一种利用本征值和正交变换计算文档哈希值的方法与流程
1.本发明属于自然语言处理领域,具体涉及一种利用本征值和正交变换计算文档哈希值的方法,确切说,涉及在自然语言处理中,利用文档中词语信息计算文档的特征,以便快速判断文档间相似性的方法。
背景技术:
2.随着网络的普及,人们在互联网上累计了大量的文档,形成了文档大数据。其中,大部分文档是相同或相似的,不仅占用了大量的网络传输时间和计算机存储空间,也占用了人们的阅读时间,形成了信息过载。如果能快速判断两份文档的相似性,人们就可以减少传输和阅读相似文档时间,减少存储相似的文档的空间。
3.有两类计算文档相似性方法:(1)不考虑文档的语义信息,如谷歌的simhash,利用文档中的某些字符串作为计算文档哈希值的基础,对不同的文档容易计算出相似的哈希值;(2)考虑文档的语义信息,例如先对文档进行分词,再计算分离出的词的词向量表示或分布式表示,再利用复杂的深度神经网络计算句子、段落和整个文档的向量表示或分布式表示,最后形成文档的哈希值。这类方法的词向量维度很高,还需要大量的计算来降低维度,不适合在计算能力较弱的普通计算机上进行。在202110941713.8中公开的《一种计算汉语文档哈希值的方法》和在202110942291.6中公开的《一种利用主元分析计算词向量的方法》,采用汉字点阵作为词向量,虽然利用了一些语义信息,但语义信息量较少,生成的文档的哈希值需要改进。
4.因此,需要一种考虑了较多语义信息、计算简单的文档哈希值计算方法,能够在普通计算机上进行,就能提高文档相似性计算的应用范围。本发明正是基于这种现实需求而产生的。
技术实现要素:
5.(一)要解决的技术问题
6.本发明要解决的技术问题是如何提供一种利用本征值和正交变换计算文档哈希值的方法,以解决提供一种考虑了较多语义信息、计算简单的文档哈希值计算方法,能够在普通计算机上进行的方法,满足文档大数据管理中快速计算文档相似性的需求。
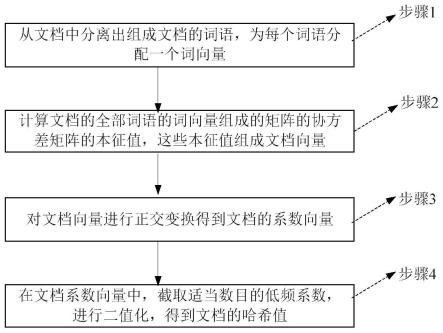
7.(二)技术方案
8.为了解决上述技术问题,本发明提出一种利用本征值和正交变换计算文档哈希值的方法,该方法包括如下步骤:
9.s1、分离文档词语步骤:从文档中分离出组成文档的词语,为每个词语分配一个词向量,即一个词语表示为n个浮点数;
10.s2、计算本征值步骤:计算文档的全部词语的词向量组成的矩阵的协方差矩阵的本征值,这些本征值组成文档向量,如果本征值数目不足n个,则补充若干个0,补足n个本征值;
11.s3、正交变换步骤:对文档向量进行正交变换得到文档系数向量;
12.s4、计算文档哈希值步骤:在文档系数向量中,截取适当数目的低频系数,进行二值化,得到文档的哈希值。
13.进一步地,所述步骤s1中,对于汉语采用“结巴”分词工具将文档分为词语的集合。
14.进一步地,所述步骤s1中,采用word2vec或bert词向量化工具为每个词语分配一个词向量。
15.进一步地,所述步骤s1中,对于英语文档,不需要分词,但需要删除没有实际意义的词语。
16.进一步地,所述步骤s1中,为每个词语wi分配一个词向量(x
i1
,x
i2
,
…
,x
in
);词向量的维度或分量数目n在100到1000之间;如果利用词向量化工具无法为某个词语分配词向量时,将这个词语删除。
17.进一步地,所述步骤s2中,如果文档最后被划分为m个词语,计算这m个词语的词向量的平均词向量w’=(x
’1,x
’2,
…
,x’n
),计算方法如下:
[0018][0019]
各个词向量减去平均词向量后,排列成一个m行n列的矩阵m,
[0020][0021]
将m转置为一个n行m列的矩阵m
t
;如果m≥n,则将m
t
乘以m得到一个n行n列的协方差矩阵covm=m
t
*m,如果m《n,则将m乘以m
t
得到一个m行m列的协方差矩阵covm=m*m
t;
[0022]
计算协方差矩阵covm的本征值λ1,λ2,
