刀具磨损状态预测方法、装置以及存储介质与流程
1.本发明涉刀具磨损技术领域,尤其涉及一种刀具磨损状态预测方法、装置以及存储介质。
背景技术:
2.目前,在产品加工过程中,由于刀具磨损的状态直接会影响到加工产品的表面质量,以及对加工过程中产品加工的稳定性也有一定的影响,因此,需要随时了解清楚刀具的磨损状态,进而建立精准可靠的刀具磨损预测模型来监控加工产品过程中的刀具磨损状态,不仅能够提高刀具的利用率,还能够有效的降低生产加工产品成本。因此,研究高效准确的刀具磨损预测模型是十分必要的。
3.然而,现有的刀具磨损预测方法相关研究大致分为两类:第一种方法是直接预测,第二种方法是间接预测。直接预测主要通过利用光学图像(彩色相机传感器)对刀具磨损状态进行分类,但是直接预测考虑到加工环境的复杂,导致彩色相机安装位置难以定位,并且对刀具进行拍照,需要进行停机操作,这会导致刀具加工效率的降低。间接预测主要通过采集切削力、振动、声发射等信号数据来进行分析预测,但这种方法大多基于单点或者短期预测层面,很少涉及对刀具磨损状态下一个完整的加工周期进行预测。因此,急需解决以上两种刀具磨损预测方法存在的问题。
技术实现要素:
4.鉴于背景技术中存在的问题,本发明的目的在于提供一种刀具磨损状态预测方法、装置以及存储介质,其不仅能有效防提高刀具加工效率,还能够完成对刀具磨损状态下一个完整的加工周期进行预测,提高了刀具磨损数据预测的准确性,保证了产品质量。
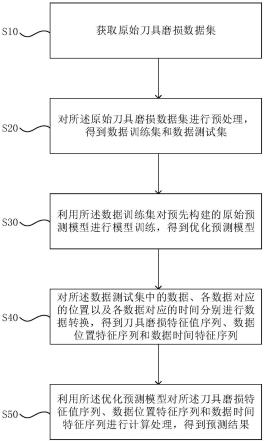
5.为了实现上述目的,本发明提供了一种刀具磨损状态预测方法,所述预测方法包括步骤:
6.获取原始刀具磨损数据集;
7.对所述原始刀具磨损数据集进行预处理,得到数据训练集和数据测试集;
8.利用所述数据训练集对预先构建的原始预测模型进行模型训练,得到优化预测模型;
9.对所述数据测试集中的数据、各数据对应的位置以及各数据对应的时间分别进行数据转换,得到刀具磨损特征值序列、数据位置特征序列和数据时间特征序列;
10.利用所述优化预测模型对所述刀具磨损特征值序列、数据位置特征序列和数据时间特征序列进行计算处理,得到预测结果。
11.可选地,对所述原始刀具磨损数据集进行预处理,得到数据训练集和数据测试集,包括步骤:
12.对所述原始刀具磨损数据集进行标准化处理,得到标准化数据集,所述标准化处理算法为:
[0013][0014]
其中,x表示刀具磨损原始数据,表示刀具磨损原始数据的平均值,σ则表示为刀具磨损原始数据的标准差,z表示刀具磨损数据标准化值;
[0015]
将所述标准化数据集进行切分,得到所述数据训练集和所述数据测试集。
[0016]
可选地,利用所述数据训练集对所述原始预测模型进行模型训练,得到优化预测模型,包括步骤:
[0017]
确定目标预测值;
[0018]
基于目标预测值和实际预测值之间的关系,构建出模型损失函数;
[0019]
将所述数据训练集中的数据按照数据先后顺序依次输入到所述原始预测模型中,并计算出实际预测值序列;
[0020]
通过所述实际预测值序列和构建出的模型损失函数,分别计算出对应的模型损失值,得到模型损失值序列;
[0021]
基于所述模型损失值序列对所述原始预测模型中的参数进行调整,直至所述模型损失值序列收敛,则所述模型损失值序列对应的模型即为所述优化预测模型。
[0022]
可选地,利用所述数据训练集对所述原始预测模型进行模型训练,得到优化预测模型,还包括步骤:
[0023]
比较所述模型损失值序列的收敛值与预设目标收敛值之间的大小:若所述模型损失值序列的收敛值大于所述预设目标收敛值,则调整模型中的参数并继续训练,反之结束训练。
[0024]
可选地,对所述数据测试集中的数据、各数据对应的位置以及各数据对应的时间分别进行数据转换,得到刀具磨损特征值序列、数据位置特征序列和数据时间特征序列,包括步骤:
[0025]
