基于位置引导Transformer的图像描述生成方法、装置和计算机设备
基于位置引导transformer的图像描述生成方法、装置和计算机设备
技术领域
1.本发明涉及计算机视觉和自然语言处理技术领域,特别涉及一种基于位置引导transformer的图像描述生成方法、装置和计算机设备。
背景技术:
2.图像描述生成是一个多模态任务,旨在自动生成图像中视觉内容的自然语言描述。它不仅要求了模型对视觉和语言的理解,而且还要有能力对齐跨模态表示。图像描述生成模型广泛地使用了编码器-解码器范式,其中卷积神经网络(convolutional neural network,cnn)被用来编码视觉特征,而循环神经网络(recurrent neural network,rnn)被用来将cnn的输出解码为自然句子。此外,基于注意力的方法探索了视觉表征和自然句子之间的互动,并关注突出的信息。具体来说,注意力机制通过生成每个输入图像的空间投影来指导每个单词的解码,以此提高性能。随着transformer的发展,在图像描述生成模型中,自注意力模块在探索视觉特征和文字之间的相关性方面发挥了重要作用。
3.然而,传统的基于transformer的框架在图像描述生成中考虑图像中视觉内容之间的几何关系方面有一定困难,不能防止自我注意中每层输入的分布变化,同时也很难捕捉到视觉元素之间的相互位置信息的交互,这限制了图像描述生成任务的表达能力。
技术实现要素:
4.本发明提供了一种基于位置引导transformer的图像描述生成方法、装置和计算机设备,将绝对位置编码和相对位置编码同时引入自注意力模块,并在其内部对图像特征进行组归一化,提高了模型的有效性。
5.本发明提供了一种基于位置引导transformer的图像描述生成方法,包括:
6.获取图像,并提取所述图像的网格特征;
7.将所述网格特征进行扁平化处理,得到输入向量;
8.根据所述网格特征得到所述网格特征的相对位置编码和绝对位置编码;
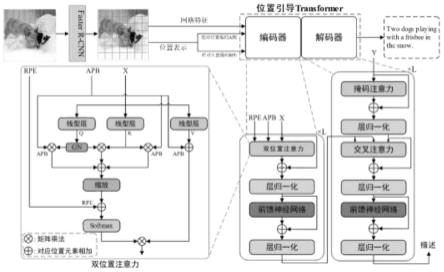
9.将所述相对位置编码、绝对位置编码、输入向量输入预设的位置引导transformer模型,得到描述所述图像的语句;其中,所述预设的位置引导transformer模型包括编码器和解码器,所述编码器和解码器均由多个堆叠的注意力块组成,所述编码器的每个注意力块包括双位置注意力层和前馈神经网络,所述解码器的每个注意力块包括掩码注意力层、交叉注意力层和前馈神经网络。
10.进一步地,所述根据所述网格特征得到所述网格特征的相对位置编码和绝对位置编码的步骤,包括:
11.采用正弦波位置编码的拼接和扁平化处理计算所述网格特征的绝对位置编码;其中,计算公式包括:
12.[0013][0014][0015]
其中,ape(i,j)表示绝对位置编码,i,j是一个网格特征的行嵌入和列嵌入,[pei;pej]表示拼接,p表示行或列的位置,m表示p的维度,d
model
表示所述位置引导transformer模型的维度;
[0016]
计算所述网格特征的平滑相对位置编码;其中,计算公式包括:
[0017][0018]
其中,表示平滑相对位置编码,表示符号函数,cx和cy表示网格特征的中心坐标,w表示网格特征的宽度,h表示网格特征的高度;
[0019]
将所述平滑相对位置编码投影到其中,公式为:
[0020][0021]
其中,fc(
·
)表示全连接层对应的映射函数,emb表示原始tansformer模型中对应的嵌入函数,σ为relu激活函数。
[0022]
进一步地,所述将所述相对位置编码、绝对位置编码、输入向量输入预设的位置引导transformer模型,得到描述所述图像的语句的步骤,包括:
[0023]
将所述相对位置编码、绝对位置编码、输入向量输入所述编码器中进行多级编码,得到编码结果;
[0024]
将所述编码结果输入所述解码器中,并在所述解码器中依次经过掩码注意力层、交叉注意力层和前馈神经网络后,得到描述所述图像的语句。
[0025]
进一步地,所述将所述相对位置编码、绝对位置编码、输入向量输入所述编码器中进行多级编码,得到编码结果的步骤中,对于第(l+1)层:
[0026]
将所述相对位置编码、绝对位置编码、输入向量输入双位置注意力层进行计算,得到第一计算结果;其中,计算公式为:
[0027]
mhbpa(f
l
,f
l
,f
l
,ape,rpe)=concat(head1,
…
,headh)wo[0028]
headi=bpa(f
l
,f
l
,f
l
,ape,rpe)
[0029]
其中,表示输入向量,表示网格特征的绝对位置编码,rpe∈rn×n表示网格特征的相对位置编码,mhbpa(f
l
,f
l
,f
l
,ape,rpe)表示第一计算结果h
l+1
;
[0030]
将所述第一计算结果h
l+1
进行层归一化得到注意力结果其中,计算公式为:
[0031]hl+1
=mhbpa(f
l
,f
l
,f
l
,apb,rpe)
[0032][0033]
将所述注意力结果输入所述编码器的前馈神经网络进行计算,得到第二计算结果f
l+1
