方法。
6.本发明采用的技术方案是:
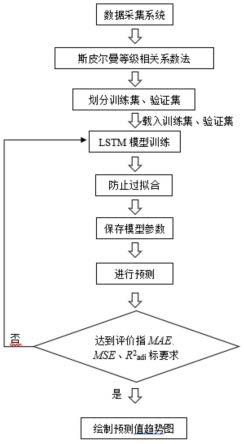
7.一种基于lstm算法预测土仓压力的方法,其包括以下步骤:
8.步骤1:将盾构机数据采集系统得到实时掘进因素数据,分别与土仓压力数据进行斯皮尔曼相关性分析,将斯皮尔曼相关性系数的绝对值按由大至小排序筛选出对土仓压力有相关性影响的因素;
9.步骤2:将筛选出的因素数据随机划分为训练集和测试集;
10.步骤3:将训练集数据作为输入得到lstm训练模型,使用dropout及early stopping方法防止出现过拟合现象,通过随机梯度下降法得到最优模型参数并以pth文件形式保存;
11.步骤4:将测试集数据作为输入,加载保存的最优模型参数得到预测数据,并对其预测性能进行评估。
12.步骤5:lstm预测模型对土压平衡盾构机土仓压力预测:将步骤一筛选出的因素作为美时刻的输入,加载步骤三中保存的模型文件,计算出未来时刻的土仓压力数值。
13.进一步地,步骤1中斯皮尔曼相关性分析计算公式为:
[0014][0015]
式中,ri和si分别是观测值i的取值等级;分别是变量x和y的平均等级;n是观测值的总数。
[0016]
具体地,举例而言,斯皮尔曼相关系数值r介于-1~1之间,-1~0之间为负相关,0~1之间为正相关。其中,相关性系数的绝对值|r|越大,代表两因素间的相关性越强,由此得到本发明中与土仓压力存在相关关系的因素依次为:总推力、螺旋机转速、推进速度、刀盘转速、刀盘扭矩、b组推进压力、泡沫系统平均压力、封前仓盾尾密封平均压力、封后仓盾尾密封平均压力、螺旋机油温、a组铰接油缸行程、c组铰接油缸行程。
[0017]
进一步地,步骤2通过sklearn算法工具包中的train_test_split()算法函数将筛选出的因素数据随机划分为训练集和测试集,减少人为因素对土仓压力预测结果的影响。
[0018]
进一步地,步骤3中lstm模型为基于循环神经网络具有的短期记忆功能的基础上通过门控机制建立长时间间隔的状态之间的依赖关系;lstm预测模型的计算过程为:利用上一时刻的外部状态h
t-1
和当前时刻的输入x
t
,计算三个门以及候选状态g
t
,并结合遗忘门f
t
和输入门o
t
来更新记忆单元c
t
,最后通过输出门o
t
,将内部状态的信息传递给外部状态h
t
,即lstm引入一个新的内部状态c
t
专门对循环信息传递,同时输出信息给隐含层的外部状态h
t
,具体的表达式如下:
[0019][0020]
其中,f
t
为遗忘门,用来控制上一时刻的内部状态c
t-1
需要遗忘的信息;i
t
为输入门,控制当前时刻的候选状态g
t
需要保存的信息;o
t
为输出门,控制当前时刻内部状态c
t
有多少信息需要输出给外部状态h
t
;tanh为双曲正切函数,其输出区间为(-1,1)。
[0021]
三个门的计算公式分别为:
[0022][0023]
式中,σ为logistic函数,其输出区间为(0,1);x
t
为当前时刻的输入;w
if
、b
if
、w
ii
、b
ii
、w
ig
、b
ig
、w
io
、b
io
分别是对于x
t
的线性变换参数矩阵;w
hf
、b
hf
、w
hi
、b
hi
、w
hg
、b
hg
、w
ho
、b
ho
是对于h
t-1
做线性变换的参数矩阵。
[0024]
进一步地,步骤3中dropout是指在深度学习的训练过程中随机丢弃一部分神经元来避免过拟合,以一个概率为p的伯努利分布随机生成与节点数量相同的丢弃掩码,将这些丢弃掩码与输入相乘后的部分节点屏蔽,在利用剩下的节点做后续计算;
[0025]
early stopping是在训练中计算模型参数在测试集上的表现,当模型参数在测试集上的预测精度开始下降时即停止训练,从而避免继续训练导致的过拟合问题。
[0026]
进一步地,步骤3中采用如下方法确定最优模型参数;
[0027]
步骤3-1,基于预测值与实际值计算得到绝对系数r2,计算公式如下;