利用一维卷积函数对所述数据测试集进行卷积处理,得到刀具磨损特征值序列;
[0026]
利用编码函数对所述数据测试集中的各数据对应的位置进行位置编码,得到数据位置特征序列;
[0027]
利用全连接层对所述数据测试集中的各数据对应的时间进行编码,得到数据时间特征序列。
[0028]
可选地,利用所述优化预测模型对所述刀具磨损特征值序列、数据位置特征序列和数据时间特征序列进行计算处理,得到预测结果,包括步骤:
[0029]
利用所述优化预测模型中的编码器,对所述刀具磨损特征值序列、数据位置特征序列和数据时间特征序列进行计算处理,得到编码器输出结果;
[0030]
利用所述优化预测模型中的解码器,对所述刀具磨损特征值序列、数据位置特征序列、数据时间特征序列和所述编码器输出结果进行计算处理,得到解码器输出结果;
[0031]
利用所述优化预测模型中的连接层函数对所述解码器输出结果进行处理,得到预测结果。
[0032]
可选地,所述优化预测模型中的编码器包括第一编码层、第一卷积层、第二编码层、第二卷积层、第三编码层和编码归一化层,所述第一编码层、第一卷积层、第二编码层、第二卷积层、第三编码层和编码归一化层依次对所述刀具磨损特征值序列、数据位置特征
序列和数据时间特征序列进行计算处理,得到所述编码器输出结果。
[0033]
可选地,所述优化预测模型中的解码器包括第一解码层、第二解码层和和解码归一化层,所述第一解码层、第二解码层和和解码归一化层依次对所述刀具磨损特征值序列、数据位置特征序列、数据时间特征序列和所述编码器输出结果进行计算处理,得到所述解码器输出结果。
[0034]
本技术还提供一种刀具磨损状态预测装置,所述预测装置包括:
[0035]
数据获取模块,用于获取原始刀具磨损数据集;
[0036]
预处理模块,用于对所述原始刀具磨损数据集进行预处理,得到数据训练集和数据测试集;
[0037]
模型训练模块,用于利用所述数据训练集对所述原始预测模型进行模型训练,得到优化预测模型;
[0038]
数据转换模块,用于对所述数据测试集中的数据、各数据对应的位置以及各数据对应的时间分别进行数据转换,得到刀具磨损特征值序列、数据位置特征序列和数据时间特征序列;
[0039]
预测模块,用于利用所述优化预测模型对所述刀具磨损特征值序列、数据位置特征序列和数据时间特征序列进行计算处理,得到预测结果。
[0040]
本技术还提供一种存储介质,其上存储有计算机可执行指令,当所述计算机可执行指令被计算装置执行时,用于执行上述任意一项所述的刀具磨损状态预测方法。
[0041]
本发明的有益效果如下:
[0042]
通过对原始刀具磨损数据集进行预处理,得到数据训练集和数据测试集,利用数据训练集对预先构建的原始预测模型进行模型训练,得到优化预测模型,利用优化预测模型对刀具磨损特征值序列、数据位置特征序列和数据时间特征序列进行计算处理,得到预测结果,从而有效提高刀具加工效率,还能够完成对刀具磨损状态下一个完整的加工周期进行预测,提高了刀具磨损数据预测的准确性,保证了产品质量。
附图说明
[0043]
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本发明的实施例,并与说明书一起用于解释本发明的原理。
[0044]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,对于本领域普通技术人员而言,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
[0045]
图1是本发明的一种刀具磨损状态预测方法流程图。
[0046]
图2是本发明的一种刀具磨损状态预测方法中的预测模型图。
具体实施方式
[0047]
为使本技术实施例的目的、技术方案和优点更加清楚,下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本技术的一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本技术保护的范围。