;其中,计算公式为:
[0034][0035]
将第二计算结果f
l+1
输入第(l+2)层进行计算,以此类推,直到所有双位置注意力层均计算后,完成多级编码。
[0036]
进一步地,所述将所述第一计算结果h
l+1
进行层归一化得到注意力结果的步骤中,注意力结果z
bpa
为经过组归一化后的注意力结果;其中,组归一化方法包括:
[0037][0038]
其中,x、y代表输入和输出,var[x]是x的均值和方差,∈是常数,γ、β是可学习的仿射参数;
[0039]qn
=gn(q)
[0040][0041]
其中,q、qn对应x、y,分别代表输入和输出;
[0042][0043]ebpa
=s
′n+log(ω)
[0044]zbpa
=bpa(q,k,v,apb,rpe)=softmax(e
bpa
)
·
(v+pv)
[0045]
其中,pq,pk分别为q和k的绝对位置编码,为查询依赖偏置,为关键值依赖偏置,s
′n代表缩放分数,ω为
[0046]
进一步地,将所述相对位置编码、绝对位置编码、输入向量输入预设的位置引导transformer模型,得到描述所述图像的语句的步骤之后,还包括:
[0047]
采用交叉熵损失函数训练所述位置引导transformer模型;其公式为:
[0048][0049]
其中,p
θ
为位置引导transformer模型给定的概率分布;
[0050]
采用自批评序列训练使负期望奖赏l
rl
(θ)最小化:
[0051][0052]
[0053][0054]
其中,r(y
1:t
)为奖赏函数,即cider分数的计算,k为波束尺寸,为第i个句子,b为被采样序列获得奖励的平均值计算而来的基线。
[0055]
进一步地,所述采用自批评序列训练使负的预期奖赏l
rl
(θ)最小化的步骤中,对所述位置引导transformer模型训练设定次数,选取所述设定次数中cider分数最高的一次的位置引导transformer模型作为初始模型,对所述初始模型采用自批评序列训练进行调整。
[0056]
本发明还提供了一种基于位置引导transformer的图像描述生成装置,包括:
[0057]
获取模块,用于获取图像,并提取所述图像的网格特征;
[0058]
处理模块,用于将所述网格特征进行扁平化处理,得到输入向量;
[0059]
编码模块,用于根据所述网格特征得到所述网格特征的相对位置编码和绝对位置编码;
[0060]
输入模块,用于将所述相对位置编码、绝对位置编码、输入向量输入预设的位置引导transformer模型,得到描述所述图像的语句;其中,所述预设的位置引导transformer模型包括编码器和解码器,所述编码器和解码器均由多个堆叠的注意力块组成,所述编码器的每个注意力块包括双位置注意力层和前馈神经网络,所述解码器的每个注意力块包括掩码注意力层、交叉注意力层和前馈神经网络。
[0061]
本发明还提供了一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现上述方法的步骤。
[0062]
本发明还提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述方法的步骤。
[0063]
本发明的有益效果为:
[0064]
1、将绝对位置编码和相对位置编码同时引入自注意力模块,形成了双位置注意力模块,结合绝对和相对位置编码来衡量视觉特征和其内部位置信息之间的贡献。
[0065]
2、使用组归一化方法,它利用多头注意力内部的通道级依赖性来减轻注意力模块中分布的偏移。
[0066]
3、将双位置注意力模块和组归一化方法应用到位置引导transformer模型中,为图像描述生成任务探索更准确的位置表示;在mscoco数据集上进行验证时,本发明中的位置引导transformer模型在离线和在线测试中取得与非预训练的最先进方法相竞争的性能,证明了模型的有效性。
附图说明
[0067]
图1为本发明中位置引导transformer模型的结构示意图。
[0068]
图2为本发明一实施例的方法流程示意图。
[0069]
图3为本发明中相对位置编码的函数图像示意图。
[0070]
图4为本发明一实施例的装置结构示意图。
[0071]
图5为本发明一实施例的计算机设备内部结构示意图。
[0072]
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
[0073]
应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
[0074]
如图1-2所示,本发明提供了一种基于位置引导transformer的图像描述生成方法,包括:
[0075]
s1、获取图像,并提取所述图像的网格特征;
[0076]
s2、将所述网格特征进行扁平化处理,得到输入向量;
[0077]
s3、根据所述网格特征得到所述网格特征的相对位置编码和绝对位置编码;
[0078]
