基于不确定性估计的多模态情感分析方法、装置及设备
1.本发明涉及一种基于不确定性估计的多模态情感分析方法、装置及设备,属于数据分析领域。
背景技术:
2.多模态情感分析旨在对视频中的图像、音频和文本信息中分析出其中蕴含的情绪信息,如高兴、愤怒和悲伤等。现有的多模态情感分析方法主要关注多模态数据的特征表示和多模态融合这两个方面。
3.在特征表示方面,通常采用预先训练好的特征提取网络对不同模态数据进行特征提取,再将提取后的特征进行进一步的表征学习。对于视频模态,通常先对图像中的人脸进行识别,再提取人脸中的表情特征;对于语音模态,通常使用声学特征分析框架covarep提取音频特征;对于文本模态,通常使用lstm(long short term memory)模型,输入文本的语义词向量获取文本的上下文特征。
4.在多模态融合方面,主要需要兼顾不同模态间的一致性特征和差异性特征。如zadeh早期提出的tfn(zadeh a,chen m,poria s,et al.tensor fusion network for multimodal sentiment analysis[j].arxiv preprint arxiv:1707.07250,2017),将不同模态的特征进行笛卡尔乘积,获取模态间的一致性特征,但是该方法在面对模态数量较多时容易出现维度过大信息冗余的情况,对计算资源要求高,对多模态数据进行分析耗时长,因此实用性不高。此外,还有hazarika等人提出的misa(hazarika d,zimmermann r,poria s.misa:modality-invariant and-specific representations for multimodal sentiment analysis[c].the 28th acm international conference on multimedia.2020:1122-1131.),将多模态分别投影到模态不变和模态专用的空间中,分别捕捉模态共有和模态独有的特征,利用这些整体特征来融合并预测结果,但是该方法基于空间距离的差异难以直接表示模态中的互补性信息。
[0005]
同时,现有的多模态情感分析方法忽视了对预测结果的可靠性进行衡量,由于不同模态间数据质量存在参差不齐的情况,存在预测结果的可靠性难以衡量、解释性差的问题。
[0006]
上述问题是在多模态情感分析过程中应当予以考虑并解决的问题。
技术实现要素:
[0007]
本发明的目的是提供一种基于不确定性估计的多模态情感分析方法解决现有技术中存在的预测结果的可靠性难以衡量、解释性差、分析耗时长、不同模态中的互补性信息难以有效保留的问题。
[0008]
本发明的技术解决方案是:
[0009]
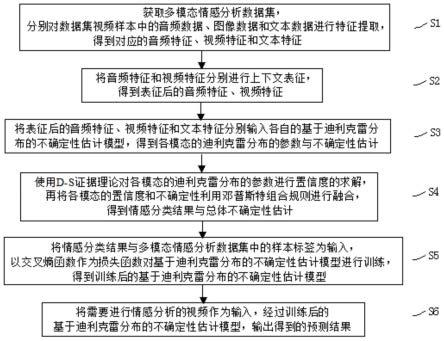
一种基于不确定性估计的多模态情感分析方法,包括以下步骤,
[0010]
s1、获取多模态情感分析数据集,多模态情感分析数据集中的视频样本包括音频
数据、图像数据、文本数据与样本标签,分别对视频样本中的音频数据、图像数据和文本数据进行特征提取,得到对应的音频特征、视频特征和文本特征;
[0011]
s2、将步骤s1所得音频特征和视频特征分别进行上下文表征,得到表征后的音频特征、视频特征;
[0012]
s3、将步骤s2得到的表征后的音频特征、视频特征和文本特征分别输入各自的基于迪利克雷分布的不确定性估计模型,分别得到音频模态的迪利克雷分布的参数、视频模态的迪利克雷分布的参数和文本模态的迪利克雷分布的参数与不确定性估计;
[0013]
s4、使用d-s证据理论对步骤s3得到的音频模态的迪利克雷分布的参数、视频模态的迪利克雷分布的参数和文本模态的迪利克雷分布的参数进行置信度的求解,再将各模态的置信度和不确定性利用邓普斯特组合规则进行融合,得到情感分类结果与总体不确定性估计;
[0014]
s5、将步骤s4中得到的情感分类结果与步骤s1中获得的多模态情感分析数据集中的样本标签为输入,以交叉熵函数作为损失函数对步骤s3中的基于迪利克雷分布的不确定性估计模型进行训练,得到训练后的基于迪利克雷分布的不确定性估计模型;
[0015]
s6、将需要进行情感分析的视频作为输入,经过步骤s5所得基于迪利克雷分布的不确定性估计模型,输出得到的预测结果。
