一种在动态场景下的视觉SLAM动态特征点剔除方法及系统
一种在动态场景下的视觉slam动态特征点剔除方法及系统
技术领域
1.本发明属于同步定位与地图构建领域,尤其涉及将摄像头作为主要传感器的同步定位与地图构建。
背景技术:
2.场景静态性的假设极大的限制了传统视觉slam(visual simultaneous localization and mapping,vslam)的发展。现在许多方案都采用了深度学习或者几何约束的方案来处理场景中存在的动态物体,但是这些方案或多或少都存在一些位姿估计精度或者鲁棒性不高的问题。因此本发明提出了一种协同使用语义分割和目标检测的方案来获取场景中的潜在动态物体的先验轮廓信息,这些先验信息就可以辅助几何约束的方案来剔除动态特征点。在公开的数据集上进行了评估测试,实验结果表明本发明的方案在没有效率损失的情况下,可以在高动态场景下提高位姿估计的精度和vslam系统运行的鲁棒性。
技术实现要素:
3.本发明的目的是为了让机器人在动态环境下更加鲁棒更加精确的估计自身的位置姿势。
4.为了实现上述目的,本发明提出的技术方案提供一种在动态场景下的视觉slam动态特征点剔除方法,同时使用语义分割和目标检测实现对动态物体的识别,利用静态点恢复减少损失,最后实现动态点的剔除;
5.实现过程包括以下步骤,
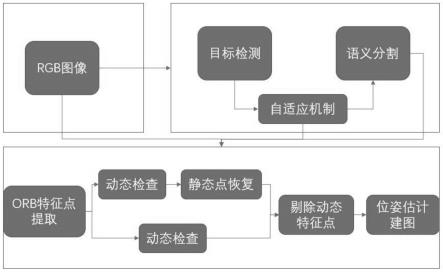
6.s1,利用目标检测处理出rgb图片中的动态部分;
7.s2,使用自适应机制,选择是否使用语义分割来做更精细化的识别;
8.s3,如果只使用目标检测处理rgb图片中的动态部分,则使用目标检测分支进一步处理,该分支使用运动一致性检测和静态点恢复两种策略来剔除动态特征点;如果使用了目标检测和语义分割处理rgb图片中的动态部分,则使用语义分割分支进一步处理,该分支使用运动一致性检测来剔除动态特征点。
9.而且,所述步骤s1)实现方式包括以下子步骤,
10.a)对每一张rgb图像使用yolov4算法进行处理,识别图像中的所有物体;
11.b)保留潜在动态物体的识别结果,潜在动态物体区域相应矩形框的保留格式为(x1,y1,x2,y2,h,w),x1为矩形框左上角的横坐标,y1为矩形框左上角的纵坐标,x2为矩形框右下角的横坐标,y2为矩形框右下角的纵坐标,h为矩形框的高度,w为矩形框的宽度。
12.而且,所述步骤s2实现方式包括以下子步骤,
13.c)计算潜在动态物体区域所占rgb图像的像素点数量,同时计算rgb图像中总的像素点数量,令score为这两个参数的比值;
14.d)如果比值大于等于预设阈值r,则进一步使用语义分割处理图像中的潜在动态物体区域,在步骤s3进行语义分割分支;如果比值小于预设阈值r,则直接进入步骤s3进行
目标检测分支。
15.而且,所述步骤s3实现方式包括以下子步骤,
16.e)提取每个rgb图像中的orb特征点;
17.f)根据步骤s2的判断结果,当进行语义分割分支时,使用动态一致性检测来判断潜在动态物体是否在运动,首先利用光流金字塔计算出几何离群点,如果达到预设数量阈值的几何离群点落在了潜在动态物体轮廓里,则认为该潜在动态物体在运动;否则认定该潜在动态物体保持静止,没有运动;对于正在运动的潜在动态物体,将落在其轮廓里的orb特征点剔除;
18.g)根据步骤s2的判断结果,当进行目标检测分支时,先使用动态一致性检测来判断潜在动态物体是否在运动,然后利用静态点恢复策略将潜在动态物体区域中orb特征点区分成静态orb特征点和动态orb特征点,最后将落在其轮廓里的动态orb特征点剔除。
19.而且,利用静态点恢复策略进行动态orb特征点剔除时,对一张rgb图像中所有的特征点分成两部分,第一部分是目标检测框外的特征点,第二部分是目标检测框内的特征点;计算第一部分中所有静态点对之间的平均距离作为静态特征点的阈值,用第一部分中所有的静态特征点,对第二部分中所有不确定点进行投票,包括根据阈值计算针对一个不确定点k的动态得分,如果超过一半的静态特征点都认为不确定点k是动态特征点,那么认定其为动态特征点并移除,否则保留该点。