s4、将所述相对位置编码、绝对位置编码、输入向量输入预设的位置引导transformer模型,得到描述所述图像的语句;其中,所述预设的位置引导transformer模型包括编码器和解码器,所述编码器和解码器均由多个堆叠的注意力块组成,所述编码器的每个注意力块包括双位置注意力层和前馈神经网络,所述解码器的每个注意力块包括掩码注意力层、交叉注意力层和前馈神经网络。
[0079]
如上述步骤s1-s4所述,图像描述生成是一个多模态任务,旨在自动生成图像中视觉内容的自然语言描述。其不仅要求了模型对视觉和语言的理解,而且还要有能力对齐跨模态表示。图像描述生成模型广泛地使用了编码器-解码器范式,其中卷积神经网络(convolutional neural network,cnn)被用来编码视觉特征,而循环神经网络(recurrent neural network,rnn)被用来将cnn的输出解码为自然句子,此外,注意力机制通过生成每个输入图像的空间投影来指导每个单词的解码,以此提高性能。
[0080]
如图2所示,获取一张图像,采用faster r-cnn模型得到该图像的网格特征,卷积神经网络(convolutional neural network,cnn)用于对图像内容进行向量化处理,并使用(recurrent neural network,rnn)将向量解码成句子。得到图片的网格特征后,根据网格特征得到网格特征的相对位置编码和绝对位置编码;同时,将网格特征进行扁平化处理,得到输入向量,记录为最后将这些向量和相对位置编码、绝对位置编码送入预设的位置引导transformer模型,得到描述所述图像的语句。预设的位置引导transformer模型,即pgt(position-guided transformer)。在整体架构中采用了编码器-解码器范式,位置引导transformer模型由一个图像特征编码器和一个描述句子解码器组成,两者都由l个堆叠的注意力块组成,每个注意力块包括多头注意力层和前馈神经网络,块内还有几个子层,他们都带有残差连接和层归一化。在编码器中,双位置注意力(bpa)模块用于捕捉全面的位置信息并学习复杂的几何表示,使用编码之后的特征,解码器可以逐词地生成描述。
[0081]
传统的自注意力模块很难捕捉到视觉元素之间的相互位置信息的交互,限制了图像描述生成任务的表达能力。对于绝对位置编码(absolute position encoding,ape)而言,尽管可以使用正弦嵌入来获取位置信息,但使用相对位置编码(relative position encoding,rpe)会获得更好的性能。然而,rpe缺乏固定的位置信息。例如,图像中不同物体之间的相对顺序或距离。为了解决上述问题,本发明提出双位置注意力(bi-positional attention,bpa)模块学习一个更全面的位置嵌入,增强图像中物体间的空间相关性,将bpa模块和gn方法都应用到位置引导transformer模型(position-guided transformer,pgt)中,即,将原始transformer的自注意力模块替换为bpa模块,并在其内部对图像特征施以组归一化,然后将其用于图像描述生成任务,其中使用的视觉特征是网格特征,bpa可以建模更复杂的空间关系。采用了组归一化(group normalization,gn)方法来提取多头注意中更
丰富的通道级特征,gn使模型能够灵活地捕捉每组的不同分布。
[0082]
基于transformer的框架在考虑图像中视觉内容之间的几何关系方面是很困难的,同时也不能防止自我注意中每层输入的分布变化。因此,本发明提出了一个双位置注意力(bi-positional attention,bpa)模块,其结合了绝对和相对位置编码,以精确探索图像中的物体及其几何信息之间的内部关系。此外,还在bpa内部使用了组归一化(group normalization,gn)方法,以缓解分布的偏移,并更好地利用视觉特征的通道依赖性。本发明将bpa和gn应用到原始的transformer中,构成了位置引导transformer(position-guided transformer,pgt)网络,其学习了更全面的位置表征,以增强图像描述生成任务中物体间的空间互动。与非预训练的最先进方法相比,在mscoco基准数据集上的实验结果表明,本发明的pgt取得了有竞争力的性能,在karpathy分割上用单个模型达到了134.2%的cider分数,在官方测试服务器上使用集成模型设置达到了136.2%的cider分数。
[0083]
在一个实施例中,所述根据所述网格特征得到所述网格特征的相对位置编码和绝对位置编码的步骤,包括:
[0084]
s31、采用正弦波位置编码的拼接和扁平化处理计算所述网格特征的绝对位置编码;其中,计算公式包括:
[0085][0086][0087][0088]
其中,ape(i,j)表示绝对位置编码,i,j是一个网格特征的行嵌入和列嵌入,[pei;pej]表示拼接,p表示行或列的位置,m表示p的维度,d
model
表示所述位置引导transformer模型的维度;
[0089]
s32、计算所述网格特征的平滑相对位置编码;其中,计算公式包括:
[0090][0091]