[0048]
为使本技术实施例的目的、技术方案和优点更加清楚,下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本技术一部分实施例,而不是全部的实施例。
[0049]
除非另有定义,本文所使用的所有的技术和科学术语与属于本技术的技术领域的技术人员通常理解的含义相同;本文中在申请的说明书中所使用的术语只是为了描述具体的实施例的目的,不是旨在于限制本技术;本技术的说明书和权利要求书及上述附图说明中的术语“包括”和“具有”以及它们的任何变形,意图在于覆盖不排他的包含。
[0050]
在本文中提及“实施例”意味着,结合实施例描述的特定特征、结构或特性可以包含在本技术的至少一个实施例中。在说明书中的各个位置出现该短语并不一定均是指相同的实施例,也不是与其它实施例互斥的独立的或备选的实施例。本领域技术人员显式地和隐式地理解的是,本文所描述的实施例可以与其它实施例相结合。
[0051]
下面参照附图1和附图2来详细说明根据本技术的刀具磨损状态预测方法。
[0052]
所述方法包括:
[0053]
步骤s10,获取原始刀具磨损数据集。
[0054]
步骤s20,对所述原始刀具磨损数据集进行预处理,得到数据训练集和数据测试集。可选地,对所述原始刀具磨损数据集进行预处理还包括步骤:对所述原始刀具磨损数据集中的数据进行规整、补充缺失数据、删除异常数据除。可选地,刀具磨损数据集的数据规整是将不同时间段的数据整合到一起,且把不同行和不同列的数据统一成行或成列,从而方便数据的输入,而且还不易出现数据的错误,并更加容易查看数据是否出现异常,使得最终训练出来的结果更加准确。其中,数据缺失补充是将出现的刀具磨损数据缺失进行及时补充,从而避免了输入至训练模型当中数据不充分,使得训练出来的原始预测模型预测刀具磨损状态更加准确。另外,数据异常删除是对刀具磨损数据出现差异过大或过小将其删除,或者重新取得新的数据,避免了输入至训练模型当中数据不准确,从而避免使得训练出来的原始预测模型预测刀具磨损状态不准确。
[0055]
可选地,对预处理的刀具磨损数据进行相关性分析,确定刀具磨损特征,也即确定在不同的加工的周期刀具磨损的数据分析,从而确定当前刀具磨损特征,使得将最终的刀具磨损特征输入至原始训练模型当中。
[0056]
可选地,对所述原始刀具磨损数据集进行预处理,得到数据训练集和数据测试集,包括步骤:
[0057]
对所述原始刀具磨损数据集进行标准化处理,得到标准化数据集,所述标准化处理算法为:
[0058][0059]
其中,x表示刀具磨损原始数据,表示刀具磨损原始数据的平均值,σ则表示为刀具磨损原始数据的标准差,z表示刀具磨损数据标准化值;
[0060]
将所述标准化数据集进行切分,得到所述数据训练集和所述数据测试集。通过预处理的刀具磨损数据,从而在后续输入预测模型当中,为了避免刀具磨损数据存在量纲(即刀具磨损数据大小分布一致),影响最终的下次使用刀具磨损状态预测结果的准确性。可选地,将标准化后的所有数据按照8:2的比例,其中8份划分为训练集,2份为测试集,通过8份
刀具磨损数据标准化训练集训练原始预测模型,待刀具磨损数据标准化收敛,从而使用2份为测试集将训练好原始预测模型进行测试,若测试合格则无需重新训练预测模型,若测试不合格重新训练原始预测模型。
[0061]
步骤s30,利用所述数据训练集对预先构建的原始预测模型进行模型训练,得到优化预测模型。可选地,原始预测模型可为rd-informer模型,使用预配置的多个训练集训练rd-informer模型,得到优化预测模型,其中,每个所述训练样本为预处理的刀具磨损数据。在训练过程中,如果直接将原始数据输入模型进行训练,在计算过程中很可能造成梯度消失或者梯度爆炸的现象,从而使得模型难以收敛,因此,训练样本为预处理的刀具磨损数据,避免数据存在量纲,影响最终的预测结果,得到准确的刀具磨损预测。
