基于多阶采样和早期注意力的手语翻译方法
1.本发明涉及手语翻译领域,特别涉及一种基于多阶采样和早期注意力的手语翻译方法。
背景技术:
2.根据世界卫生组织在2020年3月份统计数据显示,全球大约有4.66亿听障人士,超过了全球人口的5%,其中3.4亿人为儿童。对于这些规模庞大的听障人士,手语是其最重要的沟通交流方式,在聋哑人社区扮演着十分重要的角色。手语作为一种视觉语言,它主要通过手部的信息,包括手型、运动轨迹,辅助以面部表情等传递语义信息,是听障人士日常交流的主要方式之一[1]。但由于手语本身学习成本高、难度大,因此在健全人范围内普及程度较低,同时由于地域的差异,导致不同地域间听障人士的交流也存在一定的困难。因此,提出一种可以自动将手语视频翻译成健全人可以理解的自然语言句子的方法意义重大。随即,连续手语识别、手语翻译的相关研究应运而生。
[0003]
连续手语识别(continuoussignlanguagerecognition)[2][3][4]是一项视频理解任务,属于计算机视觉(computervision)研究领域。该任务的输入是一段手语视频,即包含手语动作的连续帧序列,输出是识别的手语句子,即手语对应的词汇组合成的序列。手语翻译(signlanguagetranslation)任务[5][6][7][8]是在手语识别任务的基础上更进一步,将手语识别任务输出的词汇序列翻译成符合自然语言语法的句子,实现从手语视频到自然语言的对应翻译。
[0004]
近年来,研究者们普遍利用基于深度学习的方法进行连续手语识别和手语翻译相关的研究,这些研究的普遍思路是特征提取和序列对齐。首先,对输入的手语视频进行预处理后,使用二维或三维卷积神经网络(convolutionalneuralnetwork,cnn)提取视频的视觉特征;得到视觉特征后,使用时序建模模型对特征序列进行处理,对于这种序列到序列的问题,常用的是循环神经网络(recurrentneuralnetwork,rnn)及其变体,例如长短期记忆网络(longshorttermmemory,lstm[9]和门控循环单元(gatedrecurrentunit,gru)[10]等为主要组成部分的编码器-解码器(encoder-decoder)架构。除此之外,时序连接分类(connectionisttemporalclassification,ctc)方法被用来解决序列到序列的对齐问题,ctc通常应用于弱监督序列的对其中,例如在语音识别中取得了显著的进步,近几年用于手语视频和文本序列的对齐。
[0005]
上述的有关方法已经在连续手语识别和翻译任务上取得了一些不错的成果。然而,由于cnn网络与rnn网络等非常依赖卷积层的特征计算,其提取特征时感受域较为局限,忽视了视频局部和整体的时序特征;另外,传统的编码器-解码器模型缺少对序列中长期注意力内容的关注,从而导致翻译结果出现重复或者缺失信息的问题。
[0006]
参考文献
[0007]
[1]ongscw,ranganaths.automaticsignlanguageanalysis:asurveyandthefuturebeyondlexicalmeaning[j].ieeetransactionsonpattern
analysis&machineintelligence,2005,27(06):873-891.
[0008]
[2]miny,haoa,chaix,etal.visualalignmentconstraintforcontinuoussignlanguagerecognition[c].proceedingsoftheieee/cvfinternationalconferenceoncomputervision.2021:11542-11551.
[0009]
[3]niuz,makb.stochasticfine-grainedlabelingofmulti-statesignglossesforcontinuoussignlanguagerecognition[c].europeanconferenceoncomputervision.springer,cham,2020:172-186.
[0010]
[4]chengkl,yangz,chenq,etal.fullyconvolutionalnetworksforcontinuoussignlanguagerecognition[c].europeanconferenceoncomputervision.springer,cham,2020:697-714.
[0011]
[5]zhouh,zhouw,qiw,etal.improvingsignlanguagetranslationwithmonolingualdatabysignback-translation[c].proceedingsoftheieee/cvfconferenceoncomputervisionandpatternrecognition.2021:1316-1325.