其中,表示平滑相对位置编码,表示符号函数,cx和cy表示网格特征的中心坐标,w表示网格特征的宽度,h表示网格特征的高度;
[0092]
s33、将所述平滑相对位置编码投影到其中,公式为:
[0093][0094]
其中,fc(
·
)表示全连接层对应的映射函数,emb表示原始tansformer模型中对应的嵌入函数,σ为relu激活函数。
[0095]
如上述步骤s31-s33所述,位置表征在捕捉单词的位置方面起着重要作用,位置表
征能指导模型区分物体的位置,或整合物体间的相对位置信息。故,需要根据网格特征得到网格特征的相对位置编码和绝对位置编码。
[0096]
绝对位置编码(absolute position encoding,ape):
[0097]
绝对位置编码(absolute position encoding,ape)用于探索transformer模型的序列顺序,ape为输入标记的每个位置建立一个单独的映射。此外,在自注意力中引入两个输入序列间的相对位置编码(relative position encoding,rpe),进一步利用rpe来增强视觉任务中的相对位置表征。
[0098]
每个位置所对应的独一无二的表示都是通过ape获得的,采用正弦波位置编码的拼接和扁平化处理来获取每个图像中可用的ape,整个操作的定义如下:
[0099]
ape(i,j)=[pei;pej]
[0100]
其中,i,j是一个网格的行嵌入和列嵌入,[
·
;
·
]代表拼接操作。可以被定义为:
[0101][0102][0103]
其中p可以是行或者列的位置,m是p的维度,d
model
代表模型的维度。
[0104]
相对位置编码(relative position encoding,rpe):
[0105]
ape传达了一些位置信息,但其很难捕捉到图像中物体之间的几何关系。因此,需要计算网格特征的rpe。
[0106]
给定一组网格特征,每个网格可以表示为(cx,cy,w,h),其中cx和cy代表网格的中心坐标,w和h代表其宽度和高度。两个网格i和j之间的几何关系被定义为一个4维向量将该向量命名为中心坐标相对位置编码(center-coordinate relative position encoding,crpe):
[0107][0108]
然后会被投影到一个更高维的特征
[0109][0110]
其中emb表示原始tansformer模型中对应的嵌入函数,fc(
·
)表示全连接层对应的映射函数,σ是relu激活函数。
[0111]
当计算网格的中心坐标结果,即|cx
i-cxj|和|cy
i-cyj|,必须将结果限制为略大于0来作为函数y=log(|x|)的输入。此外,函数相对于y轴是对称的,两边的结果完全相同,这可能导致该模型只区分距离,而不是网格特征中的相对方向。此外,当输入足够小的时候,
如果稍微改变它,由于对数函数的特性,输出会有很大的变化。为了克服上述限制,引入了另一种方法来计算该4维向量这被称为平滑相对位置编码(smooth relative position encoding,srpe)。如图3所示,图3示出了两个函数的图像,展示了两种方法之间的差异。通过使用srpe,计算相对坐标的结果变化更加平滑,从而提高了相对位置信息的表现力,因此,采用如下公式计算srpe:
[0112][0113]
其中代表符号函数,而其输入是对应的中心坐标cx或cy。同样会被投影到一个更高维的特征如公式:
[0114][0115]
在一个实施例中,所述将所述相对位置编码、绝对位置编码、输入向量输入预设的位置引导transformer模型,得到描述所述图像的语句的步骤,包括:
[0116]
s41、将所述相对位置编码、绝对位置编码、输入向量输入所述编码器中进行多级编码,得到编码结果;
[0117]
s42、将所述编码结果输入所述解码器中,并在所述解码器中依次经过掩码注意力层、交叉注意力层和前馈神经网络后,得到描述所述图像的语句。
[0118]
如上述步骤s41-s42所述,在多级编码时,第l个块的输出会被送入到第(l+1)个块中作为第(l+1)个块的输入,第(l+1)个块的输出又会被送入到第(l+2)个块中,以此类推。pgt,即本发明的位置引导transformer模型的解码器与原始transformer的解码器保持一致,由一个捕捉词级交互的掩码多头注意力、一个探索视觉和文本特征关系的交叉多头注意力以及一个前馈神经网络组成。将编码结果输入所述解码器中,并在所述解码器中依次经过掩码注意力层、交叉注意力层和前馈神经网络后,得到描述所述图像的语句;解码器没有使用bpa(bi-positional attention,双位置注意力)模块,因为解码器中的单词输入的长度是可变的,来自图像特征的位置表示可能会对单词的位置嵌入造成扰动。
[0119]
在一个实施例中,所述将所述相对位置编码、绝对位置编码、输入向量输入所述编码器中进行多级编码,得到编码结果的步骤中,对于第(l+1)层:
[0120]
s411、将所述相对位置编码、绝对位置编码、输入向量输入双位置注意力层进行计算,得到第一计算结果;其中,计算公式为:
[0121]
mhbpa(f
l