[0062]
在一种实施例中,利用所述数据训练集对所述原始预测模型进行模型训练,得到优化预测模型,包括步骤:
[0063]
确定目标预测值;
[0064]
基于目标预测值和实际预测值之间的关系,构建出模型损失函数;
[0065]
将所述数据训练集中的数据按照数据先后顺序依次输入到所述原始预测模型中,并计算出实际预测值序列;
[0066]
通过所述实际预测值序列和构建出的模型损失函数,分别计算出对应的模型损失值,得到模型损失值序列;
[0067]
基于所述模型损失值序列对所述原始预测模型中的参数进行调整,直至所述模型损失值序列收敛,则所述模型损失值序列对应的模型即为所述优化预测模型。可选地,收敛于0。
[0068]
可选地,通过将输入数据(x
t
,y
t
)至原始训练模型f
θ
(y|x)(已经计算得出的训练模型公式)中,在dropout两次情况下,认为样本通过两个不同的模型,即目标预测值和实际预测值,预测输出为和那么loss的计算如下式:
[0069][0070][0071]
loss=l
mse
+αl
mserd
[0072]
其中,d(
·
)表示表示mse计算,x和y分别代表目标预测值和实际预测值,f代表的是编码器-解码器一个完整的模型,f
θ
(y|x)是预测值。通过判断loss值是否收敛,进而确定了训练模型是否训练合格。当然需要对训练完成的模型进行测试,本技术在训练模型中训练和验证,模型的超参数设置如表下表1所示:
[0073]
表1
[0074][0075]
其中,输入步长代表两个加工工期的长度,预测步长代表下一个加工周期,epoch为模型训练的迭代次数,batch-size为每次训练输入模型的样本数量,dropout代表指定的
丢弃概率为0.01,随机丢弃上一层的输出,优化器代表用来更新和计算影响模型训练和模型输出的网络参数,使其逼近或达到最优值,从而最小化(或最大化)损失函数,本发明采用adam自适应矩估计,初始学习率代表训练模型一开始设置的学习率,学习率是权重更新的步长,激活函数代表让神经网络去学习非线性函数,gelu就是高斯误差线性单元激活函数。
[0076]
在一种实施例中,利用所述数据训练集对所述原始预测模型进行模型训练,得到优化预测模型,还包括步骤:
[0077]
比较所述模型损失值序列的收敛值与预设目标收敛值之间的大小:若所述模型损失值序列的收敛值大于所述预设目标收敛值,则调整模型中的参数并继续训练,反之结束训练。可选地,预设目标收敛值如0.048,优选地为0,对训练完成的模型进行测试,如下表2所示:
[0078]
表2
[0079]
epochtrain losstest loss10.1160.06520.0600.06030.0420.05440.0360.05250.0300.05160.0280.048
[0080]
epoch代表模型训练的迭代次数,train loss代表训练损失值,test loss代表测试损失。
[0081]
步骤s40,对所述数据测试集中的数据、各数据对应的位置以及各数据对应的时间分别进行数据转换,得到刀具磨损特征值序列、数据位置特征序列和数据时间特征序列。进一步地,对刀具磨损特征值序列、数据位置特征序列和数据时间特征序列之间相加得到所述刀具磨损数据值。
[0082]
可选地,对所述数据测试集中的数据、各数据对应的位置以及各数据对应的时间分别进行数据转换,得到刀具磨损特征值序列、数据位置特征序列和数据时间特征序列,包括步骤:
[0083]
利用一维卷积函数对所述数据测试集进行卷积处理,得到刀具磨损特征值序列。可选地,一维卷积核为3
×
1。刀具磨损特征值序列是将预处理的刀具磨损数据x
t
进行一个一维卷积操作,即将输入数据从c
in