[0028][0029]
其中,为预测值,yi为实际值;
[0030]
步骤3-2,绝对系数r2计算得到校正后的评价模型优劣,以消除由因素数量不同对评价指标造成的影响;
[0031][0032]
其中,n为样本数量;为均值;p为特征数量;
[0033]
步骤3-3,判断当前的校正的r
2adj
的值与1的差值是否小于最优的校正r
2adj
值与1的差值;是则,以当前的校正的r
2adj
的值作为最优的校正r
2adj
值,并将对应的模型参数作为模型的最优参数;否则,维持最优的校正r
2adj
值及模型的最优参数不变;
[0034]
步骤3-4,最优校正的r
2adj
的值与1的差值是否小于设定值;是则,结束训练将最优模型参数并以pth文件形式保存;否则,进行下一次训练。
[0035]
具体地,平均绝对误差mae能够反映预测值与实际值间误差实际情况,其值越小,表明预测模型准确描述数据的能力越好;均方误差mse常用来评价数据的变化程度,其值越小,表明预测模型准确描述数据的能力越好。由于本发明预测模型的输入维度是随着影响因素的个数而增加,故采用校正的r
2adj
来评价模型优劣更有意义,其值越接近1,表明预测模型准确描述数据的能力越好。
[0036][0037][0038][0039]
式中,n为样本数量;为预测值;yi为实际值;为均值;p为特征数量。
[0040]
进一步地,还包括步骤6,基于计算出的未来时刻的土仓压力数值绘制预测值趋势图。
[0041]
本发明采用以上技术方案,本发明与现有技术相比,具有如下优点:(1)采用了专门针对时间序列问题的lstm算法进行模型训练、预测,不仅考虑了输入数据的特征维度,同时还考虑到特征的时间维度对土仓压力的影响,提高了预测精度。(2)由于地质环境复杂多变,土压平衡盾构机在掘进过程中掘进因素众多,造成土仓压力波动的相关性程度不等,本发明采用斯皮尔曼等级相关系数方法对掘进因素进行筛选,剔除与土仓压力具有极弱相关程度的掘进因素,将剩下的掘进因素作为特征维度,最大程度的保留原始数据中蕴含的信息,提高预测精度。(3)本发明通过未来土仓压力的预测,让盾构司机及监控人员可以提前
知晓下一时刻土仓压力的变化情况,进而可以对可能存在的土压失衡做出及时的调整,保证施工安全。(4)本发明考虑了神经网络预测中存在的过拟合问题,提高了预测精度。
附图说明
[0042]
以下结合附图和具体实施方式对本发明做进一步详细说明;
[0043]
图1为本发明lstm结构示意图;
[0044]
图2为本发明一种基于lstm算法预测土仓压力的方法的流程示意图;
[0045]
图3为本发明斯皮尔曼相关性分析结果图;
[0046]
图4为本发明福州地铁四号线427环土仓压力实际值与预测值对比图;
[0047]
图5为本发明基于计算出的未来时刻的土仓压力数值绘制预测值趋势图。
具体实施方式
[0048]
为使本技术实施例的目的、技术方案和优点更加清楚,下面将结合本技术实施例中的附图对本技术实施例中的技术方案进行清楚、完整地描述。
[0049]
针对在盾构机掘进过程中的大量掘进因素数据,尽可能筛选出对土仓压力存在相关性的所有因素,并为了防止在预测过程中出现过拟合问题,在lstm预测模型中加入dropout及early stopping算法,使用pytorch深度学习框架建立动态神经网络,提出一套对土仓压力精准预测的方法。本发明填补市场中对土仓压力的预测的同时,由于盾构机施工情况的复杂性,建立数学模型等存在一定难度,本发明利用lstm神经网络,能够模拟目前已知以及其他未知的所有情况,充分分析原始数据中蕴含的已知及未知的规律,并使用dropout及early stopping算法防止出现过拟合现象,最后采用平均绝对误差mae、均方误差mse、校正后的r
2adj
作为评价指标,提高土仓压力预测的精度和准确度。
[0050]
如图1至图5之一所示,本发明公开了一种基于lstm算法预测土仓压力的方法,其包括以下步骤:
[0051]