[0016]
进一步地,步骤s1中,分别对视频样本中的音频数据、图像数据和文本数据进行特征提取,具体为,
[0017]
s11、对数据集中的音频数据逐帧进行分段,输入预先训练好的音频特征提取网络,得到音频特征;
[0018]
s12、对数据集中的视频数据逐帧进行分段,输入预先训练好的图像特征提取网络,得到视频特征;
[0019]
s13、对数据集中的文本数据输入文本预训练模型bert,得到表征后的文本特征。
[0020]
进一步地,步骤s2中,将步骤s1所得音频特征和视频特征分别进行上下文表征,得到表征后的音频特征、视频特征,具体为,
[0021]
s21、将步骤s1所得音频特征输入一层双向长短时记忆网络,用于提取音频特征中的上下文关系,再将双向长短时记忆网络的输出输入至随机失活层,用于避免训练过程中出现的过拟合现象,最后将随机失活层的输出输入至一层全连接层,得到表征后的音频特征;
[0022]
s22、将步骤s1所得视频特征输入一层双向长短时记忆网络,用于提取视频特征中的上下文关系,再将双向长短时记忆网络的输出输入至随机失活层,用于避免训练过程中出现的过拟合现象,最后将随机失活层的输出输入至一层全连接层,得到表征后的视频特征。
[0023]
进一步地,步骤s3中,将步骤s2得到的表征后的音频特征、视频特征和文本特征分别输入各自的基于迪利克雷分布的不确定性估计模型,得到对应音频、视频和文本模态的迪利克雷分布与不确定性估计,具体为,
[0024]
s31、将音频特征、视频特征和文本特征分别输入各自的基于迪利克雷分布的不确定性估计模型,该模型由一层全连接层和一层线性整流激活函数层构成,其中全连接层将步骤s2得到的对应模态上下文表征后的特征映射成证据形式,并输出至线性整流激活函数
层,用于保证输出结果为非负值,其输出维度与情感类别个数相等,模型输出即对应模态基于迪利克雷分布的证据表示:
[0025][0026]
其中,a、v、t分别对应音频模态、视频模态和文本模态,k为情感类别的个数;
[0027]
s32、根据步骤s31所得对应模态基于迪利克雷分布的证据表示,求解出迪利克雷分布利用迪利克雷分布的参数,得到对应的不确定性估计ua、uv、u
t
。
[0028]
进一步地,步骤s32中,求解出迪利克雷分布进一步地,步骤s32中,求解出迪利克雷分布利用迪利克雷分布的参数,得到对应的不确定性估计ua、uv、u
t
,计算公式如下:
[0029][0030]
其中,m∈{a,v,t},为对应模态,表示迪利克雷强度,k为情感类别的个数。
[0031]
进一步地,步骤s4中,使用d-s证据理论对步骤s3得到的音频模态的迪利克雷分布的参数、视频模态的迪利克雷分布的参数和文本模态的迪利克雷分布的参数进行置信度的求解,再将各模态的置信度和不确定性利用邓普斯特组合规则进行融合,得到情感分类结果与总体不确定性估计,具体为,
[0032]
s41、对音频模态、视频模态和文本模态的迪利克雷分布,分别求解得到各模态基于d-s证据理论的置信度s证据理论的置信度计算公式如下:
[0033][0034]
其中,m∈{a,v,t},为对应模态,表示迪利克雷强度;
[0035]
s42、将音频模态和视频模态对应的置信度和不确定性使用邓普斯特组合规则进行初步融合,得到初步融合后的置信度β
′
=[β
′1,...,β
′k]和不确定性u
′
,再将β
′
=[β
′1,...,β
′k]和u
′
与文本模态的置信度和不确定性u
t
进行融合,得到最终的置信度β
″
=[β
″1,...,β
″k]和不确定性u
″
;
[0036]
s43、由置信度β
″
求得最终预测的概率分布结果p=[p1,...,pk]。
[0037]
进一步地,步骤s42中,将音频模态和视频模态对应的置信度和不确定性使用邓普斯特组合规则进行初步融合,得到初步融合后的置信度β
′
=[β
′1,...,β
′k]和不确定性u
′
,计算公式如下:
[0038][0039]
其中,为音频模态对应的第i个情感类别的置信度,为音频
模态对应的第j个情感类别的置信度,分别为音频模态和视频模态对应的第k个情感类别的置信度,ua、uv、u
t
分别为音频模态、视频模态和文本模态对应的不确定性估计;
[0040]
再将β
′
=[β
′1,...,β
′k]和u
′
