基于NetCDF的多源异构海洋环境数据集成方法
基于netcdf的多源异构海洋环境数据集成方法
技术领域
1.本技术属于海洋环境数据集成方法技术领域,尤其涉及一种基于netcdf的多源异构海洋环境数据集成方法。
背景技术:
2.netcdf是一种面向数组并适于网络共享的数据描述和编码标准,广泛应用于大气、水文、海洋等诸多领域。netcdf是海洋环境数据文件的主要存储文件格式之一,具有自描述性、可移植性和可扩展性,多数海洋环境数据源都提供netcdf数据文件下载或提供可转换为netcdf格式的兼容数据文件。由于缺乏规范的数据存储标准,传统的netcdf多源异构海洋环境数据集成主要通过人工进行,首先批量下载数据文件或者数据源,然后对数据文件按照来源和类别进行归类,接下来对每一类数据文件内容进行人工解析并编写定制的数据变量抽取脚本程序,最后通过程序实现数据内容导入。整个过程需要人工参与,既耗时费力且可复用性低,制约了大规模多源异构海洋环境数据的集成。
技术实现要素:
3.本技术的目的在于,针对现有技术的问题,提供一种基于netcdf的多源异构海洋环境数据集成方法,利用海洋环境数据netcdf文件中提取文件元数据,基于预训练文本分类模型、命名实体识别技术,通过解析海洋环境数据的时间维、空间维,进而获取数据变量;最后基于预定义统一时空网格,将数据存入海洋环境数据库,实现netcdf数据自动识别和抽取,提高大规模海洋环境数据集成的效率。
4.为实现上述目的,本技术采用如下技术方案。
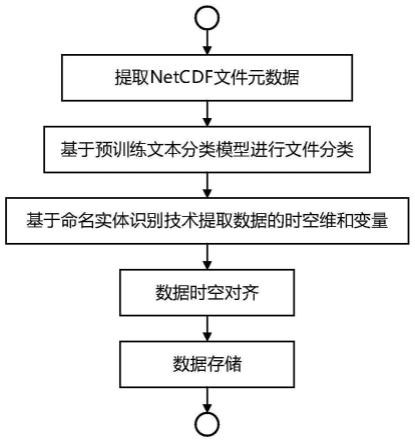
5.一种基于netcdf的多源异构海洋环境数据集成方法,包括如下步骤:
6.步骤(1)提取netcdf文件元数据
7.从netcdf源文件中读取元数据,将文件名和全局属性字段保存为海洋环境数据摘要文本文件,将维度相关信息字段保存为维度文本文件,将变量相关信息字段保存为变量文本文件;
8.步骤(2)基于预训练文本分类模型进行文件分类
9.使用预训练文本分类模型对海洋环境数据摘要文本文件进行分类,输出netcdf文件的数据类型;
10.步骤(3)基于命名实体识别技术提取数据的时空维名称及范围
11.将海洋环境数据摘要文本文件和维度文本文件作为输入,基于netcdf文件数据类型所对应的词典进行命名实体识别,提取出netcdf文件的时间维和空间维的名称和时空范围;
12.步骤(4)基于字符串模式匹配方法识别并提取数据变量
13.将变量文本文件和时空维名称作为输入,基于字符串模式匹配方法识别出netcdf文件的数据变量名称和维度顺序,然后从netcdf文件中读取数据变量;
14.步骤(5)基于预定义网格进行数据时空对齐
15.通过插值的方法,将数据变量的时空网格与预定义数据时空网格进行对齐,计算数据变量的时空网格与预定义时空网格重叠区域内预定义时空网格的各格点处的数值;
16.步骤(6)数据存储入库
17.将时空对齐的海洋环境数据存入数据库并建立数据索引,根据实际业务场景,数据库使用关系数据库或非关系数据库。
18.对前述基于netcdf的多源异构海洋环境数据集成方法的进一步补充和完善,所述全局属性字段包括netcdf文件的global attributes全局属性标签下的所有自定义字段;
19.所述维度相关信息字段包括netcdf文件的dimensions维度标签下的所有自定义字段;
20.所述变量相关信息字段包括netcdf文件的variables变量标签下的所有自定义字段。
21.对前述基于netcdf的多源异构海洋环境数据集成方法的进一步补充和完善,所述步骤(2)具体包括
22.b1收集用于训练的netcdf中的海洋环境数据摘要文本文件;
23.b2根据netcdf文件的数据类型进行分类;