,f
l
,f
l
,ape,rpe)=concat(head1,
…
,headh)wo[0122]
headi=bpa(f
l
,f
l
,f
l
,ape,rpe)
[0123]
其中,表示输入向量,表示网格特征的绝对位置编码,rpe∈rn×n表示网格特征的相对位置编码,mhbpa(f
l
,f
l
,f
l
,ape,rpe)表示第一计算结果f
l+1
;
[0124]
s412、将所述第一计算结果h
l+1
进行层归一化得到注意力结果其中,计算公式为:
[0125]hl+1
=mhbpa(f
l
,f
l
,f
l
,apb,rpe)
[0126][0127]
s413、将所述注意力结果输入所述编码器的前馈神经网络进行计算,得到第二计算结果f
l+1
;其中,计算公式为:
[0128][0129]
s414、将第二计算结果f
l+1
输入第(l+2)层进行计算,以此类推,直到所有双位置注意力层均计算后,完成多级编码。
[0130]
如上述步骤s411-s414所述,将网格特征进行扁平化处理,得到输入向量后,将其送入pgt的编码器,具体地,对于第(l+1)层,模型的输入首先会被送入多头bpa模块(multi=head bpa,mhbpa)
[0131]
mhbpa(f
l
,f
l
,f
l
,ape,rpe)=concat(head1,
…
,headh)wo[0132]
headi=bpa(f
l
,f
l
,f
l
,ape,rpe)
[0133]
其中,和rpe∈rn×n分别是网格特征的绝对和相对位置编码。mhbpa的输出h
l+1
会经过一个残差连接以及层归一化:
[0134]hl+1
=mhbpa(f
l
,f
l
,f
l
,apb,rpe)
[0135][0136]
其中,是注意力结果。然后会被送入一个前馈神经网络(feed-forward neural network,ffn),它也是带有一个残差连接和一个层归一化的:
[0137][0138]
最终,在多级编码之后,第l层得到的输出f
l
将进入解码层中。
[0139]
在一个实施例中,所述将所述第一计算结果h
l+1
进行层归一化得到注意力结果的步骤中,注意力结果z
bpa
为经过组归一化后的注意力结果;其中,组归一化方法包括:
[0140][0141]
其中,x、y代表输入和输出,var[x]是x的均值和方差,∈是常数,γ、β是可学习的仿射参数;
[0142]qn
=gn(q)
[0143][0144]
其中,q、qn对应x、y,分别代表输入和输出;
[0145][0146]ebpa
=s
′n+log(ω)
[0147]zbpa
=bpa(q,k,v,apb,rpe)=softmax(e
bpa
)
·
(v+pv)
[0148]
其中,pq,pk分别为q和k的绝对位置编码,为查询依赖偏置,为关键值依赖偏置,s
′n代表缩放分数,ω为
[0149]
如上所述,传统的transformer模型,对于自注意力层:自注意力层聚合了整个输入的信息。给定从输入中提取的特征x,注意力函数能够捕捉到x内部的相互作用。矩阵q、k和v是通过将输入特征x线性投影在三个可学习的权重矩阵,即wq,wk和wv上得到的,其公式如下:
[0150]
s=qk
t
[0151][0152]
z=attention(q,k,v)=softmax(sn)
·v[0153]
其中d
model
是特征的维度,n是每个图像中的网格数,s是通过两个不同的输入矩阵计算出的分数,sn是softmax函数中为了梯度稳定的缩放分数,代表缩放因子,z是计算后所得的矩阵。
[0154]
为了使自注意层捕获到更丰富的表征,transformer采用了多头注意力机制,其中维度为d
model
的q,k,v会分别被线型地投影h次,使其维度分别变为dk,dk和dv,即dk=dv=d
model
/h.该操作的定义如下:
[0155][0156]
multihead(q,k,v)=concat(head1,...,headh)wo[0157]
其中是参数矩阵。
[0158]
对于前馈神经网络:
[0159]
每个编码器和解码器中多头注意力层的输出h会被送入一个前馈神经网络,该网络由两个带有relu激活函数的线性变换组成,其表示为如下公式:
[0160]
ffn(h)=relu(hw1+b1)w2+b2[0161]
其中w1,w2,b1,b2是可学习的参数。隐藏层的维度d
h is set是大于d
model
的。
[0162]
对于残差连接和归一化:
[0163]
子层(sublayer)的输入h
in
和输出h
out
通过一个残差块和层归一化进行连接,表示为:
[0164]hout
=layernorm(h
in
+sublayer(h
in
))
[0165]
其中,sublayer(
·
)表示一个网络模块对应的映射函数,该网络模块可以是bpa模型中的注意力层,也可以是bpa模型中的前馈神经网络。
[0166]