20.另一方面,本发明提供一种在动态场景下的视觉slam动态特征点剔除系统,用于实现如上所述的一种在动态场景下的视觉slam动态特征点剔除方法。
21.而且,包括处理器和存储器,存储器用于存储程序指令,处理器用于调用存储器中的存储指令执行如上所述的一种在动态场景下的视觉slam动态特征点剔除方法。
22.或者,包括可读存储介质,所述可读存储介质上存储有计算机程序,所述计算机程序执行时,实现如上所述的一种在动态场景下的视觉slam动态特征点剔除方法。
23.本发明方案实施简单方便,实用性强,解决了相关技术存在的实用性低及实际应用不便的问题,能够提高用户体验,具有重要的市场价值。采用本发明所述方案,与现有技术相比,只需要增加有限的时间开销,就可以大幅度的提升机器人位姿估计的精度以及vslam系统运行时的鲁棒性。
附图说明
24.图1是本发明实施例的目标检测结果示意图。
25.图2是本发明实施例的静态点恢复策略示意图。
26.图3是本发明实施例的精度提升示意图。
27.图4是本发明实施例的时间效率提升示意图。
具体实施方式
28.以下结合附图和实施例具体说明本发明的技术方案。
29.本发明实施例提供一种动态场景下的视觉slam动态特征点剔除方法,实现协同使用目标检测和语义分割两种深度学习模型实现对动态物体的识别,来获取潜在物体先验轮廓,有了潜在物体的先验信息,然后利用静态点恢复的方法减少了可用静态点的损失,再使
用几何方案来协助移除动态特征点。这样就可以移除场景中动态物体轮廓中的动态特征点,也就减小了移动的物体对于机器人自身位姿估计的影响。实现过程包括以下步骤,包括:
30.s1:利用目标检测处理出rgb图片中的动态部分。
31.s2:使用自适应机制,选择是否使用语义分割来做更精细化的识别。
32.s3:如果只使用目标检测处理rgb图片中的动态部分,则使用目标检测分支进一步处理,该分支使用运动一致性检测和静态点恢复两种策略来剔除动态特征点;如果使用了目标检测和语义分割处理rgb图片中的动态部分,则使用语义分割分支进一步处理,该分支使用运动一致性检测来剔除动态特征点。
33.本发明实施例所设计的动态点剔除框架分为三大部分,如附图1所示,第一部分是图片的输入,本发明用到了rgb图像;第二部分是语义信息的提取,本发明使用了语义分割和目标检测两种语义获取的方法,在不同动态场景下可以切换使用不同的模型,用于加快vslam系统运行速度以及提供vslam系统运行的鲁棒性,即该部分实现步骤s1和s2。第三部分是动态点剔除,首先将上一步传来的含有语义信息的rgb图像提取出orb特征点,然后根据语义信息的类型,交给不同的分支去处理。
34.本发明实施例步骤s1中语义信息提取部分目标检测时,优选的流程为:
35.h)对每一张rgb图像使用yolov4算法进行处理,识别图像中的所有物体(人、桌子、椅子、显示器、鼠标等等)。
36.i)保留潜在动态物体(本发明把人当做潜在的动态物体)的识别结果,具体实施时可以采用不同颜色框进行标识,例如紫色矩形框代表识别的对象是人,亮黄色矩形框代表识别的对象是椅子,以此类推,一种颜色与一个物体对应。潜在动态物体区域(矩形框)的保留格式为(x1,y1,x2,y2,h,w),各个参数的含义依次是,x1-矩形框左上角的横坐标,y1-矩形框左上角的纵坐标,x2-矩形框右下角的横坐标,y2-矩形框右下角的纵坐标,h-矩形框的高度,w-矩形框的宽度。
37.本发明实施例步骤s2中语义信息提取部分自适应机制的处理实现优选流程为:
38.j)计算潜在动态物体区域(矩形框)所占rgb图像的像素点数量,同时计算rgb图像中总的像素点数量,令分数score为这两个参数的比值,计算方式如下