维映射到d维,而令一维卷积函数为value embedding,那么其输出为则可以表示为v
out
=value_embedding(x
t
)。
[0084]
利用编码函数对所述数据测试集中的各数据对应的位置进行位置编码,得到数据位置特征序列。具体地,在模型中其所有元素是一起处理的,该做法能够加快模型训练速度,但会忽略数据元素的前后顺序关系,而对于时间序列数据而言,数据间的顺序尤为重要,为了能够确保先后关系不丢失,预测模型为每个输入位置进行了编码,位置编码的公式如下:
[0085]
pe
(pos,2i)
=sin(pos/10000
2i/d
)
[0086]
pe
(pos,2i+1)
=cos(pos/10000
2i/d
)
[0087]
其中,pe(pos,2i)和pe(pos,2i+1)分别表示偶数位置和奇数位置,pos表示序列中
元素的位置,i表示维度;
[0088]
令位置编码函数为position_embedding,那么最终输出则可以表示为:
[0089]
p
out
=position_embedding(x
t
)。
[0090]
利用全连接层对所述数据测试集中的各数据对应的时间进行编码,得到数据时间特征序列。具体地,对于时间序列数据,时间信息起着十分重要的作用,比如月份、星期天、节假日等都会对相关活动产生一定影响,具体的做法是使用一个全连接层将输入的时间戳x
mark
映射到d维,来获得时间特征。
[0091]
令时间编码函数为temporal_embedding,那么其输出为则可以表示为:
[0092]
t
out
=temporal_embedding(x
mark
),
[0093]
然后,最终的刀具磨损数据处理输入则可以表示为:
[0094]
x
embedding
=v
out
+p
out
+t
out
。
[0095]
步骤s50,利用所述优化预测模型对所述刀具磨损特征值序列、数据位置特征序列和数据时间特征序列进行计算处理,得到预测结果。可选地,优化预测模型包括编码器和解码器,通过编码器对刀具磨损特征值序列、数据位置特征序列和数据时间特征序列进行编码计算处理,并将编码器处理的最终结果输入至解码器中进行解码处理,得到下次刀具磨损预测结果。
[0096]
可选地,利用所述优化预测模型中的编码器,对所述刀具磨损特征值序列、数据位置特征序列和数据时间特征序列进行计算处理,得到编码器输出结果。具体地,编码器包括:第一编码层、第一卷积层、第二编码层、第二卷积层、第三编码层和编码归一化层,即attn_layers:encoderlayer层、conv_layers:convlayer层、attn_layers:encoderlayer层、conv_layers:convlayer层、attn_layers:encoderlayer层和norm:layernorm层,所述第一编码层、第一卷积层、第二编码层、第二卷积层、第三编码层和编码归一化层依次对所述刀具磨损特征值序列、数据位置特征序列和数据时间特征序列进行计算处理,得到所述编码器输出结果,即,所述第一编码层用于对所述刀具磨损特征值序列、数据位置特征序列和数据时间特征序列进行计算处理,得到第一编码层输出结果;
[0097]
所述第一卷积层用于对所述第一编码层输出结果进行计算处理,得到第一卷积层输出结果;
[0098]
所述第二编码层用于对所述第一卷积层输出结果进行计算处理,得到第二编码层输出结果;
[0099]
所述第二卷积层用于对所述第二编码层输出结果进行计算处理,得到第二卷积层输出结果;
[0100]
所述第三编码层用于对所述第二卷积层输出结果进行计算处理,得到第三编码层输出结果;
[0101]
所述编码归一化层用于对所述第三编码层输出结果进行计算处理,得到所述编码器输出结果。
[0102]