在发明中的bpa模块中,首先将绝对位置编码(absolute position encoding,ape)引入位置引导transformer模型,ape有助于模型准确区分物体的位置。将q和k相乘形成基于内容的注意,将ape分别与q和k相乘,形成位置引导的注意并引导模型关注相对重要的位置信息,将三个注意力结果相加,得到bpa中的注意力得分,其公式为:
[0167]
[0168][0169]
其中pq,pk分别为q和k的ape,位置引导的注意力结果和被分别命名为查询依赖偏置和关键值依赖偏置,s
′n代表缩放分数。
[0170]
除此之外,采用rpe来调整比例得分,它能更好地将相对位置信息聚合到自注意力中。其表达式如下:
[0171]ebpa
=s
′n+log(ω)
[0172]
其中ω可以是上述的或者e
bpa
是bpa的最终注意力分数。
[0173]
注意到v在前述传统transformer模型的公式z=attention(q,k,v)=softmax(sn)
·
v中不涉及任何位置信息。因此,引入了v的绝对位置编码,即值依赖偏置pv:
[0174]zbpa
=bpa(q,k,v,apb,rpe)=softmax(e
bpa
)
·
(v+pv)
[0175]
其中z
bpa
是bpa的输出,前述三个偏置将其统一命名为绝对位置偏置(absolute positional bias,apb)。
[0176]
本发明中,为了缓解内部协变量偏移,稳定自注意力模块的训练,早期在图像描述生成中使用了实例归一化(instance normalization,in)。然而,in只是依靠空间维度来计算均值和方差,没有利用通道级的依赖性,而这个依赖性这对于图像描述生成模型捕捉不同的表征是至关重要的。为了解决这个问题,本发明在多头注意力中使用了组归一化的方法(gn)以学习更灵活和多样化的分布,从而提高探索物体间几何关系的能力。gn进行以下计算:
[0177][0178]
其中x,y代表输入和输出,var[x]是x的均值和方差,∈是一个很小的常数,γ,βare是可学习的仿射参数,上述等式可以被表示为y=gn(x)。
[0179]
在多头注意力的上实施归一化。h代表头指数,即要进行归一化的那个通道。将h通道分为h/2组,该操作定义为:
[0180]qn
=gn(q)
[0181]
其中qn代表已经被归一化的q,因此,bpa中的分数计算表示如下:
[0182][0183]
与前述相同的是,得到的结果s
′
bpa
经过计算,最终得到的注意力结果z
bpa
将被送入编码器的下一个阶段。其中,采用上述的公式为:
[0184][0185]ebpa
=s
′n+log(ω)
[0186]zbpa
=bpa(q,k,v,apb,rpe)=softmax(e
bpa
)
·
(v+pv)
[0187]
其中,pq,pk分别为q和k的绝对位置编码,为查询依赖偏置,为关键值依
赖偏置,s
′n代表缩放分数,ω为
[0188]
在一个实施例中,所述将所述相对位置编码、绝对位置编码、输入向量输入预设的位置引导transformer模型,得到描述所述图像的语句的步骤之后,还包括:
[0189]
s5、采用交叉熵损失函数训练所述位置引导transformer模型;其公式为:
[0190][0191]
其中,p
θ
为位置引导transformer模型给定的概率分布;
[0192]
s6、采用自批评序列训练使负期望奖赏l
rl
(θ)最小化:
[0193][0194][0195][0196]
其中,r(y
1:t
)为奖赏函数,即cider分数的计算,k为波束尺寸,为第i个句子,b为被采样序列获得奖励的平均值计算而来的基线。
[0197]
如上所述,使用交叉熵损失来预先训练优化位置引导transformer模型模型。给定一个真实标签一个来自真实标签句子中第t个时间步的单词以及一个带参数θ的图像描述生成模型,目标是使交叉熵损失函数l
xe
(θ)最小化,其定义如下:
[0198][0199]
其中p
θ
由模型给定的概率分布。
[0200]
然后,采用自批评序列训练(self-critical sequence training,scst)来微调不可微的指标。scst可以克服暴露偏差的问题,明显提高图像描述生成系统的性能。scst的目标是使负的预期奖赏l
rl
(θ)最小化:
[0201][0202]
其中r(
·
)奖赏函数,也就是cider评分的计算。用一个样本的预期奖赏函数的梯度可以被近似表达为:
[0203][0204]
[0205]
其中k是波束尺寸,第i个句子,b是由被采样序列获得奖励的平均值计算而来的基线。
[0206]
在一个实施例中,所述采用自批评序列训练使负的预期奖赏l
rl
(θ)最小化的步骤中,对所述位置引导transformer模型训练设定次数,选取所述设定次数中cider分数最高的一次的位置引导transformer模型作为初始模型,对所述初始模型采用自批评序列训练进行调整。
[0207]