与文本模态的置信度和不确定性u
t
进行融合,得到最终的置信度β
″
=[β
″1…
,β
″k]和不确定性u
″
,计算公式如下:
[0041][0042]
其中,β
′i为初步融合后的第i个情感类别的置信度,为文本模态的第j个情感类别的置信度,β
′k为初步融合后的第k个情感类别的置信度,为文本模态的第k个情感类别的置信度,u
t
为文本模态对应的不确定性估计,u
′
为初步融合后的不确定性。
[0043]
进一步地,步骤s43中,由置信度β
″
求得最终预测的概率分布结果p=[p1,...,pk],计算公式如下:
[0044]
pk=exp[ψ(β
″k×
s+1)-ψ(s)],k∈[1,k]
[0045]
其中,ψ(
·
)为digamma函数,β
″k为步骤s42得到的第k个情感类别的最终的置信度,其中,u
″
为步骤s42得到的最终的不确定性,k为情感类别的个数。
[0046]
一种实现上述任一项所述的基于不确定性估计的多模态情感分析方法的装置,包括特征提取模块、情感分类模块和预测分析模块,
[0047]
特征提取模块:获取多模态情感分析数据集,分别对视频样本中的音频数据、图像数据和文本数据进行特征提取,得到对应的音频特征、视频特征和文本特征;将所得音频特征和视频特征分别进行上下文表征,得到表征后的音频特征、视频特征;
[0048]
情感分类模块:将特征提取模块得到的表征后的音频特征、视频特征和文本特征分别输入各自的基于迪利克雷分布的不确定性估计模型,得到对应音频、视频和文本模态的迪利克雷分布与不确定性估计;使用d-s证据理论对音频模态的迪利克雷分布、视频模态的迪利克雷分布和文本模态的迪利克雷分布进行置信度的求解,再将各模态的置信度和不确定性进行融合,得到情感分类结果与总体不确定性估计;
[0049]
预测分析模块:将情感分类模块得到的情感分类结果与多模态情感分析数据集中的样本标签为输入,以交叉熵函数作为损失函数进行训练,得到训练后的基于迪利克雷分布的不确定性估计模型;将需要进行情感分析的视频作为输入,经过所得训练后的基于迪利克雷分布的不确定性估计模型,输出得到的预测结果。
[0050]
一种计算机设备,包括存储器和处理器,存储器存储可在处理器上运行的计算机程序,处理器执行计算机程序时实现上述任一项所述的基于不确定性估计的多模态情感分析方法的步骤。
[0051]
本发明的有益效果是:
[0052]
一、该种基于不确定性估计的多模态情感分析方法、装置及设备,与现有技术相比,识别精度更高,具有更强的鲁棒性和更优的可解释性,且对计算资源要求低,对多模态数据进行分析耗时更短。该种基于不确定性估计的多模态情感分析方法,对多模态模态数据进行不确定性估计,并对其概率分布进行建模,用于音视频情感分析,能够在提高分类精
度的同时,准确评估多模态数据样本中各模态数据的质量,解决了由于单一模态数据存在噪声和不确定性导致的多模态数据情感预测结果可靠性低并且缺乏解释性的问题。
[0053]
二、本发明方法,基于迪利克雷分布的不确定性估计,能够在对多模态数据进行情感分析的同时,获取总体预测结果的不确定性估计,该不确定性估计指标能够用于衡量预测结果是否可靠,其值越小可靠性越高。同时,还能通过对单模态的情感分析动态的获取单模态数据的不确定性,用于衡量各单模态数据的质量,解决了现有方法在获取预测结果时缺乏解释性的问题。
[0054]
三、该种基于不确定性估计的多模态情感分析方法、装置及设备,对每个模态均进行了情感分析,各模态的预测相互独立互不干扰,能够有效地保留不同模态间的互补性信息。
[0055]
四、该种基于不确定性估计的多模态情感分析方法、装置及设备,在将不同模态的预测结果进行融合的过程中采用迪利克雷分布与邓普斯特组合规则,相较于现有的基于softmax的分类器识别精度更高。本发明方法对不同模态的预测结果进行融合,融合计算的过程中不涉及大量的学习参数,在训练过程中收敛快,对计算资源要求低,对多模态数据进行分析耗时更短,更符合实际场景的需要。
[0056]
五、该种基于不确定性估计的多模态情感分析方法、装置及设备,采用d-s证据理论对多模态特征进行表示与融合,在数据存在噪声和不确定的情况下分类精度衰减更低,具有更强的鲁棒性。
附图说明
[0057]
图1是本发明实施例基于不确定性估计的多模态情感分析方法的流程示意图。
[0058]
