文本信息处理模型训练方法、装置、以及存储介质与流程
本发明涉及文本信息处理技术,尤其涉及文本信息处理模型训练方法、文本信息处理方法、装置、电子设备、软件程序以及存储介质。
背景技术:
1、文本信息处理的过程中,由于文本内容领域跨度大,所使用的文本信息分类的技术主要是基于长短期记忆网络(lstm,long short-term memory),但若是文本信息较长,此种方法会损失到大量的关键信息,从而导致最后分类的效果较差;另外一种常用的技术是使用卷积神经网络(cnn,convolutional neural networks),使用cnn时由于具有的窗口特征,抽取具有不同跨度的特征,这种方式并行性较好,模型较易训练,但是无法把握词前后的关系,无法把握位置特征,同样影响文本信息分类的准确性。
技术实现思路
1、有鉴于此,本发明实施例提供一种文本信息处理模型训练方法、文本信息处理方法、装置、电子设备、软件程序以及存储介质,能够实现通过预测概率分布信息和实际概率分布信息,调整文本处理模型的损失函数,节省文本处理模型的训练时间,提升文本处理模型的分类精确度,提升用户的使用体验。
2、本发明实施例的技术方案是这样实现的:
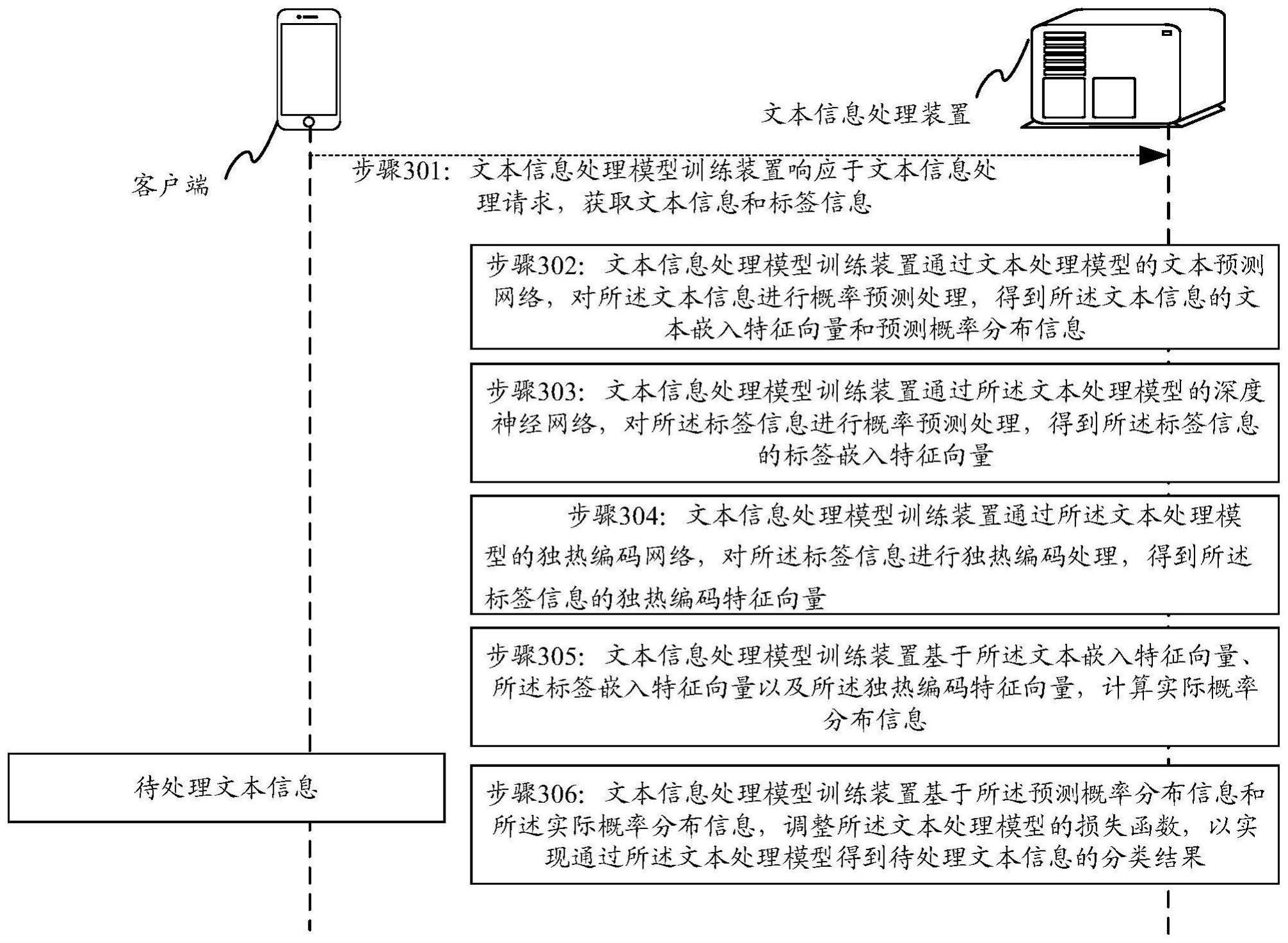
3、本发明实施例提供了一种文本信息处理模型训练方法,包括:
4、响应于文本信息处理请求,获取文本信息和标签信息;
5、通过文本处理模型的文本预测网络,对所述文本信息进行概率预测处理,得到所述文本信息的文本嵌入特征向量和预测概率分布信息;
6、通过所述文本处理模型的深度神经网络,对所述标签信息进行概率预测处理,得到所述标签信息的标签嵌入特征向量;
7、通过所述文本处理模型的独热编码网络,对所述标签信息进行独热编码处理,得到所述标签信息的独热编码特征向量;
8、基于所述文本嵌入特征向量、所述标签嵌入特征向量以及所述独热编码特征向量,计算实际概率分布信息;
9、基于所述预测概率分布信息和所述实际概率分布信息,调整所述文本处理模型的损失函数,以实现通过所述文本处理模型得到待处理文本信息的分类结果。
10、本发明实施例还提供了一种文本信息处理方法,包括:
11、获取待处理的文本信息;
12、通过文本处理模型的编码器,确定与所述待处理文本信息所对应的至少一个词语级的隐变量;
13、通过所述文本处理模型的解码器,根据所述至少一个词语级的隐变量,生成与所述词语级的隐变量相对应的文本分类结果以及所述文本分类结果的被选取概率;