[0039][0040]
其中(u,v)代表图像中的一个像素点,f(u,v)是示性函数,如果该像素属于潜在动态物体区域,则该值为1,否则该值为0;pi是当前图像中像素点的数量。
[0041]
k)实施例基于多个实验的结果为动态场景下预先设置了阈值r,用以区分使用语义分割和目标检测的场景,具体实施时可根据具体情况进行r取值设置。如果比值大于等于阈值r,则意味着动态物体占据更大的视野。在这种情况下,使用语义分割会更好,潜在动态物体的边缘将在语义掩码中得到更精确的处理,因此可以保留较多场景中的静态特征点。所以进一步使用语义分割处理图像中的潜在动态物体区域,在步骤s3进行语义分割分支。如果比值低于阈值r,则意味着场景中动态物体所占的视野较小,因此可以剔除目标检测框(矩形框)内的大多数特征点,可以直接使用目标检测的结果进入下一步骤s3进行目标检测分支。
[0042]
本发明实施例步骤s3中进一步提出的动态特征点剔除流程为:
[0043]
l)提取每个rgb图像中的orb特征点;orb(oriented fast and rotated brief)是一种快速特征点提取和描述的算法,本发明不予赘述。
[0044]
m)语义分割分支中,使用动态一致性检测来判断潜在动态物体是否在运动,实现方式包括首先利用光流金字塔计算出几何离群点,如果有达到预设数量阈值的几何离群点落在了潜在动态物体轮廓里(一般建议有10个几何离群点落在动态物体轮廓,即认定其在运动,具体实施时可根据具体情况进行设置),则认为该潜在动态物体在运动;否则认定该潜在动态物体保持静止,没有运动。对于正在运动的潜在动态物体,将落在其轮廓里的orb特征点剔除。
[0045]
n)目标检测分支中,先使用动态一致性检测来判断潜在动态物体是否在运动,实现方式和语义分割分支中一致,然后利用静态点恢复策略将潜在动态物体区域(矩形框)中orb特征点区分成静态orb特征点和动态orb特征点,最后将落在其轮廓里的动态orb特征点剔除。
[0046]
本发明的关键点在于提出了静态点恢复策略,可以减少场景中可用静态点的损失。前面的步骤中,本发明获得了一张rgb图像中所有的特征点,在目标检测分支中,本发明将这些特征点分成两部分,第一部分是目标检测框外的特征点,第二部分是目标检测框内的特征点。本发明会保留第一部分的特征点,因为这些是静态点。本发明只需要关注第二部分的特征点,这部分包括静态特征点和动态特征点。本发明的目标,在剔除动态特征点的同时,尽可能的保留静态特征点。如附图2所示,针对时间t-1对应的图像帧中第i个特征点和第j个特征点以及时间t对应的图像帧中与它们匹配的特征点和本发明用欧氏距离来衡量同一帧上两个不同特征点之间的距离
[0047][0048][0049]
其中,u,v代表水平坐标和横坐标,下标t-1和t分别代表t-1和t时刻,为特征点的坐标,为特征点的坐标,为特征点的坐标,为特征点的坐标。如果这两个特征点都属于静态特征点,那么相邻两帧的特征点对之间的距离差值e
i,j,t
会在一个确定的范围内,本发明称之为线段约束,计算方式如下
[0050]ei,j,t
=|d(i
t
,j
t
)-d(i
t-1
,j
t-1
)|
[0051]
本发明计算第一部分中所有静态点对之间的平均距离,将这个值作为静态特征点的阈值φ
t
,计算方式如下:
[0052][0053]
其中,s代表时间t对应的图像帧中第一部分中所有静态点对的数量,n
t
是时间t对应的图像帧中静态特征点的数量,t为时间点数量。
[0054]
自然地,考虑使用线段约束,本发明选取第一部分中的静态特征点i作为线段的一
端,另一端选择第二部分中的不确定特征点k。这样,本发明就可以用一个已知点来对另一个未知点进行区分。如果e
i,k,t
≤φ
t