…
,λk;如果k《n,则补充若干个0作为本征值,λ
k+1
,λ
k+2
,
…
,λn=0;将这些本征值按照从大到小的顺序排列:λ1≥λ2≥
…
≥λn;
[0023]
将本征值组合为文档向量d=(λ1,λ2,
…
,λn)。
[0024]
进一步地,采用雅可比方法计算协方差矩阵covm的本征值。
[0025]
进一步地,所述步骤s3具体包括:采取离散余弦变换对文档向量进行变换,将文档向量d=(λ1,λ2,
…
,λn)变换为文档系数向量c=(c1,c2,
…
,cn)。
[0026]
进一步地,所述步骤s4具体包括:在文档系数向量c=(c1,c2,
…
,cn)中,截取前面l个低频系数,得到c’=(c1,c2,
…
,c
l
),计算截取的系数平均值c;
[0027][0028]
将截取的低频系数c’二值化为文档的哈希值b=(b1,b2,
…
,b
l
);如果ci≥c’,则bi=1,否则,bi=0。
[0029]
进一步地,l=64。
[0030]
(三)有益效果
[0031]
本发明提出一种利用本征值和正交变换计算文档哈希值的方法,本发明提出的利用本征值和正交变换计算文档哈希值的方法,计算简单,利用了组成文档的词语的语义信
息,使得相似文档的哈希值差异较小,不同文档的哈希值差异较大,能够有效地区分不同的文档,在文档大数据管理中具有较大的应用价值。
附图说明
[0032]
图1为本发明利用本征值和正交变换计算文档哈希值的方法流程图。
具体实施方式
[0033]
为使本发明的目的、内容和优点更加清楚,下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。
[0034]
本发明公开了一种利用本征值和正交变换计算文档哈希值的方法,该方法包括:(1)分离文档词语步骤。从文档中分离出组成文档的词语,为每个词语分配一个词向量。(2)计算本征值步骤。计算文档的全部词语的词向量组成的矩阵的协方差矩阵的本征值,这些本征值组成文档的向量。(3)正交变换步骤。对文档向量进行正交变换得到文档系数向量。(4)计算文档哈希值步骤。在文档系数向量中,截取适当数目的低频系数,进行二值化,得到文档的哈希值。本发明提出的利用本征值和正交变换计算文档哈希值的方法,计算简单,并考虑了词语的语义信息,相似文档的哈希值差异较小,不相似文档的哈希值差异较大,能够有效地区分不同文档,在文档大数据管理中具有重要的应用价值。
[0035]
本发明的目的是:提供一种利用本征值和正交变换计算文档哈希值的方法,满足文档大数据管理中快速计算文档相似性的需求。
[0036]
为实现上述目的,本发明提出了一种利用本征值和正交变换计算文档哈希值的方法,该方法包括:
[0037]
s1、分离文档词语步骤。从文档中分离出组成文档的词语,为每个词语分配一个词向量,即一个词语表示为n个浮点数。
[0038]
s2、计算本征值步骤。计算文档的全部词语的词向量组成的矩阵的协方差矩阵的本征值,这些本征值组成文档向量。如果本征值数目不足n个,则补充若干个0,补足n个本征值。
[0039]
s3、正交变换步骤。对文档向量进行正交变换得到文档系数向量。
[0040]
s4、计算文档哈希值步骤。在文档系数向量中,截取适当数目的低频系数,进行二值化,得到文档的哈希值。
[0041]
图1是本发明的一种利用本征值和正交变换计算文档哈希值的方法的流程图。如图1所示,该方法包括:
[0042]
s1、分离文档词语步骤。从文档中分离出组成文档的词语,为每个词语分配一个词向量,即一个词语表示为n个浮点数。
[0043]
具体实施时,对于汉语可以采用“结巴”等分词工具将文档分为词语的集合。可以采用word2vec或bert等词向量化工具为每个词语分配一个词向量;对于英语文档,不需要分词,但需要删除没有实际意义的词语。为每个词语wi分配一个词向量(x
i1
,x
i2
,
…
,x
in