14、根据所述文本分类结果的被选取概率,选取至少一个文本分类结果。
15、本发明实施例还提供了一种文本信息处理模型训练装置,包括:
16、信息传输模块,用于响应于文本信息处理请求,获取文本信息和标签信息;
17、信息处理模块,用于通过文本处理模型的文本预测网络,对所述文本信息进行概率预测处理,得到所述文本信息的文本嵌入特征向量和预测概率分布信息;
18、所述信息处理模块,用于通过所述文本处理模型的深度神经网络,对所述标签信息进行概率预测处理,得到所述标签信息的标签嵌入特征向量;
19、所述信息处理模块,用于通过所述文本处理模型的独热编码网络,对所述标签信息进行独热编码处理,得到所述标签信息的独热编码特征向量;
20、所述信息处理模块,用于基于所述文本嵌入特征向量、所述标签嵌入特征向量以及所述独热编码特征向量,计算实际概率分布信息;
21、所述信息处理模块,用于基于所述预测概率分布信息和所述实际概率分布信息,调整所述文本处理模型的损失函数,以实现通过所述文本处理模型得到待处理文本信息的分类结果。
22、上述方案中,
23、所述信息处理模块,用于确定所述标签信息的类型数量;
24、所述信息处理模块,用于基于所述标签嵌入特征向量的索引信息,确定所述标签嵌入特征向量的维度数量;
25、所述信息处理模块,用于根据所述标签信息的类型数量和所述维度数量,计算所述标签信息的标签信息矩阵;
26、所述信息处理模块,用于通过所述深度神经网络的嵌入层网络,对所述标签信息矩阵进行概率预测处理,得到所述标签信息的标签嵌入特征向量。
27、上述方案中,
28、所述信息处理模块,用于计算所述文本嵌入特征向量和所述标签嵌入特征向量的乘积;
29、所述信息处理模块,用于对所述文本嵌入特征向量和所述标签嵌入特征向量的乘积进行非线性变换处理,得到所述文本嵌入特征向量的相似度;
30、所述信息处理模块,用于基于所述文本嵌入特征向量的相似度,对所述独热编码特征向量进行向量平滑处理,得到所述实际概率分布信息。
31、上述方案中,
32、所述信息处理模块,用于解析所述文本信息处理请求,确定所述文本信息处理请求中所包括的目标对象和所述目标对象对应的金融场景;
33、所述信息处理模块,用于在所述金融场景中,确定所述目标对象的历史行为参数和所述金融场景的历史参数;
34、所述信息处理模块,用于基于所述目标对象,对所述目标对象的历史行为参数和所述金融场景的历史参数进行数据交叉筛选处理,获取与目标对象相匹配的文本信息;