步骤1:将盾构机数据采集系统得到实时掘进因素数据,分别与土仓压力数据进行斯皮尔曼相关性分析,将斯皮尔曼相关性系数的绝对值按由大至小排序筛选出对土仓压力有相关性影响的因素;
[0052]
步骤2:将筛选出的因素数据随机划分为训练集和测试集;
[0053]
步骤3:将训练集数据作为输入得到如图1所示的lstm训练模型,为常规技术,本领域技术人员可以简单直接的得到该结构,使用dropout及early stopping方法防止出现过拟合现象,通过随机梯度下降法得到最优模型参数并以pth文件形式保存;
[0054]
步骤4:将测试集数据作为输入,加载保存的最优模型参数得到预测数据,并对其预测性能进行评估。
[0055]
步骤5:lstm预测模型对土压平衡盾构机土仓压力预测:将步骤一筛选出的因素作为美时刻的输入,加载步骤三中保存的模型文件,计算出未来时刻的土仓压力数值。
[0056]
进一步地,还包括步骤6,基于计算出的未来时刻的土仓压力数值绘制预测值趋势图。
[0057]
进一步地,步骤1中斯皮尔曼相关性分析计算公式为:
[0058][0059]
式中,ri和si分别是观测值i的取值等级;分别是变量x和y的平均等级;n是观测值的总数。
[0060]
具体地,为了更好的说明本发明,以福建省福州市在建的地铁四号线407~427环的数据作为研究对象,总计20环,2579组数据,31个掘进因素,全部因素见表1。
[0061]
经斯皮尔曼等级相关系数方法求得31个盾构机掘进因素与土仓压力之间的相关关系,结果见表1、图3所示。斯皮尔曼相关系数值r介于-1~1之间,-1~0之间为负相关,0~1之间为正相关。其中,相关性系数的绝对值|r|越大,代表两因素间的相关性越强,由此得到与土仓压力存在相关关系的因素依次为:总推力、螺旋机转速、推进速度、刀盘转速、刀盘扭矩、b组推进压力、泡沫系统平均压力、封前仓盾尾密封平均压力、封后仓盾尾密封平均压力、螺旋机油温、a组铰接油缸行程、c组铰接油缸行程。
[0062]
表1掘进因素列表
[0063]
[0064][0065]
将以上因素作为lstm的输入数据,将407~426环数据划分为训练集来预测427环的土仓压力,预测结果见图4所示。结果表明,lstm预测出来的土仓压力趋势与实际值几乎一致,证明了本发明的预测精度。
[0066]
进一步地,步骤2通过sklearn算法工具包中的train_test_split()算法函数将筛选出的因素数据随机划分为训练集和测试集,减少人为因素对土仓压力预测结果的影响。
[0067]
进一步地,步骤3中lstm模型为基于循环神经网络具有的短期记忆功能的基础上通过门控机制建立长时间间隔的状态之间的依赖关系;lstm预测模型的计算过程为:利用上一时刻的外部状态h
t-1
和当前时刻的输入x
t
,计算三个门以及候选状态g
t
,并结合遗忘门f
t
和输入门o
t
来更新记忆单元c
t
,最后通过输出门o
t
,将内部状态的信息传递给外部状态h
t
,即lstm引入一个新的内部状态c
t
专门对循环信息传递,同时输出信息给隐含层的外部状态h
t
,具体的表达式如下:
[0068][0069]
其中,f
t
为遗忘门,用来控制上一时刻的内部状态c
t-1
需要遗忘的信息;i
t
为输入门,控制当前时刻的候选状态g
t
需要保存的信息;o
t
为输出门,控制当前时刻内部状态c
t
有多少信息需要输出给外部状态h
t
;tanh为双曲正切函数,其输出区间为(-1,1)。
[0070]
三个门的计算公式分别为:
[0071][0072]
式中,σ为logistic函数,其输出区间为(0,1);x
t
为当前时刻的输入;w
if
、b
if
、w
ii
、b
ii
、w
ig
、b
ig
、w
io
、b
io
分别是对于x
t
的线性变换参数矩阵;w
hf
、b
hf
、w
hi
、b
hi
、w
hg
、b
hg
、w
ho
、b
ho
是对于h
t-1
做线性变换的参数矩阵。
[0073]