24.b2按照预设比例将分类数据分成训练集、验证集和测试集三个部分
25.b3将海洋环境数据摘要文本文件作为输入,使用预训练文本分类模型进行分类,输出netcdf文件的数据类型。
26.对前述基于netcdf的多源异构海洋环境数据集成方法的进一步补充和完善,所述预训练文本分类模型是指bert模型;
27.所述netcdf文件的数据类型包括:海浪数据类、海流数据类、温度数据类、盐度数据类、密度数据类和海面风数据类;
28.在新增数据源或新增数据类别的时候需要重新训练。
29.对前述基于netcdf的多源异构海洋环境数据集成方法的进一步补充和完善,所述步骤(3)具体包括:
30.c1基于不同的netcdf文件的数据类型所涉及的维度名称分别构建字典;
31.c2基于standford corenlp模型,将海洋环境数据摘要文本文件和维度文本作为输入,基于netcdf文件的数据类型所对应的词典进行命名实体识别,
32.c3提取出netcdf文件中时间变量和空间变量的名称,并进一步识别时空维范围及分辨率。
33.对前述基于netcdf的多源异构海洋环境数据集成方法的进一步补充和完善,其中,盐度数据的命名实体字典包括经度、纬度、时间和深度的常用名称和缩写;海浪数据的命名实体字典包括经度、纬度、时间和高度的常用名称和缩写;密度数据的命名实体字典包括经度、纬度、时间和深度的常用名称和缩写;海面风数据的命名实体字典包括经度、纬度、时间和方向的常用名称和缩写;海流数据的命名实体字典包括经度、纬度、时间和方向的常用名称和缩写;温度数据的命名实体字典包括经度、纬度、时间和深度的常用名称和缩写;
34.对前述基于netcdf的多源异构海洋环境数据集成方法的进一步补充和完善,所述步骤(4)具体包括:
35.d1将海洋环境数据变量文本文件和时空维的变量名称作为输入;使用正则表达式技术,基于字符串模式匹配方法识别出netcdf文件的数据变量名称;相当于识别出数组名称、数组维度和每个维度的下标范围。
36.对前述基于netcdf的多源异构海洋环境数据集成方法的进一步补充和完善,根据环境数据变量时空维度数量以及每个时空维度的范围及分辨率建立对应规模的多维数组,按照各个时空维度的范围及分辨率从netcdf文件中读取数据变量到多维数组。
37.对前述基于netcdf的多源异构海洋环境数据集成方法的进一步补充和完善,所述步骤(5)具体包括:
38.e1建立预定义数据时空网格,用于对齐所有同类型海洋环境数据的数据变量的时间和空间坐标。
39.e2通过插值方法,将数据变量的时间和空间坐标构成的时空网格与预定义数据时空网格的时空坐标进行对齐,所述对齐是指即将数据变量的时空坐标映射到统一的时空坐标,从而使得所集成的数据变量具有相同的时空分辨率;如果数据变量的时空网格坐标系与预定义数据时空网格坐标系不同,则首先需要将数据变量的时空网格坐标系转换为预定义数据时空网格坐标系;
40.e3空间方面,获取当前数据变量的空间网格边界,计算得到网格的各维度的数据范围,数据范围的上界为当前数据变量的空间维度的最小值按照预定义时空网格分辨率取上界,数据范围的上界为当前数据变量的空间维度的最大值按照预定义时空网格分辨率取下界。对属于数据范围的每个网格点,采用k最近距离邻法,根据欧式距离确定距离网格点最近的k个数据,加权平均后计算得到该网格点的数据;
41.e4时间方面,获取当前数据变量的时间区间边界,计算得到时间区间的起点ts、终点te和间隔ti;对于预定义数据时空网格的时间坐标t
p
,如果满足ts≤t
p
≤te,则作为待填充数据区域;对属于待填充数据区域的每个网格点,采用k最近距离邻法,根据欧式距离确定距离网格点最近的k个数据,加权平均后计算得到该网格点的数据。