[0012]
[6]orbaya,akarunl.neuralsignlanguagetranslationbylearningtokenization[c].202015thieeeinternationalconferenceonautomaticfaceandgesturerecognition(fg2020).ieee,2020:222-228.
[0013]
[7]yink,readj.bettersignlanguagetranslationwithstmc-transformer[c].proceedingsofthe28thinternationalconferenceoncomputationallinguistics.2020:5975-5989.
[0014]
[8]camgoznc,hadfields,kollero,etal.neuralsignlanguagetranslation[c].proceedingsoftheieeeconferenceoncomputervisionandpatternrecognition.2018:7784-7793.
[0015]
[9]hochreiters,schmidhuberj.longshort-termmemory[j].neuralcomputation,1997,9(8):1735-1780.
[0016]
[10]chok,vanb,gulcehrec,etal.learningphraserepresentationsusingrnnencoder-decoderforstatisticalmachinetranslation[j].arxivpreprintarxiv:1406.1078,2014.
[0017]
[11]iandolafn,hans,moskewiczmw,etal.squeezenet:alexnet-levelaccuracywith50xfewerparametersand《0.5mbmodelsize[j].arxivpreprintarxiv:1602.07360,2016.
[0018]
[12]wangx,girshickr,guptaa,etal.non-localneuralnetworks[c].proceedingsoftheieeeconferenceoncomputervisionandpatternrecognition.2018:7794-7803.
[0019]
[13]lid,xuc,yux,etal.tspnet:hierarchicalfeaturelearningviatemporalsemanticpyramidforsignlanguagetranslation[j].advancesinneuralinformationprocessingsystems,2020,33:12034-12045.
技术实现要素:
[0020]
本发明的目的是针对现有手语翻译方法缺乏探索多尺度长时时序信息的能力,并
且无法 解决词重复翻译的问题,提供一种新的手语翻译方法,以实现多尺度时序特征提取与融合和 避免词重复翻译。为此,本发明采用如下的技术方案:一种基于多阶采样和早期注意力的手 语翻译方法,包括一种新的基于多阶采样的多尺度时序特征提取和基于早期注意力的编码器
‑ꢀ
解码器网络两部分。技术方案如下:
[0021]
一种基于多阶采样和早期注意力的手语翻译方法:其特征在于,包括两个部分,
[0022]
第一部分:首先利用cnn进行视频特征的逐帧提取,然后设置不同的采样率,对时序特 征进行下采样,得到不同视野的时序特征,针对每种采样率下的时序特征,利用非局部模块 [12]关联跨度较大的特征,最后将时序特征上采样到原来的长度并对多个特征进行融合,具 体过程如下:
[0023]
s11帧级特征提取:使用轻量级模型squeezenet提取输入视频的特征,得到长度为t、 特征维度为d的逐帧特征序列x;
[0024]
s12时序特征的多阶采样:利用卷积层和池化层提取k个不同时间尺度的特征序列xi, 公式如下:
[0025]
xi=pi(ci(x)),i≤k
[0026]
其中ci、pi分别表示用于在时间维度上采样的逐点卷积层、池化层;池化层核大小设定 为2的整数倍,其值越大,得到的特征序列长度越短、时间跨度越大,越能表达视频整体上 的信息,但详细视觉信息丢失得也越多;反之,其值较小时得到的采样序列则包含更详尽的 信息;
[0027]
s13时序关系计算:使用非局部模块对每个特征序列xi进行加权计算,方法如下:对每 个特征序列xi使用两个逐点卷积处理,得到特征序列xi的自我注意矩阵ti为特 征序列xi的长度,将ai经过softmax归一化计算后与xi相乘,得到归一化的特征序列xi';
[0028]
s14时序多尺度融合:将各个归一化的特征序列xi'通过时间维度上的反平均池化扩展到 视频原先长度之后,再做逐元素相加操作,得到的多尺度融合后的特征序列i
[0029]
第二部分,建立基于早期注意力的编码器-解码器网络:编码器-解码器网络的基本结构 是lstm,编码器将多尺度融合后的特征序列i进行编码,解码器则将经过编码的特征序列 解码为文本信息;利用早期注意力机制加权融合视觉特征,方法如下:
[0030]
s21编码过程:多尺度融合后的特征序列i输入lstm编码器,得到长度为t的编码器隐 藏状态序列h1,h2,...,h
t
;
[0031]
s22计算注意力m
ij
:利用编码时刻i时编码器隐藏状态hi和解码时刻j时解码器状态sj计 算注意力m
ij
;
[0032]
s23在s22的基础上,将解码时刻j前的注意力相加,得到早期注意力e
ij
,再将早期注意 力e
ij
加入到当前注意力n
ij
的计算;之后,将加入早期注意力的当前注意力n
ij
经过softmax 归一化得到注意力权值a
ij
;
[0033]
s24语义编码计算:利用注意力权值a
ij
对编码器隐藏状态序列h1,h2,...,h
t
进行加权求和, 得到语义编码序列c1,c2,...,cu;
[0034]
s25注意力计算部分的损失函数la:对于编码时刻i和解码时刻j,取其对应的注意力权 值a
ij
和经过softmax归一化的早期注意力softmax(e
ij
)两者中的最小值,将所有i和j的组合对 应的取值求和得到la,如下式所示;
[0035][0036]aij
与softmax(e
ij
)差异越大,la的值越小;
[0037]
s26解码过程:lstm解码器递归地预测出长度为u的翻译序列y=y1y2...yu,对于j时 刻,利用所得到的语义编码cj、j时刻的上一时刻解码符号y
j-1
和解码器状态sj得到j时刻 的解码符号yj;
[0038]
s27训练时对于翻译序列y和目标序列z,计算交叉熵损失le;
[0039]
s28总损失函数l:将le和la相加得到总损失函数l。
附图说明
[0040]
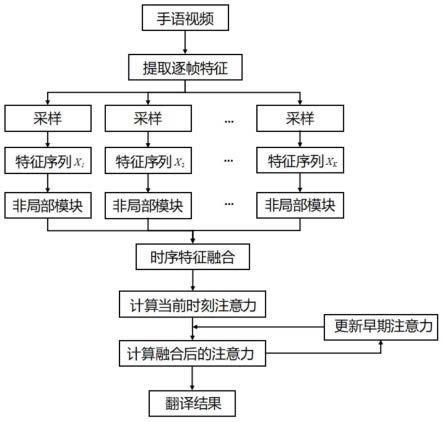
图1为基于多阶采样和早期注意力的手语翻译方法流程图。
[0041]
图2为提取多尺度特征序列示意图。
[0042]
图3为基于早期注意力的编码器-解码器网络。
[0043]
图4为本发明构建的中文手语视频数据集展示图。
[0044]
图5为本发明方法与现有手语翻译方法的翻译准确率比较。
具体实施方式
[0045]
下面结合附图和实施例对本发明进行说明。
[0046]
1.基于多阶采样的多尺度时序特征提取:首先利用cnn进行视频特征的逐帧提取,然后设 置不同的采样率,对时序特征进行下采样,得到不同视野的时序特征,针对每种采样率下的 时序特征,利用简化的非局部模块关联跨度较大的特征,最后将时序特征上采样到原来的长 度并对多个特征进行融合。具体过程分为以下几步:
[0047]
(1)帧级特征提取:使用轻量级模型squeezenet[11]提取输入视频的特征,得到长度为 t、特征维度为d的逐帧特征序列x。
[0048]
(2)时序特征采样:本发明设计了特征的多阶采样方式,利用卷积层和池化层提取k个 不同时间尺度的特征序列xi,可写成公式:
[0049]
xi=pi(ci(x)),i≤k
ꢀꢀ