进一步地,步骤3中dropout是指在深度学习的训练过程中随机丢弃一部分神经元来避免过拟合,以一个概率为p的伯努利分布随机生成与节点数量相同的丢弃掩码,将这些丢弃掩码与输入相乘后的部分节点屏蔽,在利用剩下的节点做后续计算;
[0074]
early stopping是在训练中计算模型参数在测试集上的表现,当模型参数在测试集上的预测精度开始下降时即停止训练,从而避免继续训练导致的过拟合问题。
[0075]
进一步地,步骤3中采用如下方法确定最优模型参数;
[0076]
步骤3-1,基于预测值与实际值计算得到绝对系数r2,计算公式如下;
[0077][0078]
其中,为预测值,yi为实际值;
[0079]
步骤3-2,绝对系数r2计算得到校正后的评价模型优劣,以消除由因素数量不同对评价指标造成的影响;
[0080][0081]
其中,n为样本数量;为均值;p为特征数量;
[0082]
步骤3-3,判断当前的校正的r
2adj
的值与1的差值是否小于最优的校正r
2adj
值与1的差值;是则,以当前的校正的r
2adj
的值作为最优的校正r
2adj
值,并将对应的模型参数作为模型的最优参数;否则,维持最优的校正r
2adj
值及模型的最优参数不变;
[0083]
步骤3-4,最优校正的r
2adj
的值与1的差值是否小于设定值;是则,结束训练将最优模型参数并以pth文件形式保存;否则,进行下一次训练。
[0084]
具体地,平均绝对误差mae能够反映预测值与实际值间误差实际情况,其值越小,表明预测模型准确描述数据的能力越好;均方误差mse常用来评价数据的变化程度,其值越小,表明预测模型准确描述数据的能力越好。由于本发明预测模型的输入维度是随着影响因素的个数而增加,故采用校正的r
2adj
来评价模型优劣更有意义,其值越接近1,表明预测模型准确描述数据的能力越好。
[0085][0086][0087][0088]
式中,n为样本数量;为预测值;yi为实际值;为均值;p为特征数量。
[0089]
由于土压平衡盾构机工作环境的复杂性,步骤1中与土仓压力相关的因素数量会发生变化,r2会随因素的数量增加而不断增大,因此使用校正后的评价模型优劣;注:r
2adj
是在绝对系数r2的基础上,为了消除因为因素数量不同而对评价指标造成的影响。
[0090]
本发明采用以上技术方案,使用斯皮尔曼等级相关系数方法筛选出所有与土仓压力存在显著关系的影响因素,从而提高预测精度。使用lstm神经网络,能够记忆所有输入数据的信息,充分考虑过去掘进参数对未来掘进参数的影响,进一步提高预测精度。使用dropout及early stopping算法防止预测模型出现过拟合现象。使用pytorch深度学习框架搭建预测模型,加速神经网络中的矩阵相乘。
[0091]
本发明采用了专门针对时间序列问题的lstm算法进行模型训练、预测,不仅考虑了输入数据的特征维度,同时还考虑到特征的时间维度对土仓压力的影响,提高了预测精度。由于地质环境复杂多变,土压平衡盾构机在掘进过程中掘进因素众多,造成土仓压力波动的相关性程度不等,本发明采用斯皮尔曼等级相关系数方法对掘进因素进行筛选,剔除与土仓压力具有极弱相关程度的掘进因素,将剩下的掘进因素作为特征维度,最大程度的保留原始数据中蕴含的信息,提高预测精度。本发明通过未来土仓压力的预测,让盾构司机及监控人员可以提前知晓下一时刻土仓压力的变化情况,进而可以对可能存在的土压失衡做出及时的调整,保证施工安全。本发明考虑了神经网络预测中存在的过拟合问题,提高了预测精度。
[0092]
显然,所描述的实施例是本技术一部分实施例,而不是全部的实施例。在不冲突的情况下,本技术中的实施例及实施例中的特征可以相互组合。通常在此处附图中描述和示出的本技术实施例的组件可以以各种不同的配置来布置和设计。因此,本技术的实施例的详细描述并非旨在限制要求保护的本技术的范围,而是仅仅表示本技术的选定实施例。基于本技术中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1