42.对前述基于netcdf的多源异构海洋环境数据集成方法的进一步补充和完善,所述步骤(6)具体包括:
43.采用postgresql数据库和timescaledb插件的数据存储方案,将时空对齐的海洋环境数据通过timescaledb插件作为时序数据存入postgresql数据库,并建立数据索引。
44.本技术将多源异构海洋环境数据集成到数据库系统,形成统一的海洋环境数据,实现整体上的数据一致性,提高数据共享访问的效率,实现基于netcdf标准的多源异构海洋环境数据集成,提供高质量海洋环境数据服务;netcdf是自描述的通用数据格式,不仅包含数据,还包含即对数据各种属性进行描述的元数据。不同机构不同类型的netcdf元数据具有不同特征,本技术利用预训练语言模型、命名实体识别技术和字符串模板匹配,对netcdf元数据自动分类后进行netcdf数据自动识别和抽取,降低多源异构数据集成过程中的人工数据处理工作量,提高大规模海洋环境数据集成的效率。
附图说明
45.图1是本发明实施例方法的基本流程示意图。
具体实施方式
46.以下结合具体实施例对本技术作详细说明。
47.海洋环境数据种类繁多,包括海浪、海流、温度、盐度、密度和海面风等类型;且来源多样,不仅包括不同的机构、还包括不同的平台或不同的设备。不同类型的海洋环境数据具有不同的存储内容,不同来源的同一类型的海洋环境数据往往具有不同的存储格式。
48.下文将通过实际算例对本发明的技术方案的实施方式进行详细介绍。以从某数据源获取的netcdf文件a9_1_2000m_salinity_year_1950_month_01.nc为例,如图1所示,其基本步骤包括步骤(1)~(6):
49.步骤(1)提取netcdf文件元数据
50.从netcdf源文件中读取元数据,将文件名和全局属性字段保存为海洋环境数据摘要文本文件,将维度相关信息字段保存为维度文本文件,将变量相关信息字段保存为变量文本文件;所述全局属性字段包括netcdf文件的global attributes全局属性标签下的所有自定义字段;所述维度相关信息字段包括netcdf文件的dimensions维度标签下的所有自定义字段;所述变量相关信息字段包括netcdf文件的variables变量标签下的所有自定义字段。
51.具体而言,首先从netcdf文件中读取元数据,然后根据元数据类别分别保存为不同的文本文件。将文件名a9_1_2000m_salinity_year_1950_month_01和所有的全局属性字段,包括title、startyear、startmonth、startday、endyear、endmonth、endday、period等保存为海洋环境数据摘要文本文件summary.txt;将维度相关信息包括lat、lon、time和depth_std保存为维度文本文件dim.txt;将变量相关信息包括变量lat、lon、time和depth_std的size、dimensions、datatype和attributes等保存为变量文本文件var.txt;
52.步骤(2)基于预训练文本分类模型进行文件分类
53.使用预训练文本分类模型对海洋环境数据摘要文本文件进行分类,输出netcdf文件的数据类型;具体步骤包括:
54.b1收集用于训练的netcdf中的海洋环境数据摘要文本文件;
55.b2根据netcdf文件的数据类型进行分类;
56.b2按照预设比例将分类数据分成训练集、验证集和测试集三个部分
57.b3将海洋环境数据摘要文本文件作为输入,使用预训练文本分类模型进行分类,输出netcdf文件的数据类型。