,那么不确定特征点k被特征点i认为是静态特征点,否则特征点i认为它是动态点,并且不确定特征点k的动态得分加1,考虑到静态点可能存在的误差,本发明用第一部分中所有的静态点,对第二部分中所有不确定点进行投票,针对一个不确定特征点k的动态得分s
k,t
计算方式如下:
[0055][0056]
其中,n是特征点数目,是示性函数,如果e
i,k,t
≤φ
t
,那么该函数的值为0,否则该函数的值为1。
[0057]
如果超过一半的静态特征点都认为不确定点k是动态特征点,那么本发明认定其为动态特征点并移除它,否则,本发明保留该特征点。
[0058]
为便于实施参考起见,提供本发明实施例方法的实验细节说明如下:
[0059]
实验环境配置
[0060][0061]
模型选择
[0062]
本发明实施例采用了两种语义分割模型,一种是轻量级的语义分割网络segnet,另一种是高精度的语义分割模型deeplabv3,两种模型都是在pascal voc2012数据集上训练。针对目标检测,本发明采用了在pascal voc2012数据集上训练的yolov4模型。
[0063][0064][0065]
方案对比
[0066]
本发明实施例设计了四种方案来对比。
[0067]
方案一,只使用轻量级的语义分割模型来剔除动态特征点(ds-slam所采用的方案);
[0068]
方案二:只使用高精度的语义分割模型来剔除动态特征点;
[0069]
方案三:只使用目标检测模型剔除动态特征点;
[0070]
方案四:协同使用语义分割和目标检测来剔除动态特征点。
[0071]
数据集
[0072]
本发明选择在公开的tum-rgbd数据集上评估本发明提出的方案,使用绝对轨迹误差(absolutely trajectory error,ate)和相对位姿误差(relative pose error)来量化结果。选中的5个数据集如下表所示
[0073][0074]
实验结果分析
[0075]
实验结果如附图3或4所示,可以看出方案二采用高精度的语义分割模型来辅助动态特征点的剔除的确可以提升位姿估计的精度,但是需要消耗更多的时间。方案三仅仅使用目标检测来辅助动态特征点的剔除在其中4个数据集上都有较好的表现,但是当动态物体占据画面比例较大时,会出现长时间的跟踪失败,导致机器人无法算出当前场景下自身的位姿。本发明提出的协同使用目标检测和语义分割来辅助动态特征点的剔除,可以很好的权衡位姿估计的精度和时间效率,本发明提出的方案和方案二的精度很接近,但是时间成本远远小于方案二,因为本发明的自适应机制可以让系统在语义分割分支和目标检测分支自主切换,避免了因动态物体占比过大而造成的跟踪失败。需要说明的是,在低动态数据集,例如fr3_sitting_static和fr3_walking_static,几种方案在这两个数据集上的位姿估计精度已经达到0.001m级别,误差已经很小了,所以精度提升不明显。
[0076]
具体实施时,本发明技术方案提出的方法可由本领域技术人员采用计算机软件技术实现自动运行流程,实现方法的系统装置例如存储本发明技术方案相应计算机程序的计算机可读存储介质以及包括运行相应计算机程序的计算机设备,也应当在本发明的保护范围内。
[0077]
在一些可能的实施例中,提供一种在动态场景下的视觉slam动态特征点剔除系统,包括处理器和存储器,存储器用于存储程序指令,处理器用于调用存储器中的存储指令执行如上所述的一种在动态场景下的视觉slam动态特征点剔除方法。
[0078]
在一些可能的实施例中,提供一种在动态场景下的视觉slam动态特征点剔除系统,包括可读存储介质,所述可读存储介质上存储有计算机程序,所述计算机程序执行时,实现如上所述的一种在动态场景下的视觉slam动态特征点剔除方法。
[0079]
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1