)。根据需要,一个词向量的维度或分量数目n在100到1000之间。如果利用前述词向量化工具无法为某个词语分配词向量时,可以将这个词语删除。
[0044]
s2、计算本征值步骤。计算文档的全部词语的词向量组成的矩阵的协方差矩阵的
本征值,这些本征值组成文档的向量。如果本征值数目不足n个,则补充若干个0,补足n个本征值。
[0045]
具体实施时,如果文档最后被划分为m个词语,计算这m个词语的词向量的平均词向量w’=(x
’1,x
’2,
…
,x’n
),计算方法如下:
[0046][0047]
各个词向量减去平均词向量后,排列成一个m行n列的矩阵m,
[0048][0049]
将m转置为一个n行m列的矩阵m
t
。如果m≥n,则将m
t
乘以m得到一个n行n列的协方差矩阵covm=m
t
*m。如果m《n,则将m乘以m
t
得到一个m行m列的协方差矩阵covm=m*m
t
。
[0050]
采用雅可比等本征值计算方法计算协方差矩阵covm的本征值,λ1,λ2,
…
,λk。如果k《n,则补充若干个0作为本征值,λ
k+1
,λ
k+2
,
…
,λn=0。将这些本征值按照从大到小的顺序排列:λ1≥λ2≥
…
≥λn。
[0051]
将本征值组合为文档向量d=(λ1,λ2,
…
,λn)。
[0052]
s3、正交变换步骤。对文档向量进行正交变换得到文档系数向量。
[0053]
具体实施时,可以采取离散余弦变换对文档向量进行变换,将文档向量d=(λ1,λ2,
…
,λn)变换为文档系数向量c=(c1,c2,
…
,cn)。
[0054]
s4、计算文档哈希值步骤。在文档系数向量中,截取适当数目的低频系数,进行二值化,得到文档的哈希值。
[0055]
具体实施时,在文档系数向量c=(c1,c2,
…
,cn)中,可以截取前面64个低频系数,得到c’=(c1,c2,
…
,c
64
),计算截取的系数平均值c。
[0056][0057]
将截取的低频系数c’二值化为文档的哈希值b=(b1,b2,
…
,b
64
)。如果ci≥c’,则bi=1,否则,bi=0。
[0058]
实施例1:
[0059]
一种利用本征值和正交变换计算文档哈希值的方法,包括:
[0060]
(1)分离文档词语步骤。从文档中分离出组成文档的词语,为每个词语分配一个词向量,即一个词语表示为n个浮点数。
[0061]
(2)计算本征值步骤。计算文档的全部词语的词向量组成的矩阵的协方差矩阵的本征值,这些本征值组成文档向量。如果本征值数目不足n个,则补充若干个0,补足n个本征值。
[0062]
(3)正交变换步骤。对文档向量进行正交变换得到文档系数向量。
[0063]
(4)计算文档哈希值步骤。在文档系数向量中,截取适当数目的低频系数,进行二值化,得到文档的哈希值。
[0064]
进一步地,所述步骤(1)中,一个词向量的维度或分量数目n在100到1000之间。如果无法为某个词语分配词向量时,可以将这个词语删除。
[0065]
进一步地,所述步骤(2)中,如果文档词语数目m大于等于词向量维度n,则协方差矩阵为n行n列,否则协方差矩阵为m行m列。如果协方差矩阵的本征值数目不足n个,则补充若干个0,补足n个本征值。将这些本征值按照从大到小的顺序排列。
[0066]
进一步地,所述步骤(3)中,正交变换可以采用离散余弦变换,也可以采用哈达玛变换、离散正弦变换等其他正交变换。
[0067]
进一步地,所述步骤(4)中,二值化采用平均值二值化方式,截取的各个系数与系数的平均值进行比较,二值化为1或0。
[0068]
本发明提出的利用本征值和正交变换计算文档哈希值的方法,计算简单,利用了组成文档的词语的语义信息,使得相似文档的哈希值差异较小,不同文档的哈希值差异较大,能够有效地区分不同的文档,在文档大数据管理中具有较大的应用价值。
[0069]
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1