58.本实施例中,预训练文本分类模型选用bert模型,在新增数据源或新增数据类别的时候需要重新训练。当前用于训练的数据集是来自6个数据源的海洋环境数据摘要文本数据集,共包含4730条数据,分为海浪数据、海流数据、温度数据、盐度数据、密度数据和海面风数据共6个类别,将所有数据合并为一个集合后以7:2:1的比例划分成训练集、验证集和测试集三个部分;
59.将海洋环境数据摘要文本文件summary.txt作为输入,使用预训练文本分类模型进行分类,输出分类为盐度数据。
60.步骤(3)基于命名实体识别技术提取数据的时空维名称及范围
61.将海洋环境数据摘要文本文件和维度文本文件作为输入,基于netcdf文件数据类型所对应的词典进行命名实体识别,提取出netcdf文件的时间维和空间维的名称和时空范
围;具体包括:
62.c1基于不同的netcdf文件的数据类型所涉及的维度名称分别构建字典;
63.c2基于standford corenlp模型,将海洋环境数据摘要文本文件和维度文本作为输入,基于netcdf文件的数据类型所对应的词典进行命名实体识别,
64.c3提取出netcdf文件中时间变量和空间变量的名称,并进一步识别时空维范围及分辨率。
65.目标是找到时间和空间的变量在具体的netcdf中的名称,比如在一些文件里的纬度名称叫lat,另外一些文件里的纬度名称却叫latitude或者lat或者lati。
66.本实施例中,命名实体识别模块基于standford corenlp实现,其中字典按照不同的数据类型所涉及的维度名称分别构建,其中,盐度数据的命名实体字典包括经度、纬度、时间和深度的常用名称和缩写;海浪数据的命名实体字典包括经度、纬度、时间和高度的常用名称和缩写;密度数据的命名实体字典包括经度、纬度、时间和深度的常用名称和缩写;海面风数据的命名实体字典包括经度、纬度、时间和方向的常用名称和缩写;海流数据的命名实体字典包括经度、纬度、时间和方向的常用名称和缩写;温度数据的命名实体字典包括经度、纬度、时间和深度的常用名称和缩写;
67.将海洋环境数据摘要文本文件summary.txt和维度文本dim.txt作为输入,基于盐度数据类型所对应的词典进行命名实体识别,提取出netcdf文件的时间维名称为time,时间维范围为1950年1月1日0时起共24个时间点,每个时间点间隔1小时;空间维的纬度名称为lat,维度坐标范围为1到180;空间维的经度名称为lon,经度坐标范围为1到360。
68.步骤(4)基于字符串模式匹配方法识别并提取数据变量
69.将变量文本文件和时空维名称作为输入,基于字符串模式匹配方法识别出netcdf文件的数据变量名称和维度顺序,然后从netcdf文件中读取数据变量;具体包括:将海洋环境数据变量文本文件和时空维名称time、lat和lon作为输入;使用正则表达式技术,基于字符串模式匹配方法识别出netcdf文件的数据变量名称。
70.这里识别出的海洋环境数据多维数组的名称,由于在不同数据中名称并不是固定的,因此根据维度等信息进行识别;具体而言,具体实施时,将海洋环境数据变量文本文件var.txt和时空维名称time、lat和lon作为输入,使用正则表达式技术,基于字符串模式匹配方法识别出netcdf文件的数据变量名称,其中环境数据变量名称为salinity,其维度数量为3,每个维度的数据规模按顺序分别为41、360和180,然后建立规模为41*360*180的三维数组,按照各个维度的规模从netcdf文件中读取数据变量到三维数组。
71.前面识别时空维的名称,这里识别数据变量的名称;海洋环境数据保存在一个多维数组中,数据变量可以看成是这个多维数组的变量名a,而时空维对应的是数组的各个维度的下标名称和范围a[time][lat][lon]。
[0072]
步骤(5)基于预定义网格进行数据时空对齐