35、所述信息处理模块,用于基于所述目标对象,对所述目标对象的历史行为参数和所述金融场景的历史参数进行数据交叉筛选处理,获取与目标对象相匹配的标签信息。
36、上述方案中,
37、所述信息处理模块,用于基于所述预测概率分布信息和所述实际概率分布信息,计算所述文本处理模型的相对熵;
38、所述信息处理模块,用于通过所述文本处理模型的相对熵,替代所述文本处理模型的交叉熵,以调整所述文本处理模型的损失函数。
39、本发明实施例还提供了一种文本信息处理装置,包括:
40、数据传输模块,用于获取待处理的文本信息;
41、数据处理模块,通过文本处理模型的编码器,确定与所述待处理文本信息所对应的至少一个词语级的隐变量;
42、所述数据处理模块,通过所述文本处理模型的解码器,根据所述至少一个词语级的隐变量,生成与所述词语级的隐变量相对应的文本分类结果以及所述文本分类结果的被选取概率;
43、所述数据处理模块,根据所述文本分类结果的被选取概率,选取至少一个文本分类结果。
44、本发明实施例还提供了一种电子设备,所述电子设备包括:
45、存储器,用于存储可执行指令;
46、处理器,用于运行所述存储器存储的可执行指令时,实现前述的文本信息处理模型训练方法。
47、本发明所一种计算机可读存储介质,存储有可执行指令,所述可执行指令被处理器执行时实现前述的文本信息处理模型训练方法。
48、本发明实施例具有以下有益效果:
49、本发明通过响应于文本信息处理请求,获取文本信息和标签信息;通过文本处理模型的文本预测网络,对所述文本信息进行概率预测处理,得到所述文本信息的文本嵌入特征向量和预测概率分布信息;通过所述文本处理模型的深度神经网络,对所述标签信息进行概率预测处理,得到所述标签信息的标签嵌入特征向量;通过所述文本处理模型的独热编码网络,对所述标签信息进行独热编码处理,得到所述标签信息的独热编码特征向量;基于所述文本嵌入特征向量、所述标签嵌入特征向量以及所述独热编码特征向量,计算实际概率分布信息;基于所述预测概率分布信息和所述实际概率分布信息,调整所述文本处理模型的损失函数,以实现通过所述文本处理模型得到待处理文本信息的分类结果。由此能够实现通过预测概率分布信息和实际概率分布信息,调整文本处理模型的损失函数,节省文本处理模型的训练时间,提升文本处理模型的分类精确度,提升用户的使用体验。
- 还没有人留言评论。精彩留言会获得点赞!