具体地,为了能够准确高效的建模时间序列之间的关系,优化预测模型的编码器和解码器中都利用到probsparse自注意力操作,具体的,对输入的编码数据通过attn_layers:encoderlayer层中进行处理分别乘上wq、wk和wv三个权重矩阵,即x
embedding
=v
out
+p
out
+t
out
分别乘上wq、wk和wv三个权重矩阵,得到q(query)、k(key)和v(value)。probsparse
自注意力首先对k进行随机采样,得到然后计算每个qi∈q关于矩阵的稀疏系数:
[0103][0104]
其中,q代表刀具磨损点的查询向量,k代表“被查”向量,v代表内容向量(刀具磨损特征向量),lk表示k(key)的长度,d表示编码刀具磨损特征值输入的维度,qi表示q中的第i行,kj表示k中的第j行,为转置形式。q(query)和k(key)是计算刀具磨损attention权重的向量,v代表刀具磨损特征的向量。
[0105]
具体的,通过将根据m(q
i,
)的大小处理完,在m(qi,)中,选择top-u个query组成这里的u=clnlq(c是一个超参数,lq表示q(query)的长度),那么probsparse自注意力的过程可表示为:
[0106][0107]
再将a(q,k,v)在编码器中进一步在计算处理,最终得到的结果输入至解码器中。
[0108]
利用所述优化预测模型中的解码器,对所述刀具磨损特征值序列、数据位置特征序列、数据时间特征序列和所述编码器输出结果进行计算处理,得到解码器输出结果。可选地,所述优化预测模型中的解码器包括第一解码层、第二解码层和和解码归一化层,所述第一解码层、第二解码层和和解码归一化层依次对所述刀具磨损特征值序列、数据位置特征序列、数据时间特征序列和所述编码器输出结果进行计算处理,得到所述解码器输出结果,即解码器包括layers:decoderlayer层、layers:decoderlayer层、norm:layernorm层和projection:linear层,利用所述优化预测模型中的连接层(linear层)函数对所述解码器输出结果进行计算处理,得到预测结果。
[0109]
具体地,a(q,k,v)在编码器中进一步在计算处理,最终得到的结果输入至解码器中,即解码器的输入可表示为其中,是start token,与编码器的输入完全一致,是为预测序列保留的占位,其值全部为零,解码器模型为de,de为已知的,将输入到de,那么预测输出可表示为:最终得到预测结果。
[0110]
在一种实施例中,所述编码器用于捕捉原始刀具数据之间的远程耦合关系,所述解码器用于实现长序列的刀具磨损预测。
[0111]
本技术还提供了一种刀具磨损状态预测装置,所述预测装置包括:
[0112]
数据获取模块,用于获取原始刀具磨损数据集;
[0113]
预处理模块,用于对所述原始刀具磨损数据集进行预处理,得到数据训练集和数据测试集;
[0114]
模型训练模块,用于利用所述数据训练集对所述原始预测模型进行模型训练,得到优化预测模型;
[0115]
数据转换模块,用于对所述数据测试集中的数据、各数据对应的位置以及各数据对应的时间分别进行数据转换,得到刀具磨损特征值序列、数据位置特征序列和数据时间特征序列;
[0116]
预测模块,用于利用所述优化预测模型对所述刀具磨损特征值序列、数据位置特征序列和数据时间特征序列进行计算处理,得到预测结果。
[0117]
本技术还提供一种存储介质,上存储有计算机可执行指令,当所述计算机可执行指令被计算装置执行时,用于执行上述任意一项所述的刀具磨损状态预测方法。
[0118]
以上所述仅是本发明的具体实施方式,使本领域技术人员能够理解或实现本发明。对这些实施例的多种修改对本领域的技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所申请的原理和新颖特点相一致的最宽的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1