(1)
[0050]
其中ci、pi分别表示用于在时间维度上采样的逐点卷积层、池化层。池化层核大小设定 为2的整数倍,其值越大,得到的特征序列长度越短、时间跨度越大,越能表达视频整体上 的信息,但详细视觉信息丢失得也越多;反之,其值较小时得到的采样序列则包含更详尽的 信息,采样序列如图2所示。
[0051]
(3)时序关系计算:使用简化的非局部模块[12]对每个特征序列xi进行加权计算,方法 如下:使用两个逐点卷积f、g得到特征序列xi的自我注意矩阵ti为特征序列xi的长度,将ai经过softmax归一化计算后与xi相乘,将相隔较远特征关联起来,得到归一化 的特征序列x'i。对于每个特征序列xi的计算可写成公式:
[0052]ai
=f(xi)
·
g(xi)
t
ꢀꢀ
(2)
[0053]
xi=softmax(ai)xiꢀꢀ
(3)
[0054]
其中,t表示转置。
[0055]
(4)时序多尺度融合:对上述k个不同采样下的特征序列进行时序关系计算后,将各特 征序列通过反平均池化扩展到视频原先长度做逐元素相加操作,具体过程可写成公式:
[0056][0057]
其中r表示在时间维度上的反平均池化层。得到的多尺度融合后的特征序列i输入编码器
ꢀ‑
解码器网络。
[0058]
2.基于早期注意力的编码器-解码器网络:本发明设计的编码器-解码器网络如图3所示, 其基本结构是lstm[9]。编码器将多尺度融合后的特征序列i进行编码,解码器则将经过编 码的特征序列解码为文本信息。为了体现视觉特征对每步解码的重要程度,注意力机制被用 来加权融合视觉特征。在每步解码中,既要考虑当前步的文本特征,又要考虑加权后的视觉 特征,这样可以有利于得到更加准确的翻译结果。然而,现有的方法会导致翻译结果出现词 重复翻译的现象。为了解决这个问题,本发明设计了基于早期注意力信息的翻译方法。
[0059]
(1)编码过程:多尺度融合后的特征序列i输入lstm编码器,得到长度为t的编码器 隐藏状态序列h1,h2,...,h
t
。
[0060]
(2)计算注意力m
ij
:利用编码时刻i时编码器隐藏状态hi和解码时刻j时解码器状态sj计算注意力m
ij
:
[0061]mij
=λtanh(whhi+wssj+b)
ꢀꢀ
(5)
[0062]
其中,wh、ws、b和λ是可学习参数。
[0063]
(3)在(2)的基础上,将解码时刻j前的注意力相加,得到早期注意力e
ij
,加入到当 前注意力n
ij
的计算:
[0064][0065]nij
=λtanh(whhi+wssj+wee
ij
+b)
ꢀꢀ
(7)
[0066]
同样地,we是可学习参数。将加入早期注意力的当前注意力n
ij
经过softmax归一化得到 注意力权值a
ij
:
[0067]aij
=softmax(n
ij
)
ꢀꢀ
(8)
[0068]
(4)语义编码计算:利用注意力权值a
ij
对编码器隐藏状态序列h1,h2,...,h
t
进行加权求和, 得到语义编码序列c1,c2,...,cu,如下式所示。
[0069][0070]
(5)注意力计算部分的损失函数la:对于编码时刻i和解码时刻j,取其对应的注意力 权值a
ij
和经过softmax归一化的早期注意力softmax(e
ij
)两者中的最小值,将所有i和j的 组合对应的取值求和得到la,如下式所示。
[0071][0072]aij
与softmax(e
ij
)差异越大,la的值越小。
[0073]
(6)解码过程:lstm解码器递归地预测出长度为u的翻译序列y=y1y2...yu。对于j时 刻,利用公式(9)得到的语义编码cj、j时刻的上一时刻解码符号y
j-1
(j=1时为开始符号) 和解码器状态sj得到j时刻的解码符号yj。
[0074]
(7)训练时对于翻译序列y和目标序列z,计算交叉熵损失le。
[0075]
(8)总损失函数l:将le和la相加得到总损失函数l:
[0076]
l=le+laꢀꢀ
(11)
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1