如上述所,在具体实验中,所有实验都是在mscoco数据集上进行的,其是一个标准的用于图像描述生成任务的数据集。如,该数据集共有123287张图片,其中有82783张和40504张分别用于训练和验证。每张图片都标注有5个不同的句子,遵循karpathy划分,其是一个在离线测试中应用最广泛的划分数据集的方法。该划分方法中包含了113287张带有5个标注句子的训练集图像,5000张验证集图像,以及5000张测试集图像。本发明采用了五个标准的评价指标,即bleu、meteor、rouge-l、cider、和spice来评价生成句子的质量。bleu和meteor都是为机器翻译设计的。rouge-l是一个用于文本摘要的召回导向的评价指标。值得注意的是,cider和spice是专门针对图像描述生成任务提出的评价指标,也是本发明主要考量的指标。
[0208]
使用已经在imagenet上预训练完成的带有resnext-101骨干网络的faster r-cnn来提取图像的网格特征。网格尺寸设置为7
×
7,输入特征的维度设置为2048,编码器和解码器的堆叠数为4。编码器和解码器的维度为512,注意力头数为4,前馈神经网络的内层维度为2048,神经网络的丢弃比率为0.1。使用adam优化器来训练模型,在交叉熵训练阶段,为模型热身3轮,其中的学习率会线型地增加到1
×
10-4
,在第4~10轮,将学习率设置到1
×
10-4
;在第11~12轮,学习率设置到2
×
10-5
;在第13~15轮,学习率设置到4
×
10-6
,在第16~20轮,学习率设置到8
×
10-7
。随后的30轮训练使用自批评序列训练,其中的学习率设置为5
×
10-6
并且每10轮训练就退火0.2,批次大小设置为40,束搜索的尺寸设置为5。首先使用交叉熵损失进行训练,然后选择在验证集上达到最高cider分数的那个模型作为初始模型,再使用自批评序列训练对其进行微调。
[0209]
如图4所示,本发明还提供了一种基于位置引导transformer的图像描述生成装置,包括:
[0210]
获取模块1,用于获取图像,并提取所述图像的网格特征;
[0211]
处理模块2,用于将所述网格特征进行扁平化处理,得到输入向量;
[0212]
编码模块3,用于根据所述网格特征得到所述网格特征的相对位置编码和绝对位置编码;
[0213]
输入模块4,用于将所述相对位置编码、绝对位置编码、输入向量输入预设的位置引导transformer模型,得到描述所述图像的语句;其中,所述预设的位置引导transformer模型包括编码器和解码器,所述编码器和解码器均由多个堆叠的注意力块组成,所述编码器的每个注意力块包括双位置注意力层和前馈神经网络,所述解码器的每个注意力块包括掩码注意力层、交叉注意力层和前馈神经网络。
[0214]
在一个实施例中,编码模块3,包括:
[0215]
第一计算单元,用于采用正弦波位置编码的拼接和扁平化处理计算所述网格特征的绝对位置编码;其中,计算公式包括:
[0216][0217][0218][0219]
其中,ape(i,j)表示绝对位置编码,i,j是一个网格特征的行嵌入和列嵌入,[pei;pej]表示拼接,p表示行或列的位置,m表示p的维度,d
model
表示所述位置引导transformer模型的维度;
[0220]
第二计算单元,用于计算所述网格特征的平滑相对位置编码;其中,计算公式包括:
[0221][0222]
其中,表示平滑相对位置编码,表示符号函数,cx和cy表示网格特征的中心坐标,w表示网格特征的宽度,h表示网格特征的高度;
[0223]
投影单元,用于将所述平滑相对位置编码投影到其中,公式为:
[0224][0225]
其中,fc(
·
)表示全连接层对应的映射函数,emb表示原始tansformer模型中对应的嵌入函数,σ为relu激活函数。
[0226]
在一个实施例中,输入模块4,包括:
[0227]
多级编码单元,用于将所述相对位置编码、绝对位置编码、输入向量输入所述编码器中进行多级编码,得到编码结果;
[0228]
输入单元,用于将所述编码结果输入所述解码器中,并在所述解码器中依次经过掩码注意力层、交叉注意力层和前馈神经网络后,得到描述所述图像的语句。
[0229]
在一个实施例中,多级编码单元中,对于第(l+1)层:
[0230]
将所述相对位置编码、绝对位置编码、输入向量输入双位置注意力层进行计算,得到第一计算结果;其中,计算公式为:
[0231]
mhbpa(f
l
,f
l
,f
l
,ape,rpe)=concat(head1,
…
,headh)wo[0232]
headi=bpa(f
l
,f
l
,f
l
,ape,rpe)
[0233]
其中,表示输入向量,表示网格特征的绝对位置编码,rpe∈rn×n表示网格特征的相对位置编码,mhbpa(f
l
,f
l
,f
l
,ape,rpe)表示第一计算结果h
l+1
;
[0234]
将所述第一计算结果h
l+1
进行层归一化得到注意力结果其中,计算公式为:
[0235]hl+1
=mhbpa(f
l
,f
l
,f
l
,apb,rpe)
[0236][0237]
将所述注意力结果输入所述编码器的前馈神经网络进行计算,得到第二计算结果f
l+1
;其中,计算公式为:
[0238][0239]
将第二计算结果f
l+1
输入第(l+2)层进行计算,以此类推,直到所有双位置注意力层均计算后,完成多级编码。