图2是实施例获得情感分类结果的说明示意图。
[0059]
图3是本发明实施例基于不确定性估计的多模态情感分析装置的说明示意图。
具体实施方式
[0060]
下面结合附图详细说明本发明的优选实施例。
[0061]
实施例
[0062]
一种基于不确定性估计的多模态情感分析方法,如图1,包括以下步骤,
[0063]
s1、获取多模态情感分析数据集,多模态情感分析数据集中的视频样本包括音频数据、图像数据、文本数据与样本标签,分别对视频样本中的音频数据、图像数据和文本数据进行特征提取,得到对应的音频特征、视频特征和文本特征;
[0064]
s11、对数据集中的音频数据逐帧进行分段,输入预先训练好的音频特征提取网络,得到音频特征;
[0065]
s12、对数据集中的视频数据逐帧进行分段,输入预先训练好的图像特征提取网络,得到视频特征;
[0066]
s13、对数据集中的文本数据输入文本预训练模型bert,得到表征后的文本特征。
[0067]
s2、将步骤s1所得音频特征和视频特征分别进行上下文表征,得到表征后的音频特征、视频特征;
[0068]
s21、将步骤s1所得音频特征输入一层双向长短时记忆网络slstm,用于提取音频
特征中的上下文关系,再将双向长短时记忆网络的输出输入至随机失活层即dropout层,用于避免训练过程中出现的过拟合现象,最后将随机失活层的输出输入至一层全连接层,得到表征后的音频特征;
[0069]
s22、将步骤s1所得视频特征输入一层双向长短时记忆网络slstm,用于提取视频特征中的上下文关系,再将双向长短时记忆网络的输出输入至随机失活层,用于避免训练过程中出现的过拟合现象,最后将随机失活层的输出输入至一层全连接层,得到表征后的视频特征。
[0070]
s3、将步骤s2得到的表征后的音频特征、视频特征和文本特征分别输入各自的基于迪利克雷分布的不确定性估计模型,分别得到音频模态的迪利克雷分布的参数、视频模态的迪利克雷分布的参数和文本模态的迪利克雷分布的参数与不确定性估计;
[0071]
s31、将音频特征、视频特征和文本特征分别输入各自的基于迪利克雷分布的不确定性估计模型,该模型由一层全连接层和一层线性整流激活函数层即relu激活函数层构成,其中全连接层将步骤s2得到的对应模态上下文表征后的特征映射成证据形式,并输出至线性整流激活函数层,防止训练过程中产生的梯度消失问题,保证输出结果为非负值,其输出维度与情感类别个数相等,模型输出即对应模态基于迪利克雷分布的证据表示:
[0072][0073]
其中,a、v、t分别对应音频模态、视频模态和文本模态,k为情感类别的个数;
[0074]
s32、根据步骤s31所得对应模态基于迪利克雷分布的证据表示,求解出迪利克雷分布利用迪利克雷分布的参数,得到对应的不确定性估计ua、uv、u
t
,计算公式为:
[0075][0076]
其中,m∈{a,v,t},为对应模态,表示迪利克雷强度,k为情感类别的个数。
[0077]
s4、使用d-s证据理论即邓普斯特-谢佛证据理论(dempster-shafer evidence theory)对步骤s3得到的音频模态的迪利克雷分布的参数、视频模态的迪利克雷分布的参数和文本模态的迪利克雷分布的参数进行置信度的求解,再将各模态的置信度和不确定性利用邓普斯特组合规则(dempster’s combinational rule)进行融合,得到情感分类结果与总体不确定性估计,如图2,具体为:
[0078]
s41、对音频模态、视频模态和文本模态的迪利克雷分布,分别求解得到各模态基于d-s证据理论的置信度s证据理论的置信度计算公式如下:
[0079][0080]
其中,m∈{a,v,t},为对应模态,表示迪利克雷强度;
[0081]
s42、将音频模态和视频模态对应的置信度和不确定性使用dempster融合规则进行初步融合,得到初步融合后的置信度β
′
=[β
′1,...,β
′k]和不确定性u
′
,再将β
′
=
[β
′1,...,β
′k]和u
′
与文本模态的置信度和不确定性u
t
进行融合,得到最终的置信度β
″
=[β
″1,
…
,β
″k]和不确定性u
″
,计算公式如下:
[0082][0083][0084]
其中,为音频模态对应的第i个情感类别的置信度,为音频模态对应的第j个情感类别的置信度,分别为音频模态和视频模态对应的第k个情感类别的置信度,ua、uv、u