[0073]
通过插值的方法,将数据变量的时空网格与预定义数据时空网格进行对齐,计算数据变量的时空网格与预定义时空网格重叠区域内预定义时空网格的各格点处的数值;具体包括:
[0074]
e1通过插值方法,将数据变量的时间和空间坐标构成的时空网格与预定义数据时空网格的时空坐标进行对齐,所述对齐是指即将数据变量的时空坐标映射到统一的时空坐
标,从而使得所集成的数据变量具有相同的时空;如果数据变量的时空网格坐标系与预定义数据时空网格坐标系不同,则首先需要将数据变量的时空网格坐标系转换为预定义数据时空网格坐标系;
[0075]
e2空间方面,获取当前数据变量的空间网格边界,计算得到网格的各维度的数据范围;数据范围的上界为当前数据变量的空间维度的最小值按照预定义时空网格分辨率取上界,数据范围的上界为当前数据变量的空间维度的最大值按照预定义时空网格分辨率取下界。对属于数据范围的每个网格点,采用k最近距离邻法,根据欧式距离确定距离网格点最近的k个数据,加权平均后计算得到该网格点的数据;
[0076]
e3时间方面,获取当前数据变量的时间区间边界,计算得到时间区间的起点ts、终点te和间隔ti;对于预定义数据时空网格的时间坐标t
p
,如果满足ts≤t
p
≤te,则作为待填充数据区域;对属于待填充数据区域的每个网格点,采用k最近距离邻法,根据欧式距离确定距离网格点最近的k个数据,加权平均后计算得到该网格点的数据。
[0077]
如果数据变量的时空网格坐标系与预定义数据时空网格坐标系不同,则首先需要将数据变量的时空网格坐标系转换为预定义数据时空网格坐标系;
[0078]
空间方面,获取当前数据变量的空间网格边界,空间网格包括二维网格和三维网格,以三维网格为例,计算得到三维网格的最小值组合(x
min
,y
min
,z
min
)和最大值组合(x
max
,y
max
,z
max
),其中x
min
和x
max
分别是第一维度的最小值和最大值,y
min
和y
max
分别是第二维度的最小值和最大值,z
min
和z
max
分别是第三维度的最小值和最大值。对于预定义数据时空网格的空间坐标(x
p
,y
p
,z
p
),如果同时满足x
min
≤x
p
≤x
max
,y
min
≤y
p
≤y
max
,z
min
≤z
p
≤z
max
,则作为待填充数据区域。对属于待填充数据区域的每个网格点,采用k最近距离邻法,根据欧式距离确定距离网格点最近的k个数据,加权平均后计算得到该网格点的数据。
[0079]
时间方面,获取当前数据变量的时间区间边界,计算得到时间区间的起点ts、终点te和间隔ti。对于预定义数据时空网格的时间坐标t
p
,如果满足ts≤t
p
≤te,则作为待填充数据区域。对属于待填充数据区域的每个网格点,采用k最近距离邻法,根据欧式距离确定距离网格点最近的k个数据,加权平均后计算得到该网格点的数据。
[0080]
步骤(6)数据存储入库
[0081]
将时空对齐的海洋环境数据存入数据库并建立数据索引,根据实际业务场景,数据库使用关系数据库或非关系数据库。
[0082]
本实施例中,采用postgresql数据库和timescaledb插件的数据存储方案,将时空对齐的海洋环境数据通过timescaledb插件作为时序数据存入postgresql数据库,并建立数据索引。
[0083]
最后应当说明的是,以上实施例仅用以说明本技术的技术方案,而非对本技术保护范围的限制,尽管参照较佳实施例对本技术作了详细地说明,本领域的普通技术人员应当理解,可以对本技术的技术方案进行修改或者等同替换,而不脱离本技术技术方案的实质和范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1