[0240]
在一个实施例中,所述将所述第一计算结果h
l+1
进行层归一化得到注意力结果的步骤中,注意力结果z
bpa
为经过组归一化后的注意力结果;其中,组归一化方法包括:
[0241][0242]
其中,x、y代表输入和输出,var[x]是x的均值和方差,∈是常数,γ、β是可学习的仿射参数;
[0243]qn
=gn(q)
[0244][0245]
其中,q、qn对应x、y,分别代表输入和输出;
[0246][0247]ebpa
=s
′n+log(ω)
[0248]zbpa
=bpa(q,k,v,apb,rpe)=softmax(e
bpa
)
·
(v+pv)
[0249]
其中,pq,pk分别为q和k的绝对位置编码,为查询依赖偏置,为关键值依赖偏置,s
′n代表缩放分数,ω为
[0250]
在一个实施例中,还包括:
[0251]
训练模块,用于采用交叉熵损失函数训练所述位置引导transformer模型;其公式为:
[0252][0253]
其中,p
θ
为位置引导transformer模型给定的概率分布;
[0254]
自批评序列训练模块,用于采用自批评序列训练使负期望奖赏l
rl
(θ)最小化:
[0255][0256]
[0257][0258]
其中,r(y
1:t
)为奖赏函数,即cider分数的计算,k为波束尺寸,为第i个句子,b为被采样序列获得奖励的平均值计算而来的基线。
[0259]
在一个实施例中,自批评序列训练模块中,对所述位置引导transformer模型训练设定次数,选取所述设定次数中cider分数最高的一次的位置引导transformer模型作为初始模型,对所述初始模型采用自批评序列训练进行调整。
[0260]
上述各模块、单元均是用于对应执行上述基于位置引导transformer的图像描述生成方法中的各个步骤,其具体实现方式参照上述方法实施例所述,在此不再进行赘述。
[0261]
如图5所示,本发明还提供了一种计算机设备,该计算机设备可以是服务器,其内部结构可以如图5所示。该计算机设备包括通过系统总线连接的处理器、存储器、网络接口和数据库。其中,该计算机设计的处理器用于提供计算和控制能力。该计算机设备的存储器包括非易失性存储介质、内存储器。该非易失性存储介质存储有操作系统、计算机程序和数据库。该内存器为非易失性存储介质中的操作系统和计算机程序的运行提供环境。该计算机设备的数据库用于存储基于位置引导transformer的图像描述生成方法的过程需要的所有数据。该计算机设备的网络接口用于与外部的终端通过网络连接通信。该计算机程序被处理器执行时以实现基于位置引导transformer的图像描述生成方法。
[0262]
本领域技术人员可以理解,图5中示出的结构,仅仅是与本技术方案相关的部分结构的框图,并不构成对本技术方案所应用于其上的计算机设备的限定。
[0263]
本技术一实施例还提供一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现上述任意一个基于位置引导transformer的图像描述生成方法。
[0264]
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的计算机程序可存储与一非易失性计算机可读取存储介质中,该计算机程序在执行时,可包括如上述各方法的实施例的流程。其中,本技术所提供的和实施例中所使用的对存储器、存储、数据库或其它介质的任何引用,均可包括非易失性和/或易失性存储器。非易失性存储器可以包括只读存储器(rom)、可编程rom(prom)、电可编程rom(eprom)、电可擦除可编程rom(eeprom)或闪存。易失性存储器可包括随机存取存储器(ram)或者外部高速缓冲存储器。作为说明而非局限,ram通过多种形式可得,诸如静态ram(sram)、动态ram(dram)、同步dram(sdram)、双速据率sdram(ssrsdram)、增强型sdram(esdram)、同步链路(synchlink)dram(sldram)、存储器总线(rambus)直接ram(rdram)、直接存储器总线动态ram(drdram)、以及存储器总线动态ram(rdram)等。
[0265]
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其它变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、装置、物品或者方法不仅包括那些要素,而且还包括没有明确列出的其它要素,或者是还包括为这种过程、装置、物品或者方法所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括该要素的过程、装置、物品或者方法中还存在另外的相同要素。
[0266]
以上所述仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用
本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1