t
分别为音频模态、视频模态和文本模态对应的不确定性估计;β
′i为初步融合后的第i个情感类别的置信度,为文本模态的第j个情感类别的置信度,β
′k为初步融合后的第k个情感类别的置信度,为文本模态的第k个情感类别的置信度,u
t
为文本模态对应的不确定性估计,u
′
为初步融合后的不确定性。
[0085]
s43、由置信度β
″
求得最终预测的概率分布结果p=[p1,...,pk],计算公式如下:
[0086]
pk=exp[ψ(β
″k×
s+1)-ψ(s)],k∈[1,k]
[0087]
其中,ψ(
·
)为digamma函数,β
″k为步骤s42得到的第k个情感类别的最终的置信度,其中,u
″
为步骤s42得到的最终的不确定性,k为情感类别的个数。
[0088]
s5、将步骤s4中得到的情感分类结果与步骤s1中获得的多模态情感分析数据集中的样本标签为输入,以交叉熵函数作为损失函数对步骤s3中的基于迪利克雷分布的不确定性估计模型进行训练,得到训练后的基于迪利克雷分布的不确定性估计模型;
[0089]
s6、将需要进行情感分析的视频作为输入,经过步骤s5所得基于迪利克雷分布的不确定性估计模型,输出得到的预测结果。
[0090]
一种实现上述任一项所述的基于不确定性估计的多模态情感分析方法的装置,包括特征提取模块、情感分类模块和预测分析模块,如图3。
[0091]
特征提取模块:获取多模态情感分析数据集,分别对视频样本中的音频数据、图像数据和文本数据进行特征提取,得到对应的音频特征、视频特征和文本特征;将所得音频特征和视频特征分别进行上下文表征,得到表征后的音频特征、视频特征;
[0092]
情感分类模块:将特征提取模块得到的表征后的音频特征、视频特征和文本特征分别输入各自的基于迪利克雷分布的不确定性估计模型,得到对应音频、视频和文本模态的迪利克雷分布与不确定性估计;使用d-s证据理论对音频模态的迪利克雷分布、视频模态的迪利克雷分布和文本模态的迪利克雷分布进行置信度的求解,再将各模态的置信度和不确定性进行融合,得到情感分类结果与总体不确定性估计;
[0093]
预测分析模块:将情感分类模块得到的情感分类结果与多模态情感分析数据集中的样本标签为输入,以交叉熵函数作为损失函数进行训练,得到训练后的基于迪利克雷分布的不确定性估计模型;将需要进行情感分析的视频作为输入,经过所得训练后的基于迪利克雷分布的不确定性估计模型,输出得到的预测结果。
[0094]
一种计算机设备,包括存储器和处理器,存储器存储可在处理器上运行的计算机
intelligence.vol.34.no.05.2020.)、misa(modality invariant and specific representations)。实验结果如表1所示。表1中,tfn表示zadeh提出的张量融合网络(tensor fusion network),mfn表示zadeh提出的记忆融合网络(memory fusion network),mfm表示tsai提出的多模态分解模型(multimodal factorization model),iccn表示sun提出的交互典型相关分析网络(interaction canonical correlation network),misa表示hazarika提出的模态不变与模态特定表征(modalityinvariantand specific representations)网络模型,acc-7表示七分类任务的识别精度,acc-2表示二分类任务的识别精度,f1表示f1分数(f1 score),是用于衡量二分类模型精确度的指标。
[0104]
表1实施例方法与现有的五种模型的结果对比
[0105][0106]
表1中结果表明,与现有方法相比,实施例方法在识别准确率上有较为显著的提升效果。
[0107]
上面是结合附图对本发明的实施方式介绍的详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,可联想的变换或替换,都应涵盖在本发明的包含范围之内,因此,本发明的保护范围应该以权利要求书的保护范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1